







高级查询:
1. group_by
根据某个字段进行分组,比如说需要根据某个字段分组,来统计每组有多少人。
2. having
having是对查询结果进一步过滤,比如只想看到未成年人的数量,那么首先可以对年龄进行分组统计人数,然后再对分组进行having过滤。
3. join查询分为两种,一种是inner join, 另一种是outer join。默认的是inner join,如果指定的是left join或者right join则为outer join。如果想要查询user及其对应的address.
在数据库中插入测试数据:
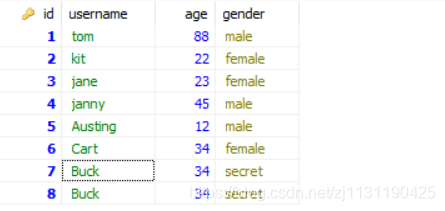
# -*- coding: utf-8 -*-
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Float, func, Enum
from sqlalchemy import Text, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship, backref
from datetime import datetime
import random
from sqlalchemy import Table
import time
HOST_NAME = "127.0.0.1"
PORT = "3306"
DATABASE = "cms"
USERNAME = "root"
PASSWORD = "root1234"
# dialect+driver://username:password@host:port/database
DB_URI = "mysql+pymysql://{username}:{password}@{host}:{port}/{database}".format(
username=USERNAME, password=PASSWORD, host=HOST_NAME, port=PORT, database=DATABASE
)
# 创建数据库引擎
engine = create_engine(DB_URI)
Base = declarative_base(engine) # 通过继承Base创建ORM模型/ 创建基类
db_session = sessionmaker(engine)() # 创建会话,才能实现增删改查
# 1. 创建ORM模型,必须继承自SQLAlchemy:
# 2. 在ORM中创建一些属性,跟表中的字段一一映射,这些属性必须是SQLAlchemy提供的数据类型
# 3. 将创建好的ORM模型映射到数据库中
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
age = Column(Integer, default=0)
gender = Column(Enum("male", "female", "secret"), default="secret")
def __repr__(self):
return str(self.id) + " | " + self.username
# Base.metadata.drop_all()
# Base.metadata.create_all()
#
# user1 = User(username="tom", age=88, gender="male")
# user2 = User(username="kit", age=22, gender="female")
# user3 = User(username="jane", age=23, gender="female")
# user4 = User(username="janny", age=45, gender="male")
# user5 = User(username="Austing", age=12, gender="male")
# user6 = User(username="Cart", age=34, gender="female")
# user7 = User(username="Buck", age=34, gender="secret")
# user8 = User(username="Buck", age=34, gender="secret")
# db_session.add_all([user1, user2, user3, user4,
# user5, user6, user7, user8])
#
# db_session.commit()
# 统计每个年龄段的人数 group_by
result = db_session.query(User.age, func.count(User.id)).group_by(User.age).all()
print(result)
# having,针对产找出来的数据进行再一层的过滤 having
result = db_session.query(User.age, func.count(User.id)).group_by(User.age).having(User.age > 20).all()
print(result)
join操作:
result = db_session.query(User.username, func.count(Article.id)).join(Article, User.id == Article.uid).group_by(User.id).order_by(func.count(Article.id)).desc().all()
print(result)subquery()实现复杂的查询:
在数据库中插入测试数据:

例如,需要查找和一个人城市相同的人,或者年龄相同的人
原生的sql语句如下所示:

