






 本文详细描述了如何使用Docker编译并部署Hadoop3.3.6集群,包括创建自定义网络my-net,配置环境变量,HDFS和YARN的相关设置,以及容器间的通信和端口映射。
本文详细描述了如何使用Docker编译并部署Hadoop3.3.6集群,包括创建自定义网络my-net,配置环境变量,HDFS和YARN的相关设置,以及容器间的通信和端口映射。
docker 编译hadoop 和 docker 创建一个新的网段,取名为 my-net 详见
Hadoop 集群至少3台服务器(或至少3个docker容器实例)
为了保证数据的可靠性和完整性,Hadoop的分布式存储系统要求每个文件至少应有三个副本。因此,至少需要三台DataNode主机来满足这一需求。
启动容器
hadoop01
docker run --name hadoop01 --hostname=hadoop01 -d -v /Users/zhanglianming/workspace/Docker/ssh:/root/.ssh -v /Users/zhanglianming/workspace/Docker/hadoop:/root/hadoop --privileged --network=my-net -p 10022:22 iwill220182/anolisos-hadoop3.3.6:v1.0 /usr/sbin/inithadoop02
docker run --name hadoop02 --hostname=hadoop02 -d -v /Users/zhanglianming/workspace/Docker/ssh:/root/.ssh -v /Users/zhanglianming/workspace/Docker/hadoop:/root/hadoop --privileged --network=my-net -p 10023:22 iwill220182/anolisos-hadoop3.3.6:v1.0 /usr/sbin/inithadoop03
docker run --name hadoop03 --hostname=hadoop03 -d -v /Users/zhanglianming/workspace/Docker/ssh:/root/.ssh -v /Users/zhanglianming/workspace/Docker/hadoop:/root/hadoop --privileged --network=my-net -p 10024:22 iwill220182/anolisos-hadoop3.3.6:v1.0 /usr/sbin/init
上面每个容器实例都挂载了两个目录
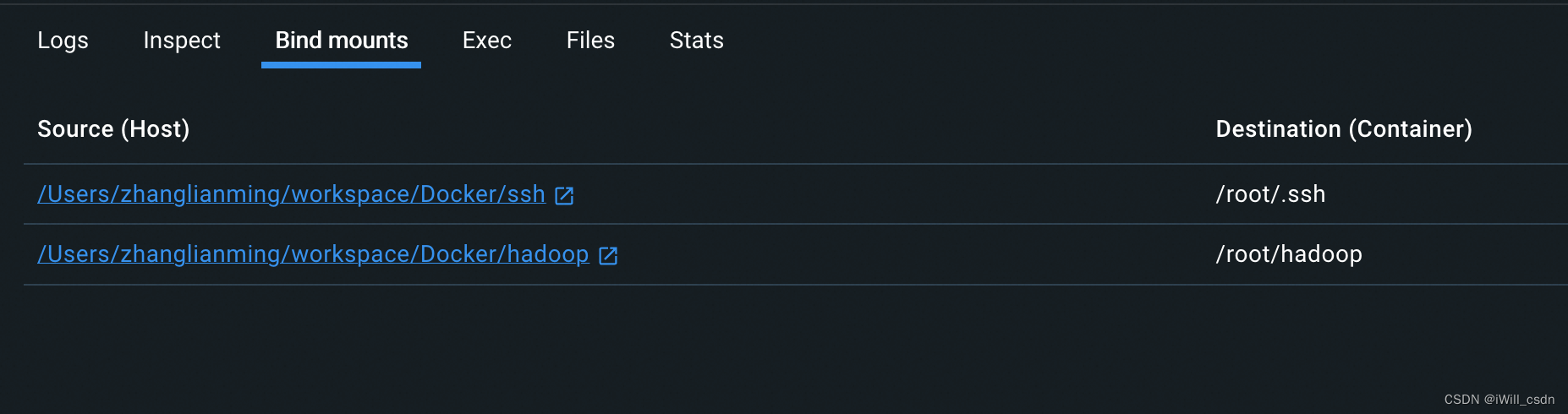
/root/hadoop 主要从本地宿主机获取一下文件,比如修改好的配置
/root/.ssh 放置一下内容,用来解决node节点间通信需要的ssh密钥(是为了偷懒)

使用 docker network inspect bigdata 查看网段内的容器进行验证:
docker network inspect my-net输出
[
{
"Name": "my-net",
"Id": "41ce032bdf2a4a4e38d5cca8121c08d72c373d72b711b812615e401ef6497b70",
"Created": "2024-01-11T12:04:05.155861138Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"3c05748ea1be28e9e45052104bf06f87a3bdfeb0f57bf061cba5f4a368468321": {
"Name": "hadoop2",
"EndpointID": "fb5e5fecd703b91b943dcf69de6717a07e947da43ebe0fe80742e962c4b8a62d",
"MacAddress": "02:42:ac:12:00:03",
"IPv4Address": "172.18.0.3/16",
"IPv6Address": ""
},
"44c5c5ae915ed61b2248aaec2f460f013aaf8d5a2456c3035b874609ac404395": {
"Name": "hadoop",
"EndpointID": "b1194b0fee5e957131419cffc7161baa97f981b1154ea6921ac73fe94c037f7c",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
},
"c8095a8b8fd1233a2a23a61239c99ac7b4332ec74c8c761199255d0ab1a1b1c7": {
"Name": "hadoop3",
"EndpointID": "3f4144f47a5b30f1e84ba2c050c1d9ba23c258440021ae445283d02a4dbfb95e",
"MacAddress": "02:42:ac:12:00:04",
