










主要介绍无监督学习中的生成模型。
传统利用RNN的Pixel RNN
经典的Auto-Decoder和VAE(变分自动编码器),以及解释在概率上的VAE做法,和存NN的联系
最近比较流行的GAN
pdf 视频1 视频2
Pixel RNN
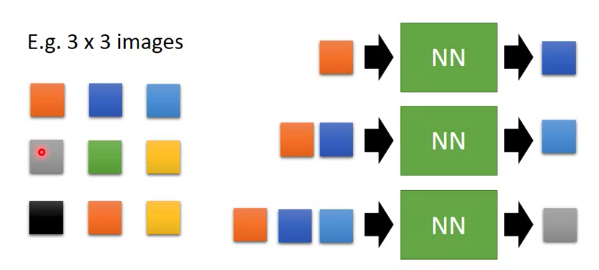
训练一个RNN:
看到第1个pixel就输出第2个推理pixel。
看到第1、第2个pixel就输出第3个推理pixel。
看到第1、第2个、第3个pixel就输出第4个推理pixel。
…
比如有一张真实的图:

如果遮挡一部分,然后输入Pixel RNN:

得到的结果:

同样可以用在语音上,比如WaveNet:

预先输入一段语义,预测后面的部分。
Variational Auto-encoder(VAE)
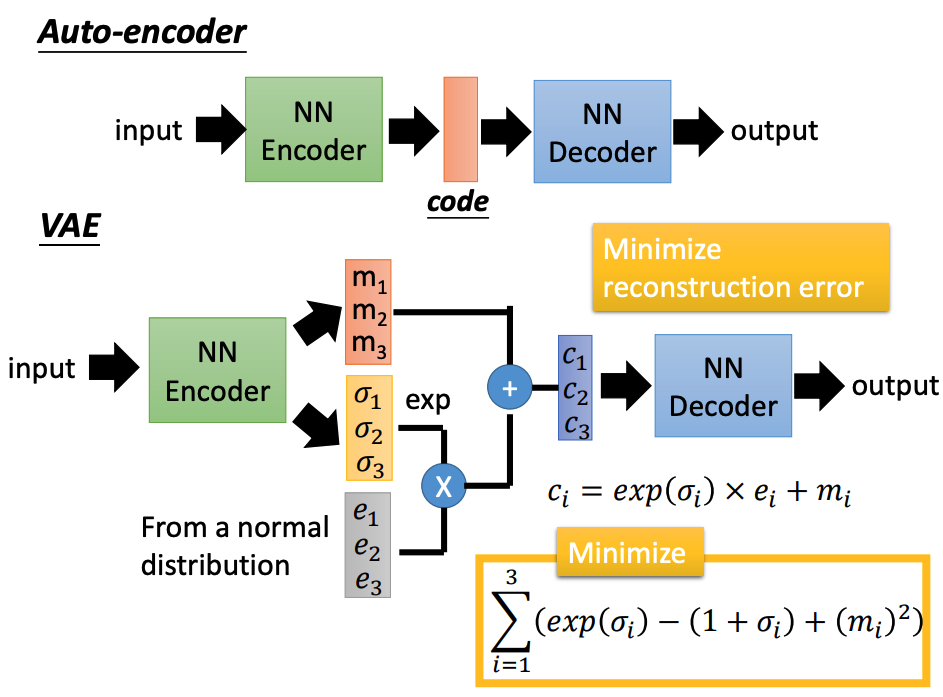
VAE与Auto-encoder不同的地方在于中间的code部分是:
c
i
=
exp
(
σ
i
)
×
e
i
+
m
i
c_{i}=\exp \left(\sigma_{i}\right) \times e_{i}+m_{i}
ci=exp(σi)×ei+mi
除了希望输入输出要尽可能一样外,还需要最小化:
∑
i
=
1
3
(
exp
(
σ
i
)
−
(
1
+
σ
i
)
+
(
m
i
)
2
)
\sum_{i=1}^{3}\left(\exp \left(\sigma_{i}\right)-\left(1+\sigma_{i}\right)+\left(m_{i}\right)^{2}\right)
i=1∑3(exp(σi)−(1+σi)+(mi)2)
为什么要用VAE方法?
