




 RocketMQ是一个消息中间件,提供应用解耦、流量削峰填谷等功能。其角色包括Producer、Consumer、Broker和Name Server。RocketMQ支持多种消费模式,如集群和广播模式,并具备高可用机制,如主从复制。消息存储采用顺序写入和零拷贝技术,保证高效。 RocketMQ还提供顺序消息、延迟消息、批量消息、过滤消息和事务消息等功能。在消息重复和消费一致性方面,RocketMQ有相应的处理策略。
RocketMQ是一个消息中间件,提供应用解耦、流量削峰填谷等功能。其角色包括Producer、Consumer、Broker和Name Server。RocketMQ支持多种消费模式,如集群和广播模式,并具备高可用机制,如主从复制。消息存储采用顺序写入和零拷贝技术,保证高效。 RocketMQ还提供顺序消息、延迟消息、批量消息、过滤消息和事务消息等功能。在消息重复和消费一致性方面,RocketMQ有相应的处理策略。
Mq的优点:
- 应用解耦
- 流量的削峰填谷
- 数据分发(将数据发送到多个系统)
- 异步处理
Mq的缺点:
- 系统可用性降低
使用mq后引用外部依赖增多,mq挂了将会影响应用的可用性
- 系统复杂度提高
消息的重复消费、Exactly-Once问题、消息消费顺序问题、消息丢失问题
- 一致性问题
多个系统同时处理消息,其中一个系统失败,整个系统一致性如何保证
常用MQ比较:
| 特性 | RabbitMq | RocketMQ | Kafka |
| 开发语言 | Erlang | Java | Scala 和 Java |
| 成熟度 | 成熟 | 比较成熟 | 成熟的日志领域 |
| 时效性 | 微秒级 | 毫秒级 | 毫秒级 |
| 社区活跃度 | 高 | 高 | 高 |
| 单机吞吐量 | 5.9W/S,CPU资源消耗较高;消息持久化场景下在2.6w/s左右 | 11.6w/s,RocketMQ 的消息写入内存后即返回ack,由单独的线程专门做刷盘的操作,所有的消息均是顺序写文件。(内存消耗相对较大) | 17.3w/s,这主要取决于它的队列模式保证了写磁盘的过程是线性IO。此时broker磁盘IO已达瓶颈。(cpu消耗相对较大) |
