









需引入包 java.util.*;
该篇只是对java集合类的一些常用方法进行记录摘抄,方便日后理解运用,并没有对其原理进行深究,初涉这方面的知识,归结的比较杂乱,望谅解
一.集合类的关系
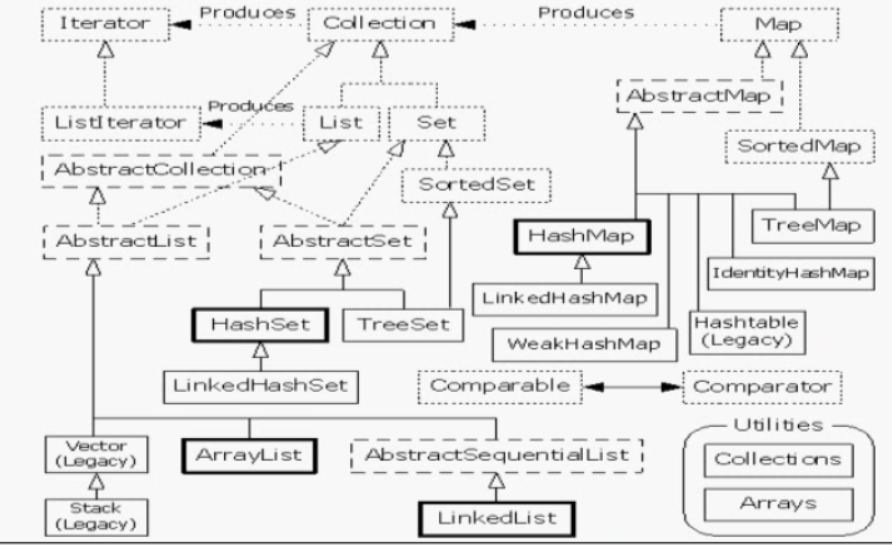
二.主要的集合类
1.List结构的集合类
①.ArrayList类(动态数组)
每当执行Add、AddRange、Insert、InsertRange等添加元素的方法,都会检查内部数组的容量是否不够了,如果是,它就会以当前容量的两倍来重新构建一个数组,将旧元素Copy到新数组中,然后丢弃旧数组,在这个临界点的扩容操作,应该来说是比较影响效率的。
定义对象:ArrayList al=new ArrayList();
显示大小:al.size();
加入数据(类型是Object):al.add(E e); (允许加入相同的对象)
访问对象:比如:Cat temp=(Cat)al.get(0);(注意将取出来的对象强制转换,Cat是一个类,0代表访问第一个对象)
删除对象:al.remove(0);(0代表删除第一个对象)
//第一种遍历 ArrayList 对象的方法
foreach(object o in al)
{
Console.Write(o.ToString()+" ");
}
//第二种遍历 ArrayList 对象的方法
IEnumerator ie=al.GetEnumerator();
while(ie.MoveNext())
{
Console.Write(ie.Curret.ToString()+" ");
}
②.LinkedList类
LinkedList类是双向列表,列表中的每个节点都包含了对前一个和后一个元素的引用.
加入数据:al.addFirst(cat1);(形同栈,从表头加入,后加入的在前面)
al.addLast(cat1);(形同队列,从表尾加入,后加入的在后面)
删除:
al.remove(int index);//根据下标删除
al.removeAll();//全部删除
al.removeFirst();//从前面删除
al.removeLast();//从后面删除
al.getFirst();//获取链表第一个元素
al.getLast());//获取链表最后一个元素
al.clear();//删掉所有元素:清空LinkedList
al.subList(2, 5).clear(); //根据范围删除列表元素
al.set(3, “Replaced”);//使用set方法替换元素,方法的第一个参数是元素索引,后一个是替换值
String[] my = theList.toArray(new String[theList.size()]); //将LinkedList转换为数组,数组长度为链表长度
List< String> myList = new ArrayList< String>(myQueue); //将LinkedList转换成ArrayList
③.Vector类(动态数组,同步访问)
Vector v = new Vector(4); //使用Vector的构造方法进行创建
v.add(“Test0”); //使用add方法直接添加元素
v.remove(“Test0”); //删除指定内容的元素
v.remove(0); //按照索引号删除元素
④.ArrayList和LinkedList的区别
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
4.ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间。
⑤.ArrayList和Vector的区别