多次查询虽然也可以实现子查询的功能,但是多次查询会影响数据库的性能,如果网站的访问量过大的话,会造成网站性能不好。因此应该尽量采用子查询对数据库查询进行优化。子查询能够一次完成查询,避免多次查询数据库。
在sqlalchemy中实现子查询需要通过以下几个步骤:
1. 将子查询按照传统的方式写好查询代码,然后在query对象后面执行subquery方法,将这个查询变成一个子查询
2. 在子查询中,将需要用到的字段同构label取一个别名。
3. 在父查询中,如果需要使用子查询的字段,那么可以通过子查询的变量上的c属性获得。
示例代码:
# -*- coding: utf-8 -*-
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Float, func, Enum
from sqlalchemy import Text, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship, backref
from datetime import datetime
import random
from sqlalchemy import Table
import time
HOST_NAME = "127.0.0.1"
PORT = "3306"
DATABASE = "cms"
USERNAME = "root"
PASSWORD = "root1234"
# dialect+driver://username:password@host:port/database
DB_URI = "mysql+pymysql://{username}:{password}@{host}:{port}/{database}".format(
username=USERNAME, password=PASSWORD, host=HOST_NAME, port=PORT, database=DATABASE
)
# 创建数据库引擎
engine = create_engine(DB_URI)
Base = declarative_base(engine) # 通过继承Base创建ORM模型/ 创建基类
db_session = sessionmaker(engine)() # 创建会话,才能实现增删改查
# 1. 创建ORM模型,必须继承自SQLAlchemy:
# 2. 在ORM中创建一些属性,跟表中的字段一一映射,这些属性必须是SQLAlchemy提供的数据类型
# 3. 将创建好的ORM模型映射到数据库中
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
age = Column(Integer, default=0)
city = Column(String(50), nullable=False)
def __repr__(self):
return str(self.id) + " | " + self.username + " | " + str(self.age) + " | " + self.city
# Base.metadata.drop_all()
# Base.metadata.create_all()
#
# user1 = User(username="tom", age=88, city="北京")
# user2 = User(username="kit", age=22, city="上海")
# user3 = User(username="jane", age=23, city="常山")
# user4 = User(username="janny", age=45, city="长沙")
# user5 = User(username="Austing", age=12, city="香港")
# user6 = User(username="Cart", age=34, city="西安")
# user7 = User(username="Buck", age=34, city="上海")
# user8 = User(username="Buck", age=34, city="北京")
# db_session.add_all([user1, user2, user3, user4,
# user5, user6, user7, user8])
#
# db_session.commit()
# 两次查询的方式得到结果,效率低
user = db_session.query(User).filter(User.username == "tom").first()
users = db_session.query(User).filter(User.city == user.city).all()
print(users)
# 通过子查询的方式实现
# 通过.label()给查询到的字段起一个新的名字
sub_res = db_session.query(User.city.label("city")).filter(User.username == "tom").subquery()
res = db_session.query(User).filter(User.city == sub_res.c.city)
print(res)
Flask-sqlalchemy插件介绍:
flask-sqlalchemy相当于将sqlalchemy结合到flask中,并且对初始化数据,连接数据库,以及一些包的导入统一做了封装,进行进一步的简化,使得更加易于使用。
1. 数据库连接
定义好数据库连接字符串:
from flask import Flask, url_for
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
HOST_NAME = "127.0.0.1"
PORT = "3306"
DATABASE = "cms"
USERNAME = "root"
PASSWORD = "root1234"
# dialect+driver://username:password@host:port/database
DB_URI = "mysql+pymysql://{username}:{password}@{host}:{port}/{database}".format(
username=USERNAME, password=PASSWORD, host=HOST_NAME, port=PORT, database=DATABASE
)
app.config["SQLALCHEMY_DATABASE_URI"] = DB_URI
db = SQLAlchemy(app) # 初始化数据库
app.config["TEMPLATE_AUTO_RELOAD"] = True
2. 创建orm模型
不需要再创建基类,不需要再导入各种数据类型,直接使用db下面相应的属性名即可
3. 将orm模型映射到数据库
省略
4. 使用session
省略
5. 查询数据
from flask import Flask, url_for
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
HOST_NAME = "127.0.0.1"
PORT = "3306"
DATABASE = "flask_sqlalchemy"
USERNAME = "root"
PASSWORD = "root1234"
# dialect+driver://username:password@host:port/database
DB_URI = "mysql+pymysql://{username}:{password}@{host}:{port}/{database}".format(
username=USERNAME, password=PASSWORD, host=HOST_NAME, port=PORT, database=DATABASE
)
app.config["SQLALCHEMY_DATABASE_URI"] = DB_URI
app.config["TEMPLATE_AUTO_RELOAD"] = True
db = SQLAlchemy(app) # 初始化数据库
class Person(db.Model):
__tablename__ = "person"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(50), nullable=False)
def __repr__(self):
return str(self.id) + " | " + self.name
db.drop_all()
db.create_all()
p1 = Person(name="zhang")
p2 = Person(name="wang")
db.session.add(p2)
db.session.commit()
res = db.session.query(Person).all()
print([p for p in res])
@app.route('/')
def hello_world():
print(url_for("news.news_list"))
return 'Hello World!'
if __name__ == '__main__':
app.run(debug=True)
在flask-sqlalchemy中,__tablename__也可以省略不写,会自动进行添加(但是不推荐这种写法)
alembic数据库迁移工具基本使用:
在使用sqlalchemy的过程中,在定义好orm模型之后,是通过.create_all()方法进行数据表的创建,创建好之后的不能再进行变更。但是在实际的开发中,可能需要在已经创建好的数据表中删除或者增加字段,而alembic就可以解决表之间的映射问题。对于orm模型新增的字段,如果要将新增字段映射到数据表中,就需要通过alembic工具进行。
alembic的使用方式优点类似于git,第一:所有命令以alembic开头,第二:alembic的迁移文件也是通过版本进行控制的。通过pip install alembic进行安装。
alembic使用:
1. 初始化alembic仓库,在pycharm中右键项目文件,选择open in terminate, 打开项目终端

