







📢📢📢📣📣📣
哈喽!大家好,我是「奇点」,江湖人称 singularity。刚工作几年,想和大家一同进步🤝🤝
一位上进心十足的【Java ToB端大厂领域博主】!😜😜😜
喜欢java和python,平时比较懒,能用程序解决的坚决不手动解决😜😜😜
✨ 如果有对【java】感兴趣的【小可爱】,欢迎关注我❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
————————————————如果觉得本文对你有帮助,欢迎点赞,欢迎关注我,如果有补充欢迎评论交流,我将努力创作更多更好的文章。
上篇我们讲到了python中常见的ORM框架,我们大致知道了python中有什么主流的ORM框架,并对不同的ORM框架的优缺点进行了比较,今天我们就来聊聊在Python中,最有名的ORM框架---SQLAlchemy。我们来看看SQLAlchemy的用法。
📖 准备工作
首先通过pip安装SQLAlchemy:
pip install sqlalchemy然后创建一个user表,用SQLAlchemy来试试:
sql创语句如下
create table user (id varchar(20) primary key, name varchar(20))第一步,导入SQLAlchemy,并初始化DBSession:
💾 简介
SQLAlchemy 是 Python SQL 工具包和对象关系映射器,它为应用程序开发人员提供了 SQL 的全部功能和灵活性。 它提供了一整套众所周知的企业级持久性模式,专为高效和高性能的数据库访问而设计,适用于简单的 Python 领域语言。
SQL 数据库的行为不像对象集合,越大和性能越重要; 对象集合的行为越不像表和行,抽象越重要。
SQLAlchemy 旨在适应这两个原则。 SQLAlchemy 认为数据库是一个关系代数引擎,而不仅仅是一个表的集合。 行不仅可以从表中选择,还可以从连接和其他选择语句中选择; 这些单元中的任何一个都可以组成一个更大的结构。 SQLAlchemy 的表达式语言从其核心建立在这个概念之上。 SQLAlchemy以其对象关系映射器(ORM)而闻名,这是一个提供数据映射器模式的可选组件,其中类可以以开放式、多种方式映射到数据库——允许对象模型和数据库模式在一个 从一开始就干净地解耦。 SQLAlchemy 解决这些问题的整体方法与大多数其他 SQL 完全不同。这是官网的介绍。看起来还是很强大的。

SQLAlchemy 是一个功能强大的Python ORM 工具包,口碑不错,社区活跃也较为开放所以我们今天就来聊一聊SqlAlchemy,Alchemy是炼金术的意思,看到没名字就这么硬气。
无论什么语言,无论什么库,做一个ORM实现,至少应当实现完全语义化的数据库操作,使得操作数据库表就像在操作对象。完整的ORM应当可以完全避免SQL拼接
一般来说SQLAlchemy的使用方式有两种: Core和ORM
两种有什么不同呢?
