







并发容器
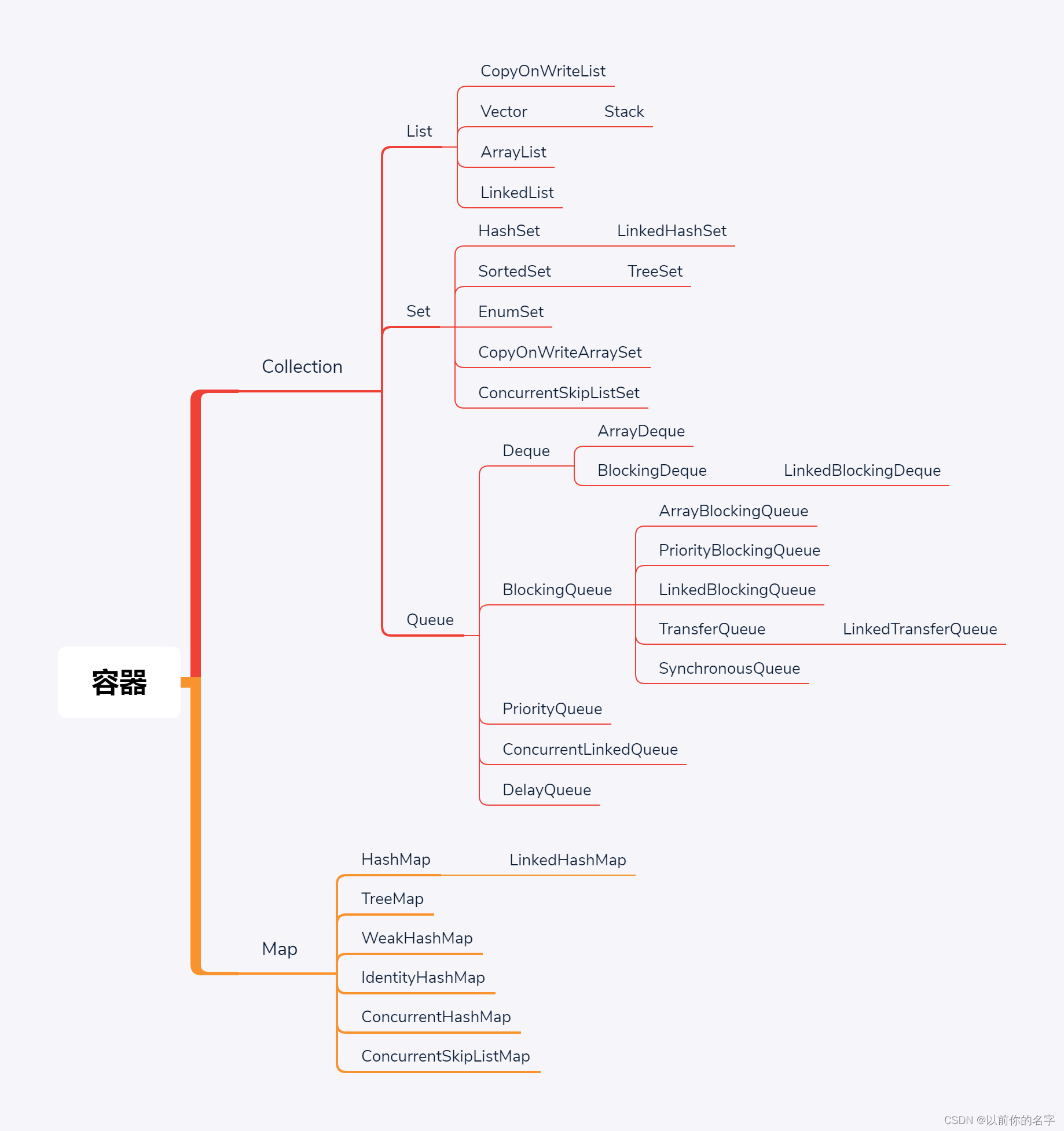
容器这章是面试特别爱问,这个面试属于是高频中的高频,为什么他特别爱问,因为他牵扯的东西太多了,拿大腿想一下也知道容器肯定是往里面装东西的肯定牵扯到数据结构,数据结构肯定要牵扯到算法,还有一点就是容器本身的一个组织结构也是大家比较爱考的,再一点他又牵扯到高并发,这就是面试的一个重灾区。容器这章得用好多个维度来讲他才能理解的比较透彻,今天,主要还是从线程池使用的角度,为了和后面的线程池做准备。这个容器通过接口来说分为两大类,我们先从大体的结构上来认识他。
第一大类Collection叫集合。集合的意思是不管你这个容器是什么结构你可以把一个元素一个元素的往里面扔;Map是一对一对的往里扔。其实Map来说可以看出是Collection一个特殊的变种,你可以把一对对象看成一个entry对象,所以这也是一个整个对象。容器就是装一个一个对象的,这么一些个集合。严格来讲数组也属于容器。从数据结构角度来讲在物理上的这种存储的数据结构其实只有两种,一种是连续存储的数组Array,另一种就是非连续存储的一个指向另外一个的链表。在逻辑结构那就非常非常多了。
ok,容器上来讲JAVA接口区分的比较明确,两大接口:Map是一对一对的。Collection是一个一个的,在它里面又分三大类。在大概十年前我讲的一段老的视频,在那个时候讲的Collection之分两大类List和Set,Queue是后来加入的接口,而这个接口专门就是为高并发准备的,所以这个接口对高并发来说才是最重要的。你要和别人聊面试题的时候,说你聊聊这个容器类吧,好,你就可以从大面开始聊,容器分两大类Collection、Map,Collection又分三大类List、Set、Queue队列,队列就是一对一队的,往这个队列里取数据的时候它和这个List、Set都不一样。大家知道List取的时候如果是Array的话还可以取到其中一个的。Set主要和其他的区别就是中间是唯一的,不会有重复元素,这个它最主要的区别。Queue实现了一个什么逻辑呢,实际上就是一个队列,队列什么概念,有进有出,那么在这个基础之上它实现了很多的多线程的访问方法(比如说put阻塞式的放、take阻塞式的取),这个是在其他的List、Set里面都是没有的。队列最主要的原因是为了实现任务的装载的这种取和装这里面最重要的就是是叫做阻塞队列,它的实现的初衷就是为了线程池、高并发做准备的。原来的这些是容器是普通的为了装东西做准备的。所以你要和别人聊Queue的区别的时候主要就说高并发和普通的这种容器这上面的一个区别,这里面有三个Collection的子接口,在子接口Queue里面又分了各种各样的队列,稍后我们讲到在聊。Queue里面还有一个子接口叫Deque叫双端队列,一般的队列只是从一端往里扔从另一端往外取。Deque就是说你可以从反方向装从另外一个方向取。
Hashtable - CHM
最开始java1.0容器里只有两个,第一个叫Vector可以单独的往里扔,还有一个是Hashtable是可以一对一对往里扔的。Vector相对于实现了List接口,Hashtable实现了Map接口。但是这个两个容器在1.0设计的时候稍微有点问题,这两个容器设计成了所有方法默认都是加synchronized的,这是它最早设计不太合理的地方。多数的时候我们多数的程序只有一个线程在工作,所以在这种情况下你完全是没有必要加synchronized,因此最开始的时候设计的性能比较差,所以后来它意识到了这一点,在Hashtable之后又添加了HashMap,HashMap就是完全的没有加锁,一个是二话没说就加锁,一个是完全没有加锁。那这两个除了这个加锁区别之外 还有其他的一些源码上的区别,所以Sun在那个时候就在这个HashMap的基础之上又添加了一个,说你用的这个新的HashMap比原来Hashtable好用,但是HashMap没有那些锁的东西,那么怎么才可以让这个HashMap既可以用于这些不需要锁的环境,有可以用于需要锁的环境呢? 所以它又添加了一个方法叫做Collections相当于这个容器的工具类,这个工具类里有一个方法叫synchronizedMap,这个方法会把它变成加锁的版本。所以,HashMap有两个版本。
Vector 和 Hashtable 自带锁,基本不用,大家记住这个结论。
- Hashtable
看第一个小程序Hashtable里面装的是什么东西呢,装的都是Key,Value对,一对一对的。这个Key是UUID,Value也是UUID等于new一个Hashtable出来,这里面的UUID到底有多少个呢,我定义了两个常量,这两个常量在一个单独的类里,这个类叫Constants:100万个UUID对内容要装到容器里,会有100个线程,将来我们访问的时候会有100个线程来模拟。
package com.mashibing.juc.c_023_02_FromHashtableToCHM;
public class Constants {
public static final int COUNT = 1000000;
public static final int THREAD_COUNT = 100;
}
这两个值的变化会引起效率上的变化,永远要记住这一点,那个效率高那个效率低不要想当然,务必要写程序来测试,高并发课的后面还会给大家讲一个JMH测试框架。看程序,我先new出100万个Key和100万个Value来,然后把这些东西装到数组里面去,for循环(int i = 0; i < count; i++)。为什么先把这些UUID对准备好而不是我们装的时候现场生成?原因是我们写这个测试用例的时候前后用的是一样的,你往Hashtable里头装的时候也得是这100万对,同样的内容,但你要是每次都生成是不一样的内容,在这种情况下你测试就会有一些干扰因素,所以我们先准备好在往里扔。后面,写了一个线程类,叫MyThread,从Thread继承,start,gap是每个线程负责往里面装多少。线程开始往里面扔。在看后面主程序代码,记录起始时间,new出来一个线程数组,这个线程数据总共有100个线程,给它做初始化。由于你需要指定这个start值,所以这个MyThread启动的时候i乘以count(总而言之就是这个起始的值不一样,第一个线程是从0开始,第二个是从100000个开始)没用到也没关系,用到了就把他记录下来是一个好的习惯。然后让每一个线程启动,等待每一个线程结束,最后计算这个线程时间。
我在重新解释一下,现在我有一个Hashtable,里面装的是一对一对的内容,现在我们起了100个线程,这个100个线程去Key,Value取数据,一个线程取1万个数据,一共100万个数据,100个线程,每个线程取1万个数据往里插,整个程序模拟的是这么一个情形