初始化alembic仓库之后,会在项目文件夹中生成一个alembic文件夹:

2. 创建模型类。创建一个models.py文件,然后定义模型类:
# -*- coding: utf-8 -*-
from sqlalchemy import Column, String, Integer, create_engine, Text
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship, backref
HOST_NAME = "127.0.0.1"
PORT = "3306"
DATABASE = "alembic_demon"
USERNAME = "root"
PASSWORD = "root1234"
# dialect+driver://username:password@host:port/database
DB_URI = "mysql+pymysql://{username}:{password}@{host}:{port}/{database}".format(
username=USERNAME, password=PASSWORD, host=HOST_NAME, port=PORT, database=DATABASE
)
# 创建数据库引擎
engine = create_engine(DB_URI)
Base = declarative_base(engine) # 通过继承Base创建ORM模型/ 创建基类
db_session = sessionmaker(engine)() # 创建会话,才能实现增删改查
# 1. 创建ORM模型,必须继承自SQLAlchemy:
# 2. 在ORM中创建一些属性,跟表中的字段一一映射,这些属性必须是SQLAlchemy提供的数据类型
# 3. 将创建好的ORM模型映射到数据库中
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
password = Column(String(100), nullable=False)
age = Column(Integer, default=0)
country = Column(String(50), nullable=False)
def __repr__(self):
return str(self.id) + " | " + self.username
# class Article(Base):
# __tablename__ = "article"
# id = Column(Integer, primary_key=True, autoincrement=True)
# title = Column(String(100), nullable=False)
# content = Column(Text, nullable=False)
# ROM->迁移脚本->映射到数据库中
3. 修改配置文件:
在alembic.ini中设置数据库连接,设置的格式为:
sqlalchemy.url = driver://user:pass@localhost/dbname
sqlalchemy.url = mysql+pymysql://root:root1234@localhost/alembic_demon?charset=utf8
# 指定连接数据的方式为了使得模型类能够更新到数据库当中,需要在env.py中设置target_metadata,默认target_metadata=None,需要使用sys啊把当前的项目路基那个导入到path中:
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(__file__))) # 添加models的路径
import models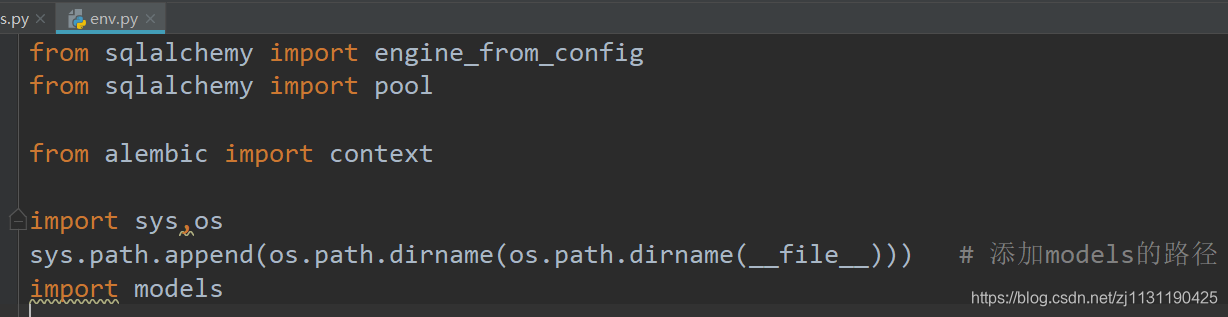
target_metadata = models.Base.metadata4. 自动生成迁移脚本,通过下面的命令:
alembic revision --autogenerate -m "message"
在生成迁移脚本的时候,出现了如下的报错:

应该是某处的编码问题,查找报错的文件,发现在下面这个地方调用了一个read()方法:
![]()

需要将read()方法的encoding参数修改为utf8.
还有这个地方,也调用了read()方法
![]()
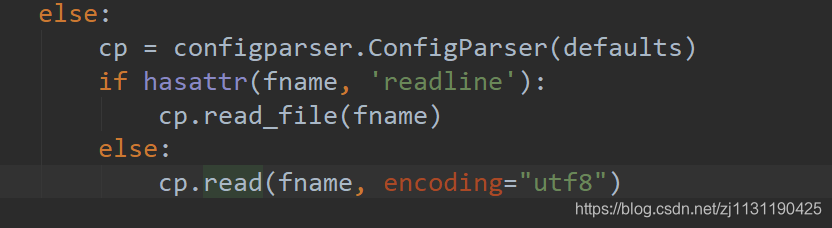
将encoding参数修改为utf8.
anaconda/Lib/configeparser中定义了这个read()方法:这里的read()方法有一个参数encoding:

此时,调用迁移脚本生成命令:

此时在alembic/versions目录下会生成迁移脚本:
5. 更新数据库:
alembic upgrade head
6. 如果需要在数据表中添加新的字段,则首先对orm模型进行修改,重复4,5步骤
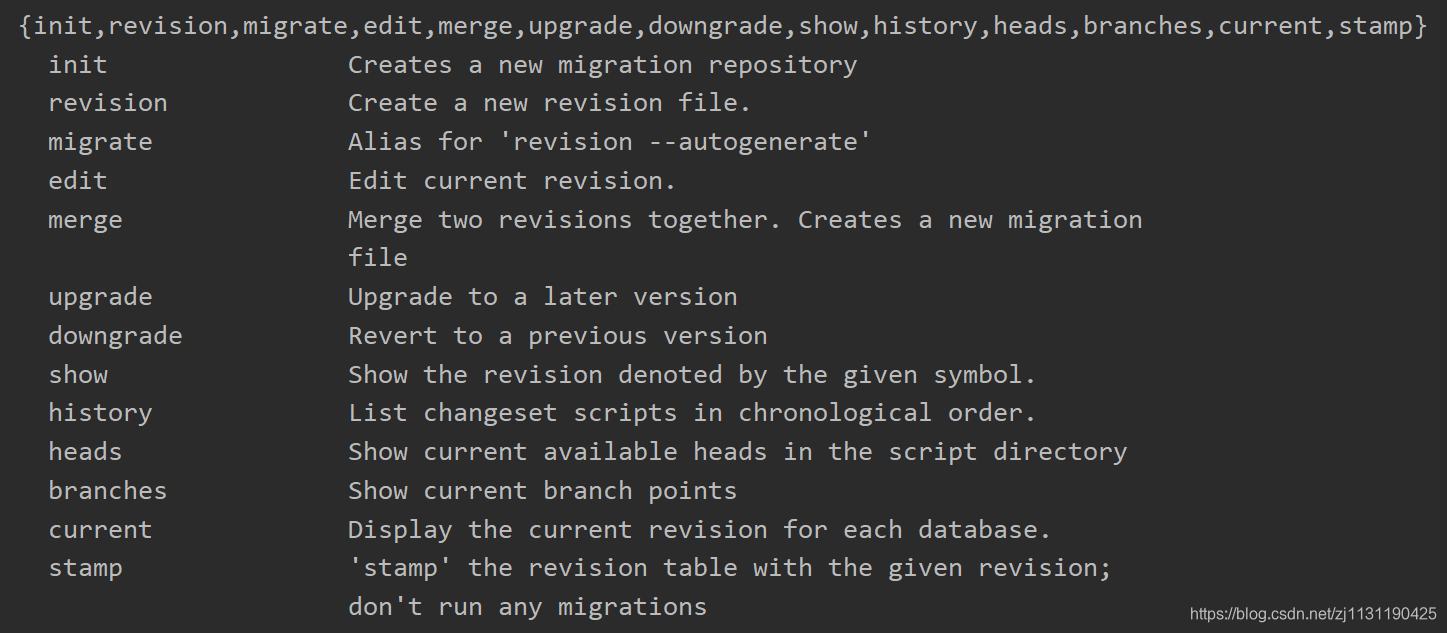
命令和参数:
1. init:创建一个alembic仓库。
2. revision:创建一个新的版本文件。
3. --autogenerate:自动将当前模型的修改,生成迁移脚本。
4. -m:本次迁移做了哪些修改,用户可以指定这个参数,方便回顾。
5. upgrade:将指定版本的迁移文件映射到数据库中,会执行版本文件中的upgrade函数。如果有多个迁移脚本没有被映射到数据库中,那么会执行多个迁移脚本。
6. [head]:代表最新的迁移脚本的版本号。
7. downgrade:会执行指定版本的迁移文件中的downgrade函数。
8. heads:展示head指向的脚本文件版本号。
9. history:列出所有的迁移版本及其信息。
10. current:展示当前数据库中的版本号。
alembic中的经典错误:
1. FAILED: Target database is not up to date.
原因:主要是heads和current不相同。current落后于heads的版本。
解决办法:将current移动到head上。alembic upgrade head
2. FAILED: Can't locate revision identified by '77525ee61b5b'
原因:数据库中存的版本号不在迁移脚本文件中
解决办法:删除数据库的alembic_version表中的数据,重新执行alembic upgrade head
3. 执行`upgrade head`时报某个表已经存在的错误:
原因:执行这个命令的时候,会执行所有的迁移脚本,因为数据库中已经存在了这个表。然后迁移脚本中又包含了创建表的代 码。
解决办法:(1)删除versions中所有的迁移文件。(2)修改迁移脚本中创建表的代码,使用pass语句
Flask-SqlAlchemy下使用alembic:
使用alembic管理Flask项目下的数据库:
1. 在Flask项目下打开终端
2. 创建初始的alembic仓库
3. 修改配置文件
alembic.ini文件修改方法不变
env.py文件中导入app文件的路径,以及app文件:
import os
import sys
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
import app
target_metadata = app.db.Model.metadata # 完成绑定后面生成迁移脚本以及映射数据库的方法不变。
Fask-script插件介绍:
Falsk-script的作用是可以通过命令行的形式来操作flask,例如通过命令跑一个开发版的服务器,设置数据库,定时任务等。可以通过pip install flask-script来安装。