"IPv4Address": "172.18.0.4/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]环境变量及配置
以下配置环境变量在所有容器实例都要配置和设置。
修改环境变量
export HADOOP_HOME=/opt/hadoop-3.3.6/
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH修改host文件
172.18.0.2 hadoop01
172.18.0.3 hadoop02
172.18.0.4 hadoop03修改配置
代码设置
*-site.xml
*-default.xml
要实现完全分布式的配置,需要配置以下文件:
- hadoop-env.sh
- yarn-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
在Hadoop安装完成后,会在$HADOOP_HOME/share路径下,有若干个*-default.xml文件,这些文件中记录了默认的配置信息。同时,在代码中,我们也可以设置Hadoop的配置信息。这些位置配置的Hadoop,
优先级为: 代码设置 > *-site.xml > *-default.xml
本次部署的集群规划如下:
| Node | Applications |
| hadoop01 | NameNode、DataNode、ResourceManager、NodeManager |
| hadoop02 | SecondaryNameNode、DataNode、NodeManager |
| hadoop03 | DataNode、NodeManager |
mkdir -p /home/admin/hadoop/tmp
cd $HADOOP_HOME/etc/hadoop/
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/admin/hadoop/tmp</value>
</property>
</configuration>fs.defaultFS:HDFS对外提供服务的主机及端口号
hdfs-site.xml
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:50070</value>
</property>
</configuration>dfs.namenode.name.dir:fsimage存储的位置
dfs.datanode.data.dir:块的存储位置
dfs.replication:HDFS为了保证属性不丢失,会保存块的副本
dfs.blocksize:块大小,在hadoop1.x版本中为64M,在hadoop2.x的版本汇总默认128M
dfs.namenode.secondary.http-address:指定secondarynamenode的节点服务器位置
dfs.namenode.http-address:webui查看时的地址端口
mapred-site.xml
<configuration>
<!-- 指定mapreduce使用yarn资源管理器-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置作业历史服务器的地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- 配置作业历史服务器的http地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6</value>
</property>
</configuration>yarn-site.xml
<configuration>
<!-- 指定yarn的shuffle技术-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!--下面的可选-->
<!--指定shuffle对应的类 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--配置resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:8032</value>
</property>
<!--配置resourcemanager的scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:8030</value>
</property>
<!--配置resoucemanager的资源调度的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:8031</value>
</property>
<!--配置resourcemanager的管理员的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:8033</value>
</property>
<!--配置resourcemanager的web ui 的监控页面-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8088</value>