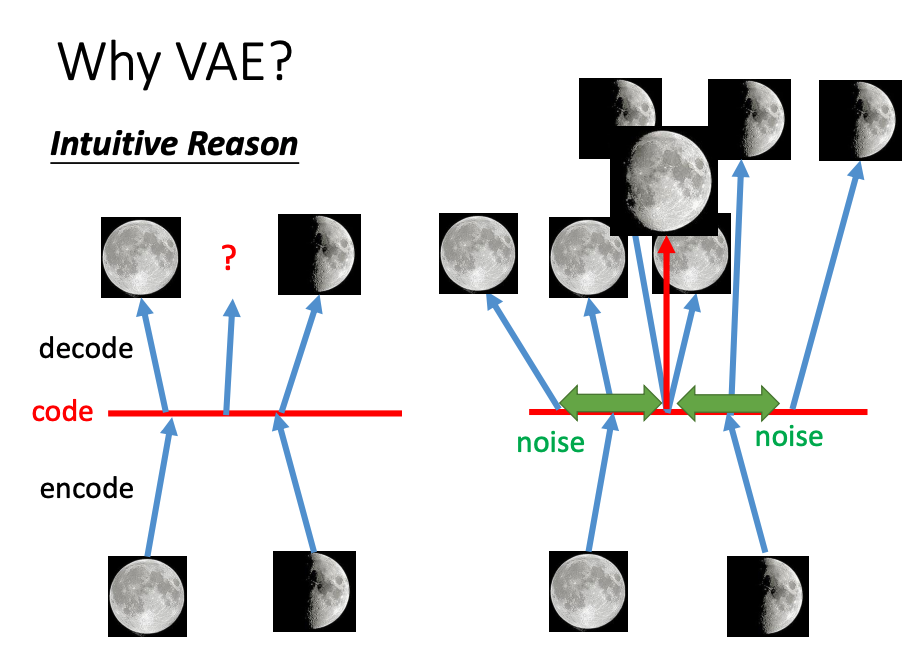
左边是Auto-encoder,在code的中间部分,希望输出的3/4月亮,但是Auto-encoder往往很难学习到。
VAE的做法是在code部分添加noise,两边的noise都会延伸到中间,那么在中间的部分就学习到两边的图,但是输出右只能一张,所以会比Auto-encoder有更好的学习能力。
使用VAE,我们观察式子:
c
i
=
exp
(
σ
i
)
×
e
i
+
m
i
c_{i}=\exp \left(\sigma_{i}\right) \times e_{i}+m_{i}
ci=exp(σi)×ei+mi
可以发现
m
i
m_{i}
mi是原始的code,但是和Auto-encoder相比多添加了
exp
(
σ
i
)
×
e
i
\exp \left(\sigma_{i}\right) \times e_{i}
exp(σi)×ei。其中
e
i
e_{i}
ei是从正态分布中抽取的样本,然后乘一个
exp
(
σ
i
)
\exp(\sigma_{i})
exp(σi) 改变大小,
σ
i
\sigma_{i}
σi的大小是encoder自动学习的。
但是不对
σ
i
\sigma_{i}
σi做限制的话,
exp
(
σ
i
)
\exp(\sigma_{i})
exp(σi)可能是0,所以就有:
∑
i
=
1
3
(
exp
(
σ
i
)
−
(
1
+
σ
i
)
+
(
m
i
)
2
)
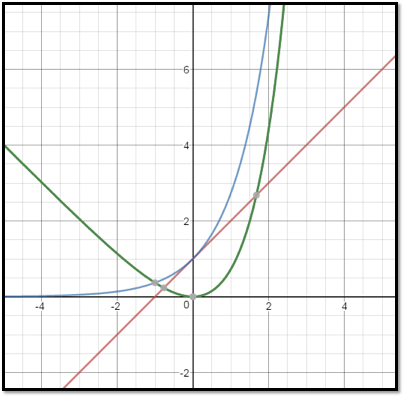
\sum_{i=1}^{3}\left(\exp \left(\sigma_{i}\right)-\left(1+\sigma_{i}\right)+\left(m_{i}\right)^{2}\right)