ORM是构建在Core之上的
Core更加底层, 可以执行直接执行SQL语句
ORM类似于Django的ORM, 由于sqlalchemy提供了一套接口, 所以不需要我们直接写SQL语句 (1.x版本)
至于要用哪个, 等到你用到时, 你会知道的
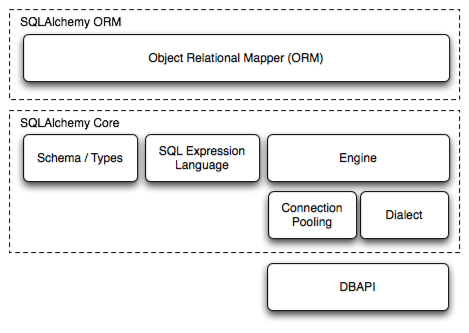
Core
一般来说, 使用步骤如下:
- 配置数据库连接
- 建立连接
- 创建表
- 执行SQL语句, 按需开启事件是否自动提交
- 拿到返回数据, 执行其他代码
这种方式使用的不多,这里主要使用的是ORM的方式
ORM方式
📚 基本概念
相关概念
| 对应数据库 | 说明 | |
| Engine | 连接 | |
| Session | 连接池、事务 | 查询的连接会话 进行数据库操作到对象 |
| Model | 表 | 类定义和表定义类似,类实例本质上是其中一行 |
| Column | 列 | 在各个地方支持运算操作 |
| Query | 若干行 | 可链式操作添加条件: 1.查看展开成Select 2.删除展开成Delete 3.改展开成Update |
概念不多而且很清晰明了,当我们理解好这些概念之后,我们基本就能看出,这里包括了我们常用的大部分操作了。
Session的作用
下面是session的一些常见的方法
| 方法 | 参数 | 描述 |
| add | instance | 下次刷新操作,将instance保存到数据库中 |
| delete | instance | 下次刷新操作,将instance从数据库中删除 |
| begin | subtransactions nested _subtrans | 开始事务 |
| rollback | 无 | 回滚当前事务 |
| commit | 无 | 提交当前事务 |
| close | 无 | 关闭此session |
| execute |
| 执行sql表达式构造 |
| query |
| 返回Query对象 可用于查询数据 |
| refresh | instance attribute_names with_for_update | 为instance执行刷新操作 |
模型定义
下面我们来看一个如何定义一个模型:
# coding=utf-8
from __future__ import unicode_literals, absolute_import
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
ModelBase = declarative_base() #<-元类
class User(ModelBase):
__tablename__ = "auth_user"
id = Column(Integer, primary_key=True)
date_joined = Column(DateTime)
username = Column(String(length=30))
password = Column(String(length=128))