package com.mashibing.juc.c_023_02_FromHashtableToCHM;
import java.util.Hashtable;
import java.util.UUID;
public class T01_TestHashtable {
static Hashtable<UUID, UUID> m = new Hashtable<>();
static int count = Constants.COUNT;
static UUID[] keys = new UUID[count];
static UUID[] values = new UUID[count];
static final int THREAD_COUNT = Constants.THREAD_COUNT;
static {
for (int i = 0; i < count; i++) {
keys[i] = UUID.randomUUID();
values[i] = UUID.randomUUID();
}
}
static class MyThread extends Thread {
int start;
int gap = count/THREAD_COUNT;
public MyThread(int start) {
this.start = start;
}
@Override
public void run() {
for(int i=start; i<start+gap; i++) {
m.put(keys[i], values[i]);
}
}
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for(int i=0; i<threads.length; i++) {
threads[i] =
new MyThread(i * (count/THREAD_COUNT));
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println(end - start);
System.out.println(m.size());
//-----------------------------------
start = System.currentTimeMillis();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(()->{
for (int j = 0; j < 10000000; j++) {
m.get(keys[10]);
}
});
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
end = System.currentTimeMillis();
System.out.println(end - start);
}
}
HashMap
我们来看这HashMap,同学们想一下这个HashMap往里头插会不会有问题。因为HashMap没有锁啊,线程不安全,这个就没有意义了,这只是为了程序的完整性留在这,他虽然速度比较快,但是数据会出问题,还各种各样的报异常。主要是因为它内部会把这个变成TreeNode,我们先不去细究它,总而言之HashMap这个东西你往里扔的时候,由于它内部没有锁,所以你多线程访问的时候会出问题,这个你往里插的时候就没有实际意义了。
package com.mashibing.juc.c_023_02_FromHashtableToCHM;
import java.util.HashMap;
import java.util.UUID;
public class T02_TestHashMap {
static HashMap<UUID, UUID> m = new HashMap<>();
static int count = Constants.COUNT;
static UUID[] keys = new UUID[count];
static UUID[] values = new UUID[count];
static final int THREAD_COUNT = Constants.THREAD_COUNT;
static {
for (int i = 0; i < count; i++) {
keys[i] = UUID.randomUUID();
values[i] = UUID.randomUUID();
}
}
static class MyThread extends Thread {
int start;
int gap = count/THREAD_COUNT;
public MyThread(int start) {
this.start = start;
}
@Override
public void run() {
for(int i=start; i<start+gap; i++) {
m.put(keys[i], values[i]);
}
}
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for(int i=0; i<threads.length; i++) {
threads[i] =
new MyThread(i * (count/THREAD_COUNT));
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println(end - start);
System.out.println(m.size());
}
}
SynchronizedHashMap
我们在看第三个,用的是SynchronizedMap这个方法,给HashMap我们手动加锁,它的源码自己做了一个Object,然后每次都是SynchronizedObject,严格来讲他和那个Hashtable效率上区别不大。
package com.mashibing.juc.c_023_02_FromHashtableToCHM;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
public class T03_TestSynchronizedHashMap {
static Map<UUID, UUID> m = Collections.synchronizedMap(new HashMap<UUID, UUID>());
static int count = Constants.COUNT;
