







hi~大家好,最近疫情慢慢控制,各城市也开始逐步复工。风雨终究会过去,但是依然还是要努力,不管是在什么时候。
好了,本篇我们学习堆排序。啥子叫堆排序呢?
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。今天我们就能把二叉堆的知识用上啦。
还记得二叉堆的特性是什么吗?
- 最大堆的堆顶是整个堆中的最大元素。
- 最小堆的堆顶是整个堆中的最小元素。
以最大堆为例,如果删除一个最大堆的堆顶(并不是完全删除,而是跟末尾的节点交换位置),经过自我调整,第2大的元素就会被交换上来,成为最大堆的新堆顶。
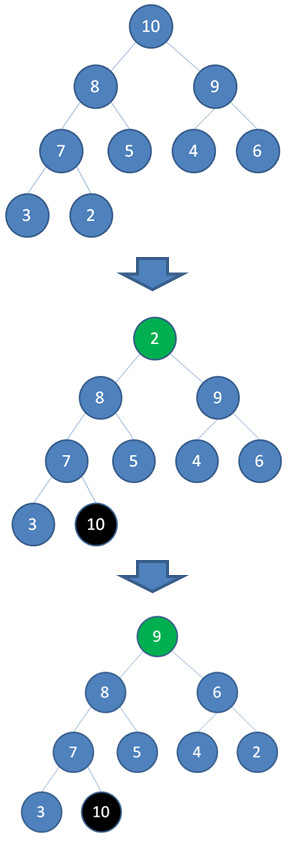
正如上图所示,当我们删除值为10的堆顶节点,经过调节,值为9的新节点就会顶替上来;当我们删除值为9的堆顶节点,经过调节,值为8的新节点就会顶替上来.......
由于二叉堆的这个特性,我们每一次删除旧堆顶,调整后的新堆顶都是大小仅次于旧堆顶的节点。那么我们只要反复删除堆顶,反复调节二叉堆,所得到的集合就成为了一个有序集合。
由此,我们可以归纳出堆排序算法的步骤:
- 把无序数组构建成二叉堆。
- 循环删除堆顶元素,移到集合尾部,调节堆产生新的堆顶。
那么具体代码是如何实现的呢?
public class HeapSort {
/**
* 下沉调整
* @param array
* @param parentIndex
* @param length
*/
public static void downAdjust(int[] array,int parentIndex,int length){
//temp 保存父节点值,用于最后赋值
int temp=array[parentIndex];
int childIndex=2*parentIndex+1;
while (childIndex<length){
//如果有右孩子,且右孩子大于左孩子,则定位到右孩子
if (childIndex+1<length&&array[childIndex+1]>array[childIndex]){
childIndex++;
}
//如果父节点小于任何一个孩子的值,直接跳出
if (temp>=array[childIndex]){
break;
}
//无须真正交换,单向赋值即可
array[parentIndex]=array[childIndex];
parentIndex=childIndex;
childIndex=2*childIndex+1;
}
array[parentIndex]=temp;
}
public static void heapSort(int[] array){
//1.把无序数组构建成二叉堆。
for (int i = (array.length-2)/2; i >=0 ; i--) {
downAdjust(array,i,array.length);
}
System.out.println(Arrays.toString(array));
//2.虚幻删除对顶元素,移到集合尾部,调节对产生的新的堆顶。
for (int i = array.length-1; i >0 ; i--) {
//最后一个元素和第一个元素进行交换
int temp=array[i];
array[i]=array[0];
array[0]=temp;
//下沉调整最大堆
downAdjust(array,0,i);
}
}
public static void main(String[] args) {
int[] ints = {1, 3, 5, 7, 9, 8, 6, 4, 2, 10, 0};
heapSort(ints);
System.out.println(Arrays.toString(ints));
}
}二叉堆的节点下沉调整(downAdjust 方法)是堆排序算法的基础,这个调节操作本身的时间复杂度是多少呢?
假设二叉堆总共有n个元素,那么下沉调整的最坏时间复杂度就等同于二叉堆的高度,也就是O(logn)。
我们再来回顾一下堆排序算法的步骤:
1. 把无序数组构建成二叉堆。
2. 循环删除堆顶元素,移到集合尾部,调节堆产生新的堆顶。
第一步,把无序数组构建成二叉堆,需要进行n/2次循环。每次循环调用一次 downAdjust 方法,所以第一步的计算规模是 n/2 * logn,时间复杂度O(nlogn)。
第二步,需要进行n-1次循环。每次循环调用一次 downAdjust 方法,所以第二步的计算规模是 (n-1) * logn ,时间复杂度 O(nlogn)。
两个步骤是并列关系,所以整体的时间复杂度同样是 O(nlogn)。
堆排序的实际应用场景呢?
有一个经典的算法题:给定一个无序数组,要求找出前k个最大的数,这里可以使用堆排序的思路来实现。
好了堆排序的学习就到这里啦。















 2416
2416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