</property>
</configuration>hadoop-env.sh
配置hadoop运行的jdk环境路径
export JAVA_HOME=/opt/jdk1.8.0_391yarn-env.sh
配置yarn运行的jdk环境路径
export JAVA_HOME=/opt/jdk1.8.0_391workers
配置集群的从节点
vim workers
hadoop01
hadoop02
hadoop03分发配置到其他容器
格式化
如果之前格式化过集群,需要删除上次配置的hadoop.tmp.dir属性对应位置的tmp文件夹,hadoop.tmp.dir属性值见core-site.xml文件
在hadoop01上运行
hdfs namenode -format格式化信息解读
生成一个集群唯一标识符:clusterid
生成一个块池唯一标识符:blockPoolId
生成namenode进程管理内容(fsimage)的存储路径:
默认配置文件属性hadoop.tmp.dir指定的路径下生成dfs/name目录
生成镜像文件fsimage,记录分布式文件系统根路径的元数据
他信息都可以查看一下,比如块的副本数,集群的fsOwner等。
目录所在位置及内容查看
/home/admin/hadoop/tmp/dfs/name/current

启动集群
增加容器实例端口映射
发现容器实例需要增加使用的端口映射
hadoop 增加如下端口
9864:9864
8020:8020
8030:8030
8031:8031
8032:8032
8033:8033
8088:8088
50070:50070
10020:10020
19888:19888
hadoop2 增加如下端口
50090:50090
hadoop3 增加如下端口
1. 启动脚本
-- start-dfs.sh :用于启动hdfs集群的脚本
-- start-yarn.sh :用于启动yarn守护进程
-- start-all.sh :用于启动hdfs和yarn
2. 关闭脚本
-- stop-dfs.sh :用于关闭hdfs集群的脚本
-- stop-yarn.sh :用于关闭yarn守护进程
-- stop-all.sh :用于关闭hdfs和yarn
3. 单个守护进程脚本
-- hadoop-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
-- hadoop-daemon.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
reg:
hadoop-daemon.sh [start|stop] [namenode|datanode|secondarynamenode]
-- yarn-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
-- yarn-daemon.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
reg:
yarn-daemon.sh [start|stop] [resourcemanager|nodemanager]修改环境变量
以 root 用户身份操作 HDFS 的 Namenode, 没有定义 HDFS_NAMENODE_USER 环境变量,会报错
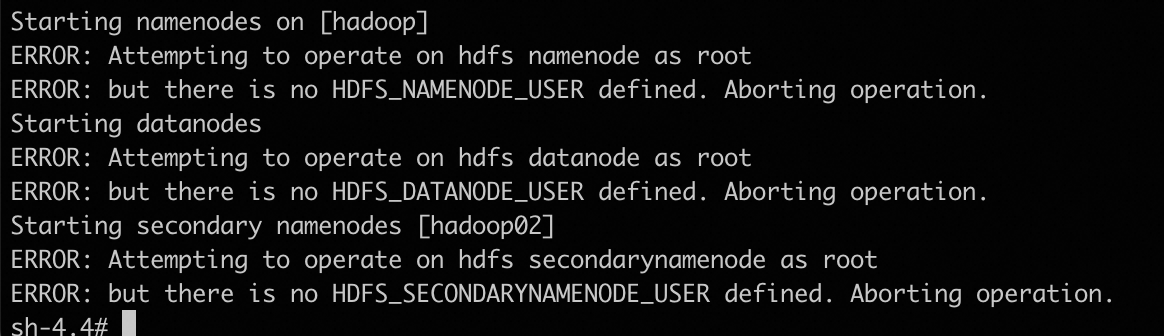
Starting namenodes on [hadoop]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [hadoop02]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootsource/etc/profile.d/my_env.sh启动HDFS
使用start-dfs.sh,启动hdfs
- 启动集群中的各个机器节点上的分布式文件系统的守护进程
一个namenode和resourcemanager以及secondarynamenode
多个datanode和nodemanager
- 在namenode守护进程管理内容的目录下生成edit日志文件
- 在每个datanode所在节点下生成${hadoop.tmp.dir}/dfs/data目录,参考下图:注意! 如果哪台机器的相关守护进程没有开启,那么,就查看哪台机器上的守护进程对应的日志log文件,注意,启动脚本运行时提醒的日志后缀是*.out,而我们查看的是*.log文件。此文件的位置:${HADOOP_HOME}/logs/里
[root@44c5c5ae915e sbin]# ./start-dfs.sh
Starting namenodes on [hadoop]
Last login: Sat Jan 27 07:06:08 UTC 2024 on pts/1
hadoop: namenode is running as process 2924. Stop it first and ensure /tmp/hadoop-root-namenode.pid file is empty before retry.