static UUID[] keys = new UUID[count];
static UUID[] values = new UUID[count];
static final int THREAD_COUNT = Constants.THREAD_COUNT;
static {
for (int i = 0; i < count; i++) {
keys[i] = UUID.randomUUID();
values[i] = UUID.randomUUID();
}
}
static class MyThread extends Thread {
int start;
int gap = count/THREAD_COUNT;
public MyThread(int start) {
this.start = start;
}
@Override
public void run() {
for(int i=start; i<start+gap; i++) {
m.put(keys[i], values[i]);
}
}
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for(int i=0; i<threads.length; i++) {
threads[i] =
new MyThread(i * (count/THREAD_COUNT));
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println(end - start);
System.out.println(m.size());
//-----------------------------------
start = System.currentTimeMillis();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(()->{
for (int j = 0; j < 10000000; j++) {
m.get(keys[10]);
}
});
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
end = System.currentTimeMillis();
System.out.println(end - start);
}
}
ConcurrentHashMap
这个第四个ConcurrentHashMap是多线程里面真正用的,以后我们多线程用的基本就是它,用Map的时候。并发的。这个ConcurrentHashMap提高效率主要提高在读上面,由于它往里插的时候内部又做了各种各样的判断,本来是链表的,到8之后又变成了红黑树,然后里面又做了各种各样的cas的判断,所以他往里插的数据是要更低一些的。HashMap和Hashtable虽然说读的效率会稍微低一些,但是它往里插的时候检查的东西特别的少,就加个锁然后往里一插。所以,关于效率,还是看你实际当中的需求。用几个简单的小程序来给大家列举了这几个不同的区别。
package com.mashibing.juc.c_023_02_FromHashtableToCHM;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.ConcurrentHashMap;
public class T04_TestConcurrentHashMap {
static Map<UUID, UUID> m = new ConcurrentHashMap<>();
static int count = Constants.COUNT;
static UUID[] keys = new UUID[count];
static UUID[] values = new UUID[count];
static final int THREAD_COUNT = Constants.THREAD_COUNT;
static {
for (int i = 0; i < count; i++) {
keys[i] = UUID.randomUUID();
values[i] = UUID.randomUUID();
}
}
static class MyThread extends Thread {
int start;
int gap = count/THREAD_COUNT;
public MyThread(int start) {
this.start = start;
}
@Override
public void run() {
for(int i=start; i<start+gap; i++) {
m.put(keys[i], values[i]);
}
}
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for(int i=0; i<threads.length; i++) {
threads[i] =
new MyThread(i * (count/THREAD_COUNT));
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println(end - start);
System.out.println(m.size());
//-----------------------------------
start = System.currentTimeMillis();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(()->{
for (int j = 0; j < 10000000; j++) {
m.get(keys[10]);
}
});
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
end = System.currentTimeMillis();
System.out.println(end - start);
}
}
From Vector To Queue
ArrayList
我们在认识一下Vector到Queue的发展历程,下面有这样一个小程序叫TicketSeller给票做销售的这么一个小程序,写法比较简单,我们先来用一个List把这些票全装进去,往里面装一万张票,然后10个线程也就是10个窗口对外销售,只要size大于零,只要还有剩余的票时我就往外卖,取一张往外卖remove。大家想象一下到最后一张票的时候,好几个线程执行到这里所以线程都发现了size大于零,所有线程都往外买了一张票,那么会发生什么情形,只有一个线程拿到了这张票,其他的拿到的都是空值,就是超卖的现象。没有加锁,线程不安全。
