






Docker 搭建 Hadoop集群-CSDN博客
目录创建
打开HDFS控制台
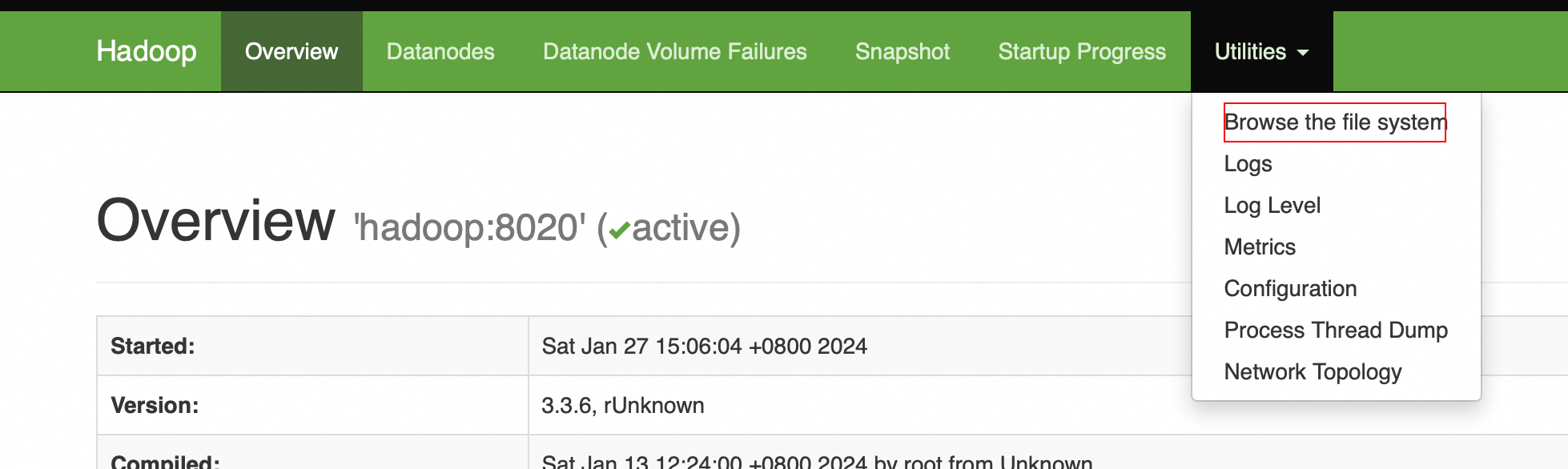
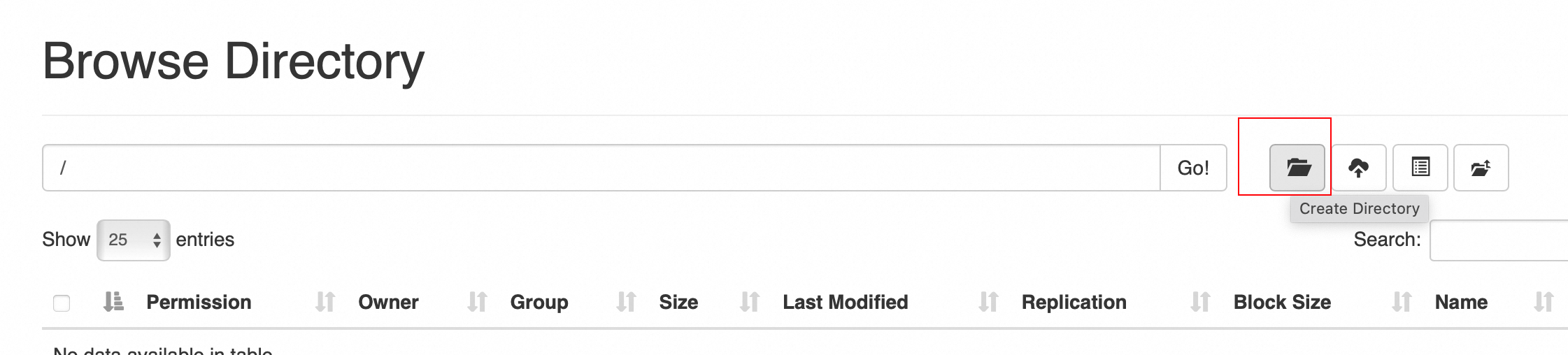
新建名称 test 的文件夹
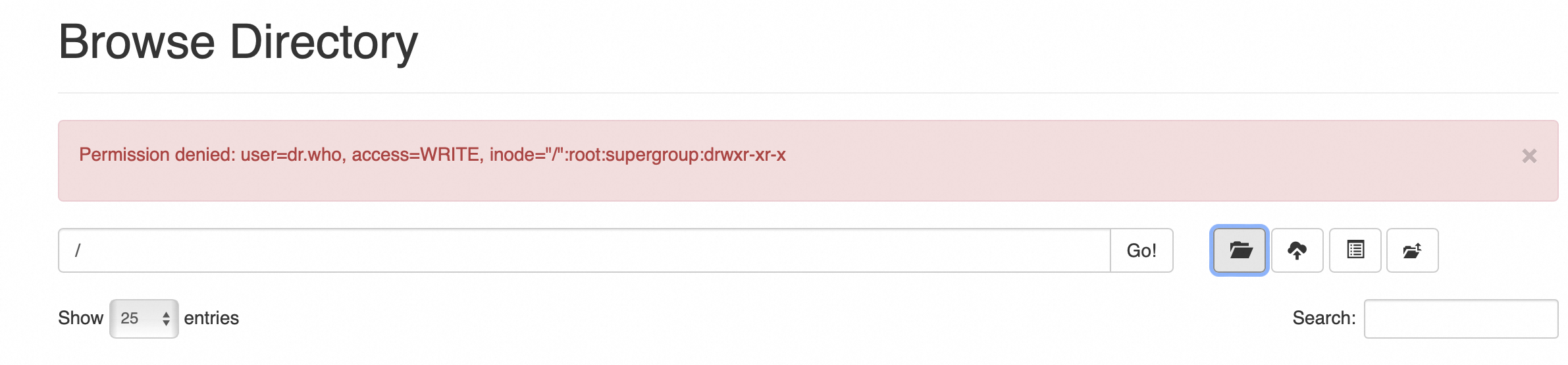
进入到hadoop目录执行 hadoop-xxx/bin/hdfs dfs -chmod -R 777 / 给所有文件赋值最高权限(所有node节点)
创建成功
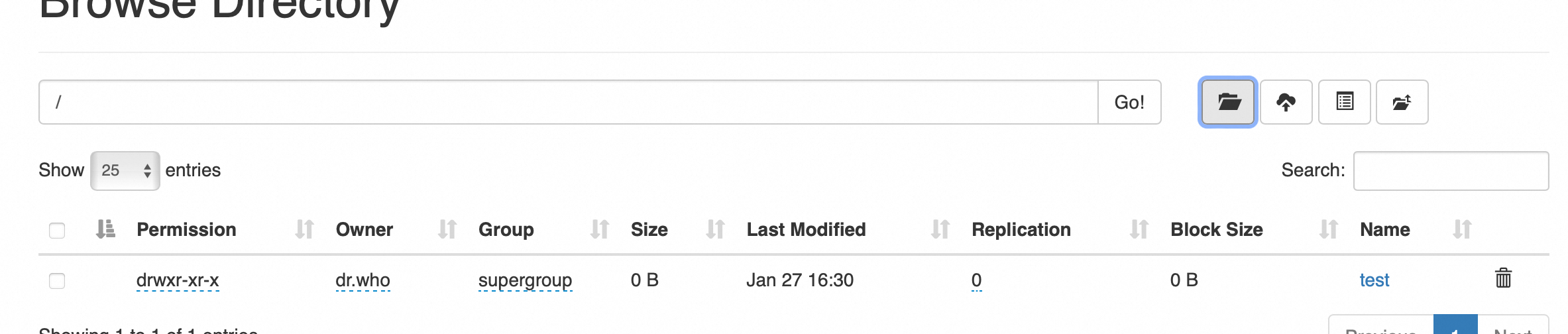
继续创建如下目录
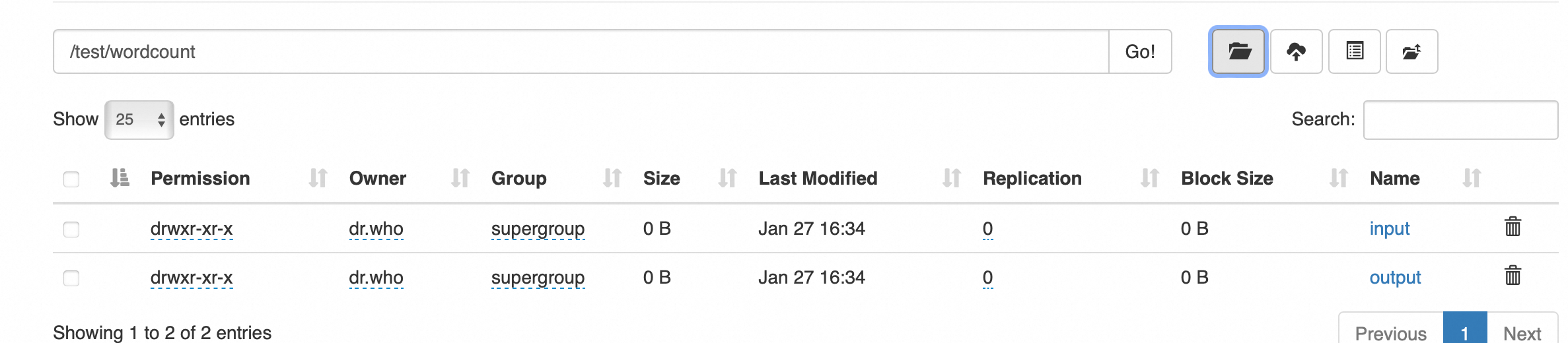
准备数据
新建txt文件并上传
hadoop is very good mapreduce is very good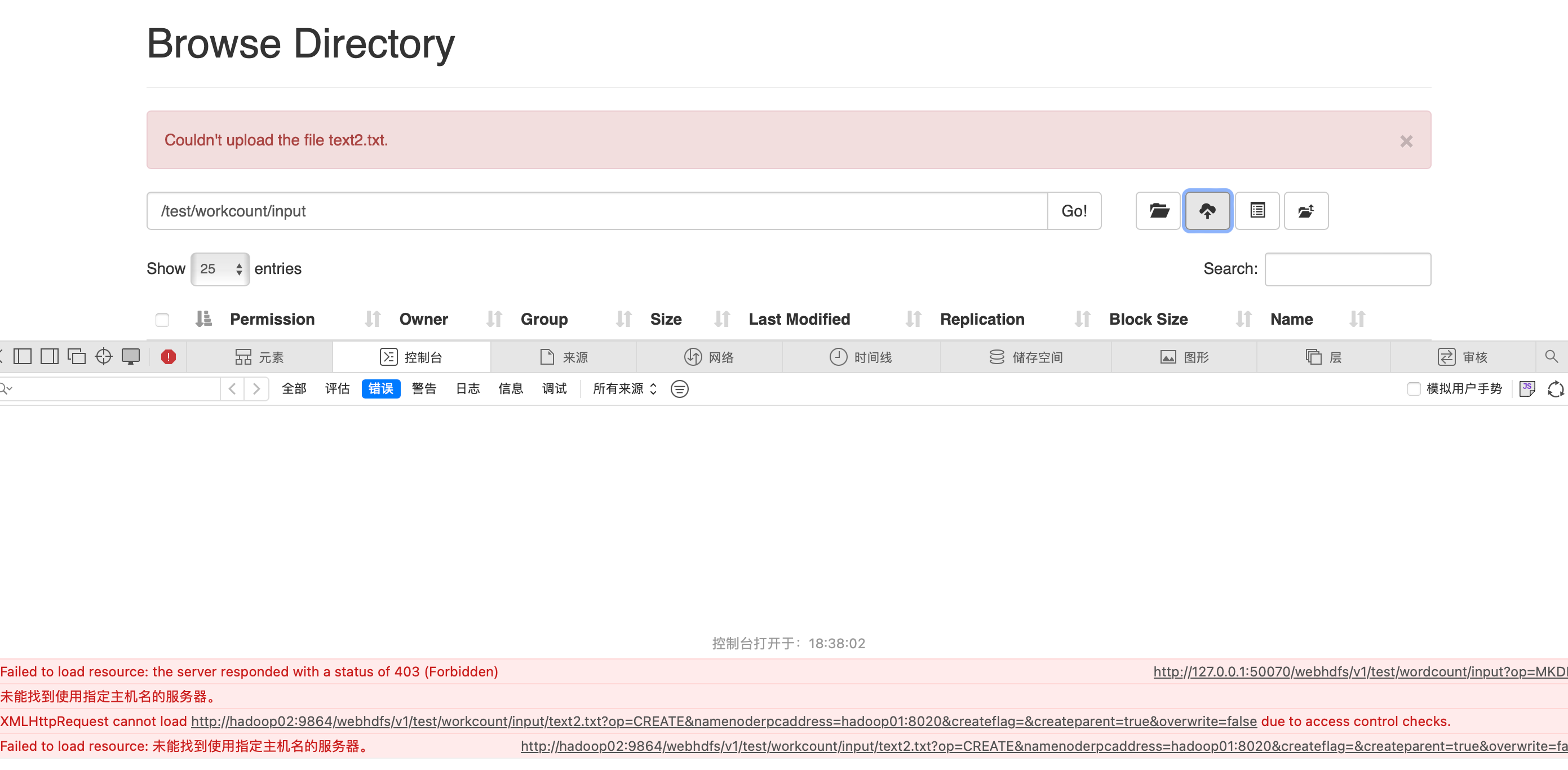
可以看出页面代码识别的主机名来进行api调用,
在宿主机上添加如下映射
vi /etc/hosts
127.0.0.1 hadoop01
127.0.0.1 hadoop02文件上传成功