flask-script使用:
通过新建manager.py文件,导入Manager和新建manager
from flask_script import Manager
manager = Manager(app)
# 没有参数
@manager.command
def greet():
print("Hello")
if __name__ == "__main__":
manager.run()在命令行中通过如下的命令直接运行greet()函数:![]()
如果函数中有参数,需要使用option装饰器进行传参,有几个参数就用几个option装饰器
# 如果需要传递参数,则需要使用option装饰器
@manager.option("-u", "--username", dest="username")
@manager.option("-a", "--age", dest="age")
def info_list(username, age):
print("The name is {}, and the age is".format(username, age))option中,第一个参数为命令行中参数的简写,第二个为命令行中的参数,第三个参数是接受参数值的变量。
通过如下的命令运行info_list()函数:
![]()
实际应用,例如要给CMS管理系统添加一个管理员:
1. 首先创建数据库,这里使用alembic实现,回顾一下前面的知识
from flask import Flask, url_for
from flask_sqlalchemy import SQLAlchemy
import config
app = Flask(__name__)
app.config.from_object(config)
db = SQLAlchemy(app) # 初始化数据库
class BackEndUser(db.Model):
__tablename__ = "back_user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
username = db.Column(db.String(50), nullable=False)
email = db.Column(db.String(50), nullable=False)
@app.route('/')
def hello_world():
print(url_for("news.news_list"))
return 'Hello World!'
if __name__ == '__main__':
app.run(debug=True)
2. 使用flask-script定义数据插入的函数:
# -*- coding: utf-8 -*-
from app import app, BackEndUser, db
from flask_script import Manager
manager = Manager(app)
@manager.option("-u", "--username", dest="username")
@manager.option("-e", "--email", dest="email")
def add_backend_user(username, email):
user = BackEndUser(username=username, email=email)
db.session.add(user)
db.session.commit()
if __name__ == "__main__":
manager.run()
3. 通过命令调用:
![]()
查看插入的数据:

这种添加管理员的方式,更加的安全与优雅
-------------------------------------------------------------------------------------------------------------------------------------------------
可以用flask-script对数据库的操作进行统一的管理,例如,创建db_manage.py文件,用于对数据库操作的方法做统一的封装:
# -*- coding: utf-8 -*-
from flask_script import Manager
db_manager = Manager()
@db_manager.command
def init():
print("数据库初始化创建完成")
@db_manager.command
def revision():
print("迁移脚本初始化完成")
@db_manager.command
def upgrade():
print("数据库映射完成")
再将创建的db_manager添加到主Manager中,在manager.py文件中加入如下的代码即可:
from db_manager import db_manager
manager = Manager(app)
manager.add_command("db", db_manager) # 添加子命令
然后通过下面的命令就可以调用db下面的子命令:
![]()
项目结构重构:
flask-migrate插件,底层基于alembic,相当于对alembic进行了一层封装,并集成到flask中,使用起来更加方便,类似于SQLAlchemy和flask-sqlalchemy。
python中的循环引用:创建一个第三方的文件,避免循环引用
例如,下面的app文件和models文件,models文件需要导入app文件中的db,app文件需要到models文件中User,就会造成文件之间循环引用的问题:

app.py文件:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
import config
from models import User
app = Flask(__name__)
app.config.from_object(config)
db = SQLAlchemy(app)
@app.route('/')
def hello_world():
return 'Hello World!'
@app.route('/profile/')
def profile():
return "profile page"
if __name__ == '__main__':
app.run()
models.py文件:
# -*- coding: utf-8 -*-
from app import db
class User(db.Model):
__tablename__ = "user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
username = db.Column(db.String(50), nullable=False)
这样就会报错:

解决方案:
创建一个第三方的文件:
例如新建exts.py文件,就可以解决循环引用的问题:
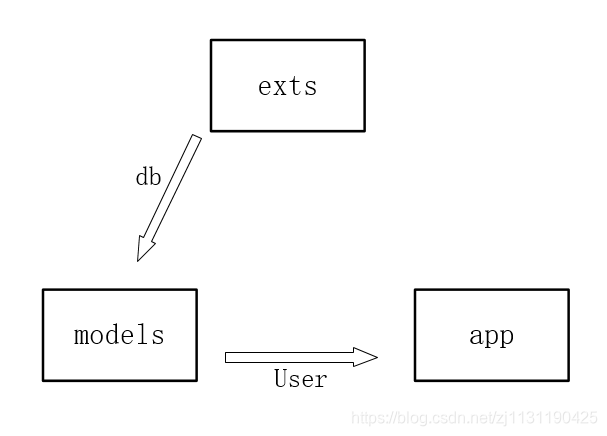
exts.py文件:
# -*- coding: utf-8 -*-
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy() # db没有绑定app,此时db就拿不到app中数据库的配置文件
models.py文件:
# -*- coding: utf-8 -*-
from exts import db
class User(db.Model):
__tablename__ = "user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
username = db.Column(db.String(50), nullable=False)
app.py文件:
from flask import Flask
import config
from models import User
from exts import db
app = Flask(__name__)
app.config.from_object(config)
db.init_app(app) # db获取app中数据库的连接方式
@app.route('/')
def hello_world():
return 'Hello World!'
@app.route('/profile/')
def profile():
return "profile page"
if __name__ == '__main__':
app.run()
Flask-migrate详细介绍:
在实际的开发环境中,经常需要去修改数据库的行为,一般不回去直接修改数据库,而是将数据库的ORM模型进行修改,然后再把模型映射到数据库中。利用前面介绍的alembic可以实现此功能。在flask中,通过flask-migrate实现此功能,flask-migrate是基于alembic的一个封装,并将其集成到flask中。因此所有的数据库迁移操作以及上都是通过alembic完成的。
安装:pip install flask-migrate
实际使用:
基于上面的工程,新建一个manager.py的文件:
# -*- coding: utf-8 -*-
from flask_script import Manager
from app import app
from flask_migrate import MigrateCommand, Migrate # 用来绑定app以及db
from exts import db
manager = Manager(app) # 绑定app,db到flask-migrate
Migrate(app=app, db=db)
# 添加falsk-migrate中子命令到db下:
manager.add_command("db", MigrateCommand)
if __name__ == "__main__":
manager.run()
flask-migrate 常用命令:
1. python manager.py db init
初始化一个alembic仓库在项目文件夹下会生成一个Migration文件夹:其中的文件与alembic init alembic命令生成的类似
2. python manager.py db migrate 生成数据库的迁移文件
3. pyhon manager.py db upgrade 将迁移文件映射到数据库当中
如果需要修改模型,则重复2,3步骤即可
可以通过python manager.py db --help查看所有命令
flask-migrate注意事项:
from models import User # 将需要映射的模型直接导入manager.py中即可














 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









