







Hive中提供了类似于SQL语言的查询语言——HiveQL,可以通过 HiveQL语句快速实现简单的 MapReduce统计, Hive 自身可以将 HiveQL 语句快速转换成 MapReduce 任务进行运行,而不必开发专门的 MapReduce 应用程序,因而十分适合数据仓库的统计分析。 通过一个简单的词频统计来初步认识hive
1.本地创建两个文本文件
cd /usr/local/hadoop/input
echo “hello world”> file1.txt
echo “hello hadoop”> file2.txt
2.将文件上传至hdfs中(因为hive的的操作是基于hdfs文件系统)
./bin/hdfs dfs -mkdir -p /wordcount/input
./bin/hdfs dfs -put /usr/local/hadoop/input/*.txt /wordcount/input
3.在hive下通过如下HiveQL语句实现统计功能
create table wordcount(line string); //表有一个string类型的字段
load data inpath '/wordcount/input' overwrite into table wordcount ; //把数据导入到wordcount表
create table word_count as
select word,count(1) as count from
(select explode(split(line,' ')) as word from wordcount) w //通过explode函数把wordcount表变成字段为word的w表
group by word
order by word;
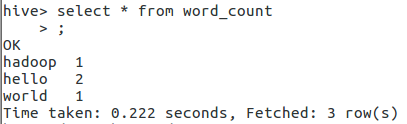
4.查找结果
select * from word_count;















 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









