







Hive中提供了类似于SQL语言的查询语言——HiveQL,可以通过 HiveQL语句快速实现简单的 MapReduce统计, Hive 自身可以将 HiveQL 语句快速转换成 MapReduce 任务进行运行,而不必开发专门的 MapReduce 应用程序,因而十分适合数据仓库的统计分析。
下面介绍如何使用Hive进行词频统计。
实验步骤
- 本地创建两个文本文件
cd /usr/local/hadoop/input
echo 'hello world' >> file1.txt
echo 'hello hadoop' >> file2.txt
- 将文件上传至hdfs中(因为hive的的操作是基于hdfs文件系统)
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put /usr/local/hadoop/input/*.txt /wordcount/input
- 在hive下通过如下HiveQL语句实现统计功能
//表有一个string类型的字段
create table wordcount(line string);
//把数据导入到wordcount表
load data inpath '/wordcount/input' overwrite into table wordcount ;
//利用hive查询功能实现词频统计
//其中explode函数把wordcount表变成字段为word的w表
create table word_count as
select word,count(1) as count from
(select explode(split(line,' ')) as word from wordcount) w
group by word
order by word;
- 查找结果
select * from word_count;
针对步骤3中HIve sql语句讲解
- 首先创建一个普通表,只有一个字段line,类型为string。
create table wordcount(line string);
- 然后把数据导入到wordcount表
load data inpath '/wordcount/input' overwrite into table wordcount ;
此时导入后的样式大概是这样。

- 然后我们利用hive查询功能实现词频统计
首先呢,我们先一起回忆一下sql语句基本常识。
①as 可理解为:用作,当成,作为,或者更通俗的意思就是起别名;
②explode(split(line,’ ')) ,这个函数可以实现一行转多行的操作。
怎么说呢?看个例子。

这样一个表,此时呢我想把student中以逗号隔开的学生名字单独列出,也就是每个学生作为单独一条记录出现。此时就会用到它:explode(split(student,’,’))
转换后的样式如下:

明白了以上两点就基本可以读懂下面这条语句了。
create table word_count as
select word,count(1) as count from
(select explode(split(line,' ')) as word from wordcount) w
group by word
order by word;
- 从wordcount表中把单词以空格分开并独立成行作为一条记录,赋给(as)字段名word,并把select出来的东西作为临时表w。
(select explode(split(line,' ')) as word from wordcount) w
select出来的样式如下:
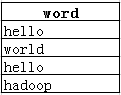
2. 在临时表w再次进行查询,用聚合函数count()统计每个单词出现的次数并赋给(as)字段名count,并按照word字段进行排序。
select word,count(1) as count from
(select explode(split(line,' ')) as word from wordcount) w
group by word
order by word;
注意:①count(1)等价于count(*),统计
②count()函数配合group by使用效果就是把同字段下相同的值合并为一个并统计出现的次数。
此时得到的表如下:
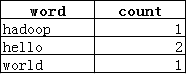
3. 最后再将上面这个表赋予(as)一个名字word_count。
得到结果如下:
create table word_count as
select word,count(1) as count from
(select explode(split(line,' ')) as word from wordcount) w
group by word
order by word;
同时这也就是最后查询出来的结果。


















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