# 初始化数据库连接:
engine = create_engine('mysql+mysqlconnector://root:root@localhost:3306/python_db')
# 创建DBSession类型:
DBSession = sessionmaker(bind=engine)从这里可以看到,模型定义甚至与数据库是无关的,所以允许不同的数据库后端,不同类型拥有不同的表现形式和建表语句
这里我们可以看到它实现了 ORM与数据库连接的解耦,一些数据库后端不支持的数据类型,例如Numeric类型,在sqlite中不支持,不过SQLAlchemy也能做一些兼容使用普通浮点
Model 等同于数据库的一张表
Column 显然就是这张表的一列
create_engine()用来初始化数据库连接。SQLAlchemy用一个字符串表示连接信息:
'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名'
以上代码完成SQLAlchemy的初始化和具体每个表的class定义。如果有多个表,就继续定义其他class,例如School:
class School(ModelBase):
__tablename__ = 'school'
id = ...
name = ...
你只需要根据需要替换掉用户名、口令等信息即可。
下面,我们看看如何向数据库表中添加一行记录。
增加
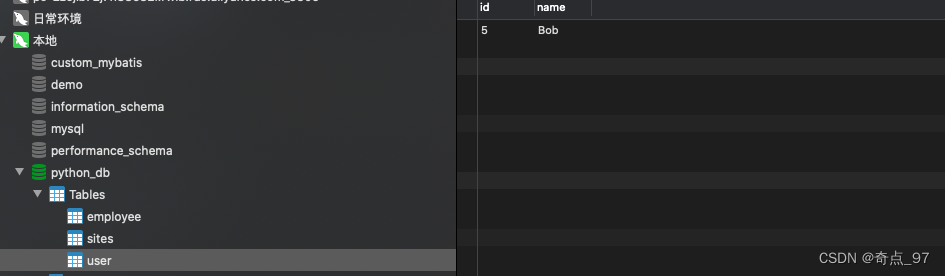
由于有了ORM,我们向数据库表中添加一行记录,可以视为添加一个User对象:
# 创建session对象:
session = DBSession()
# 创建新User对象:
new_user = User(id='5', name='Bob')
# 添加到session:
session.add(new_user)
# 提交即保存到数据库:
session.commit()
# 关闭session:
session.close()这时user表就有了bob的一条记录
可见,关键是获取session,然后把对象添加到session,最后提交并关闭。DBSession对象可视为当前数据库连接。
get_session底下configure可以控制auto_commit参数,= False时写操作默认都不放在事务里,SQLAlchemy默认为True
session.add函数将会把Model加入当前的持久空间(可以从session.dirty看到),直到commit时更新
查询
如何从数据库表中查询数据呢?有了ORM,查询出来的可以不再是tuple,而是User对象。SQLAlchemy提供的查询接口如下:
with get_session() as session:
# <class 'sqlalchemy.orm.query.Query'>
session.query(User)最简单的这个查询返回了一个Query对象
