







为什么要数据建模
性能:良好的数据模型能帮助我们快速查询所需要的数据,减少数据的吞吐。
成本:良好的数据模型能极大地减少不必要的数据冗余,也能实现计算结果复用,极大地降低大数据系统中的存储和计算成本。
效率:良好的数据模型能极大地改善用户使用数据的体验,提高使用数据的效率。
质量:良好的数据模型能改善数据统计口径的不一致性,减少数据计算错误的可能性。
数据仓库建模方法论
ER 模型:用实体关系( Entity Relationship, ER )模型描述企业业务,在范式理论上符合 3NF 。
维度模型:从分析决策的需求出发构建模型,为分析需求服务,因此它重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复杂查询的响应性能。其典型的代表是星形模型,以及在一些特殊场景下使用的雪花模型。
Data Vault 模型:是ER模型的衍生,其设计的出发点也是为了实现数据的整合,但不能直接用于数据分析决策。
Anchor 模型:其核心思想是所有的扩展只是添加而不是修改,因此将模型规范到 6NF ,基本变成了 k-v 结构化模型。
规范定义指以维度建模作为理论基础 构建总线矩阵,划分和定义数据域、业务过程、维度、度量 原子指标、修饰类型、修饰词、时间周期、派生指标。
名词术语

指标体系
原子指标+修饰词+时间周期=派生指标
模型设计
模型层次
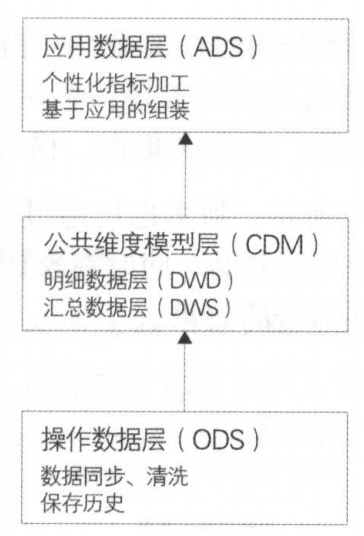
基本原则
高内聚低耦合
核心模型和扩展模型分离
公共处理逻辑下沉且单一
成本与性能平衡
数据可回滚
一致性
命名清洗可理解
模型实施
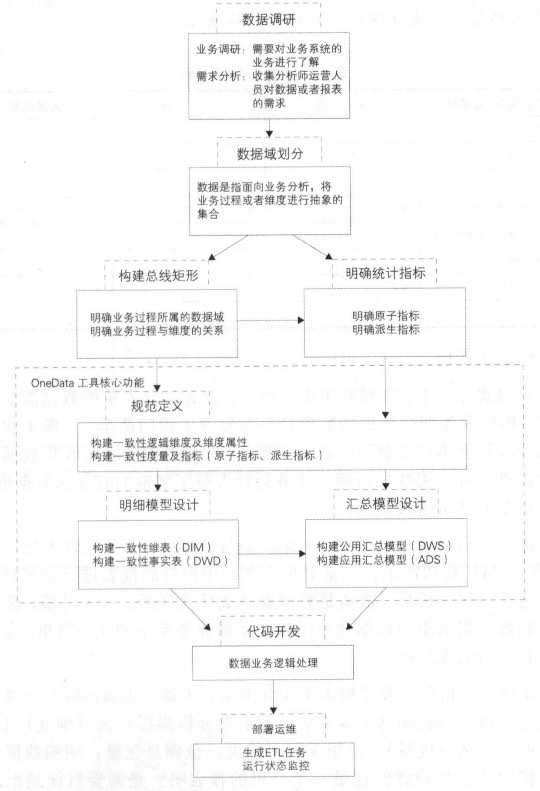
数据域划分
数据域是指面向业务分析,将业务过程或者维度进行抽象的集合。业务过程可以概括为 个个不可拆分的行为事件,如下单、支付、退款。
构建总线矩阵
需要做两件事情 :明确每个数据域下有哪些业务过程;业务过程与哪些维度相关,并定义每个数据域下的业务过程和维度。
规范定义
规范定义主要定义指标体系,包括原子指标、修饰词、时间周期和派生指标。
模型设计
模型设计主要包括维度及属性的规范定义,维表、明细事实表和汇总事实表的模型设计。
维度设计
选择维度或新建维度。
确定主维表。
确定相关维表。
确定维度属性。















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