/**
* 有N张火车票,每张票都有一个编号
* 同时有10个窗口对外售票
* 请写一个模拟程序
*
* 分析下面的程序可能会产生哪些问题?
* 重复销售?超量销售?
*
*
* @author 马士兵
*/
package com.mashibing.juc.c_024_FromVectorToQueue;
import java.util.ArrayList;
import java.util.List;
public class TicketSeller1 {
static List<String> tickets = new ArrayList<>();
static {
for(int i=0; i<10000; i++) tickets.add("票编号" + i);
}
public static void main(String[] args) {
for(int i=0; i<10; i++) {
new Thread(()->{
while(tickets.size() > 0) {
System.out.println("销售了--" + tickets.remove(0));
}
}).start();
}
}
}
Vector
我们来看最早的这个容器Vector,内部是自带锁的,你去读它的时候就会看到很多方法synchronized二话不说先加上锁在说,所以你用Vector的时候请放心它一定是线程安全的。100张票,10个窗口,读这个程序还是有问题的,还是不对。锁为了线程的安全,就是当我们调用size方法的时候他加锁了,调用remove的时候它也加锁了,可是很不幸的是在你这两个中间它没有加锁,那么,好多个线程还会判断依然这个size还是大于0的,大家伙又超卖了。
/**
* 有N张火车票,每张票都有一个编号
* 同时有10个窗口对外售票
* 请写一个模拟程序
*
* 分析下面的程序可能会产生哪些问题?
* 重复销售?超量销售?
*
*
* @author 马士兵
*/
package com.mashibing.juc.c_024_FromVectorToQueue;
import java.util.Vector;
import java.util.concurrent.TimeUnit;
public class TicketSeller2 {
static Vector<String> tickets = new Vector<>();
static {
for(int i=0; i<1000; i++) tickets.add("票编号" + i);
}
public static void main(String[] args) {
for(int i=0; i<10; i++) {
new Thread(()->{
while(tickets.size() > 0) {
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("销售了--" + tickets.remove(0));
}
}).start();
}
}
}
LinkedList
虽然你用了这个加锁的容器了,由于在你调用这个并发容器的时候,你是调用了其中的两个原子方法,所以你在外层还得在加一把锁synchronized(tickets),继续判断size,售出去不断的remove,这个就没有问题了,它会踏踏实实的往外销售,但不是效率最高的方案
package com.mashibing.juc.c_024_FromVectorToQueue;
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.TimeUnit;
public class TicketSeller3 {
static List<String> tickets = new LinkedList<>();
static {
for(int i=0; i<1000; i++) tickets.add("票编号" + i);
}
public static void main(String[] args) {
for(int i=0; i<10; i++) {
new Thread(()->{
while(true) {
synchronized(tickets) {
if(tickets.size() <= 0) break;
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("销售了--" + tickets.remove(0));
}
}
}).start();
}
}
}
Queue
效率最高的就是这个Queue,这是最新的一个接口,他的主要目标就是为了高并发用的,就是为了多线程用的。所以,以后考虑多线程这种单个元素的时候多考虑Queue。看程序前面初始化不说了,这个使用的是ConcurrentLinkedQueue,然后里面并没有说加锁,我就直接调用了一个方法叫poll,poll的意思就是我从tickets去取值,这个值什么时候取空了就说明里面的值已经没了,所以这个while(true)不断的往外销售,一直到他突然发现伸手去取票的时候这里面没了,那我这个窗口就可以关了不用买票了。poll的意思它加了很多对于多线程访问的时候比较友好的一些方法,它的源码,取一下去得到我们这个queue上的头部,脑袋上这个元素,得到并且去除掉这里面这个值,如果这个已经是空我就返回null值。
package com.mashibing.juc.c_024_FromVectorToQueue;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
public class TicketSeller4 {
static Queue<String> tickets = new ConcurrentLinkedQueue<>();
static {
for(int i=0; i<1000; i++) tickets.add("票编号" + i);
}
public static void main(String[] args) {
for(int i=0; i<10; i++) {
new Thread(()->{
while(true) {
String s = tickets.poll();
if(s == null) break;
else System.out.println("销售了--" + s);
}
}).start();
}
}
}