Starting datanodes
Last login: Sat Jan 27 07:12:00 UTC 2024 on pts/1
hadoop03: WARNING: /opt/hadoop-3.3.6/logs does not exist. Creating.
hadoop02: WARNING: /opt/hadoop-3.3.6/logs does not exist. Creating.
hadoop01: datanode is running as process 3115. Stop it first and ensure /tmp/hadoop-root-datanode.pid file is empty before retry.
Starting secondary namenodes [hadoop02]
Last login: Sat Jan 27 07:12:01 UTC 2024 on pts/1jps查看进程
hadoop01
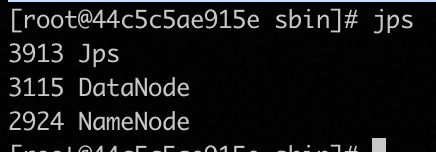
hadoop02
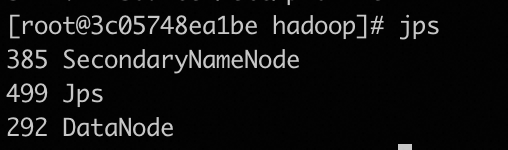
hadoop03
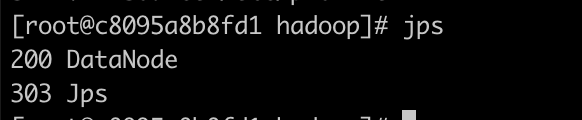
启动yarn
使用start-yarn.sh脚本
[root@44c5c5ae915e sbin]# ./start-yarn.sh
Starting resourcemanager
Last login: Sat Jan 27 07:12:03 UTC 2024 on pts/1
Starting nodemanagers
Last login: Sat Jan 27 07:23:03 UTC 2024 on pts/1jps查看进程
hadoop01

hadoop02

hadoop03
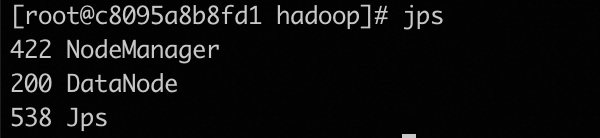
web UI查看
HDFS

YARN
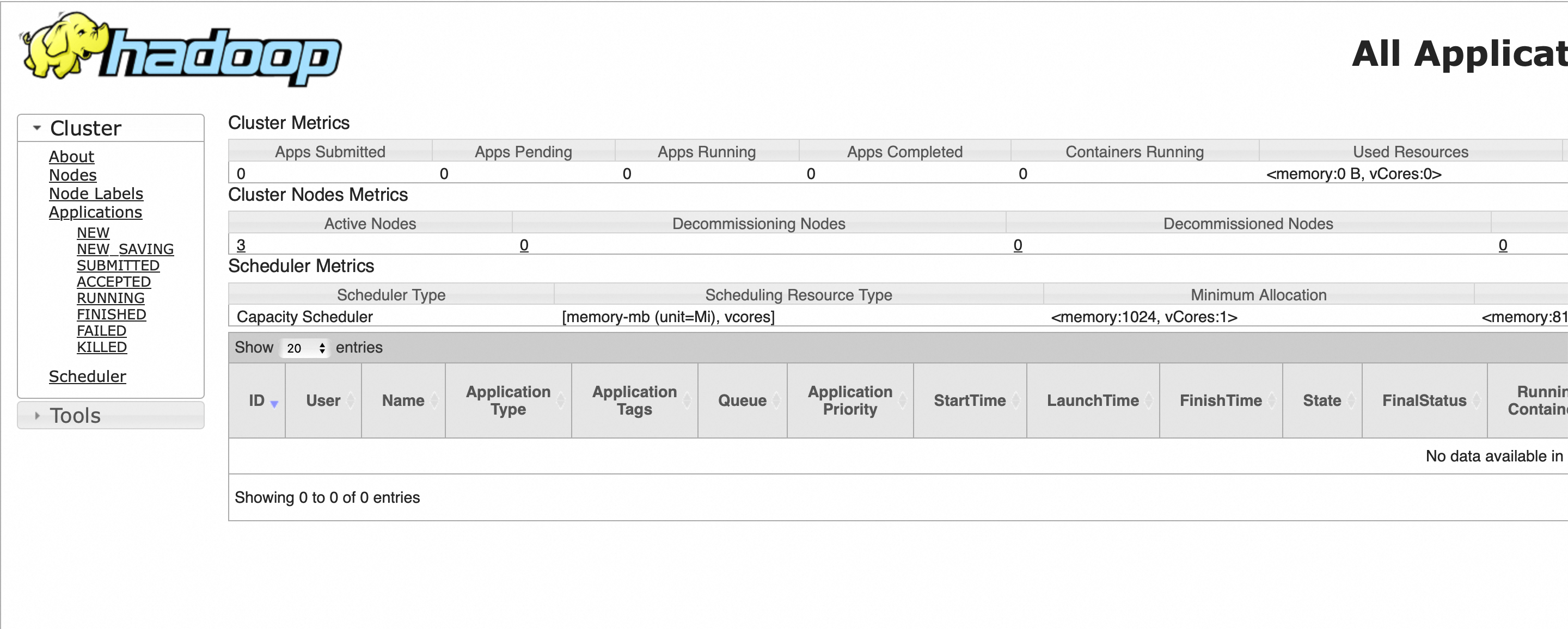
