







读书笔记仅供个人学习使用
本文主要参考书籍为《统计学习方法》(李航)第二版
参考博文
带你搞懂朴素贝叶斯分类算法
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。
对于给定的训练数据集
(1)首先基于特征条件独立假设学习输入/输出的联合概率分布;
(2)然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出Y
朴素贝叶斯法的学习与分类
基本方法
朴素贝叶斯法通过训练数据集学习X和Y的联合概率分布 P(X,Y)。
学习先验概率分布及条件概率分布。
先验概率分布
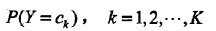
条件概率分布
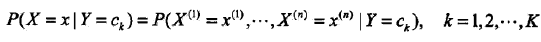
条件概率分布有指数级数量的参数,其估计实际是不可行的。
朴素贝叶斯法对条件概率分布作了条件独立性的假设。条件独立性假设是说用于分类的特征在类确定的条件下都是条件独立的。
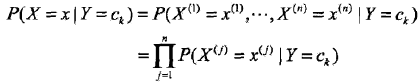
朴素贝叶斯法实际上学习到生成数据的机制,所以属于生成模型。
朴素贝叶斯法通过最大后验概率(MAP)准则进行类的判决。
基于贝叶斯定理:
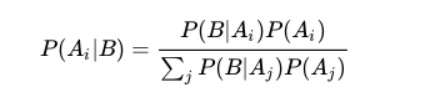
后验概率为:
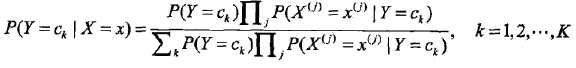
分类器
(后验概率最大化等价于0-1损失函数时的期望风险最小化)
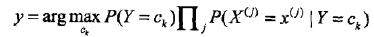
朴素贝叶斯法的参数估计
极大似然估计
先验概率的极大似然估计:
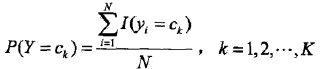
设第j个特征x(j)可能取值的集合为
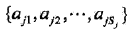
条件概率的极大似然估计:
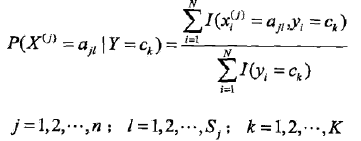
贝叶斯估计
用极大似然估计可能会出现所要估计的概率值为0的情况,使分类产生偏差,解决这一问题的方法是采用贝叶斯估计
条件概率的贝叶斯估计为:
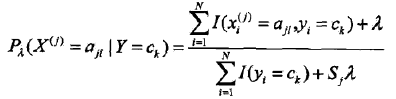
(λ>=0)
先验概率的贝叶斯估计为:
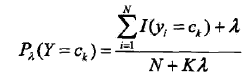
朴素贝叶斯算法
以参数估计为极大似然估计为例:
样本集为:
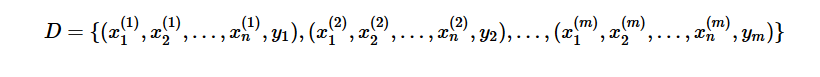 yi,i=1,2,…,m 表示样本类别,取值为 {C1,C2,…,CK}
yi,i=1,2,…,m 表示样本类别,取值为 {C1,C2,…,CK}
(1)计算先验概率:
求出样本类别的个数 K
对于每一个样本 Y=Ck
计算出 P(Y=Ck) ,其为类别 Ck 在总样本集中的频率。
(2)计算条件概率:
将样本集划分成 K 个子样本集,分别对属于 Ck 的子样本集进行计算,计算出其中特征 Xj=ajl 的概率: P(Xj=ajl|Y=Ck)。其为该子集中特征取值为 ajl 的样本数与该子集样本数的比值。
(3)针对待预测样本 xtest ,
计算其对于每个类别 Ck 的后验概率
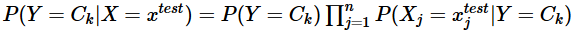
概率值最大的类别即为待预测样本的预测类别。
简单例子
文本分类器 来源于python实现朴素贝叶斯算法
输入数据:eat spicy chicken

import numpy as np
def loadDataSet():
dataset = [['study', 'or', 'rest', 'OK'],
['eat', 'fried', 'chicken'],
['today', 'is', 'a', 'bad_day'],
['today', 'is', 'a', 'good', 'day', 'right'],
['today', 'is', 'sunday', 'right'],
['I', 'want', 'to', 'rest']]
label = [1, 1, 0, 0, 0, 1]
return dataset, label
# 获取文档中出现的不重复词表
def createVocabList(dataset):
vocaset = set([]) # 用集合结构得到不重复词表
for document in dataset:
vocaset = vocaset | set(document) # 两个集合的并集
return list(vocaset)
def setword(listvocaset, inputSet):
newVocaset = [0] * len(listvocaset)
for data in inputSet:
if data in listvocaset:
newVocaset[listvocaset.index(data)] = 1 # 如果文档中的单词在列表中,则列表对应索引元素变为1
return newVocaset
def train(listnewVocaset, label):
label = np.array(label)
numDocument = len(listnewVocaset) # 样本总数
numWord = len(listnewVocaset[0]) # 词表的大小
pInsult = np.sum(label) / float(numDocument)
p0num = np.ones(numWord) # class 0
p1num = np.ones(numWord) # class 1
p0Denom = 2.0 # 拉普拉斯平滑
p1Denom = 2.0
for i in range(numDocument):
if label[i] == 1:
p1num += listnewVocaset[i]
p1Denom += 1
else:
p0num += listnewVocaset[i]
p0Denom += 1
# 取对数是为了防止因为小数连乘而造成向下溢出
p0 = np.log(p0num / p0Denom) # 属于0的概率
p1 = np.log(p1num / p1Denom) # 属于1的概率
return p0, p1, pInsult
# 分类函数
def classiyyNB(Inputdata, p0, p1, pInsult):
# 因为取对数,因此连乘操作就变成了连续相加
p0vec = np.sum(Inputdata * p0) + np.log(pInsult)
p1vec = np.sum(Inputdata * p1) + np.log(1.0 - pInsult)
if p0vec > p1vec:
return 0
else:
return 1
def testingNB():
dataset, label = loadDataSet()
voast = createVocabList(dataset)
listnewVocaset = []
for listvocaset in dataset:
listnewVocaset.append(setword(voast, listvocaset))
p0, p1, pInsult = train(listnewVocaset, label)
Inputdata = ['eat', 'spicy', 'chicken']
Inputdata = np.array(Inputdata)
Inputdata = setword(voast, Inputdata)
print("This sentence belongs to:")
print(classiyyNB(Inputdata, p0, p1, pInsult))
testingNB()















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