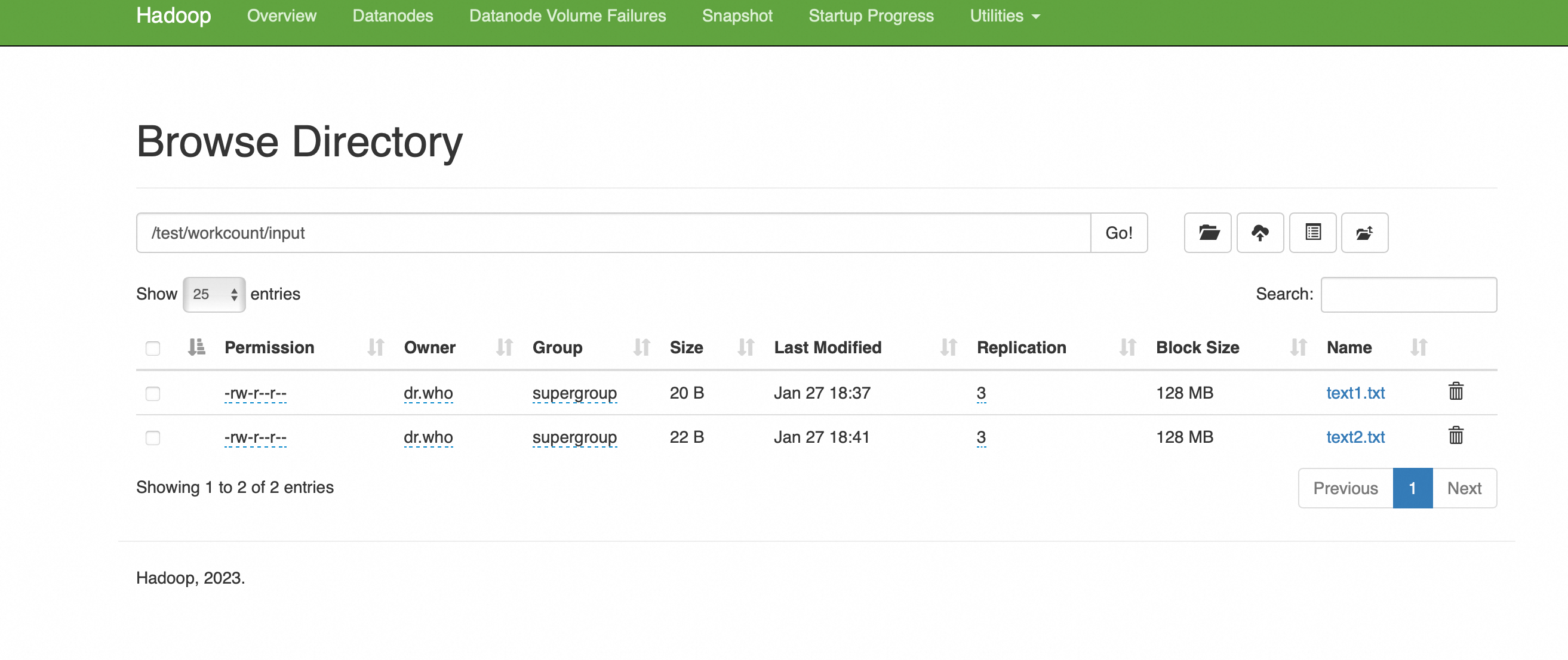
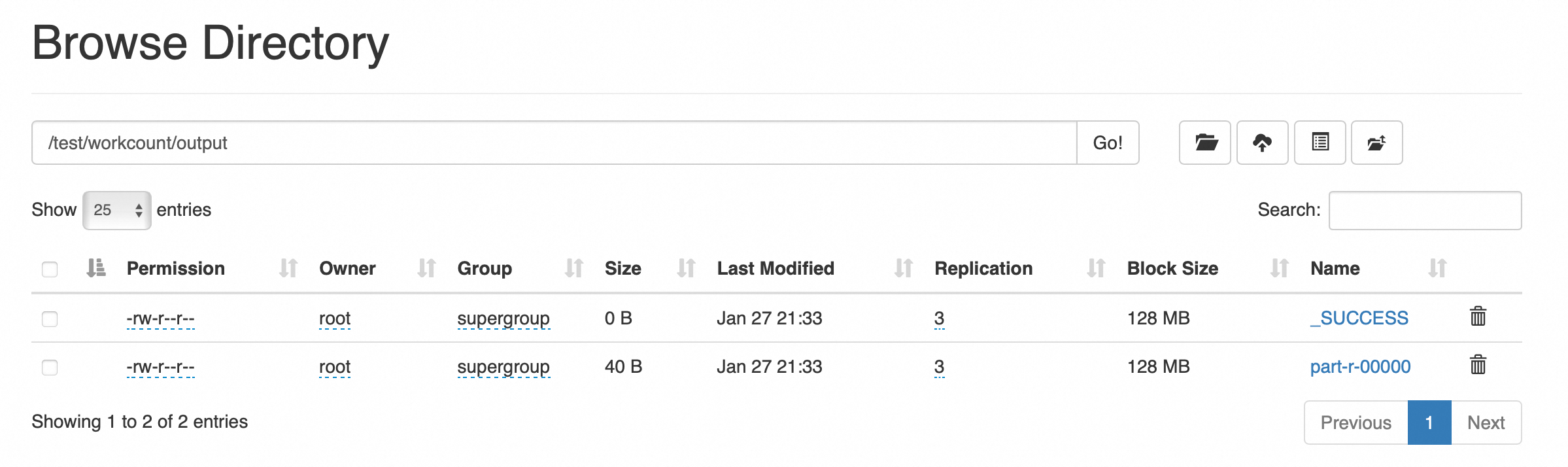
运行MapReduce用WordCount进行处理
hadoop jar hadoop-mapreduce-examples-3.3.6.jar wordcount /test/workcount/input /test/workcount/output
报错:
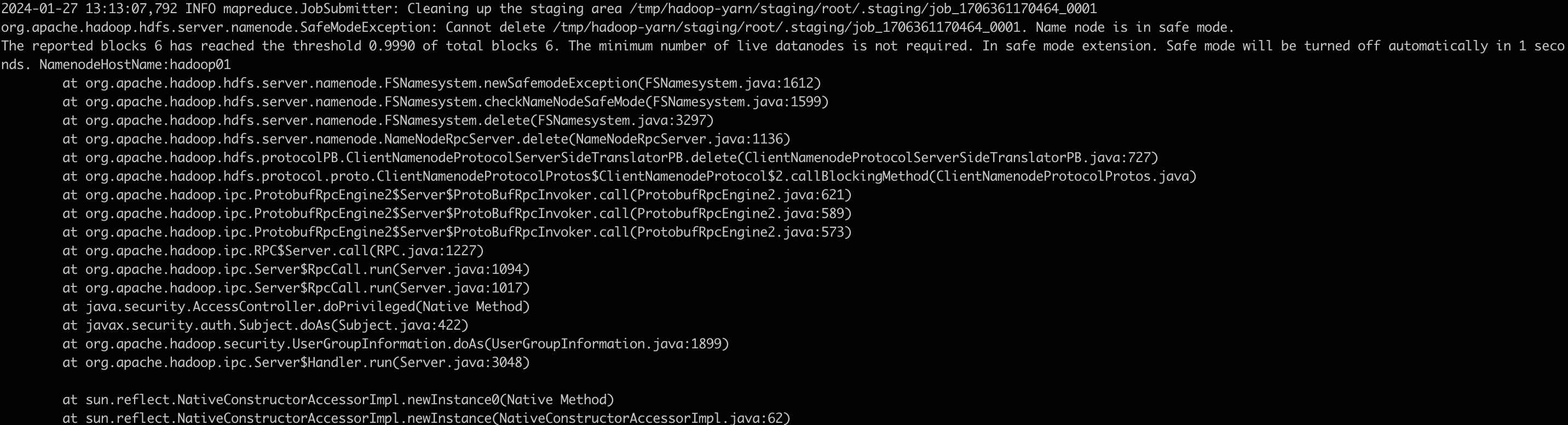
退出安全模式
hdfs dfsadmin -safemode leave
再次运行
2024-01-27 13:27:20,952 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop01/172.18.0.2:8032
2024-01-27 13:27:21,205 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1706361976462_0002
2024-01-27 13:27:22,049 INFO input.FileInputFormat: Total input files to process : 2