需要注意的是,这里只构造Query,事实上并没有发送至数据库进行查询,只会在Query.get()、Query.all()、Query.one()以及Query.__iter__等具有“执行”语义的函数,才会真的去获取 ,如下方法
# 创建Session:
session = DBSession()
# 创建Query查询,filter是where条件,最后调用one()返回唯一行,如果调用all()则返回所有行:
user = session.query(User).filter(User.id=='5').one()
# 打印类型和对象的name属性:
print('type:', type(user))
print('name:', user.name)
# 关闭Session:
session.close()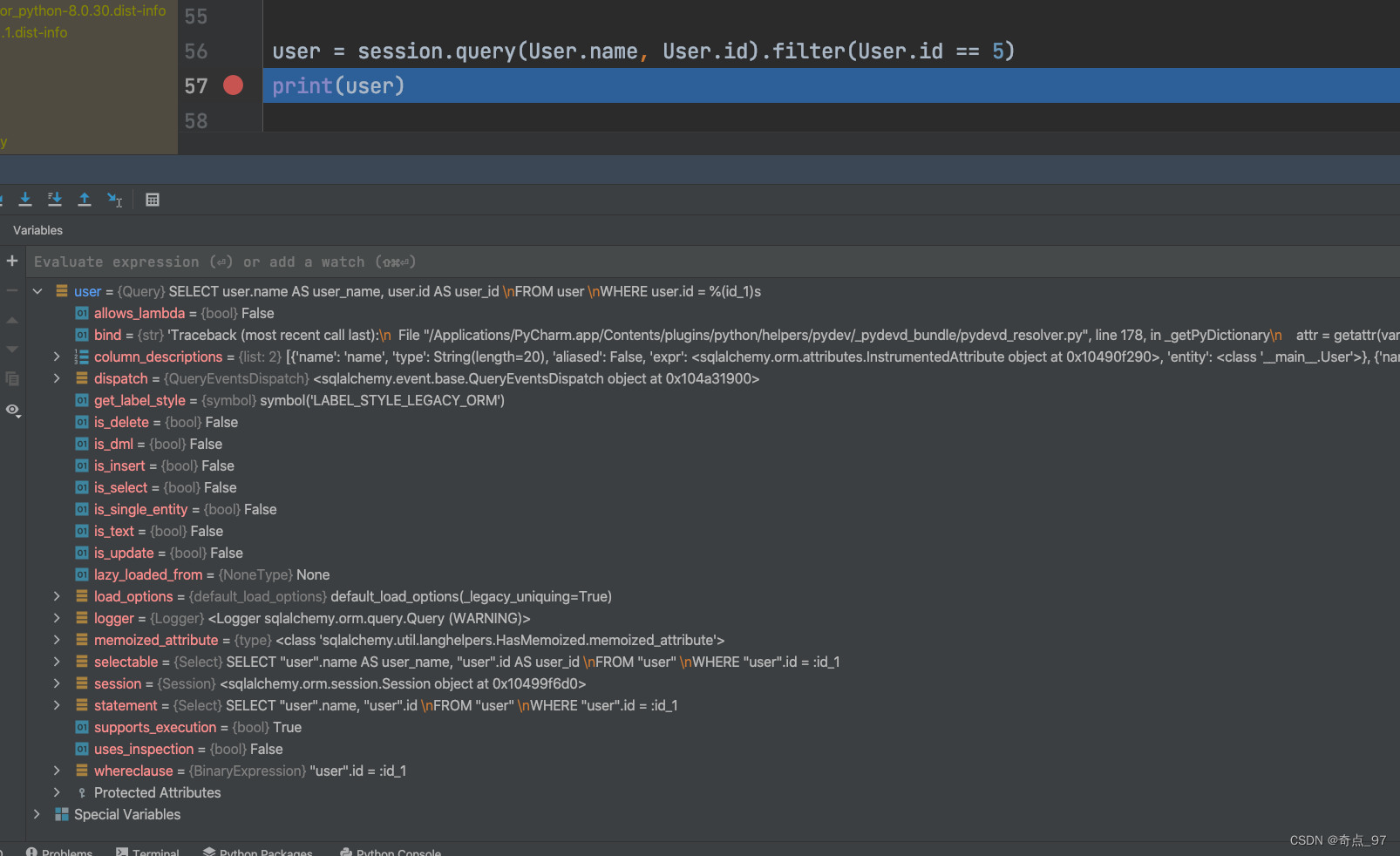
加入.one()方法之后,这里就能获取到查询的对象信息了,否则不加的话就是使用的sql语句
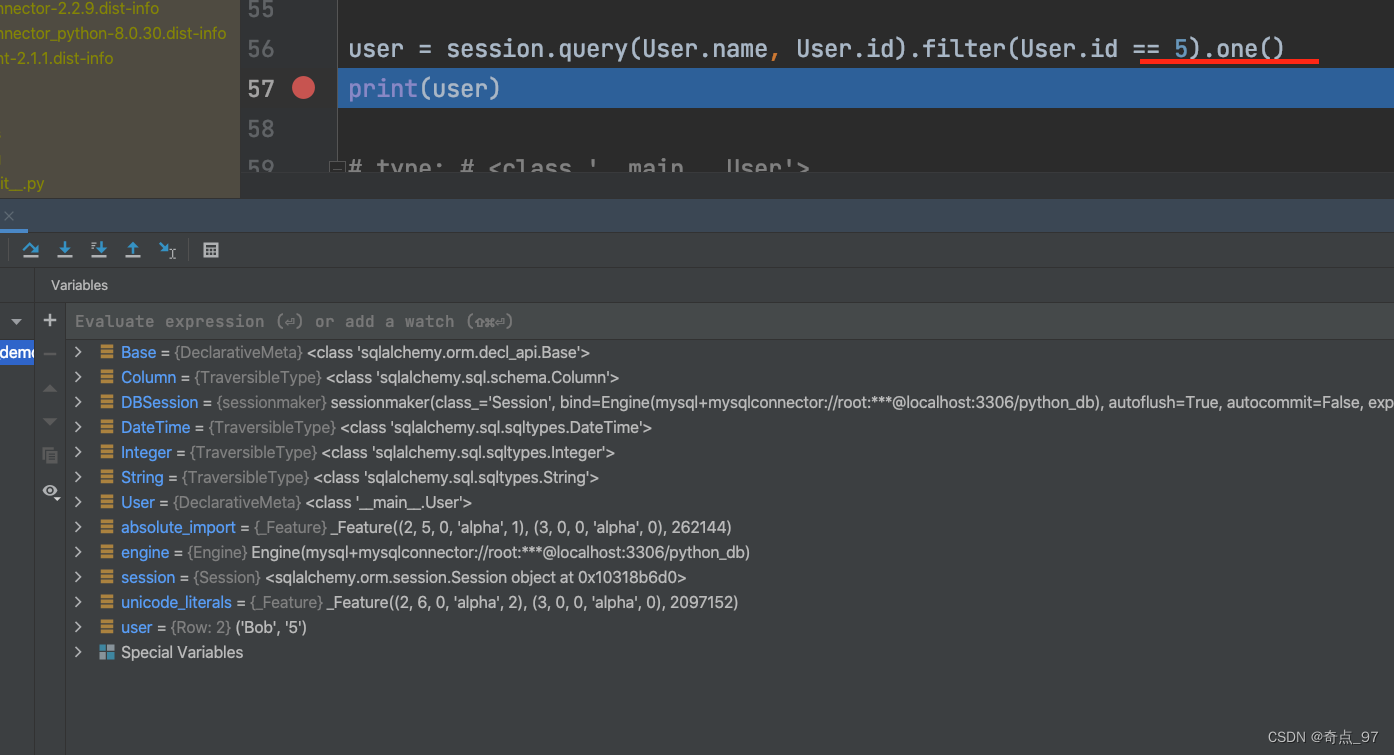
可见,ORM就是把数据库表的行与相应的对象建立关联,互相转换。
由于关系数据库的多个表还可以用外键实现一对多、多对多等关联,相应地,ORM框架也可以提供两个对象之间的一对多、多对多等功能。
例如,如果一个User拥有多个Book,就可以定义一对多关系如下:
class User(Base):
__tablename__ = 'user'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 一对多:
books = relationship('Book')
class Book(Base):
__tablename__ = 'book'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# “多”的一方的book表是通过外键关联到user表的:
user_id = Column(String(20), ForeignKey('user.id'))当我们查询一个User对象时,该对象的books属性将返回一个包含若干个Book对象的list。
Query :本质上是数据表的若干行
- 在查询情况的下,等同于SQL 中的 SELECT Syntax
- 在update函数的操作时,可以根据参数选择等同于直接UPDATE users SET xxx WHERE name=xxx或者先用SELECT 选出ID,再循环用UPDATE xxx WHERE id=xxx
- delete同上
以SQLAlchemy为代表的ORM基本都支持链式操作。
with get_session() as session:
# <class 'sqlalchemy.orm.query.Query'>
query = (session
.query(User)
.filter(User.username == "asd")
.filter_by(username="asd")
#上面两个都是添加where
.join(Addreess)#使用ForeignKey