其他
Mac 系统修改 Docker 容器实例的端口号
linux 比较容易,网上很多资料。
查看容器实例id
docker ps -a
找到完整的实例id
docker inspect 44c5c5ae915e | grep Id
MAC OS中,docker有两层虚拟机,一层是docker本身的虚拟层(linux),然后是docker里容器的虚拟层,所以网上文章提到的/var/lib/docker 文件夹在MAC系统中是找不到的。下面记录如何在mac系统中修改配置文件。
停止容器
进入docker虚拟的linux
cd ~/Library/Containers/com.docker.docker/Data/vms/0/目录中,有一个tty文件,可以通过这个文件登录到docker内部的linux:
1.如果没有tty文件或者执行出现screen is terminating这个提示,进行如下处置
docker run -it --privileged --pid=host justincormack/nsenter1执行成功后会进入容器
2.screen tty 执行成功也会进入容器
后续步骤两者相同如下:
cd /var/lib/docker/containers && ls
cd 44c5c5ae915ed61b2248aaec2f460f013aaf8d5a2456c3035b874609ac404395修改config.v2.json和hostconfig.json文件对应的端口映射部分
⑴ 修改config.v2.json
找到要修改的关键字ExposedPorts,
原先的内容如下:

那我们要增加暴露的端口
⑵ 修改hostconfig.json
找到要修改的关键字PortBindings,
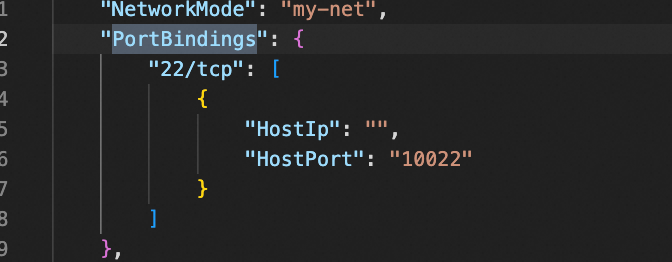
重启docker
启动容器实例查看是否生效
















 4107
4107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