i=1∑3(exp(σi)−(1+σi)+(mi)2)
蓝色是
exp
(
σ
i
)
\exp \left(\sigma_{i}\right)
exp(σi),红色是
1
+
σ
i
1+\sigma_{i}
1+σi,绿色就是:
exp
(
σ
i
)
−
(
1
+
σ
i
)
\exp \left(\sigma_{i}\right)-\left(1+\sigma_{i}\right)
exp(σi)−(1+σi),可以发现当我们希望
exp
(
σ
i
)
−
(
1
+
σ
i
)
\exp \left(\sigma_{i}\right)-\left(1+\sigma_{i}\right)
exp(σi)−(1+σi)最小时,
exp
(
σ
i
)
\exp \left(\sigma_{i}\right)
exp(σi)并不是0,而是1。所以这个正则可以防止
exp
(
σ
i
)
=
0
\exp(\sigma_{i})= 0
exp(σi)=0
注意到有个
(
m
i
)
2
\left(m_{i}\right)^{2}
(mi)2,就是常规的L2正则,希望不要过拟合。
VAE-Gaussian解释
VAE在统计学上对的解释:
我们的目的是求一个概率分布
P
(
x
)
P(x)
P(x),其中x是图片在高维空间的表示,比如图像
256
∗
256
256 *256
256∗256那么x就是
256
∗
256
256 *256
256∗256的向量,但是一般我们是用低维空间的x来输出图片,使用x一般是比
256
∗
256
256 *256
256∗256低很多的向量。那么是关于什么的概率分布呢?是关于这个x是不是真实图片的概率。比如下面概率低的地方,图片也就很不真实。我们求得