.join(Addreess,Addreess.user_id==User.id)#使用显式声明
.limit(10)
.offset(0)
)所有Query支持的详情见Query API文档
上面也涉及到一个特别有意思的filter函数:User.username == "asd" ,实际上是SQLAlchemy重载了Column上的各种运算符 __eq__、__ge__,返回了一个BinaryExpression对象,看起来就更加符合直觉上的语义
复杂查询
基于Query的subquery
with get_session() as session:
# <class 'sqlalchemy.orm.query.Query'>
query = (session
.query(User.id)
.filter(User.name == "asd")
.filter_by(name="asd")
.limit(10)
)
subquery = query.subquery()
query2 = session.query(User).filter(
User.id.in_(subquery)
)
print query2#<-打印展开成的SQL,此处没有SQL查询
查询结果的处理:
| all() | 返回由表对象组成的列表 | |
| first() | 返回第一个结果 (表对象), 内部执行limit SQL | |
| one() | 只返回一行数据或引发异常 | 无数据时抛出: 多行数据时抛出: |
| one_or_none() | 最多返回一行数据或引发异常 | 无数据时返回None, 多行数据时抛出: sqlalchemy.exc.MultipleResultsFound |
| scalar() | 获取第一行的第一列数据. | 如果没有要获取的行, 则返回None, 多行数据时抛出: sqlalchemy.exc.MultipleResultsFound |
返回由表对象组成的列表
只返回一行数据或引发异常 (无数据时抛出: sqlalchemy.exc.NoResultFound, 多行数据时抛出: sqlalchemy.exc.MultipleResultsFound)
最多返回一行数据或引发异常 ()
scalar()
获取第一行的第一列数据. 如果没有要获取的行, 则返回None, 多行数据时抛出: sqlalchemy.exc.MultipleResultsFound
删除操作
删除操作就是先查询出对象,通过该对象再删除就Ok了, 一般形式为: session.query(...).filter(...).delete()
# 删除操作
user = session.query(
User) \
.filter(User.id == 50) \
.delete()
session.commit()
session.close()
print(user)1
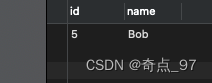
这时只剩下一个了id是50 的大bob就删除了
像Core一样删除数据, 即delte(...).where(...)
