







字符串(String):
-
python 中的字符串用单引号(' ')或双引号(" ")括起来,同时使用反斜杠(\)对特殊字符进行转义;
-
python 中单引号和双引号用法完全相同;
-
python 中使用三引号(''' 或 """)可以指定一个多行字符串;
#!/usr/bin/python3
str1 = "我是字符串"
str2 = '我也是字符串'
# ''' 或 """ 可以表示多行字符串
# 注意:多行字符串中会保留 换行符 和 空格符
str3 = '''我还是
字符串'''
print(str1)
print(str2)
print(str3)输出结果:

- 反斜杠(\)可以用来转义,使用 r 可以让反斜杠不发生转义;如 r"this is line with \n" 则 \n 会显示,而不是换行;r 是 raw 的缩写,raw string 表示原始字符串;
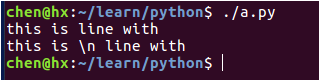
#!/usr/bin/python3
# 修改 print 方法的 end 参数为空,就表示 print 方法输出的数据默认不换行;
# 但是输出的数据中带有换行符(\n),所以下面这句输出还是会换行;
print("this is line with \n", end="")
# 用 r 可以让反斜杠(\)不发生转义,即 \n 不再表示换行,而是作为一个字符串
print(r"this is \n line with")输出结果:
python 中所有的转义字符如下:
| 转义字符 | 描述 |
|---|---|
| (在行尾时) | 续行符 |
| \ | 反斜杠符号 |
| ' | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy 代表的字符,例如:\o12 代表换行,其中 o 是字母,不是数字 0。 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
-
按字面意思级联字符串,比如 "this " "is " "string" 会被自动转换为 "this is string";
-
字符串可以用 + 运算符连接在一起;
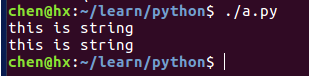
#!/usr/bin/python3
# 字符串的拼接:直接按字面意思进行拼接
print("this " "is " "string")
# 字符串的拼接:使用 + 号运算符进行拼接
print("this " + "is " + "string")输出结果:
-
python 中的字符串有两种索引方式,从左往右从 0 开始,从右往左从 -1 开始;
-
python 没有单独的字符类型,一个字符就是长度为 1 的字符串;
-
字符串的截取的语法格式如下:变量[头下标:尾下标:步长]
注意:截取的区间属于 左闭右开型,即从 "起始" 位开始,到 "结束" 位的前一位结束(不包含结束位本身)
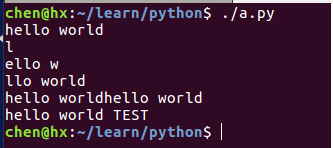
#!/usr/bin/python3
str = "hello world" # 定义一个字符串
print (str) # 输出字符串
print (str[2]) # 输出第三个字符(索引从 0 开始)
print (str[1:7]) # 输出第二个到第八个的所有字符
print (str[2:]) # 输出从第三个开始后面的所有字符
print (str * 2) # 输出字符串两次,也可以写成 print (2 * str)
print (str + " TEST") # 连接字符串输出结果:
- 用成员运算符 in 或 not in,可以判断字符串中是否包含给定的字符;
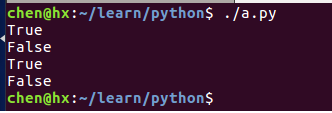
#!/usr/bin/python3
str = "hello world" # 定义一个字符串
print("w" in str) # 判断字符 w 是否在 str 中
print("how" in str) # 判断字符串 "hel" 是否在 str 中
print("x" not in str)
print("wor" not in str)输出结果:
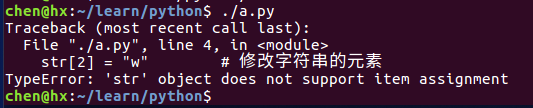
- 字符串的元素是不可以改变的:
#!/usr/bin/python3
str = "hello"
str[2] = "w" # 修改字符串的元素会报错
print(str)输出结果:
python 的字符串内建函数:
1、capitalize():将字符串的第一个字符转换为大写,其他字符变小写;
#!/usr/bin/python3
str = "hEllo WoRld" # 定义一个字符串
print(str.capitalize()) # 将字符串第一个字符转换成大写,其他变为小写(输出结果:Hello world)2、center(width, fillchar):返回一个原字符串居中对齐,并使用 fillchar 左右填充至指定宽度为 width 的新字符串;如果 width 小于原字符串的长度,则返回原字符串;
-
width:字符串的总长度;
-
fillchar:填充的字符(如果不使用该参数,默认为空格);
3、ljust(width, fillchar):和 center() 用法一样,区别是原字符串左对齐,右填充;
4、rjust(width, fillchar):和 center() 用法一样,区别是原字符串右对齐,左填充;
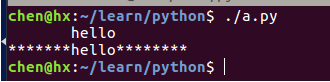
#!/usr/bin/python3
str = "hello" # 定义一个字符串