P
(
x
)
P(x)
P(x)后,在概率值高的地方sample就是大概率会和真实的图接近。
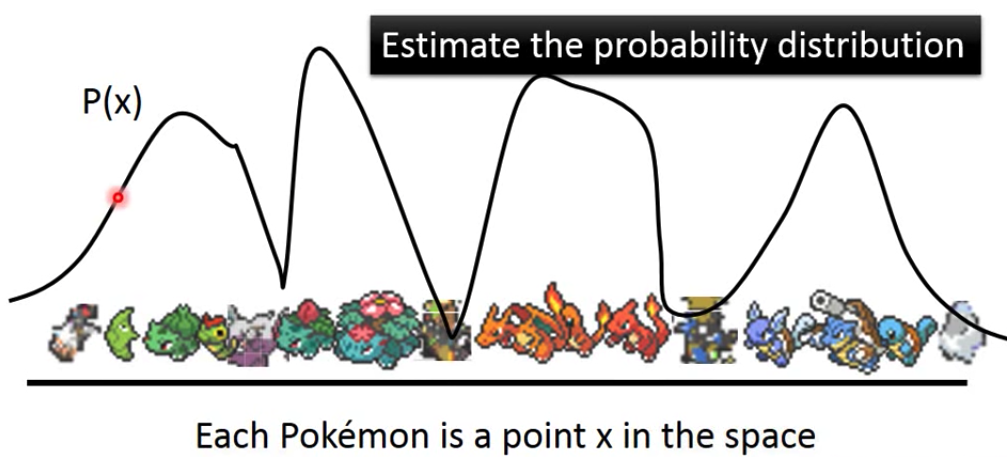
问题变成求 P ( x ) P(x) P(x)
我们把数据分布看做是GMM(Gaussian Mixture Model),假设GMM是由m个GM组成,而这个m其实就是上面NN中code的长度,而code的值在这就是
P
(
m
)
P(m)
P(m),单个GM的weight。相同的道理,在NN中表示低维空间的weight。
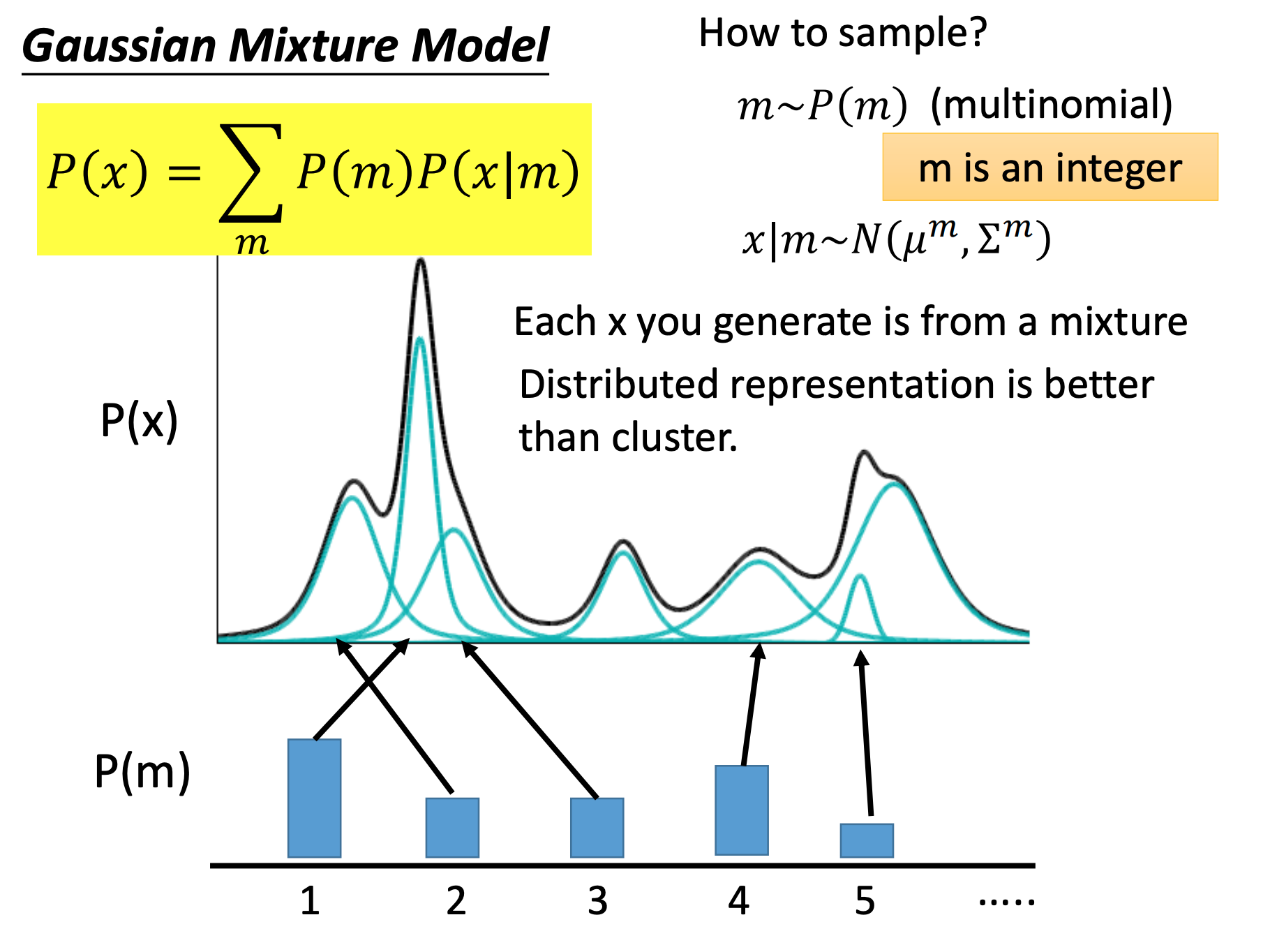
这个式子
P
(
x
)
=
∑
m
P
(
m
)
P
(
x
∣
m
)
P(x)=\sum_{m} P(m) P(x \mid m)
P(x)=∑mP(m)P(x∣m)其实就是全概率公式。也可以结合上面GMM来理解。
上面是离散型表示,类比上面预测月亮,我们希望学习输入的code不是特定的值,而是希望是一个连续的分布,使用 P ( z ) P(z) P(z)是1个多维的正态分布。
所以
求
P
(
x
)
求P(x)
求P(x)变为:
P
(
x
)
=
∫
Z
P
(
z
)
P
(
x
∣
z
)
d
z
P(x)=\int_{Z} P(z) P(x \mid z) d z
P(x)=∫ZP(z)P(x∣z)dz
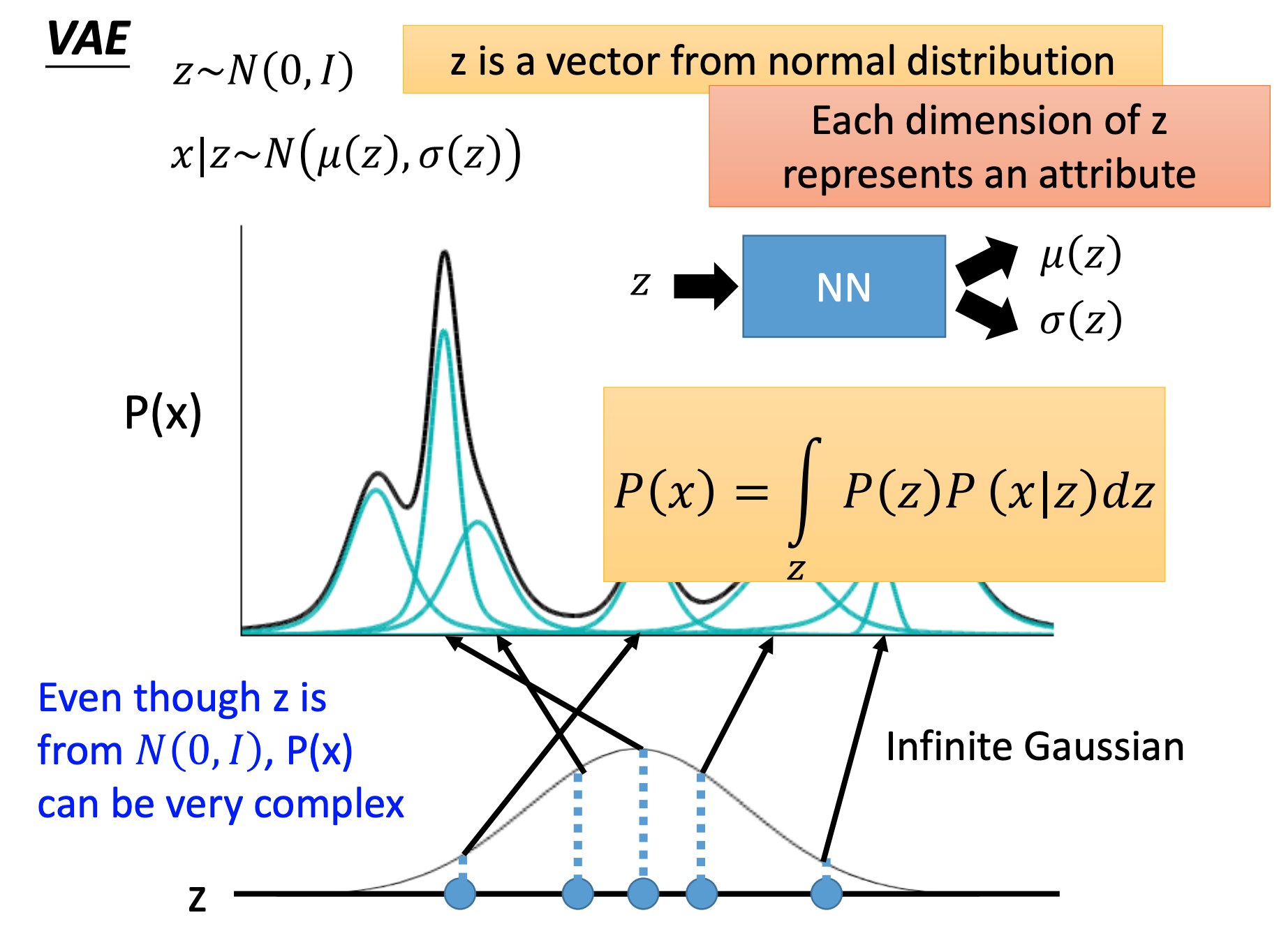
插入一些预备的东西:
我们假设学习一个NN可以求z这个点对应到x空间上时,那个GM的
μ
(
z
)
,
σ
(
z
)
\mu(z), \sigma(z)
μ(z),σ(z):
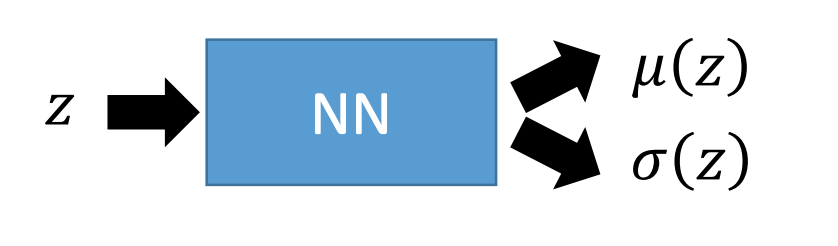