这个四个小程序就给大家演示了怎么从Vector一步一步演化到Queue的,所以刚才讲的这八个小程序,主要是为了给大家说明整体的这个演化的过程是一个什么样子的,从Map这个角度来讲最早是从Hashtable,二话不说先加锁到HashMap去除掉锁,再到synchronizedHashMap加一个带锁的版本,到ConcurrentHashMap多线程时候专用。注意,不是替代关系,这个归根结底还是会归到,到底cas操作就一定会比synchronized效率要高吗,不一定,要看你并发量的高低,要看你锁定之后代码执行的时间,任何时候在你实际情况下都需要通过测试,压测来决定用哪种容器。
讲到这里,在给大家扩展一下,设计上方法有一种叫面向接口编程,为什么要面向接口编程,如果说你在工作之中设计一个程序,这个程序你应该设计一个接口,这个接口里面只包括业务逻辑,取出学生列表,放好,但是这里列表具体的实现是放到Hashtable里面还是放到HashMap里面还是放到ConcurrentHashMap里面,你可以写好几个不同的实现,在不同的并发情况下采用不同的实现你的程序会更灵活,在这里你们能不能理解就是这种面向接口的编程和面向接口的设计它的微妙之所在。
ConcurrentMap
我们来看这个经常在多线程的情况下使用的这些个容器 ,从Map开始讲,Map经常用的有这么几个
-
ConcurrentHashMap用hash表实现的这样一个高并发容器;
既然有了ConcurrentHashMap正常情况下就应该有ConcurrentTreeMap,你可以去查查,它没有,就等于缺了一块,为什么没有呢,原因就是ConcurrentHashMap里面用的是cas操作,这个cas操作它用在tree的时候,用在树这个节点上的时候实现起来太复杂了,所以就没有这个ConcurrentTreeMap,但是有时间也需要这样一个排好序的Map,那就有了ConcurrentSkipListMap跳表结构就出现了。
-
ConcurrentSkipListMap通过跳表来实现的高并发容器并且这个Map是有排序的;
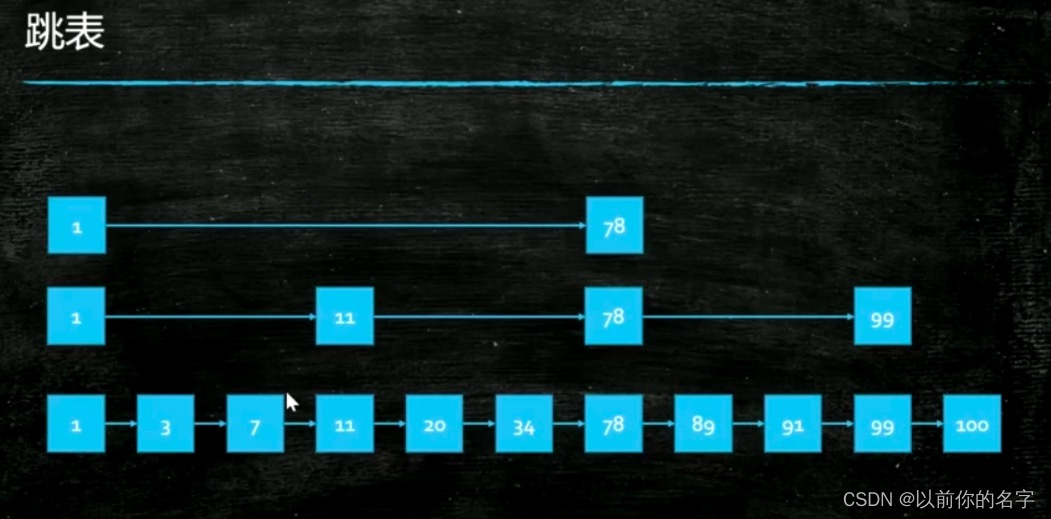
跳表是什么样的结构呢?底层本身存储的元素一个链表,它是排好顺序的,大家知道当一个链表排好顺序的时候往里插入是特别困难的,查找的时候也特别麻烦,因为你得从头去遍历查找这个元素到底在哪里,所以就出现了这个跳表的结构,底层是一个链表,链表查找的时候比较困难怎么办,那么我们在这些链表的基础上在拿出一些关键元素来,在上面做一层,那这个关键元素的这一层也是一个链表,那这个数量特别大的话在这个基础之上在拿一层出来再做一个链表,每层链表的数据越来越少,而且它是分层,在我们查找的时候从顶层往下开始查找,所以呢,查找容易了很多,同时它无锁的实现难度比TreeMap又容易很多,因此在JUC里面提供了ConcurrentSkipListMap这个类。
他们两个的区别一个是有序的一个是无序的,同时都支持并发的操作。下面这个小程序是一个效率的测试其实也没多大意义,大家可以去写一下跑跑。
package com.mashibing.juc.c_025;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentSkipListMap;
import java.util.concurrent.CountDownLatch;
public class T01_ConcurrentMap {
public static void main(String[] args) {
Map<String, String> map = new ConcurrentHashMap<>();
//Map<String, String> map = new ConcurrentSkipListMap<>(); //高并发并且排序
//Map<String, String> map = new Hashtable<>();
//Map<String, String> map = new HashMap<>(); //Collections.synchronizedXXX
//TreeMap
Random r = new Random();
Thread[] ths = new Thread[100];
CountDownLatch latch = new CountDownLatch(ths.length);
long start = System.currentTimeMillis();
for(int i=0; i<ths.length; i++) {
ths[i] = new Thread(()->{
for(int j=0; j<10000; j++) map.put("a" + r.nextInt(100000), "a" + r.nextInt(100000));
latch.countDown();
});
}
Arrays.asList(ths).forEach(t->t.start());
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println(end - start);
System.out.println(map.size());
}
}
CopyOnWrite
再来说一个在并发的时候经常使用的一个类,这个类叫CopyOnWrite。CopyOnWriteList、CopyOnWriteSet有两个。CopyOnWrite的意思叫写时复制。
我们看这个小程序,用了一个容器,这个容器是List,一个一个元素往里装,往里装的时候,装的一堆的数组,一堆的字符串,没100个线程往里面装1000个,各种各样的实现,可以用ArrayList、Vector,但是ArrayList会出并发问题,因为多线程访问没有锁,可以用CopyOnWriteArrayList。这个CopyOnWrite解释一下,你通过这个名字进行分析一下,当Write的时候我们要进行复制,写时复制,写的时候进行复制。这个原理非常简单,当我们需要往里面加元素的时候你把里面的元素得复制出来。在很多情况下,写的时候特别少,读的时候很多。在这个时候就可以考虑CopyOnWrite这种方式来提高效率,CopyOnWrite为什么会提高效率呢,是因为我写的时候不加锁,大家知道我Vector写的时候加锁,读的时候也加锁。那么用CopyOnWriteList的时候我读的时候不加锁,写的时候会在原来的基础上拷贝一个,拷贝的时候扩展出一个新元素来,然后把你新添加的这个扔到这个元素扔到最后这个位置上,于此同时把指向老的容器的一个引用指向新的,这个写法就是写时复制。我这里只是写了一个写线程,没有模拟读线程,这个写时复制,写的效率比较低,因为每次写都要复制。在读比较多写比较少的情况下使用CopyOnWrite。