2024-01-27 13:27:22,091 INFO mapreduce.JobSubmitter: number of splits:2
2024-01-27 13:27:22,196 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1706361976462_0002
2024-01-27 13:27:22,196 INFO mapreduce.JobSubmitter: Executing with tokens: []
2024-01-27 13:27:22,284 INFO conf.Configuration: resource-types.xml not found
2024-01-27 13:27:22,284 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2024-01-27 13:27:22,465 INFO impl.YarnClientImpl: Submitted application application_1706361976462_0002
2024-01-27 13:27:22,486 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1706361976462_0002/
2024-01-27 13:27:22,486 INFO mapreduce.Job: Running job: job_1706361976462_0002
2024-01-27 13:27:27,534 INFO mapreduce.Job: Job job_1706361976462_0002 running in uber mode : false
2024-01-27 13:27:27,536 INFO mapreduce.Job: map 0% reduce 0%
2024-01-27 13:27:32,659 INFO mapreduce.Job: map 100% reduce 0%
2024-01-27 13:27:36,691 INFO mapreduce.Job: map 100% reduce 100%
2024-01-27 13:27:36,702 INFO mapreduce.Job: Job job_1706361976462_0002 completed successfully
2024-01-27 13:27:36,770 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=97
FILE: Number of bytes written=828676
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=274
HDFS: Number of bytes written=40
HDFS: Number of read operations=11
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=4960
Total time spent by all reduces in occupied slots (ms)=1279
Total time spent by all map tasks (ms)=4960
Total time spent by all reduce tasks (ms)=1279
Total vcore-milliseconds taken by all map tasks=4960
Total vcore-milliseconds taken by all reduce tasks=1279