| topic数量对吞吐量的影响 | topic可以达到几百,几千个的级别,吞吐量会有较小幅度的下降这是 RocketMQ的一大优势,在同等机器下,可以支撑大量的topic | topic 从几十个到几百个的时候,吞吐量会大幅度下降所以在同等机器下,kafka 尽量保证 topic 数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源 | |
| 可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 以 broker 为中心,有消息的确认机制 | 经过参数优化配置,可以做到0丢失 | 经过参数优化配置,消息可以做到0丢失。以 consumer 为中心,无消息的确认机制 |
| 功能支持 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
RocketMQ角色:
- Producer: 消息生产者
- Consumer: 消息消费者
- Broker: 消息存储中心,主要作用是接收来自 Producer 的消息并存储, Consumer 从这里取得消息。Broker上存储着多个topic的消息。
- Name Server: 保存 Broker 相关 Topic 等元信息并给 Producer ,提供 Consumer 查找 Broker 信息。(类似于注册中心)
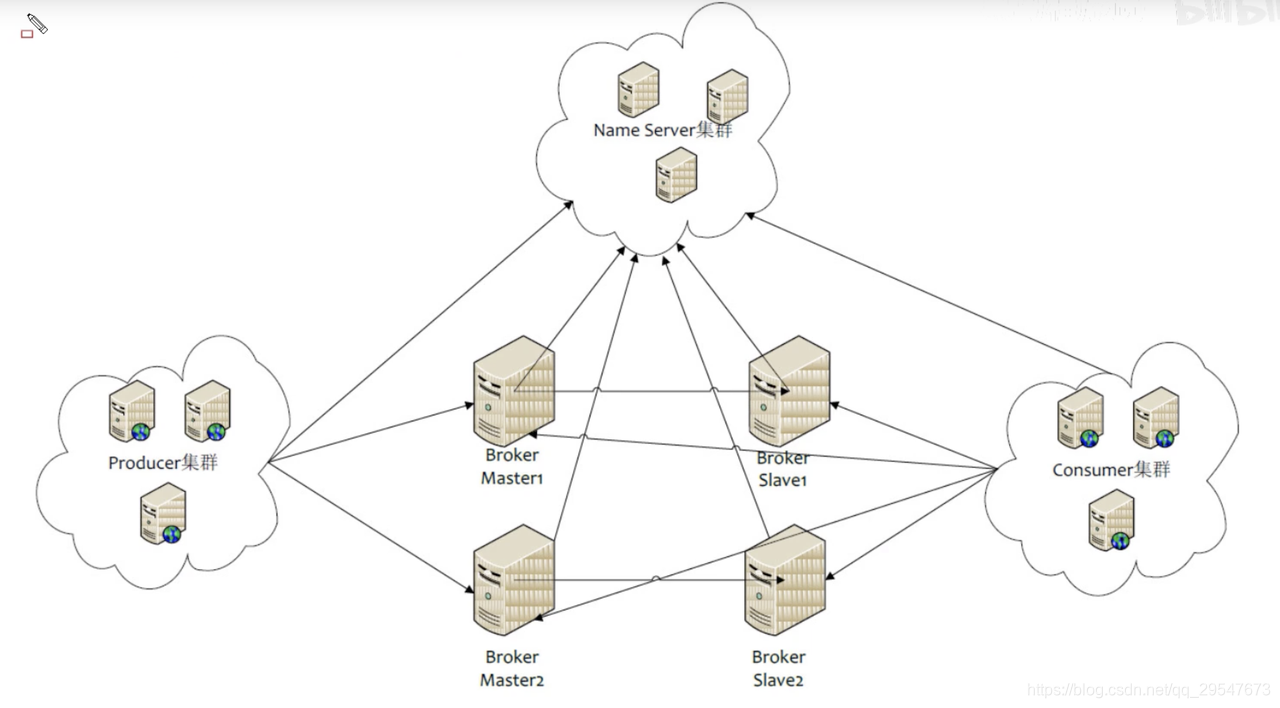
- Topic: 区分不同的消息的类别;一个topic可以多个Producer生产,也可以多个Consumer消费。
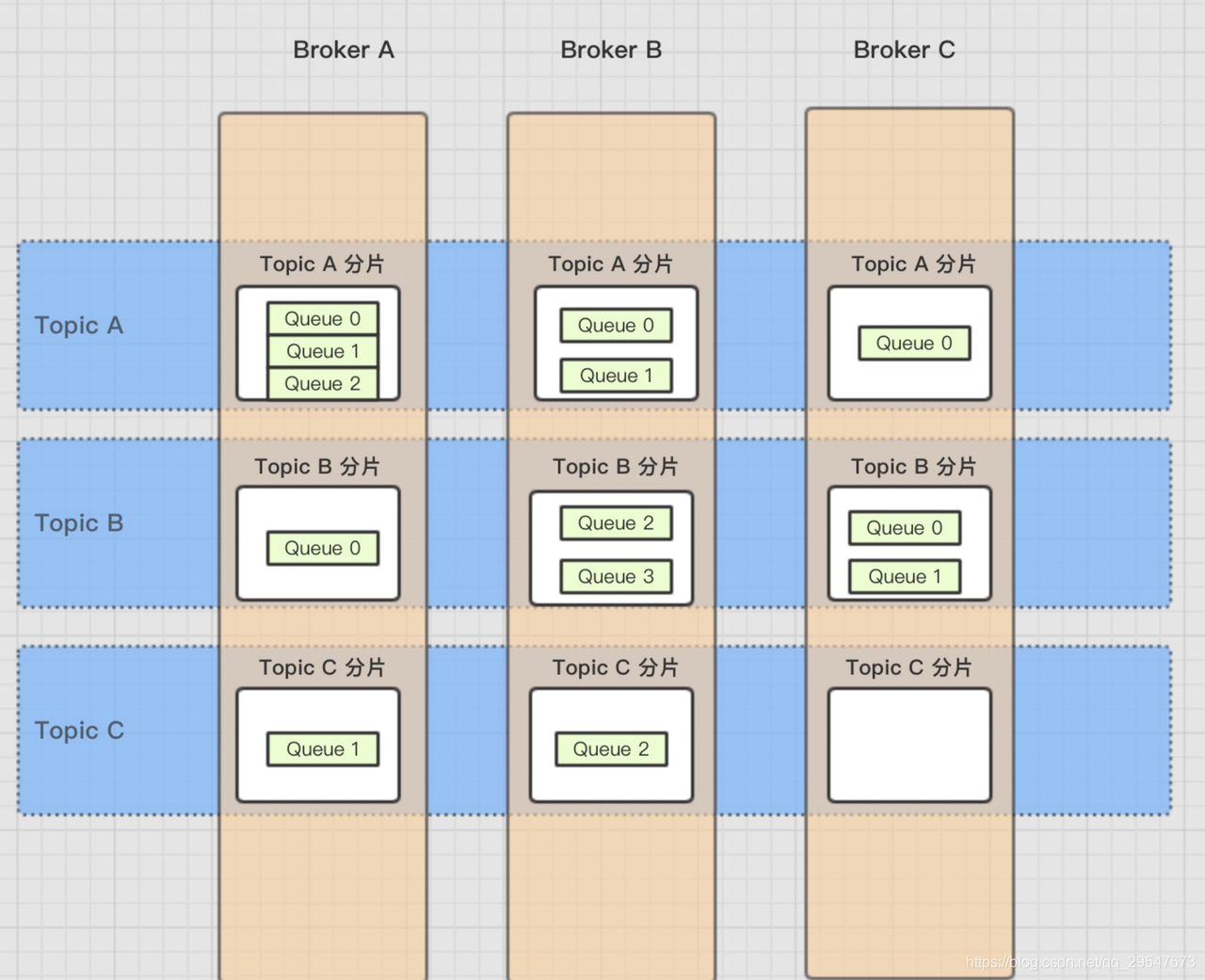
- Message Queue: Message是在每个Broker上以Queue的形式记录。同一个topic有多个队列存储消息,消息在队列里有序,不同队列的数据相对无序。
- Tag:消息标签,用来进一步区分某个 Topic 下的消息分类,消息队列 RocketMQ 允许消费者按照 Tag 对消息进行过滤,确保消费者最终只消费到他关注的消息类型。
集群特点:
- Name Server:
- 几乎无状态,多个节点之间无需同步。