package com.mashibing.juc.c_025;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Random;
import java.util.Vector;
import java.util.concurrent.CopyOnWriteArrayList;
public class T02_CopyOnWriteList {
public static void main(String[] args) {
List<String> lists =
//new ArrayList<>(); //这个会出并发问题!
//new Vector();
new CopyOnWriteArrayList<>();
Random r = new Random();
Thread[] ths = new Thread[100];
for(int i=0; i<ths.length; i++) {
Runnable task = new Runnable() {
@Override
public void run() {
for(int i=0; i<1000; i++) lists.add("a" + r.nextInt(10000));
}
};
ths[i] = new Thread(task);
}
runAndComputeTime(ths);
System.out.println(lists.size());
}
static void runAndComputeTime(Thread[] ths) {
long s1 = System.currentTimeMillis();
Arrays.asList(ths).forEach(t->t.start());
Arrays.asList(ths).forEach(t->{
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long s2 = System.currentTimeMillis();
System.out.println(s2 - s1);
}
}
CopyOnWrite对比的是synchronizedList,这方面的一个对比。
package com.mashibing.juc.c_025;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class T03_SynchronizedList {
public static void main(String[] args) {
List<String> strs = new ArrayList<>();
List<String> strsSync = Collections.synchronizedList(strs);
}
}
BlockingQueue
BlockingQueue,是我们后面讲线程池需要用到的这方面的内容,是给线程池来做准备的。BlockingQueue的概念重点是在Blocking上,Blocking阻塞,Queue队列,是阻塞队列。他提供了一系列的方法,我们可以在这些方法的基础之上做到让线程实现自动的阻塞。
我们现在聊的就是这个Queue里面所提供的一些可以给多线程比较友好的接口。他提供了一些什么接口呢,第一个就是offer对应的是原来的那个add,提供了poll取数据,然后提供了peek拿出来这个数据。那么这个是什么意思呢,我们读一下这个offer的概念,offer是往里头添加,加进去没加进去它会给你一个布尔类型的返回值,和原来的add是什么区别呢,add如果加不进去了是会抛异常的。所以一般的情况下我们用的最多的Queue里面都用offer,它会给你一个返回值,peek的概念是去取并不是让你remove掉,poll是取并且remove掉,而且这几个对于BlockingQueue来说也确实是线程安全的一个操作。对于Queue经常用的接口就这么几个,大家了解就可以。
package com.mashibing.juc.c_025;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
public class T04_ConcurrentQueue {
public static void main(String[] args) {
Queue<String> strs = new ConcurrentLinkedQueue<>();
for(int i=0; i<10; i++) {
strs.offer("a" + i); //add
}
System.out.println(strs);
System.out.println(strs.size());
System.out.println(strs.poll());
System.out.println(strs.size());
System.out.println(strs.peek());
System.out.println(strs.size());
//双端队列Deque
}
}
LinkedBlockingQueue
LinkedBlockingQueue,体现Concurrent的这个点在哪里呢,我们来看这个LinkedBlockingQueue,用链表实现的BlockingQueue,是一个无界队列。就是它可以一直装到你内存满了为止,一直添加。
来看一下这个小程序,这么一些线程,第一个线程是我往里头加内容,加put。BlockingQueue在Queue的基础上又添加了两个方法,这两个方法一个叫put,一个叫take。这两个方法是真真正正的实现了阻塞。put往里装如果满了的话我这个线程会阻塞住,take往外取如果空了的话线程会阻塞住。所以这个BlockingQueue就实现了生产者消费者里面的那个容器。这个小程序是往里面装了100个字符串,a开头i结尾,每装一个的时候睡1秒钟。然后,后面又启动了5个线程不断的从里面take,空了我就等着,什么时候新加了我就马上给它取出来。这是BlockingQueue和Queue的一个基本的概念。
package com.mashibing.juc.c_025;
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;
public class T05_LinkedBlockingQueue {
static BlockingQueue<String> strs = new LinkedBlockingQueue<>();
static Random r = new Random();