2.Map结构的集合类
①.HashMap类
不允许Key值重复,相同的Key后者将覆盖前者.
原理:(可以理解为其存储数据的容器就是一个线性数组)
1.根据key得到hashcode 方法:int hash = hash(key.hashCode());
2.根据hashcode得到对应的位置 方法:int i = indexFor(hash, table.length);
这一步很关进。可以将一个key转换成一个固定的位置。这就是为什么快的原因。当需要get(o)的时候。只要根据上面1和2两步 就可以得到该key对应的value所在的位置(table数组中的位置)。可以快速取出value
总结 : hashmap快的原因:可以通过hash算法。将一个固定的key转换为它唯一对应的位置。
原理具体详解:http://www.cnblogs.com/xwdreamer/archive/2012/05/14/2499339.html
以及百度百科对重写方法的详细说明:http://baike.baidu.com/link?url=VqLlZnyN_SqHK-zjv9lospcdMKPhrrpx7uOXR8PcK7q3uYG5z0rR6Szygs0BHr1jkrLdsuJFa3iiYAmuzfdby_
加入对象:hm.put(“关键字”,cat1);
关键字查找:hm.containsKey(“关键字”) //查找是否有包含这个关键字的对象并返回一个值
取出对象:Cat cat=(Cat)hm.get(“关键字”);
//方法一
// 遍历所有Key和value:(当不知道KEY值时无法使用for循环遍历,使用迭代器Iterator)
Iterator it=hm.keySet().iterator();
while(it.hasNext())// 探测判断是否还有下一个对象
{
String key=it.next().toString();//取出key
Cat cat=(Cat)hm.get(key);//再通过key取出value
}
//方法二
//在Hash中可以直接使用以下方法遍历(所有键)KeySet,然后通过键可以找出需要的值
HashMap<String,String> mp = new HashMap<String,String>();
for (String i : mp.keySet())
{
//String 是mp中的键的对应类型 i 是对应的KeySet中的每一个键值
System.out.println( mp.get(i));
}
②.Hashtable类(在用法上同HashMap)
HashtableObject.Add(key,);//在哈希表中添加一个key/键值对
HashtableObject.Remove(key);//在哈希表中去除某个key/键值对
HashtableObject.Clear();//从哈希表中移除所有元素
HashtableObject.Contains(key);//判断哈希表是否包含特定键key
③.HashMap和Hashtable的区别

3.Set结构的集合类
①.HashSet类(只能存储不重复的对象,无序)
与HashMap的不同是HashMap属性包含key,和value,而HashSet就像是把HashMap中value去掉,就是只有一个key的HashMap集合
boolean add(E e);//如果此 set 中尚未包含指定元素,则添加指定元素。
void clear();//从此 set 中移除所有元素。
Object clone();//返回此 HashSet 实例的浅表副本:并没有复制这些元素本身。
boolean contains(Object o);//如果此 set 包含指定元素,则返回 true。
boolean isEmpty();//如果此 set 不包含任何元素,则返回 true。
Iterator< E> iterator();//返回对此 set 中元素进行迭代的迭代器。
boolean remove(Object o);//如果指定元素存在于此 set 中,则将其移除。
int size();//返回此 set 中的元素的数量(set 的容量)。
②HashMap和HashSet的区别

③.TreeSet类
TreeSet是一个有序集合,TreeSet中的元素将按照升序排列,缺省是按照自然排序进行排列,意味着TreeSet中的元素要实现Comparable接口。或者有一个自定义的比较器。构造一个新的空TreeSet,它根据指定比较器进行排序。插入到该 set 的所有元素都必须能够由指定比较器进行相互比较:对于 set 中的任意两个元素 e1 和e2,执行 comparator.compare(e1, e2) 都不得抛出 ClassCastException。如果用户试图将违反此约束的元素添加到 set 中,则 add 调用将抛出 ClassCastException。
1.TreeSet是集合,是用来存数据的,就像数组一样,但TreeSet是动态的。
2.TreeSet存的数据是无序号的,你不能通过get的方法获得里面的数据。
3.TreeSet存数据是有顺序的,这个顺序是你规定的,规定方法就是通过实现Comparator接口。
4.你上面的存储顺序的规则就是static class compareToStudent implements Comparator {……. }这个方法,至于public int compareTo(Object o) {…..}那是它的一部分
与HashSet的不同:
1.HashSet无序集合,放入顺序与取出顺序不一致。
2.TreeSet自动排好序,而且必须放相同的类型,放不同的类型就会报错。
4.Queue结构的集合类
Queue接口
队列是一种数据结构.它有两个基本操作:在队列尾部加人一个元素,和从队列头部移除一个元素就是说,队列以一种先进先出的方式管理数据,如果你试图向一个 已经满了的阻塞队列中添加一个元素或者是从一个空的阻塞队列中移除一个元索,将导致线程阻塞.在多线程进行合作时,阻塞队列是很有用的工具。工作者线程可 以定期地把中间结果存到阻塞队列中而其他工作者线线程把中间结果取出并在将来修改它们。队列会自动平衡负载。如果第一个线程集运行得比第二个慢,则第二个 线程集在等待结果时就会阻塞。如果第一个线程集运行得快,那么它将等待第二个线程集赶上来。
add 增加一个元索 如果队列已满,则抛出一个IIIegaISlabEepeplian异常
remove 移除并返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
element 返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
offer 添加一个元素并返回true 如果队列已满,则返回false
poll 移除并返问队列头部的元素 如果队列为空,则返回null
peek 返回队列头部的元素 如果队列为空,则返回null
put 添加一个元素 如果队列满,则阻塞
take 移除并返回队列头部的元素 如果队列为空,则阻塞
注意:poll和peek方法出错进返回null。因此,向队列中插入null值是不合法的。















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