- Broker加入时向每一个NameServer都发送注册信息,每个Broker定时发送topic信息
- Broker:
- 区分主从,一主对应多从,一从对应一主。主节点既可消费数据,也可生产数据,从节点只能让Consumer消费数据。
- 主从节点通过指定相同的BrokerName,不同的BrokerID,BrokerID为0就是主节点,非0就是从节点。
- 与所有的NameServer保持长连接,定时向NameServer发送心跳与topic信息。
- 当Broker挂掉;NameServer会根据心跳超时主动关闭连接,一旦连接断开,会更新Topic与队列的对应关系,但不会通知生产者和消费者。
- 一个Topic分布在多个Broker上,一个Broker可以配置多个Topic,它们是多对多的关系。
- 如果某个Topic消息量很大,应该给它多配置几个Queue,并且尽量多分布在不同Broker上,减轻某个Broker的压力。
- Salve定时从Master同步数据,如果Master宕机,则Slave提供消费服务,但是不能写入消息,此过程对应用透明,由RocketMQ内部解决。
- Producer:
- 通过与NameServer中的某一节点(随机选择)建立长连接,定期从NameServer获取Topic的信息,并与提供信息的Topic的主节点建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。
- 单个Producer和一台NameServer保持长连接,如果该NameServer挂掉,生产者会自动连接下一个NameServer,直到有可用连接为止,并能自动重连。
- 单个生产者和该生产者关联的所有broker保持长连接。
- 与Master定时发送心跳
- Consumer:
- 通过与NameServer中的某一节点(随机选择)建立长连接,定期从NameServer获取Topic的信息。
- 如果该NameServer挂掉,消费者会自动连接下一个NameServer,直到有可用连接为止,并能自动重连。
- 单个消费者和该消费者关联的所有broker保持长连接。
- Consumer会向Broker发送心跳信息,心跳信息中包含了当前消费者的订阅信息。
消费模式:
- 集群模式:
- 同一消费者组内默认集群模式,即同一消费者组内的多个消费者竞争消费数据,ack确认由broker完成
- 广播模式:
- 同一消费者组内的所有消费者均可消费对应topic的所有数据,不存在竞争消费。偏移量控制由消费者控制
拉取模式:
消息类型:
- 顺序消息:
- rocketMq的消息存储在队列中,数据先进先出,但一个topic对应多个queue,每个queue一个队列存储,对于多queue的数据,只能保证局部有序,即同一queue数据先进先出,全局有序性无法保证。若需要全局有序,可考虑一个topic只有一个queue。
- 部分数据需要有序消费时,可以考虑将此部分消息发送到同一queue队列中,消费时即可保证此部分数据消费顺序。例如同一订单的创建、付款、完成需要被顺序消费,可以考虑根据订单id进行hash计算得到对应的queue,将同一订单的数据发送到同一queue中。使用MessageQueueSelector,消费时,同一queue由一个线程进行消费,使用MessageListenerOrderly
- 延时消息:
- 延迟消息是指生产者发送消息发送消息后,不能立刻被消费者消费,需要等待指定的时间后才可以被消费。
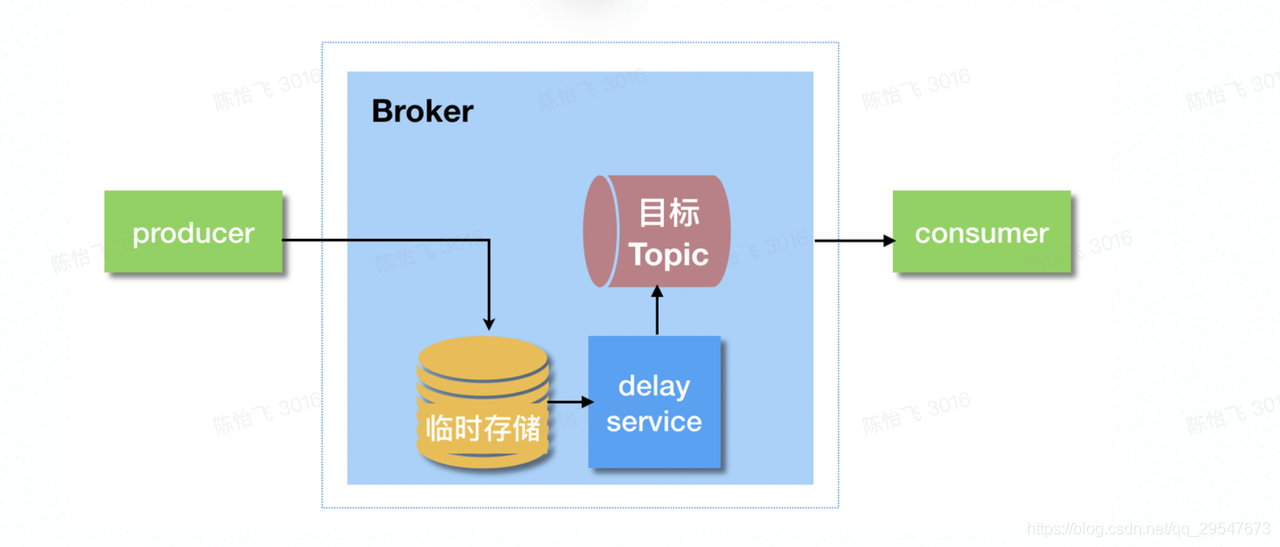
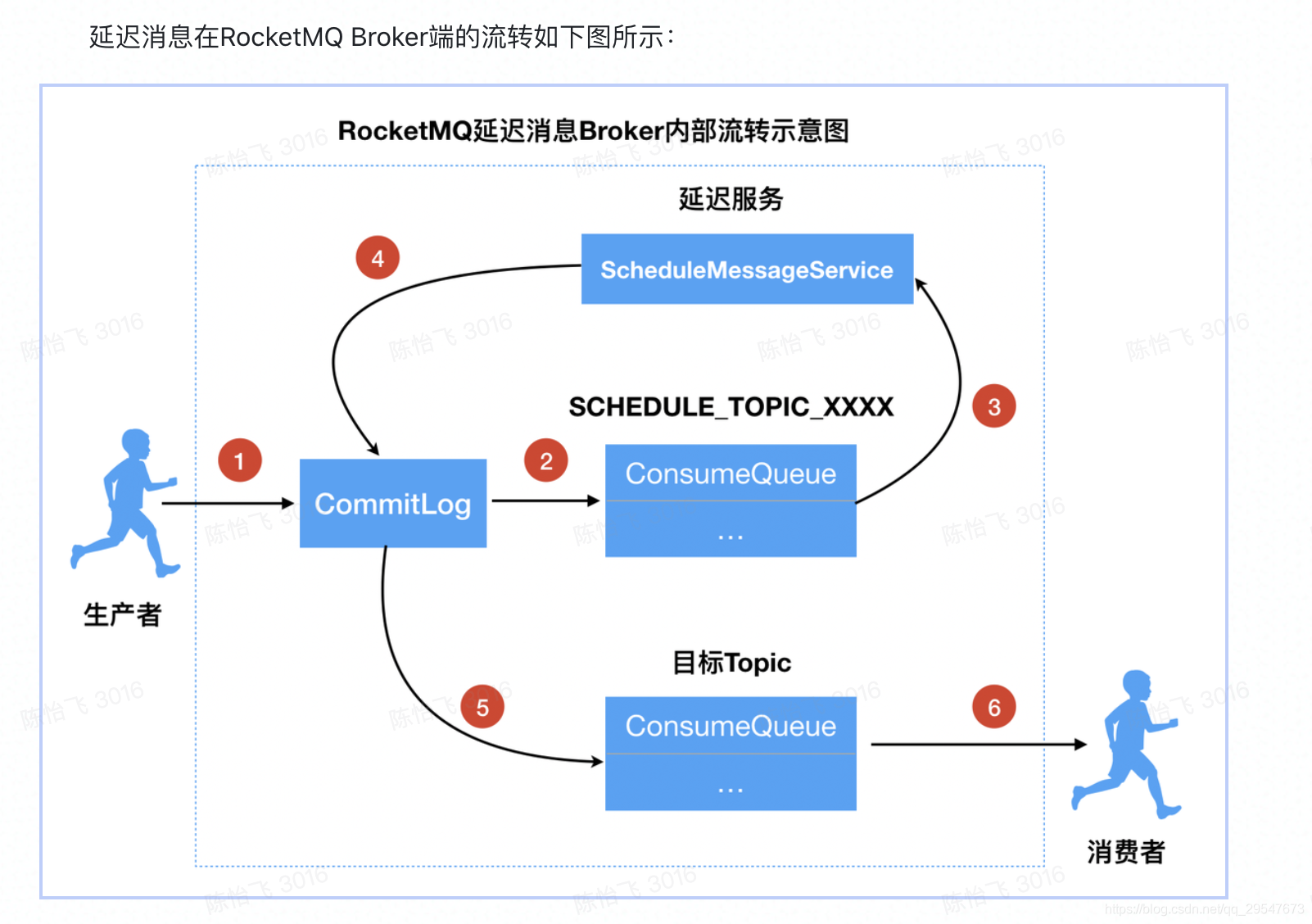
- 步骤说明如下:
- producer要将一个延迟消息发送到某个Topic中
- Broker判断这是一个延迟消息后,将其通过临时存储进行暂存。
- Broker内部通过一个延迟服务(delay service)检查消息是否到期,将到期的消息投递到目标Topic中。这个的延迟服务名字为delay service,不同消息中间件的延迟服务模块名称可能不同。
- 消费者消费目标topic中的延迟投递的消息
- 开源RocketMQ支持延迟消息,但是不支持秒级精度。默认支持18个level的延迟消息,这是通过broker端的messageDelayLevel配置项确定的(框架已实现指定时间的延迟队列,详情参考文档:https://doc.bytedance.net/docs/1019/1257/19589/),messageDelayLevel如下:
messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
- 批量消息:
- 一次性将多条消息发送到mq中(发送消息时传递一个list)
- 过滤消息:
- Broker的消息过滤可以帮助保证消费端只消费所需要的消息。
- 以天猫交易平台为例,订单消息和支付消息属于不同业务类型的消息,分别创建 Topic_Order 和 Topic_Pay,其中订单消息根据商品品类以不同的 Tag 再进行细分,列如电器类、男装类、女装类、化妆品类等被各个不同的系统所接收。
- 总的来说,针对消息分类,您可以选择创建多个 Topic,或者在同一个 Topic 下创建多个 Tag。但通常情况下,不同的 Topic 之间的消息没有必然的联系,而 Tag 则用来区分同一个 Topic 下相互关联的消息,例如全集和子集的关系、流程先后的关系。
- sql语法过滤,RocketMq支持通过sql语法来过滤消费的数据,订阅消息时使用MessageSelector.bySql()指定筛选条件
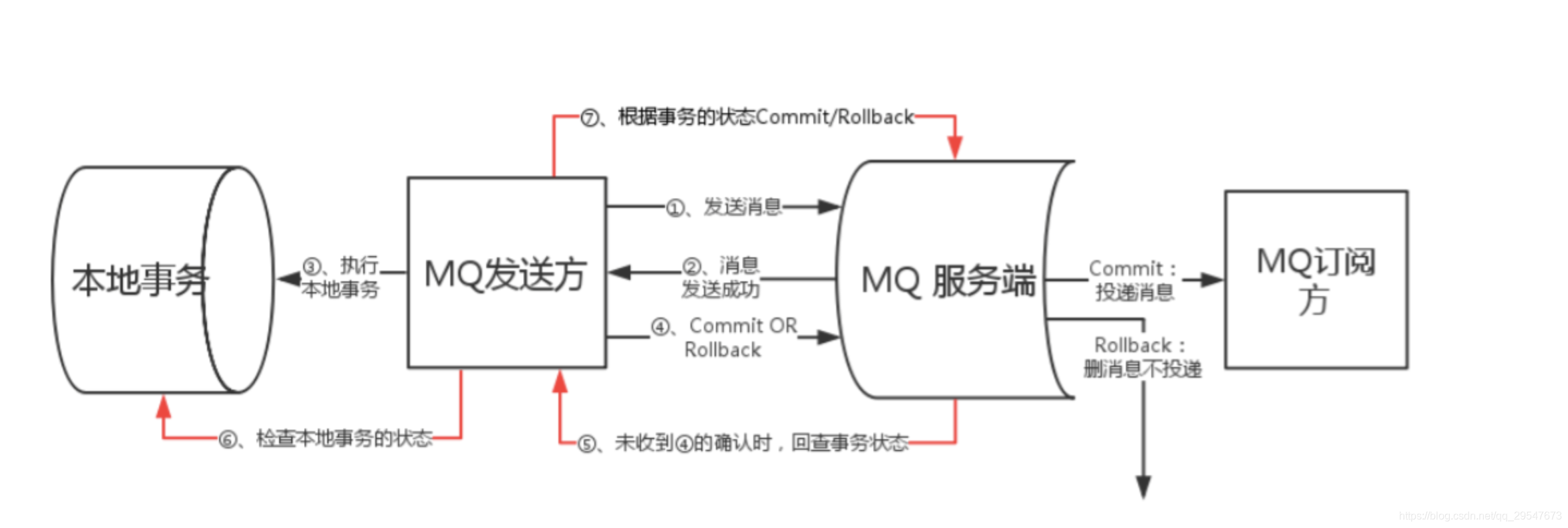
- 事务消息:
- 事务消息的发布主要分为两个部分:正常事务消息的发布与提交、事务消息的补偿流程
- 正常事务消息发布
- 发送消息(half消息)
- 服务端响应消息写入结果
- 根据写入结果执行本地事务(如果写入失败,此时half消息对consumer不可见,本地逻辑不执行)
- 根据本地事务状态执行commit或者rollback(只有commit后的消息才会对consumer可见)
- 事务补偿(用于解决消息Commit/Rollback失败或者超时的情况)
- 对没有Commit/Rollback的事务消息(pending状态的消息),从服务端发起一次回查
- Producer收到回查消息,检查消息对应的本地事务状态
- 根据本地事务状态,重新发起Commit/Rollback
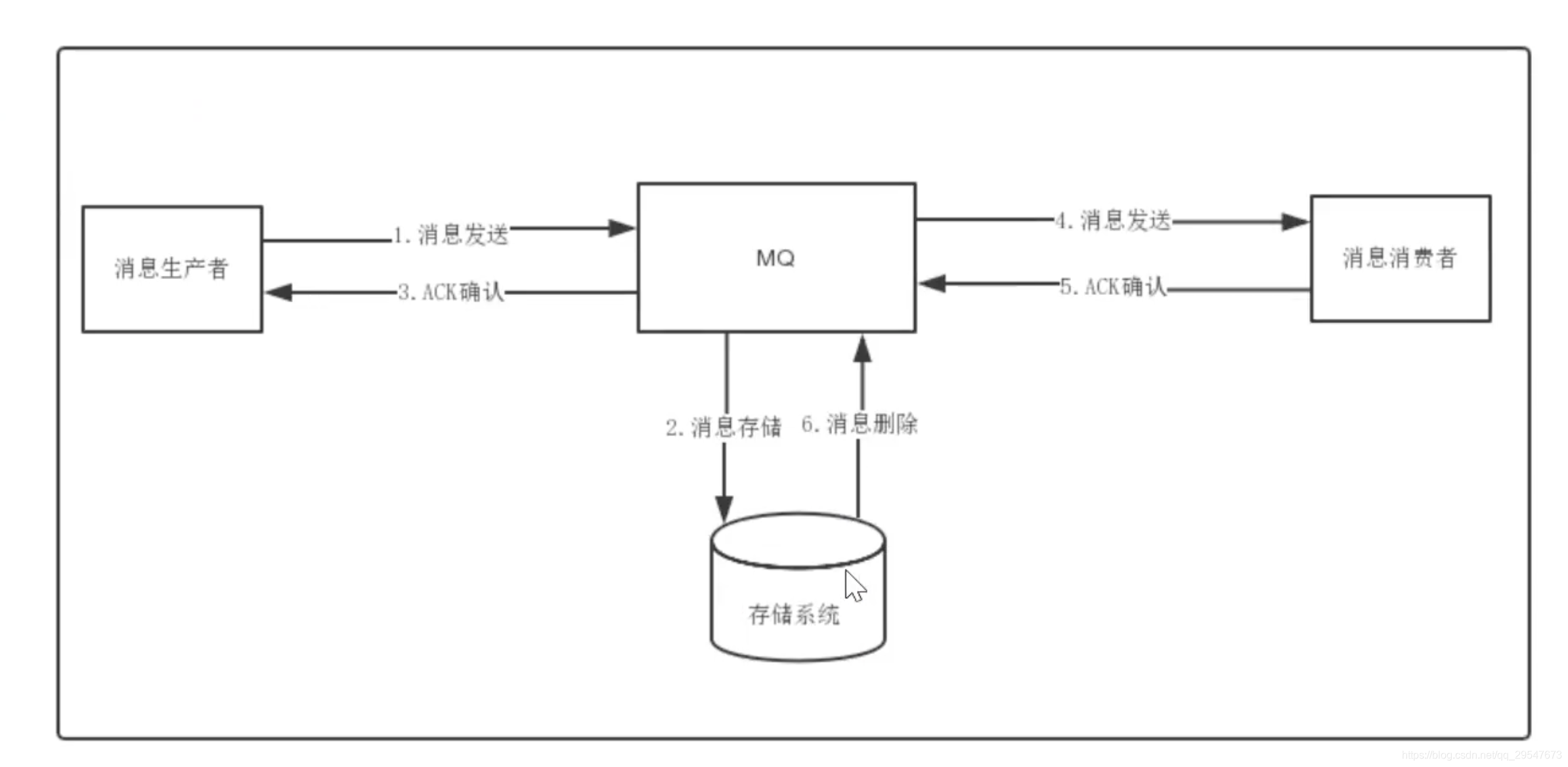
消息存储:
消息的传输流程如图所示:
- 消息的存储与发送:
- 消息存储:采用顺序写的方式将消息写入磁盘,保证了消息存储速度。
- 消息发送:采用零拷贝技术,提高消息存盘和发送的速度。(一次只能发送1.5-2G的文件到用户态的虚拟内存)