public static void main(String[] args) {
new Thread(() -> {
for (int i = 0; i < 100; i++) {
try {
strs.put("a" + i); //如果满了,就会等待
TimeUnit.MILLISECONDS.sleep(r.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "p1").start();
for (int i = 0; i < 5; i++) {
new Thread(() -> {
for (;;) {
try {
System.out.println(Thread.currentThread().getName() + " take -" + strs.take()); //如果空了,就会等待
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "c" + i).start();
}
}
}
ArrayBlockingQueue
ArrayBlockingQueue是有界的,你可以指定它一个固定的值10,它容器就是10,那么当你往里面扔容器的时候,一旦他满了这个put方法就会阻塞住。然后你可以看看用add方法满了之后他会报异常。offer用返回值来判断到底加没加成功,offer还有另外一个写法你可以指定一个时间尝试着往里面加1秒钟,1秒钟之后如果加不进去它就返回了。
回到那个面试经常被问到的问题,Queue和List的区别到底在哪里,主要就在这里,添加了offer、peek、poll、put、take这些个对线程友好的或者阻塞,或者等待方法。
package com.mashibing.juc.c_025;
import java.util.Random;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
public class T06_ArrayBlockingQueue {
static BlockingQueue<String> strs = new ArrayBlockingQueue<>(10);
static Random r = new Random();
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
strs.put("a" + i);
}
//strs.put("aaa"); //满了就会等待,程序阻塞
//strs.add("aaa");
//strs.offer("aaa");
strs.offer("aaa", 1, TimeUnit.SECONDS);
System.out.println(strs);
}
}
继续,我们来看几个比较特殊的Queue,这几个Queue是BlockingQueue,全是阻塞的,记住这点。这几种Queue都有特殊的用途,往下看。
DelayQueue
DelayQueue可以实现在时间上的排序,这个DelayQueue能实现按照在里面等待的时间来进行排序。这里我们new了一个DelayQueue,他是BlockingQueue的一种也是用于阻塞的队列,这个阻塞队列装任务的时候要求你必须实现Delayed接口,Delayed往后拖延推迟,Delayed需要做一个比较compareTo,最后这个队列的实现,这个时间等待越短的就会有优先的得到运行,所以你需要做一个比较 ,这里面他就有一个排序了,这个排序是按时间来排的,所以去做好,哪个时间返回什么样的值,不同的内容比较的时候可以按照时间来排序。如果你对compareTo和Comparable不理解的话可以去翻找以前老师讲的策略模式。总而言之,你要实现Comparable接口重写 compareTo方法来确定你这个任务之间是怎么排序的。getDelay去拿到你Delay多长时间了。往里头装任务的时候首先拿到当前时间,在当前时间的基础之上指定在多长时间之后这个任务要运行,添加顺序参看代码,但是当我们去拿的时候,一般的队列是先加那个先往外拿那个,先进先出。这个队列是不一样的,按时间进行排序(按紧迫程度进行排序)。DelayQueue就是按照时间进行任务调度。
package com.mashibing.juc.c_025;
import java.util.Calendar;
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
public class T07_DelayQueue {
static BlockingQueue<MyTask> tasks = new DelayQueue<>();
static Random r = new Random();
static class MyTask implements Delayed {
String name;
long runningTime;
MyTask(String name, long rt) {
this.name = name;
this.runningTime = rt;
}
@Override
public int compareTo(Delayed o) {
if(this.getDelay(TimeUnit.MILLISECONDS) < o.getDelay(TimeUnit.MILLISECONDS))
return -1;
else if(this.getDelay(TimeUnit.MILLISECONDS) > o.getDelay(TimeUnit.MILLISECONDS))
return 1;
else
return 0;
}
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(runningTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
@Override
public String toString() {
return name + " " + runningTime;
}
}
public static void main(String[] args) throws InterruptedException {
long now = System.currentTimeMillis();
MyTask t1 = new MyTask("t1", now + 1000);
MyTask t2 = new MyTask("t2", now + 2000);
MyTask t3 = new MyTask("t3", now + 1500);
MyTask t4 = new MyTask("t4", now + 2500);