更新操作
主要步骤是先查询再更新, 即: session.query(...).filter(...).update(...)
user = session.query(User).filter(User.id == 5).update({"name": 'tom'})同样和Core一样, 使用update(...).where(...).values(...)的形式更新数据
📒扩展与深入进阶
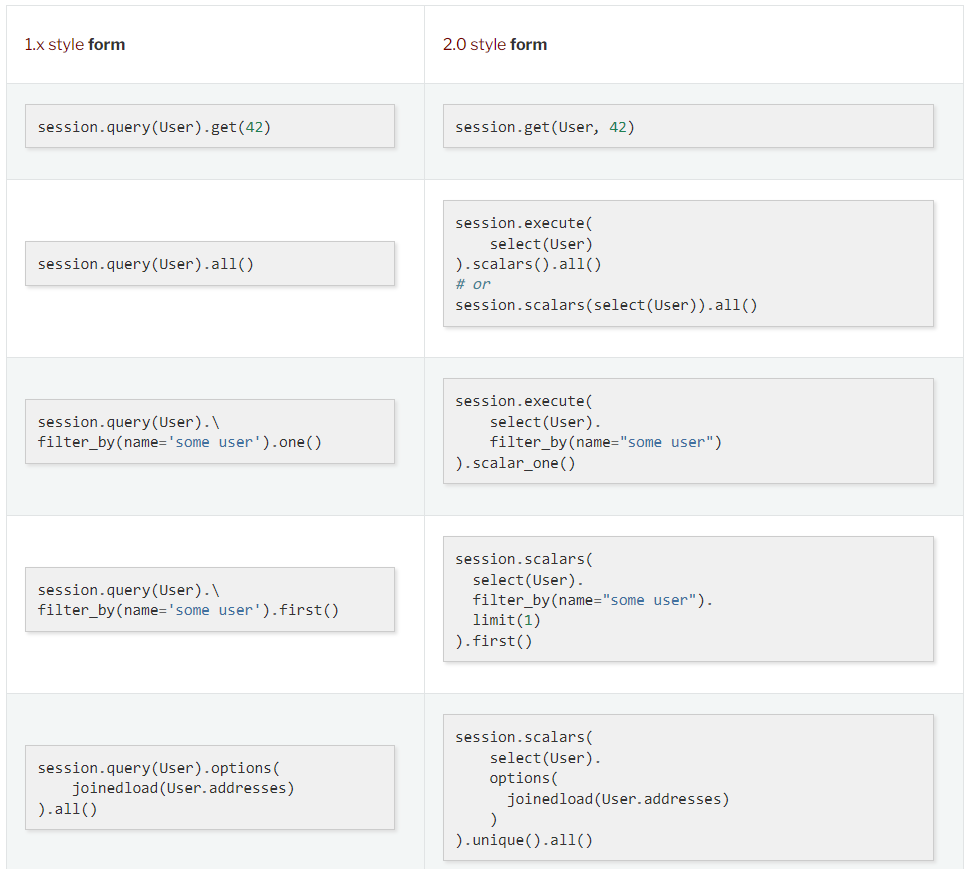
这里说说1.x和2.x方法的一些区别

如果觉得本文对你有帮助,欢迎点赞,欢迎关注我,如果有补充欢迎评论交流,我将努力创作更多更好的文章。创作不易,给博主点个小心心吧

















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