# 表示返回一个长度为 20,字符串 str 居中,左右两边为空格的新字符串
print (str.center(20))
# 表示返回一个长度为 20,字符串 str 居中,左右两边用 * 号填充的新字符串
print (str.center(20, '*'))输出结果:
5、zfill(width):返回指定长度的字符串,原字符串右对齐,前补 0;
print("hello".zfill(10)) # 输出结果:00000hello6、len(string):返回字符串长度;
7、max(str):返回字符串中最大的字母;
8、min(str):返回字符串中最小的字母;
print (len("world")) # 输出结果:5
print (max("world")) # 输出结果:w
print (min("world")) # 输出结果:d9、count(sub, start= 0,end=len(string)):用于统计 sub 在 string 中出现的次数,如果 start 或者 end 指定,则返回指定范围内 sub 出现的次数;
-
sub:需要查找的子字符串;
-
start:字符串开始搜索的位置,默认为第一个字符,第一个字符串索引值为 0;
-
end:字符串中结束搜索的位置,默认为字符串的最后一个位置;
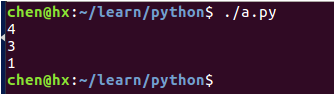
#!/usr/bin/python3
str="How are you?I am fine, thank you, and you?"
# 查看字符 o 在 str 中出现的次数
sub='o'
print(str.count(sub))
# 查找子字符串 you 在 str 中出现的次数
sub='you'
print(str.count(sub, 0, len(str)))
# 查找子字符串 you 在 str 索引从 10 到 40 中出现的次数
print(str.count(sub, 10, 40))输出结果:
10、encode(encoding='UTF-8',errors='strict'):根据给定的 encoding 编码格式编码字符串,如果出错,默认报一个 UnicodeError 的异常,除非 errors 指定的是 "ignore" 或者 "replace";
-
encoding:要使用的编码格式,如 "UTF-8";
-
errors:设置不同错误的处理方案;默认为 "strict",表示编码错误引起一个 UnicodeError;其他可能得值有 'ignore','replace','xmlcharrefreplace','backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
-
该方法返回一个编码后的字符串,它是一个 bytes 对象;
11、bytes.decode(encoding="utf-8", errors="strict"):字符串对象没有 decode 方法,但我们可以使用 bytes 对象的 decode 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回;
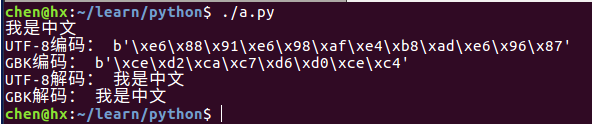
#!/usr/bin/python3
str = "我是中文"
# 编码之后返回的是一个 bytes 对象
str_utf8 = str.encode("UTF-8") # 将字符串以 UTF-8 格式进行编码
str_gbk = str.encode("GBK") # 将字符串以 GBK 格式进行编码
# 输出字符串
print(str)
print("UTF-8编码:", str_utf8)
print("GBK编码:", str_gbk)
# 使用 bytes 对象的 decode 方法进行解码
print("UTF-8解码:", str_utf8.decode("UTF-8"))
print("GBK解码:", str_gbk.decode("GBK"))输出结果:
12、endswith(substr, start=0, end=len(string)):检查字符串是否以指定子字符串 substr 结尾,如果 start 或者 end 指定,则检查在指定的范围内,是否以 substr 结尾;如果是,返回 True;否则返回 False;
-
substr:该参数可以是一个子字符串或者是一个元素。
-
start:字符串中的开始位置。
-
end:字符串中的结束位置。
13、startswith(substr, start=0, end=len(string)):检查字符串中是否以指定子字符串 substr 开始,如果是,返回 True;否则返回 False。如果 start 和 end 参数存在,则在指定范围内查找;
#!/usr/bin/python3
str = "how are you! I am fine, thank you!"
print(str.endswith("you!")) # 字符串是否以 you! 结尾
print(str.endswith("you", 5)) # 从第5个字符开始,字符串是否以 you 结尾
print(str.endswith("fine", 5, 22)) # 从第5个字符开始,到第22个字符结束的字符串里,是否以 fine 结尾
print(str.startswith('how')) # 字符串是否以 how 开头
print(str.startswith('you', 8)) # 从第8个字符开始的字符串是否以 you 开头
print(str.startswith('you', 5, 15)) # 从第5个字符开始到第15个字符结束的字符串是否以 you 开头输出结果:

14、expandtabs(tabsize=8):把字符串中的 tab 符号('\t')转为空格,tab 符号默认的空格数是 8;
15、find(str, start=0, end=len(string)):检查 str 是否包含在字符串中;如果指定范围 start 和 end,则在指定的范围内检查,如果包含,返回 str 开始的索引值,否则返回 -1;
16、rfind(str, start=0, end=len(string)):和 find() 用法一样,区别是返回 str 最后一次出现的位置;
17、index(str, start=0, end=len(string)):跟 find() 方法一样,只不过如果 str 不在字符串中,会报一个异常;
18、rindex(str, start=0, end=len(string)):用法和 rfind() 一样,区别也是如果 str 不在字符串中,会报一个异常;
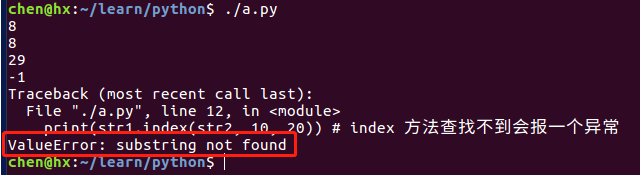
#!/usr/bin/python3
str1 = "how are you!I am fine, thank you!"
str2 = "you";
print(str1.find(str2)) # 如果 str2 在 str1 中,返回 str2 开始的索引值
print(str1.find(str2, 5)) # 从 str1 的第 5 个字符开始,查找 str2 在 str1 中出现的位置(查到的是第一个 you 的位置)
print(str1.find(str2, 10)) # 从 str1 的第 10 个字符开始,查找 str2 在 str1 中出现的位置(查到的是第二个 you 的位置)
print(str1.find(str2, 10, 20)) # 从 str1 的第 10 个字符开始,到第 20 个字符结束的范围内,查找 str2 的位置(查找不到返回 -1)
print(str1.index(str2, 10, 20)) # index 方法查找不到会报一个异常输出结果:
19、isalnum():用于检测字符串是否只由字母或数字组成,如果是则返回 True,即只有字母或数字,或者是字母和数字的组合,不能存在其他第三种字符;如果存在其他第三种字符了,就返回 False;
#!/usr/bin/python3
# 只由字母,或数组,或字母和数字的组合,才返回 True
print("1111".isalnum()) # True
print("aaaa".isalnum()) # True
print("11aa".isalnum()) # True
print("aa11".isalnum()) # True
# 只要存在其他第三种字符,就返回 False
print("www.baidu.com".isalnum()) # False
print("hello\tworld".isalnum()) # False20、isalpha():用于检测字符串是否只由字母和文字(汉字)组成,是则返回 True,否则返回 False;
#!/usr/bin/python3
# 只由字母,或汉字,或字母和汉字的组合,才返回 True
print("aaaa".isalpha()) # True
print("汉字".isalpha()) # True
print("hello你好".isalpha()) # True
# 只要存在除字母和汉字外的其他第三种字符,就返回 False
print("11aa".isalpha()) # False
print("www.baidu.com".isalpha())# False21、isdigit():用于检测字符串是否只由数字组成,是则返回 True,否则返回 False;
22、isnumeric():用于检测字符串是否只由数字组成,数字可以是:Unicode 数字、全角数字(双字节)、罗马数字、汉字数字;指数与分数也属于数字;是则返回 True,否则返回 False;
23、isdecimal():用于检测字符串是否只包含十进制字符;这种方法只存在于 unicode 对象;是则返回 True,否则返回 False;
#!/usr/bin/python3
# isdigit()、isnumeric()、isdecimal() 三个方法都可以用来检测字符串是否只由数字组成;
# isdigit() 可以用来判断一般的数字字符串;
# isnumeric() 可以用来判断一些特殊的数字字符串,比如:Unicode 数字,全角数字(双字节),罗马数字,汉字数字。
# isdecimal() 只可以用来判断只包含十进制数字的字符串;
# 普通数字字符串
print("22".isdigit()) # True
print("22".isnumeric()) # True
print("22".isdecimal()) # True
# Unicode 数字
print("\u00B23455".isdigit()) # True
print("\u00B23455".isnumeric()) # True
print("\u00B23455".isdecimal()) # False
# 罗马数字
print("Ⅱ".isdigit()) # False
print("Ⅱ".isnumeric()) # True
print("Ⅱ".isdecimal()) # False
# 汉字数字
print("一二三".isdigit()) # False
print("一二三".isnumeric()) # True
print("一二三".isdecimal()) # False24、isspace():用于检测字符串是否只由空白组成;是则返回 True,否则返回 False;
#!/usr/bin/python3
print(" ".isspace()) # True
print("\r".isspace()) # True
print("\n".isspace()) # True
print("\t".isspace()) # True25、islower():用于检测字符串是否只由小写字符组成;是则返回 True,否则返回 False;
26、isupper():用于检测字符串是否只由大写字符组成;是则返回 True,否则返回 False;
27、istitle():用于检测字符串中是否所有单词的首字母为大写,其他字符为小写;是则返回 True,否则返回 False;
28、title():返回 "标题化" 的字符串,即将字符串中所有单词的首字母变为大写,其余字母变为小写;
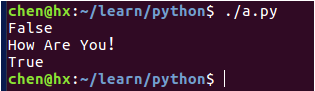
#!/usr/bin/python3
str = "how are you!"
print(str.istitle()) # False
str = str.title()
print(str) # 将字符串首字母变为大写
print(str.istitle()) # True输出结果:
29、join(sequence):用于将序列中的元素以指定的字符连接生成一个新的字符串;
-
sequence:要连接的元素序列;
#!/usr/bin/python3
str1 = "-"
str2 = "|"
seq = ("h", "e", "l", "l", "o") # 序列
print(str1.join(seq)) # 使用 _ 将序列中的元素连接起来
print(str2.join(seq)) # 使用 | 将序列中的元素连接起来输出结果:

30、lower():将字符串中所有大写字符转换为小写;
31、upper():将字符串中所有小写字符转换为大写;
32、swapcase():将字符串中的大写字符转换为小写,小写字符转换为大写;
33、lstrip([chars]):截掉(删除)字符串左边的空格或指定字符;
34、rstrip([chars]):截掉(删除)字符串左边的空格或指定字符;
35、strip([chars]):截掉(删除)字符串左边和右边的空格或指定字符;相当于 lstrip() 和 rstrip() 同时使用;
-
注意:如果参数 chars 不存在,则默认只删除空格;
-
注意:不能截掉(删除)字符串中间的内容;
#!/usr/bin/python3
str = " how are you "
# 删除字符串左右两边的空格,中间的空格无法删除
print(str.strip())
# 删除字符串左右两边的 you;因为右边还有空格字符,you 不在最右边,所以无法删除
print(str.strip("you"))输出结果:

36、replace(old, new[, max]):把字符串中的 old 替换成 new;如果指定参数 max,则替换不超过 max 次;
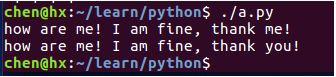
#!/usr/bin/python3
str = "how are you! I am fine, thank you!"
print(str.replace("you", "me")) # 将字符串中的 you 替换成 me
str = "how are you! I am fine, thank you!"
print(str.replace("you", "me", 1)) # 将字符串中的 you 替换成 me,但是只替换 1 次输出结果:
37、split(str, num):通过指定的分隔符对字符串进行分割;如果第二个参数 num 有值,则分割为 num+1 个子字符串;返回分割后的字符串列表;
#!/usr/bin/python3
str = "how are you! I am fine, thank you!"
print(str.split(" ")) # 以空格进行分割
print(str.split(" ", 3)) # 以空格进行分割,但是只分割成 4 个子字符串
print(str.split("a")) # 以字符 a 进行分割输出结果:

38、splitlines(keepends):按照行("\r", "\n", "\r\n")进行分割,返回一个包含各行作为元素的列表,如果参数为 False,不包含换行符(默认);如果为 True,则保留换行符;
#!/usr/bin/python3
str = "how are\r you! \nI am fine, \r\nthank you!"
print(str.splitlines()) # 以行进行分割,默认情况不保留换行符
print(str.splitlines(True)) # 以行进行分割,保留换行符输出结果:
















 1428
1428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