Total megabyte-milliseconds taken by all map tasks=5079040
Total megabyte-milliseconds taken by all reduce tasks=1309696
Map-Reduce Framework
Map input records=2
Map output records=8
Map output bytes=75
Map output materialized bytes=103
Input split bytes=232
Combine input records=8
Combine output records=8
Reduce input groups=5
Reduce shuffle bytes=103
Reduce input records=8
Reduce output records=5
Spilled Records=16
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=704
CPU time spent (ms)=2760
Physical memory (bytes) snapshot=1225478144
Virtual memory (bytes) snapshot=7589892096
Total committed heap usage (bytes)=1238892544
Peak Map Physical memory (bytes)=490315776
Peak Map Virtual memory (bytes)=2526896128
Peak Reduce Physical memory (bytes)=251367424
Peak Reduce Virtual memory (bytes)=2537238528
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=42
File Output Format Counters
Bytes Written=40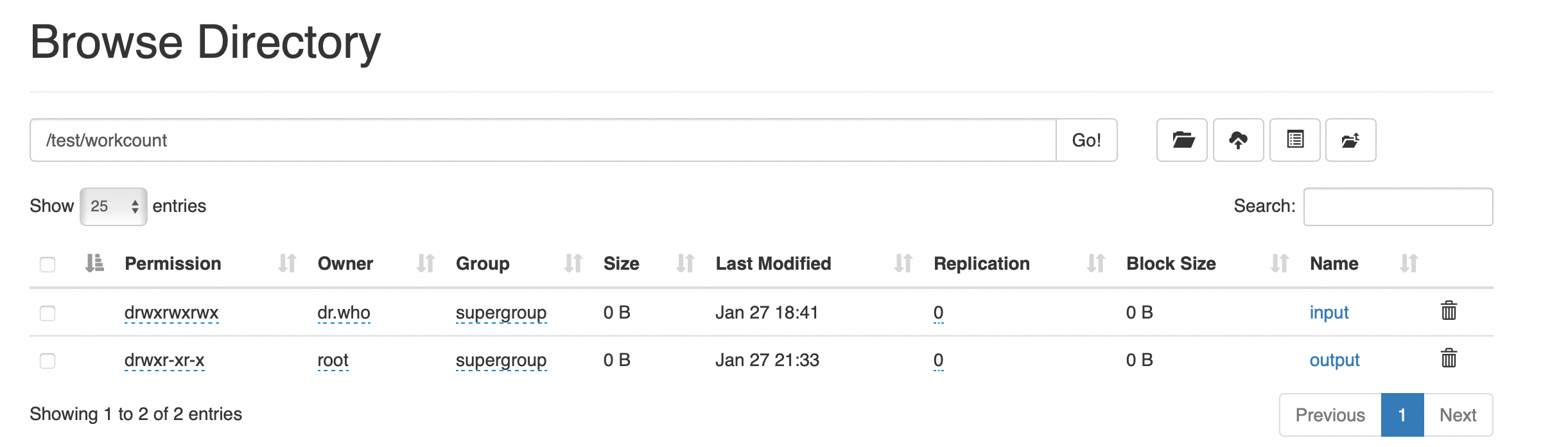
hdfs dfs -cat /test/workcount/output/part-r-00000

wordcount 源码
hadoop-mapreduce-examples-3.3.6.jar wordcount 源码
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