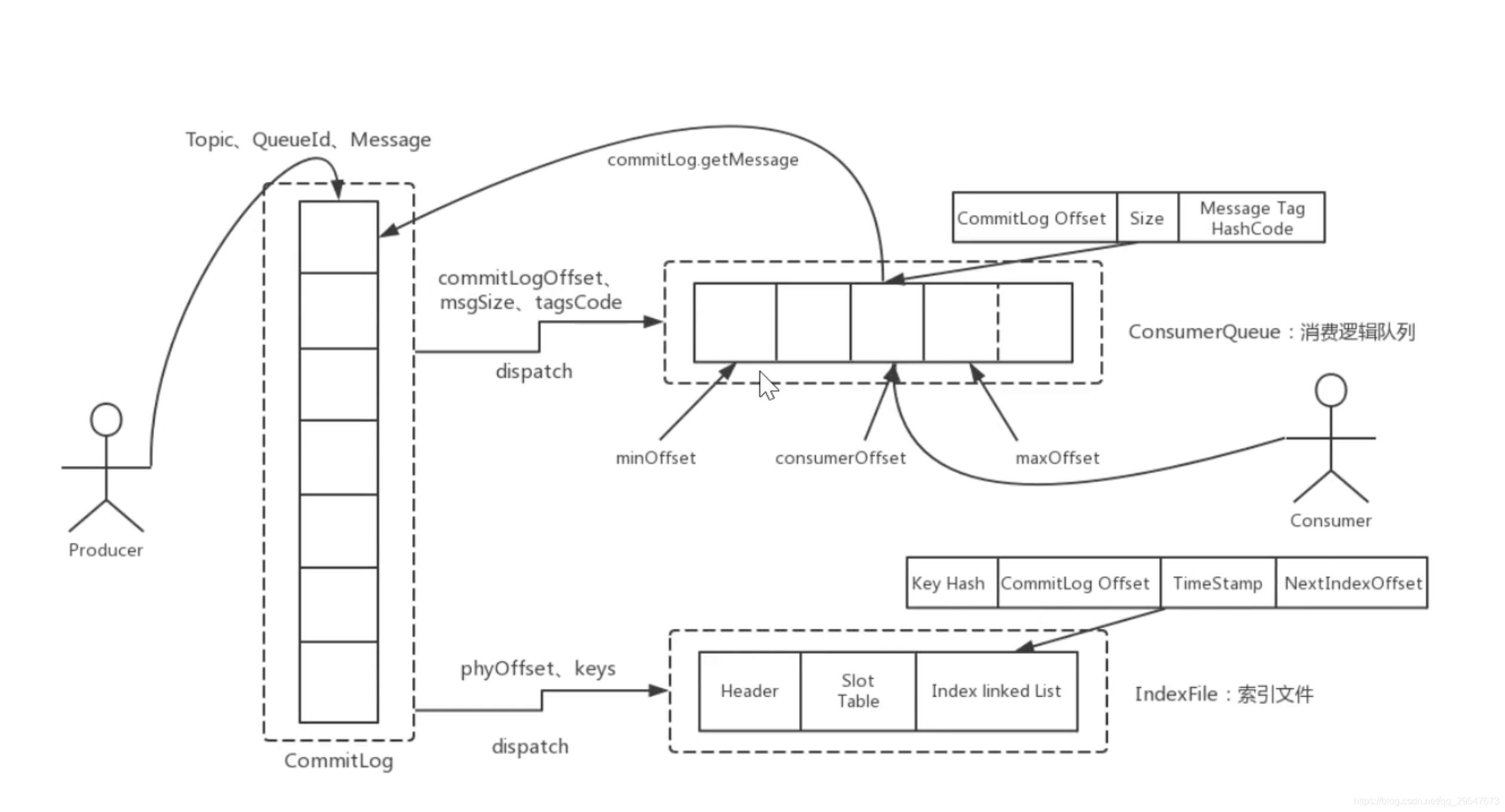
- 消息存储结构:
- RocketMq的消息存储是由ConsumerQueue和CommitLog配合完成的
- CommitLog:存储消息的元数据
- ConsumerQueue:存储了消息在CommitLog中的索引值。存放了某个Topic下面的所有消息在CommitLog中的位置。每个topic下的每个queue都有一个对应的consumeQueue文件。key为单调递增的整数。ConsumerQueue和MessageQueue是一一对应的
- IndexFile:
- 消息索引文件,主要存储的是key和offset的对应关系。为了满足根据某些关键字查询消息的功能,保证查询速度。一个broker对应一组index文件,同样是写完一个文件去写下一个。
- rocketMq提供了根据消息msgID、消息key来查询消息的功能,对应的msgID以及生产者指定的消息key就会被索引,其中msgID是创建消息时自动生成的索引,肯定有的。消息key是producer发送消息前指定的,可以设置一组key,每个key都会被索引,不设置就没有。
- 综上所述,当Broker新建一条消息时,会在commitLog中插入一条消息正文;后台线程ReputMessageService在consumeQueue中插入一条索引数据,key为消费位点,内容为消息在commitLog文件的位置信息;在index中插入一条或多条索引数据,key为msgId或者指定的消息key,value为消息在commitLog文件的位置信息。之后消息可以用于消费了。
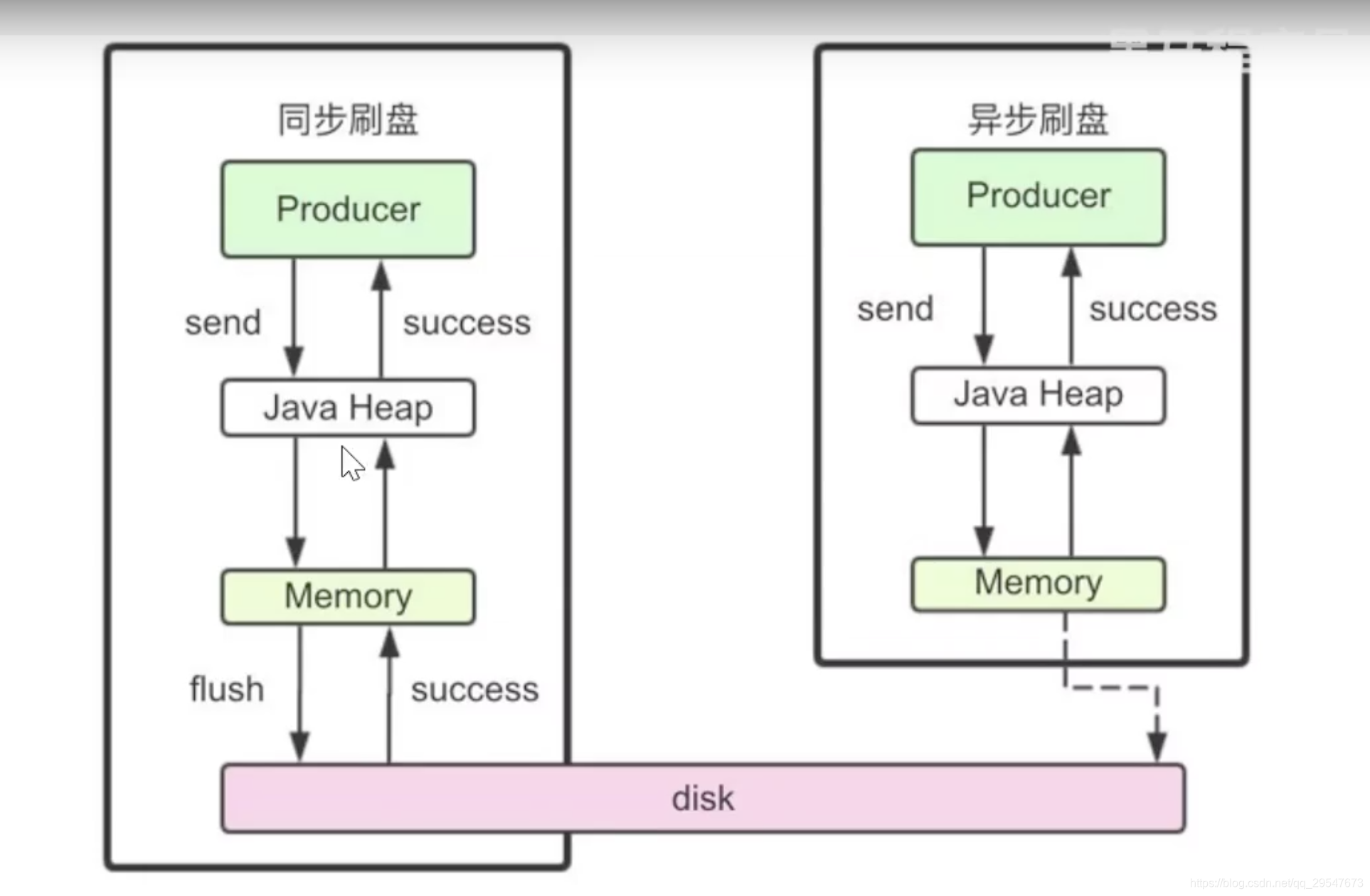
- 刷盘机制:
- 同步刷盘:在返回写成功状态时,消息已经被写入磁盘。
- 异步刷盘:在返回写成功状态时,数据只是被写入内存,由另外的线程将数据从内存写到磁盘上。
高可用机制:
- 同步(主从复制):slave主动建立TCP连接,然后每隔 5s 向master上报 commitLog 文件最大偏移量并拉取还未同步的消息;master收到请求,解析偏移量,返回未同步的消息;slave收到消息,更新自己的commitLog,更新偏移量,准备下次申请同步;向master上报此次同步进度。
