







今天发现了一个链接,是GitHub 上有哪些优秀的 Python 爬虫项目?
https://www.zhihu.com/question/58151047/answer/859783454
然后呢我大概扫了一眼,挑选了一个网站来搞,没错就是这个http://girl-atlas.net/
首页就是一个分页了
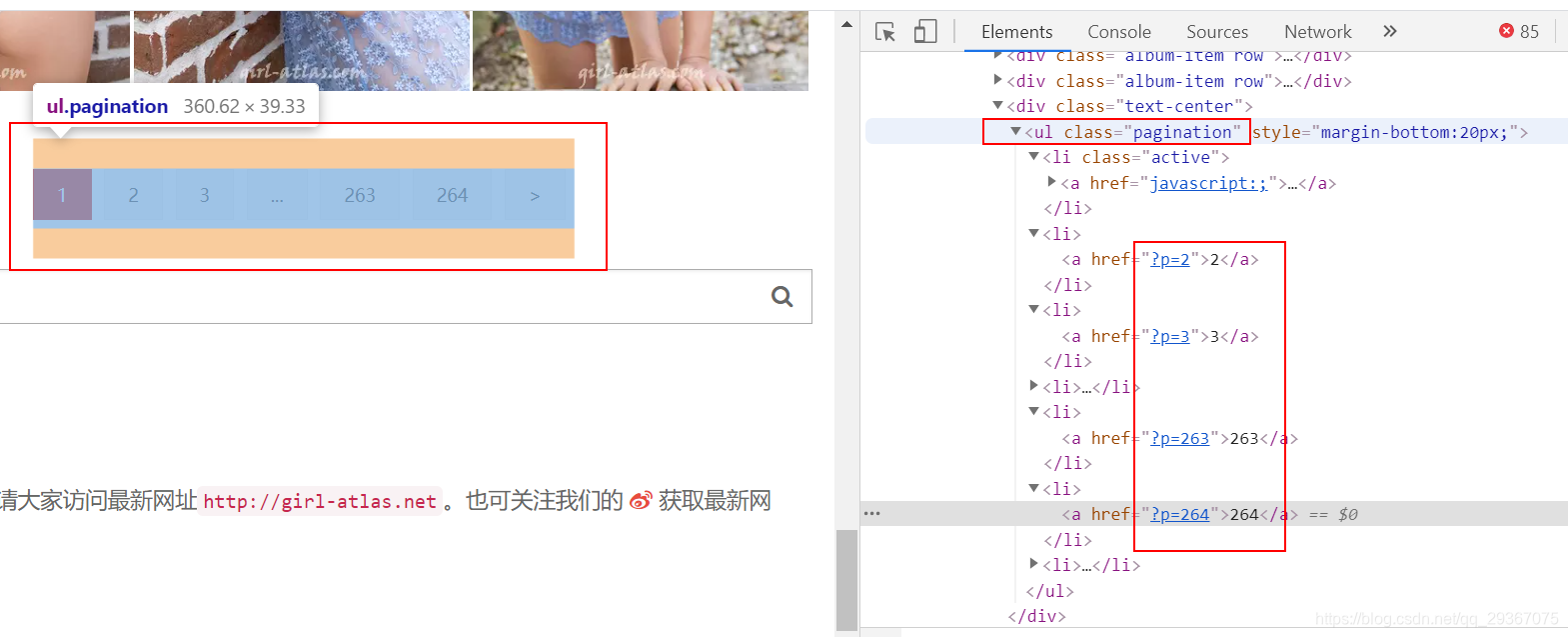
每一页的地址很有规律,在根地址上增加”?p=XX”,XX就是页码边贸,可见首页其实也是http://girl-atlas.net/?p=1 ,嗯,验证正确,因此我们只需要把最大页面数字记录下来就能遍历所有页面。
对于每一个页面都是列表展示
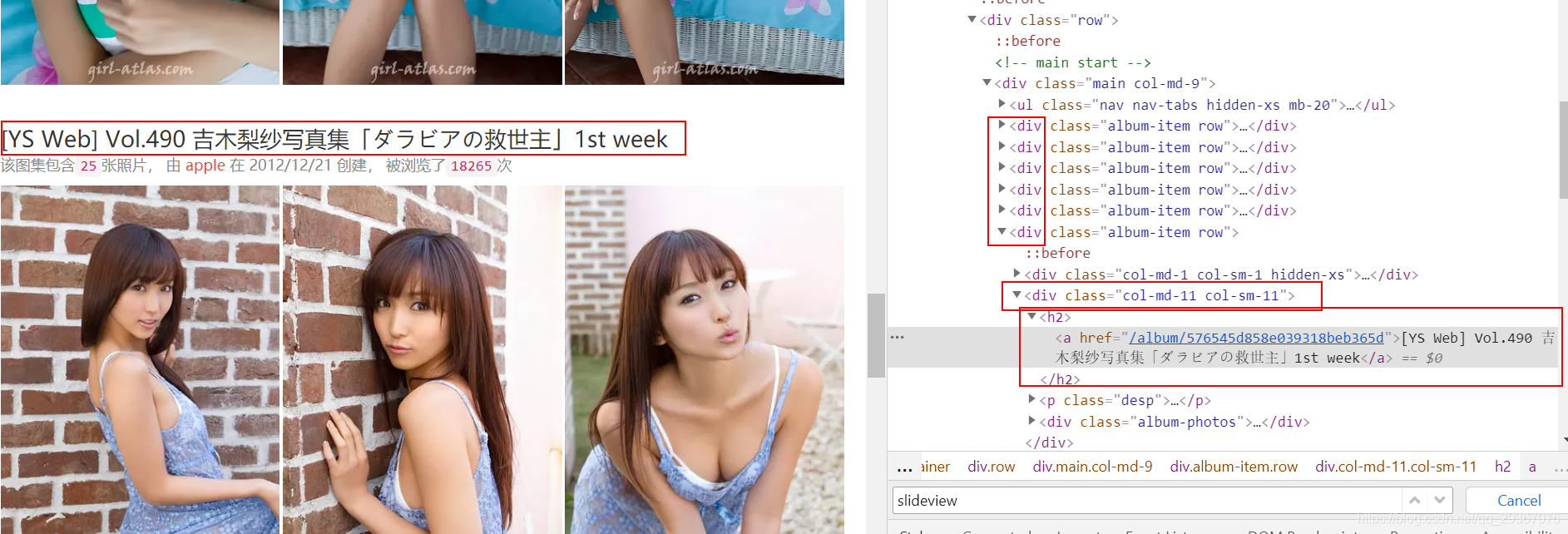
有六块div,里面的有标题,我们爬取出来作为目录,因为标题和图片都是指向了同一个新的页面地址。
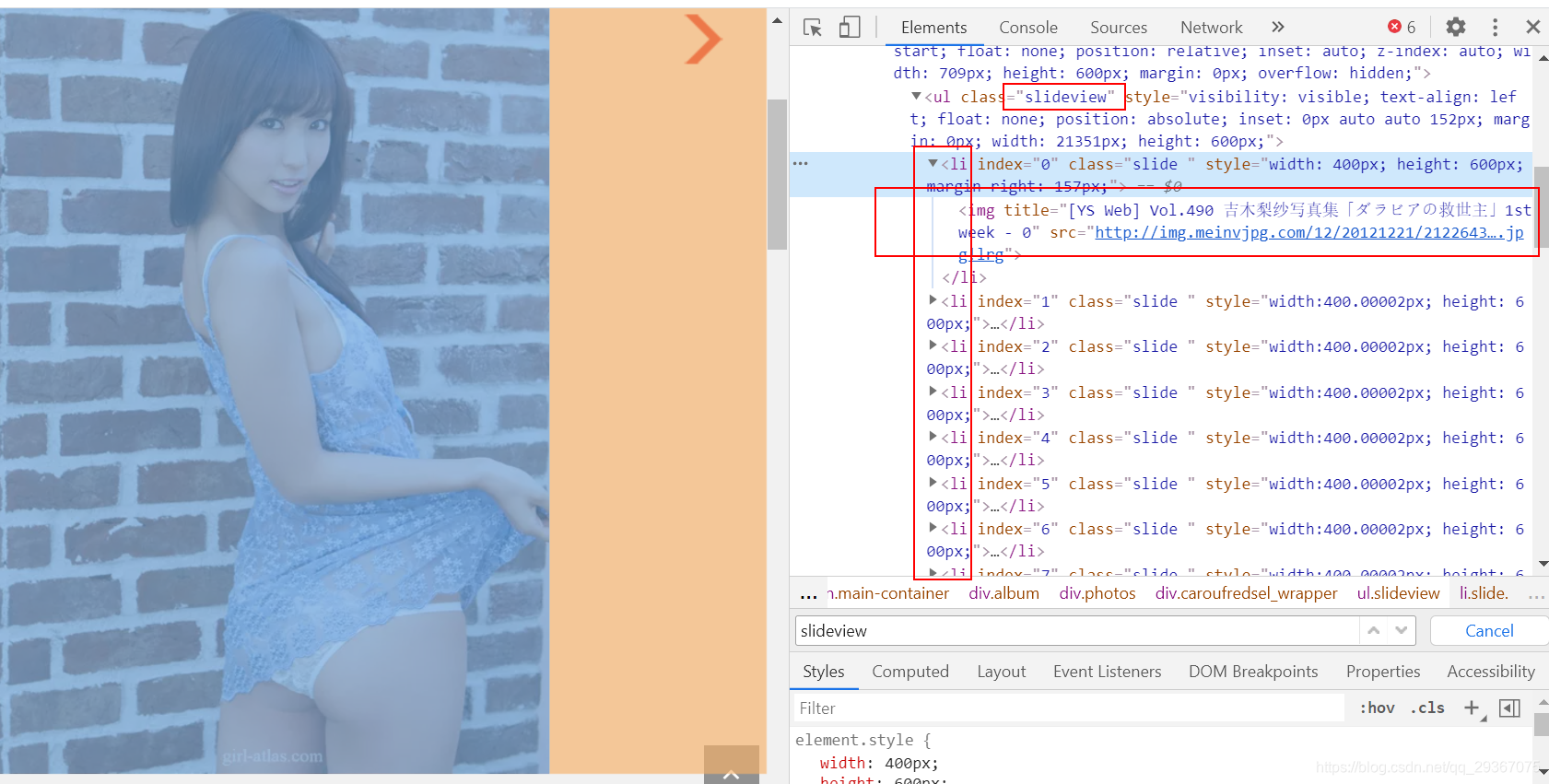
接着我们点进去看到一个新的页面,专门来展示这个图集的。经过检查发现,所有图集的图片都在一起页面放好了,没有分页,很好很好。
于是一把爬取所有的照片。
按照惯例,我们先用单张图片做实验啊。
比如下面这张图片