MyTask t5 = new MyTask("t5", now + 500);
tasks.put(t1);
tasks.put(t2);
tasks.put(t3);
tasks.put(t4);
tasks.put(t5);
System.out.println(tasks);
for(int i=0; i<5; i++) {
System.out.println(tasks.take());
}
}
}
DelayQueue本质上用的是一个PriorityQueue,PriorityQueue是从AbstractQueue继承的。PriorityQueue特点是它内部你往里装的时候并不是按顺序往里装的,而是内部进行了一个排序。按照优先级,最小的优先。它内部实现的结构是一个二叉树,这个二叉树可以认为是堆排序里面的那个最小堆值排在最上面。
package com.mashibing.juc.c_025;
import java.util.PriorityQueue;
public class T07_01_PriorityQueque {
public static void main(String[] args) {
PriorityQueue<String> q = new PriorityQueue<>();
q.add("c");
q.add("e");
q.add("a");
q.add("d");
q.add("z");
for (int i = 0; i < 5; i++) {
System.out.println(q.poll());
}
}
}
SynchronousQueue
SynchronousQueue容量为0,就是这个东西它不是用来装内容的,SynchronousQueue是专门用来两个线程之间传内容的,给线程下达任务的,老师讲过一个容器叫Exchanger还有印象吗,本质上这个容器的概念是一样的。看下面代码,有一个线程起来等着take,里面没有值一定是take不到的,然后就等着。然后当put的时候能取出来,take到了之后能打印出来,最后打印这个容器的size一定是0,打印出aaa来这个没问题。那当把线程注释掉,在运行一下程序就会在这阻塞,永远等着。如果add方法直接就报错,原因是满了,这个容器为0,你不可以往里面扔东西。这个Queue和其他的很重要的区别就是你不能往里头装东西,只能用来阻塞式的put调用,要求是前面得有人等着拿这个东西的时候你才可以往里装,但容量为0,其实说白了就是我要递到另外一个的手里才可以。这个SynchronousQueue看似没有用,其实不然,SynchronousQueue在线程池里用处特别大,很多的线程取任务,互相之间进行任务的一个调度的时候用的都是它。
package com.mashibing.juc.c_025;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.SynchronousQueue;
public class T08_SynchronusQueue { //容量为0
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> strs = new SynchronousQueue<>();
new Thread(()->{
try {
System.out.println(strs.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
strs.put("aaa"); //阻塞等待消费者消费
//strs.put("bbb");
//strs.add("aaa");
System.out.println(strs.size());
}
}
TransferQueue
TransferQueue传递,实际上是前面这各种各样Queue的一个组合,它可以给线程来传递任务,以此同时不像是SynchronousQueue只能传递一个,TransferQueue做成列表可以传好多个。比较牛X的是它添加了一个方法叫transfer,如果我们用put就相当于一个线程来了往里一装它就走了。transfer就是装完在这等着,阻塞等有人把它取走我这个线程才回去干我自己的事情。一般使用场景:是我做了一件事情,我这个事情要求有一个结果,有了这个结果之后我可以继续进行我下面的这个事情的时候,比方说我付了钱,这个订单我付账完成了,但是我一直要等这个付账的结果完成才可以给客户反馈。
package com.mashibing.juc.c_025;
import java.util.concurrent.LinkedTransferQueue;
public class T09_TransferQueue {
public static void main(String[] args) throws InterruptedException {
LinkedTransferQueue<String> strs = new LinkedTransferQueue<>();
new Thread(() -> {
try {
System.out.println(strs.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
strs.transfer("aaa");
//strs.put("aaa");
/*new Thread(() -> {
try {
System.out.println(strs.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();*/
}
}
容器这章主要还是为了后面的线程池,由于这章呢它不单单牵扯到高并发,还会牵扯到算法和数据结构,所以很多时候对与容器的理解你要分多方面去解读它。
讲的内容总结一下,讲了什么内容呢
-
从Hashtable一直到这个ConcurrentHashMap,这些不是一个替代的关系,它们各自有各自的用途
-
Vector到Queue的这样的一个过程,这里面经常问的面试题就是Queue到List的区别到底在哪里需要大家记住
区别主要就是Queue添加了许多对线程友好的API offer、peek、poll,他的一个子类型叫BlockingQueue对线程友好的API又添加了put和take,这两个实现了阻塞操作。
-
DelayQueue SynchronousQ TransferQ















 141
141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