注意事实上这里的
μ
(
z
)
,
σ
(
z
)
\mu(z), \sigma(z)
μ(z),σ(z)是
P
(
x
∣
z
)
P(x|z)
P(x∣z)的。
我们也假设学习一个NN’可以求x这个点对应到z空间上时,那个GM的
μ
′
(
z
)
,
σ
′
(
z
)
\mu'(z), \sigma'(z)
μ′(z),σ′(z):
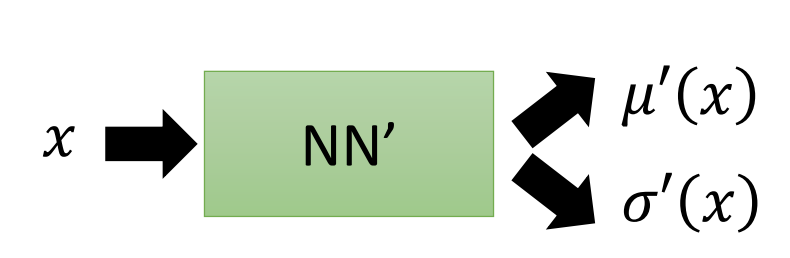
注意事实上这里的
μ
′
(
z
)
,
σ
′
(
z
)
\mu'(z), \sigma'(z)
μ′(z),σ′(z)是
P
(
z
)
P(z)
P(z)的。
类比NN中VAE:
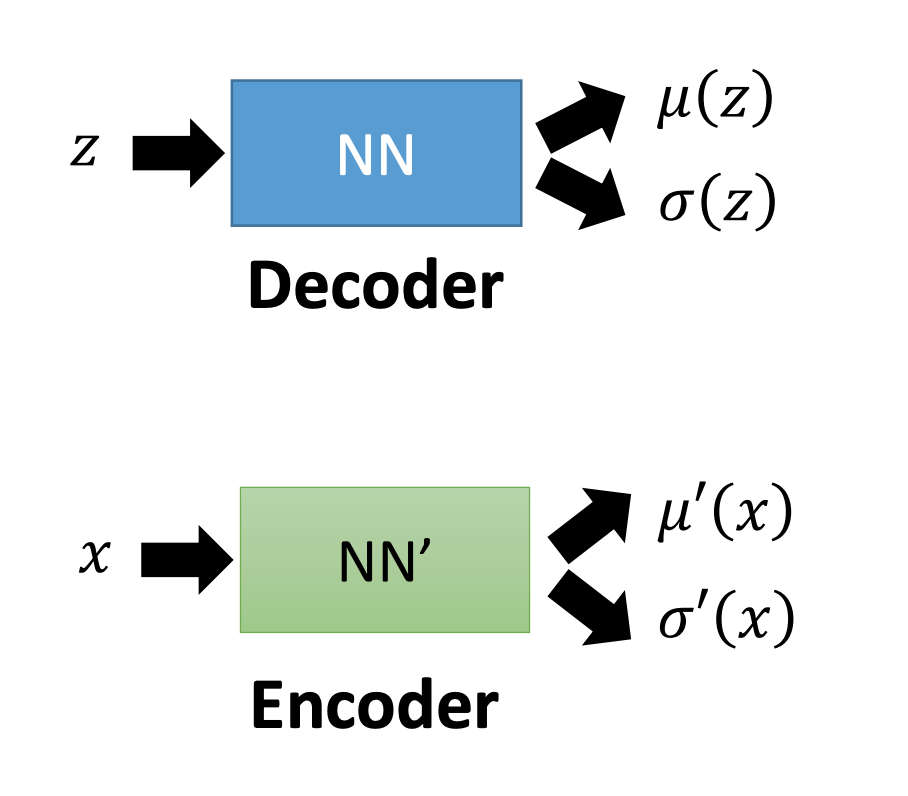
各种是Decoder和Encoder。
继续回到数学上,要求P(x),数学上直观方法是使用Maximizing Likelihood求:
L
=
∑
x
log
P
(
x
)
L=\sum_{x} \log P(x)
L=x∑logP(x)
下面一些推导

其中引入一个任意分布
q
(
z
∣
x
)
q(z \mid x)
q(z∣x):
∫
z
q
(
z
∣
x
)
=
1
\int_{z} q(z \mid x) = 1
∫zq(z∣x)=1
所以要最大化L,而
L
≥
∫
Z
q
(
z
∣
x
)
log
(
P
(
x
∣
z
)
P
(
z
)
q
(
z
∣
x
)
)
d
z
L\geq \int_{Z} q(z \mid x) \log \left(\frac{P(x \mid z) P(z)}{q(z \mid x)}\right) d z
L≥∫Zq(z∣x)log(q(z∣x)P(x∣z)P(z))dz