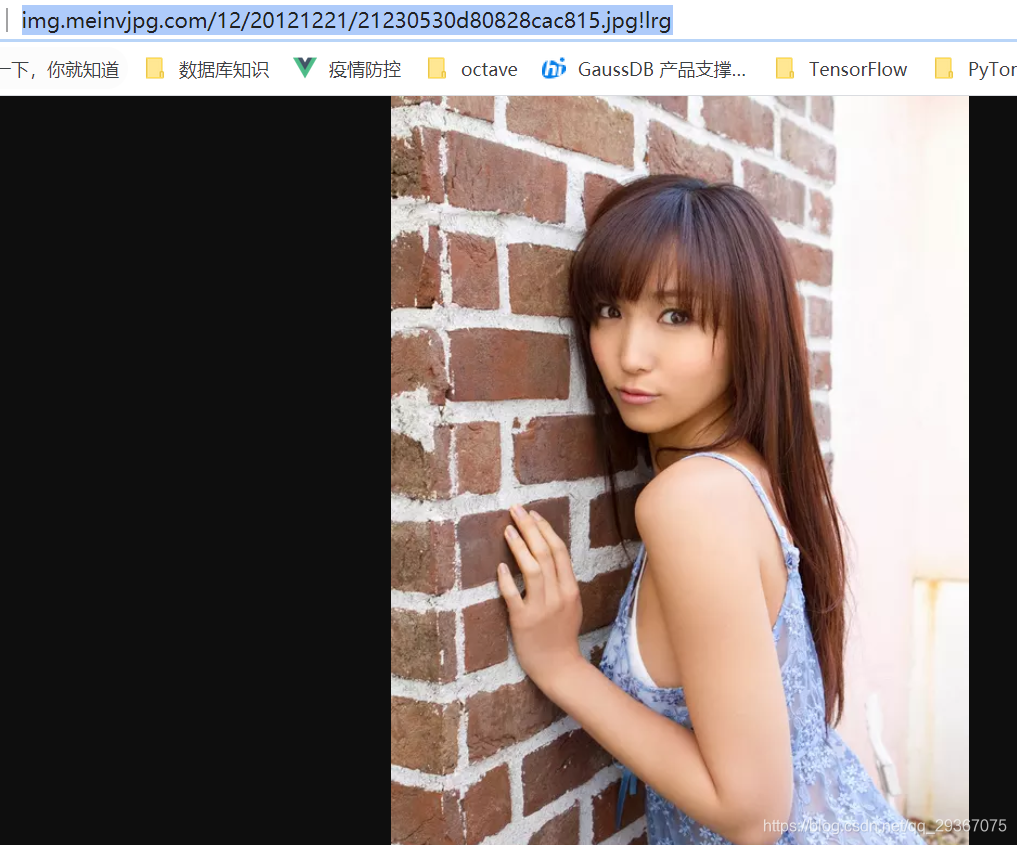
测试代码如下:
import requests #导入模块
def run7():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"Referer": "http://girl-atlas.net/"
}
with open("D:/estimages/mn.jpg", "wb") as f :
f.write(requests.get("http://img.meinvjpg.com/12/20121221/21230530d80828cac815.jpg!lrg", headers=headers).content)
f.close
if __name__ == "__main__": #主程序入口
run7() #调用上面的run方法
试验成功,是可以下载下来的。

下面贴出完整实验代码
import os
import requests
from bs4 import BeautifulSoup
rootrurl = 'http://girl-atlas.net/'
#rootrurl = 'http://girl-atlas.net/index1'