- 读写分离:消息只能写入master,读取消息既可以从master也可以从slave。根据master的消息堆积量来决定向master/slave拉取消息。当前消息堆积量大于物理内存的 40 %,则将 suggestPullingFromSlave 设置为 true,且slaveReadEnable=true时,设置 suggestWhichBrokerId 为slave 的 broker ID。当消费者收到拉取响应回来的数据后,会将下次建议拉取的 brokerID 缓存起来(pullFromWhichNodeTable)。下次拉取消息可以从中取出 brokerId。
-
消费进度同步:集群消费时,消息消费进度是保存在broker的;广播消费时,消息进度保存在consumer本地。集群消费需要做broker的消费进度同步。无论消息消费者是从master拉的消息还是从slave拉取的消息,在向Broker反馈消息消费进度时,优先向master汇报,除非master挂了。消息消费进度的同步是单向的,slave开启一个定时任务,定时从master同步消息消费进度。
-
master挂了,拉取消息只能从slave,master重启后消息进度是旧的?consumer在消费时,本地也会保存消费进度。在集群模式下,也会有缓存。consumer向master/slave拉取消息时,首先就会更新消息进度。如果consumer内存中存在消息消费进度时,broker会更新消息消费进度,所以重启后,master可以更新进度。
-
负载均衡:
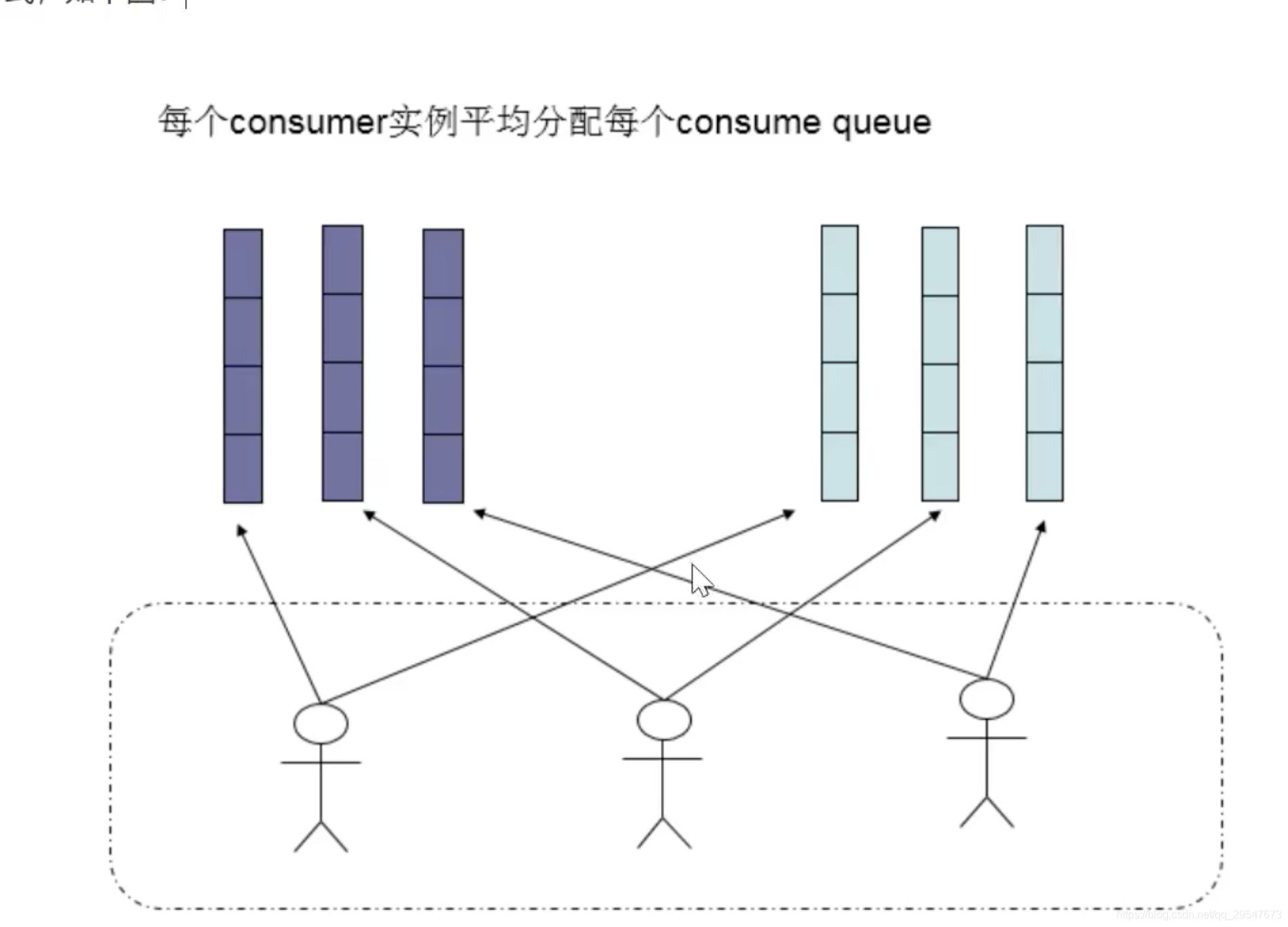
- 生产者负载均衡:每个实例在发送消息时,默认会轮询所有的messageQueue发送消息,以达到让所有的消息均匀的落在不同的queue中。
- 消费者负载均衡:每个queue只能分配给一个消费者,因此消费者的数量应小于queue的数量
- 常见负载均衡策略:AllocateMessageQueueAveragely平均算法,默认策略;
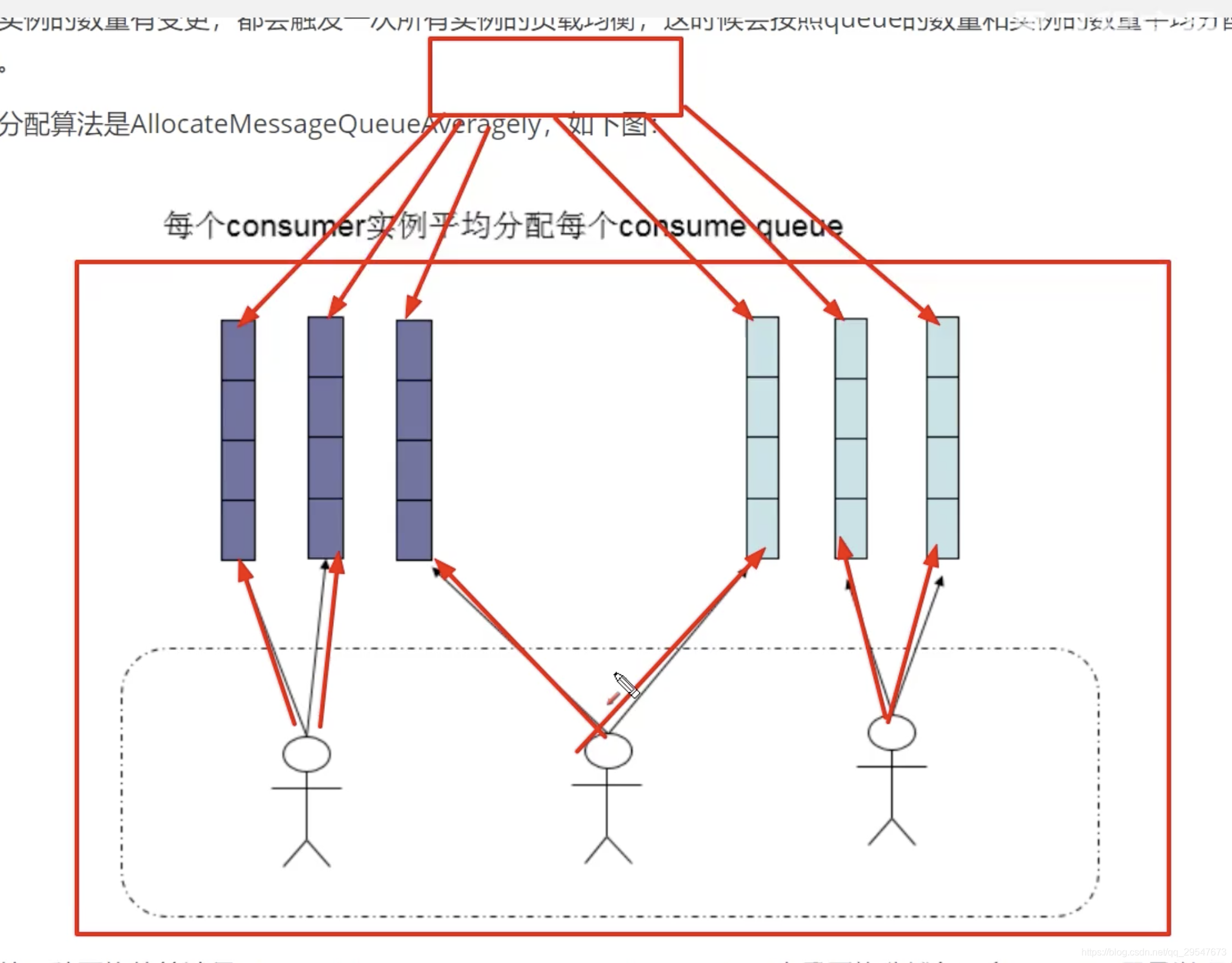