L
b
L_b
Lb作为下界
log
P
(
x
)
=
L
b
+
K
L
(
q
(
z
∣
x
)
∥
P
(
z
∣
x
)
)
L
b
=
∫
Z
q
(
z
∣
x
)
log
(
P
(
x
∣
z
)
P
(
z
)
q
(
z
∣
x
)
)
d
z
\begin{array}{l} \log P(x)=L_{b}+K L(q(z \mid x) \| P(z \mid x)) \\ L_{b}=\int_{Z} q(z \mid x) \log \left(\frac{P(x \mid z) P(z)}{q(z \mid x)}\right) d z \end{array}
logP(x)=Lb+KL(q(z∣x)∥P(z∣x))Lb=∫Zq(z∣x)log(q(z∣x)P(x∣z)P(z))dz
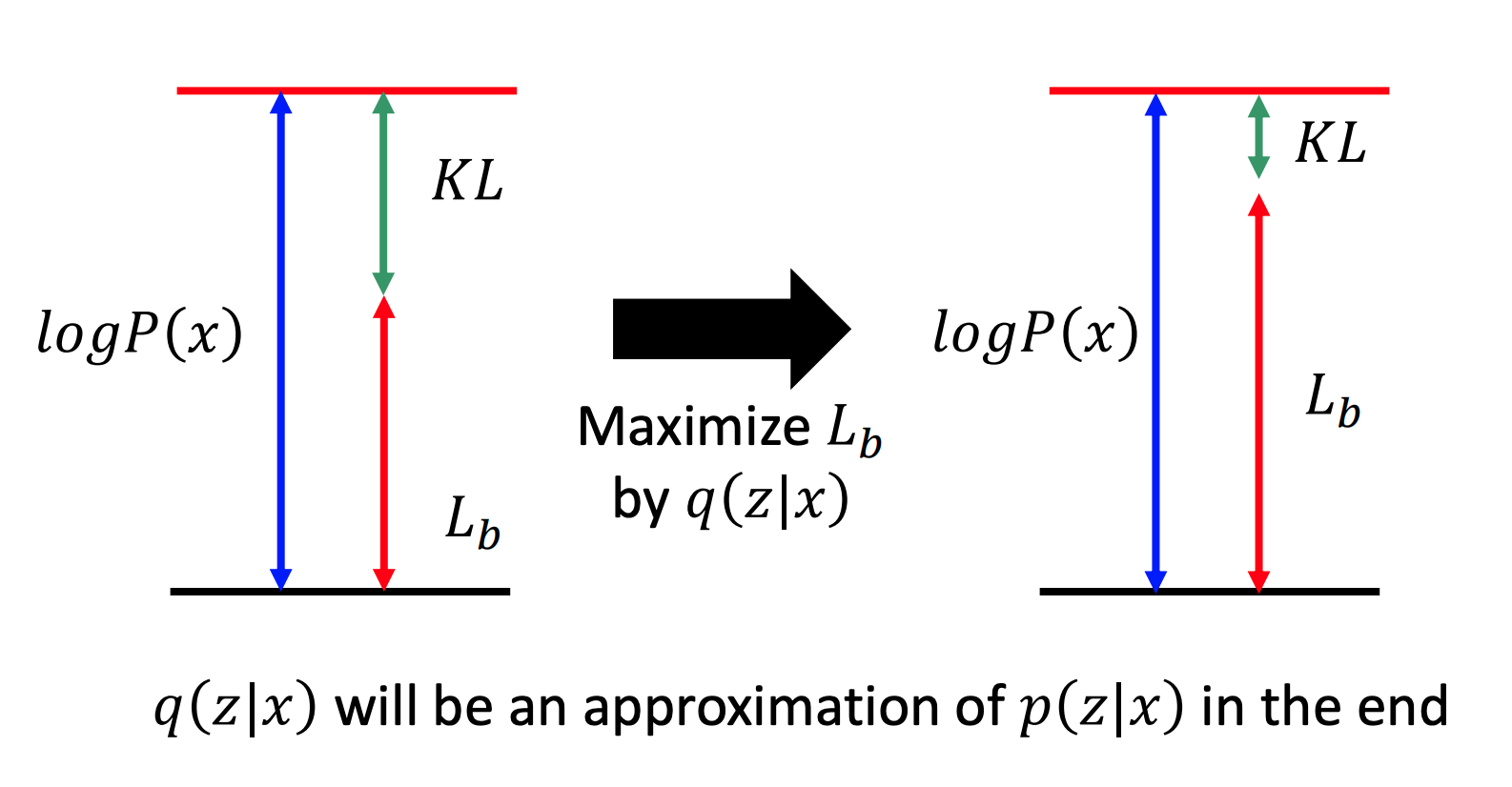
我们的目的是找
P
(
x
∣
z
)
P(x \mid z)
P(x∣z) 和
q
(
z
∣
x
)
q(z \mid x)
q(z∣x),使得
L
b
L_b
Lb越来越大,从而
log
P
(
x
)
\log P(x)
logP(x)就会越来越大。
而对于
q
(
z
∣
x
)
q(z \mid x)
q(z∣x)来说,它不会影响
log
P
(
x
)
\log P(x)
logP(x),它引入的目的只是调整
L
b
L_b
Lb。所以当
L
b
L_b
Lb越来越大时,
K
L
(
q
(
z
∣
x
)
∥
P
(
z
∣
x
)
)
K L(q(z \mid x) \| P(z \mid x))
KL(q(z∣x)∥P(z∣x))越来越小。