save_dir = 'D:/estimages/'
no_more_pages = 'END'
max_src_pages = 10
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"Referer": rootrurl
}
def getMaxPagesNum(url):
html = BeautifulSoup(requests.get(url).text, features="html.parser")
lis = html.find('ul', attrs={'class': 'pagination'}).find_all('a')[-2].string
return int(lis)
def saveImgsCore(href, saveDir):
html = BeautifulSoup(requests.get(href, headers=headers).text, features="html.parser")
imgs = html.find('ul', attrs={'class': 'slideview'}).find_all('img')
for img in imgs:
# 获得图片的地址
img_url = img.get('src')
if img_url is None:
img_url = img.get('delay')
# 防止出现反盗链
new_headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
'Referer': img_url
}
print("downloading : " + img_url)
img = requests.get(img_url, headers=new_headers) # 请求图片的实际URL
with open(
'{}/{}'.format(saveDir, img_url.split("/")[-1][:-4]), 'wb') as jpg: # 请求图片并写进去到本地文件
jpg.write(img.content)
pass
def saveAllImgs(url):
print("current page is: %s" % url)
html = BeautifulSoup(requests.get(url, headers=headers).text, features="html.parser")
divs = html.find_all('div', attrs={'class': 'col-md-11 col-sm-11'})