- AllocateMessageQueueAveragelyByCircle:环形平均算法;所有消费者围成一个环,然后循环这个环分配队列。
- AllocateMessageQueueByConfig:根据配置负载均衡算法;
- AllocateMessageQueueConsistentHash:一致性哈希负载均衡算法。
消息重试与死信队列:
- 顺序消息的重试:对于顺序消息,当消费者消费失败后,消息队列会自动的进行消息重试,这时,应用会出现消息消费被阻塞的情况。因此在使用顺序消息时,务必保证应用能够及时监控并处理消费失败的情况。
- 无序消息的重试:通过返回状态实现重试。广播方式不提供重试特性,消费失败后,失败消息不再重试,继续消费新消息。
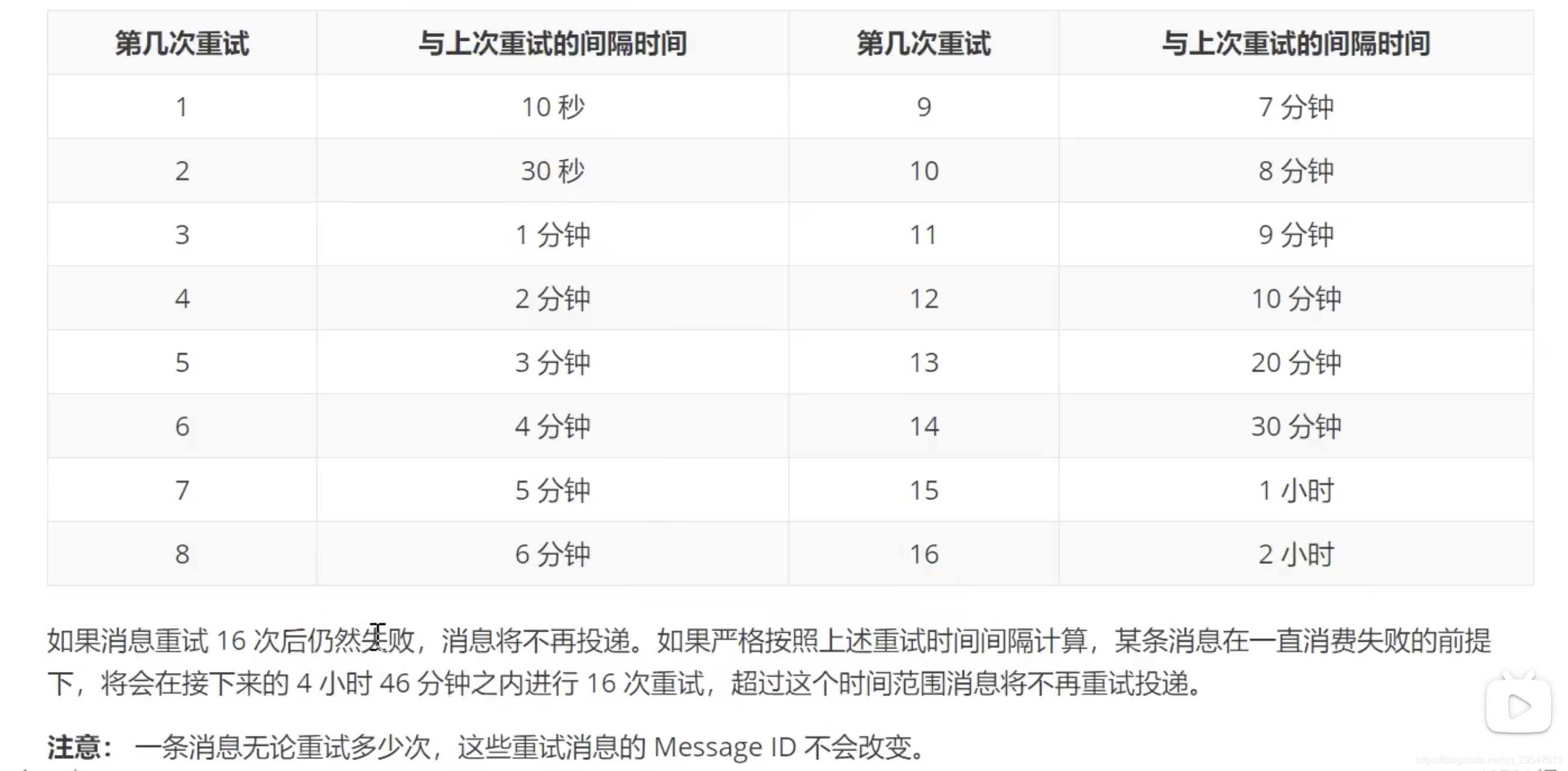
- 默认允许每条消息最多重试16次,16次后会将消息放入死信队列。有效期为3天,3天后会被删除
- 死信队列:一个死信队列对应一个GroupID,如果一个Group没有产生死信消息,则不会创建死信队列。一个死信队列包含了一个Group所有的死信消息,无论该消息属于哪个topic。
消息重复:
- 发送消息时重复:
- 当一条消息从客户端成功发送到服务端,并完成持久化,但因为网络抖动或者客户端宕机,导致服务端对客户端应答失败,客户端认为消息发送失败并重新发送消息,此时客户端会受到两条相同的数据。
- 投递时消息重复:
- 消息消费场景下,消息已投递到消费者并完成业务处理,当客户端给服务端反馈应答网络异常,为保证至少一次消费,服务端在网络恢复后会再次将之前的消息投递到消费者,消费者会收到两条相同的消息。
- 负载均衡时消息重复:
- Broker或客户端重启、扩容或者缩容时,会发生Rebalance,此时消费者可能会消费到重复的数据。
参考文档:
https://cloud.tencent.com/developer/article/1581368
https://xie.infoq.cn/article/fba37afd9bda31fb10eec651f

















 3022
3022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