此时 q ( z ∣ x ) q(z \mid x) q(z∣x)和 P ( z ∣ x ) P(z \mid x) P(z∣x)分布越来越接近。而 P ( z ∣ x ) P(z \mid x) P(z∣x)是由NN得到,相当于Decoder。
单独分析
L
b
L_b
Lb,现在目的是使得
L
b
L_b
Lb越大越好。别忘记了,求这些的一切目的都是在最大似然的框架下求
P
(
x
)
P(x)
P(x)。
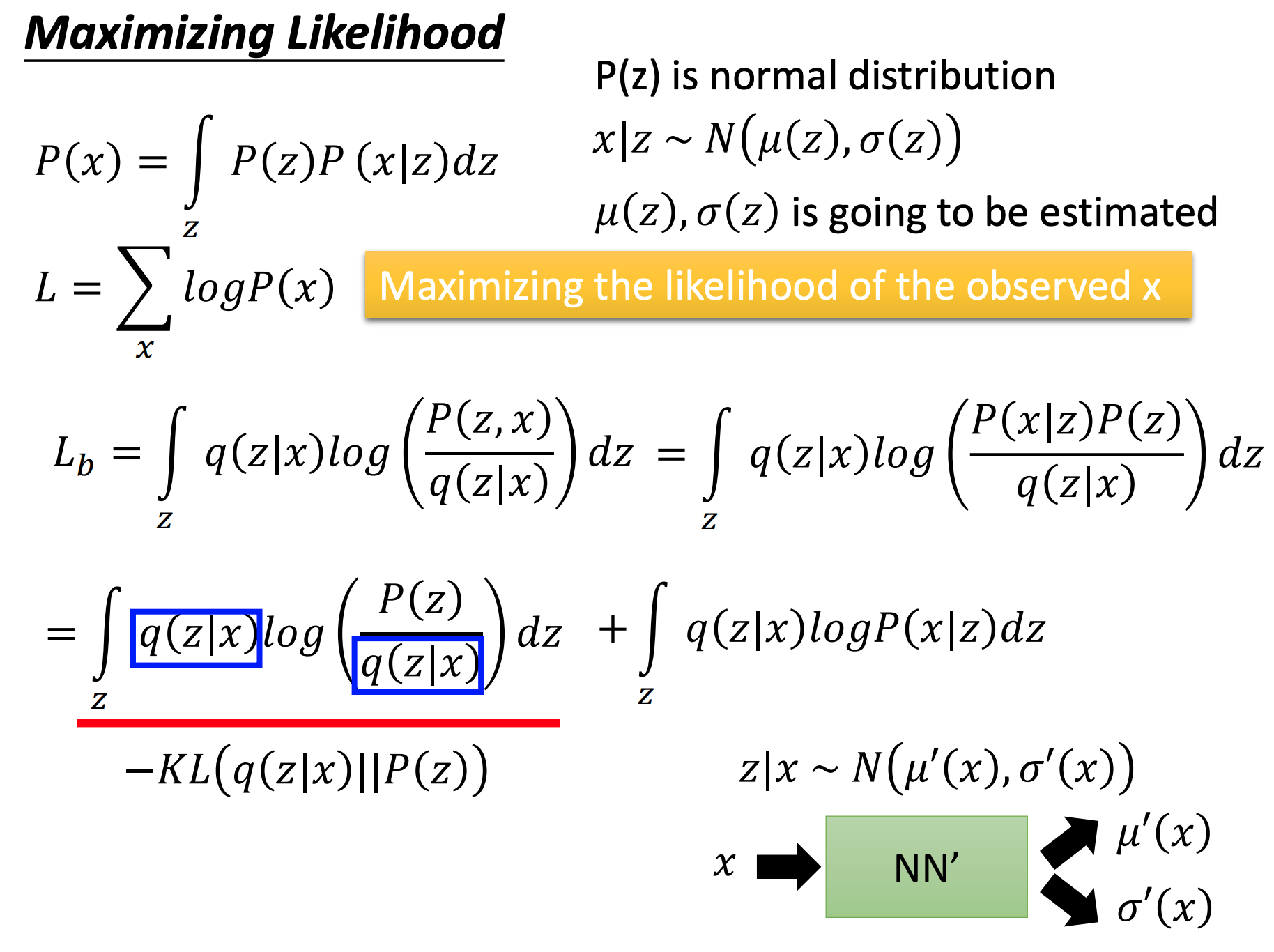
为了最大化
L
b
L_b
Lb,所以需要使得
K
L
(
q
(
z
∣
x
)
∥
P
(
z
)
)
K L(q(z \mid x) \| P(z))
KL(q(z∣x)∥P(z))越来越小。
此时 q ( z ∣ x ) q(z \mid x) q(z∣x)和 P ( z ) P(z) P(z)分布越来越接近。而 P ( z ) P(z ) P(z)是由NN’得到,相当于Encoder。
分析最后一项:
∫
Z
q
(
z
∣
x
)
log
P
(
x
∣
z
)
d
z
\int_{Z} q(z \mid x) \log P(x \mid z) d z
∫Zq(z∣x)logP(x∣z)dz
最大化它,其实就是求
log
P
(
x
∣
z
)
\log P(x \mid z)
logP(x∣z)最大化,由于P是一个GM,所以在取均值是得到最大。所以期望
P
(
x
∣
z
)
P(x \mid z)
P(x∣z)的均值就是x的均值。
所以在概率上的VAE也是期望输入和输出要越接近越好。
和之前提到的Auto-Encode对比:
- 在输入这边的NN’得到 μ ′ ( z ) , σ ′ ( z ) \mu'(z), \sigma'(z) μ′(z),σ′(z),也就是 P ( z ) P(z) P(z),在AE中相当于Encoder。