for link in divs:
a = link.find('h2').find('a')
href = a.get('href')
title = a.get_text()
if not os.path.exists(save_dir + title):
os.mkdir(save_dir + title)
print("current group is: %s" % title)
saveImgsCore(rootrurl + href, save_dir + title)
if __name__ == '__main__':
maxPages = getMaxPagesNum(rootrurl)
for i in range(1, (maxPages+1)):
url = rootrurl + ('?p=%d' % i)
saveAllImgs(url)
效果如下:
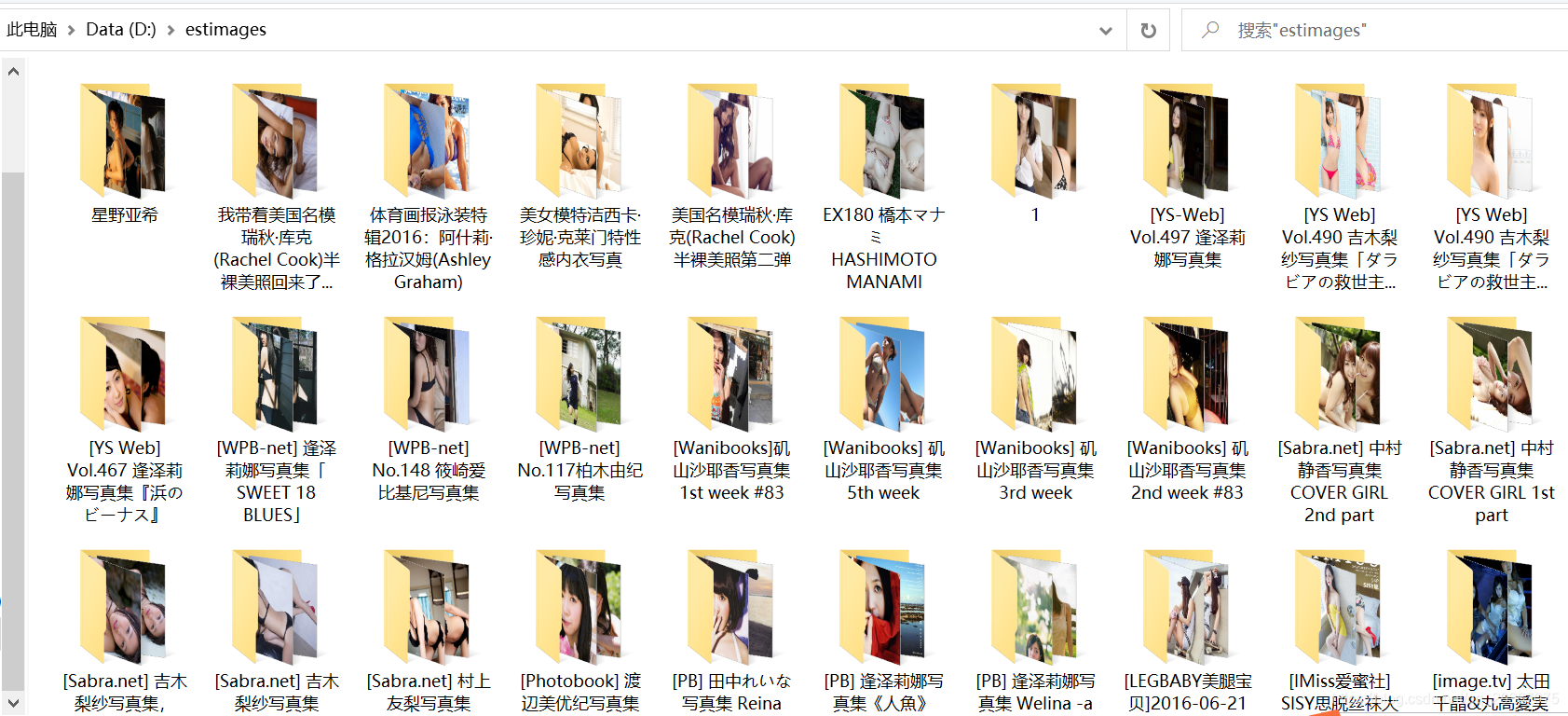














 2579
2579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