- 然后在 P ( z ) P(z) P(z)上进行sample得到z,在AE中相当于hidden layer中的code。
- z又经过输出层这边的NN得到 μ ( z ) , σ ( z ) \mu(z), \sigma(z) μ(z),σ(z),也就是 P ( x ∣ z ) P(x|z) P(x∣z),在AE中相当于Decoder。
- 而使用最大似然求 P ( x ) P(x) P(x)要求最后的 μ ′ ( z ) , σ ′ ( z ) \mu'(z), \sigma'(z) μ′(z),σ′(z),也就是 P ( z ) P(z) P(z)的 μ ’ ( z ) \mu’(z) μ’(z)要与x的mean一样,在AE中相当于Loss要求的输入-输出越小越好。
一头雾水,还不是很明白…
VAE缺点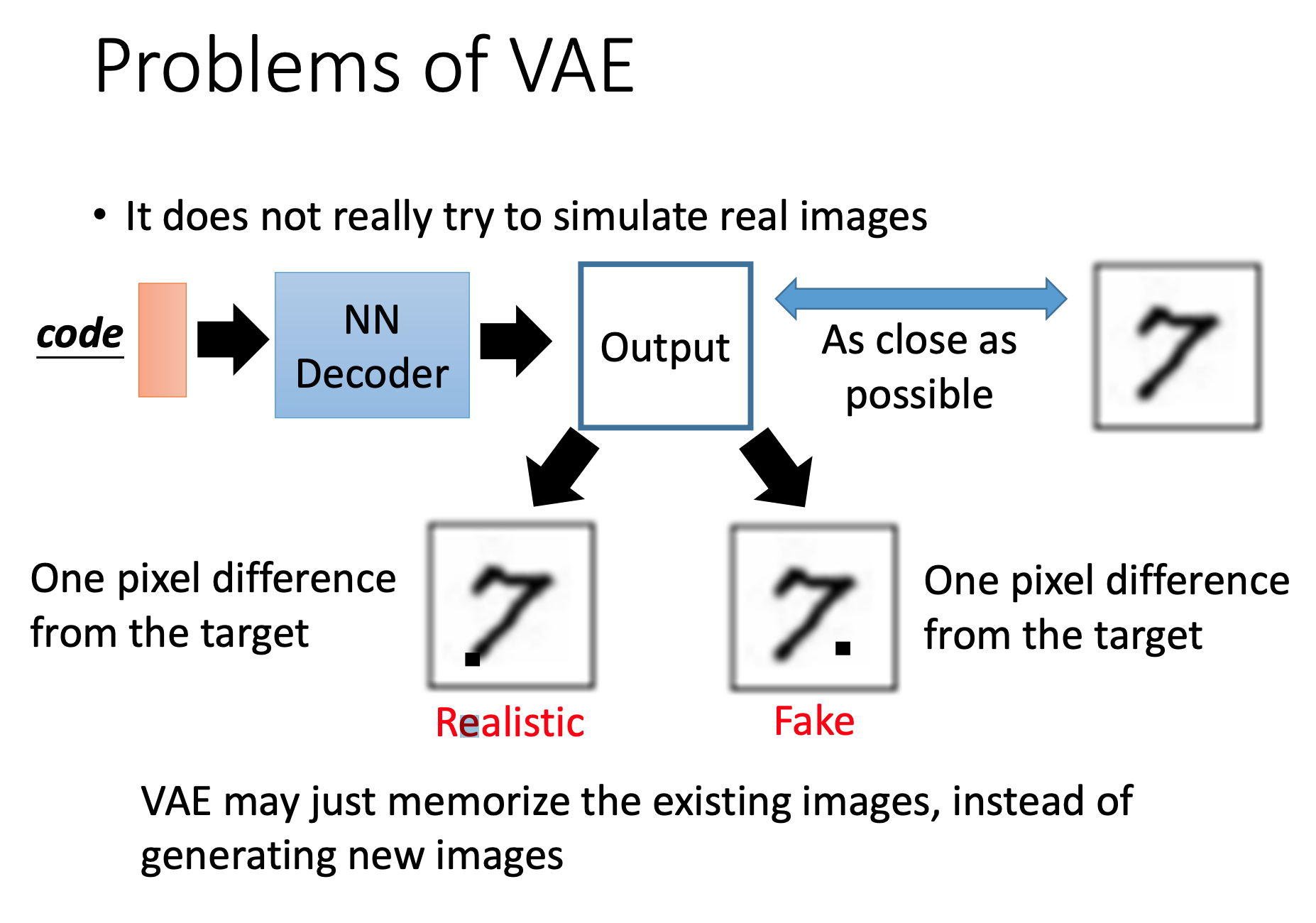
从训练过程就可以看出,VAE一般产生的图片是去近似数据集里的图片。它做的更新是线性变换。而没有真正意义上的生成新的图。
VAE可能只是记住现有的图像,而不是 生成新的图片
Generative Adversarial Network (GAN)
GAN是2014年提出。
The evolution of generation
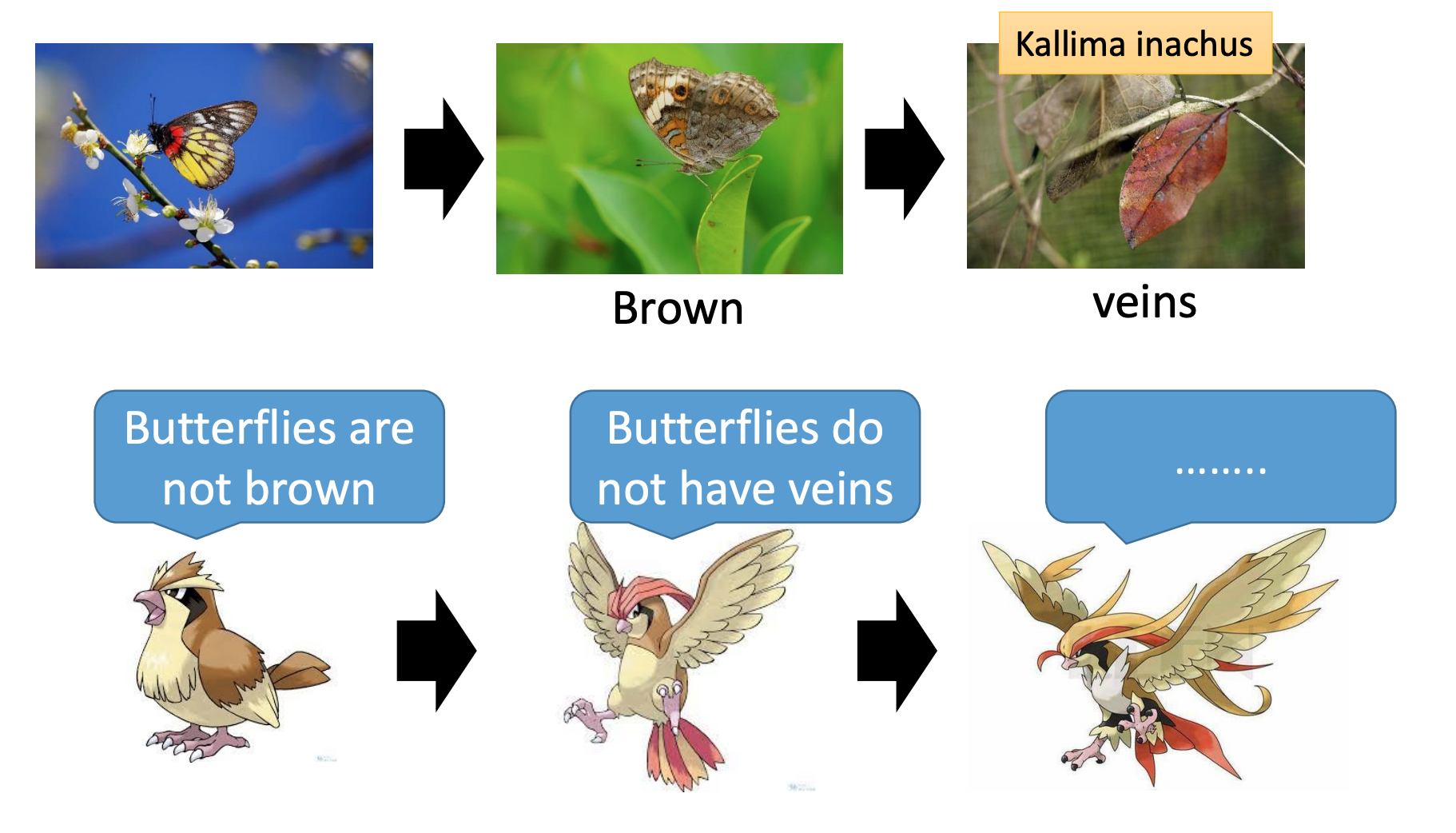
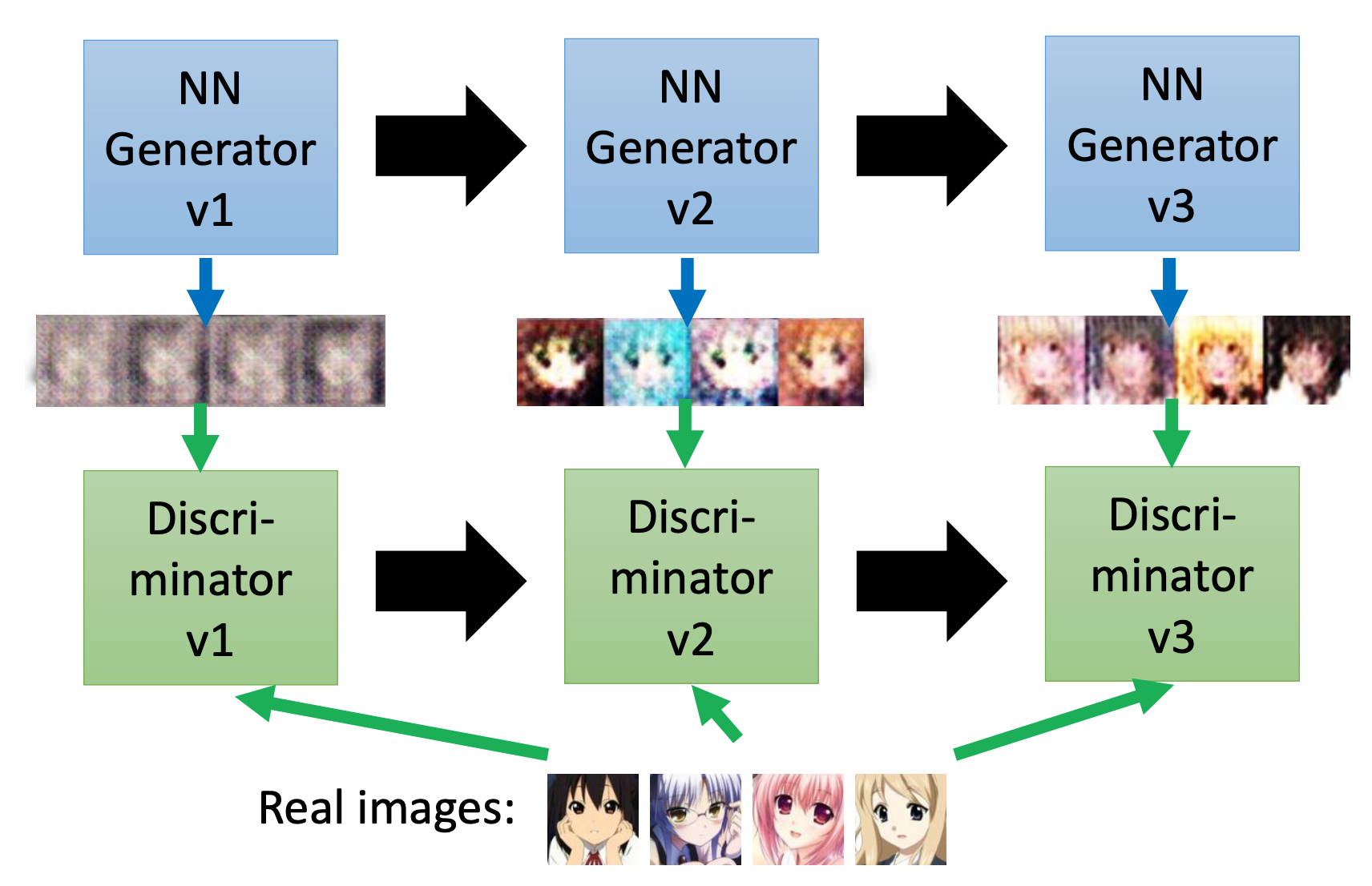
以上参考李宏毅老师视频和ppt,仅作为学习笔记交流使用















 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









