










本文方法侧重2点改进:
1.以往方法依赖假设,比如房间限制是个box或者是manhattan布局,通用性被限制
2.实时性,以往方法可能无法满足机器人导航和AR/VR需求
使用EquiConvs(本文重点),一种直接应用在球面投影图像上以解决扭曲问题
项目地址
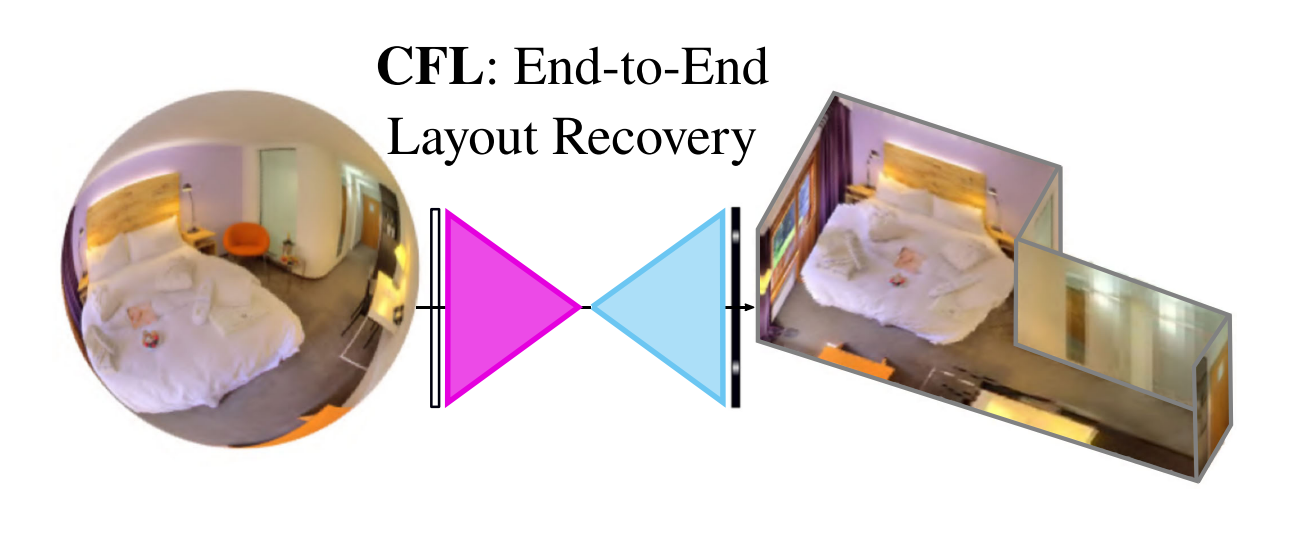
INTRODUCTION
布局估计应用场景:AR/VR、机器人导航、房地产。
Manhattan假设或者布局简化box-shaped layouts,不能很好拟合丰富的室内布局。
传统相机视野受限,所以要使用FOV=360的全局相机,但是全景图因为是球面投影的,在平面显示会发生变形,就像地图。所以不能使用传统相机方法。
预处理(显示点对齐)往往比较费时,是不能达到实时性的主要原因。
CFL比以往方法快100,且更准确。可以预测超过4个墙角以上且不受Manhattan布局约束。
EquiConvs是对卷积核进行扭曲,以抵消全景图扭曲的卷积方法。直接使用EquiConv相比标准卷积作用于具有更好的关联性。
RELATED WORK
房间布局为很多任务提供基础比如:深度估计、虚拟物体摆放、室内物体识别、室内定位、人的位姿估计。
PanoContext(ECCV 2014) 首先将恢复房间布局从透视图扩展到全景图,限制:假设布局是一个简单的3D box。
Pano2CAD 扩展非盒型房间,但是受限于物体检测器
LayoutNet(CVPR 2018) 是直接在全景图上预测房间布局具有代表性的模型,输入是全景图和消失线(消失点估计后划分线段),通过FCN,得到墙边和墙角map
DuLa-Net(CVPR 2019) 使用全景图+透视天花板图,各自一个encode-decoder分支,后处理依赖2D的Manhattan约束。
HorizonNet(CVPR 2019) 把房间布局编码成为3个1维向量,结合LSTM的记忆性。
所有这些方法都需要预处理或后处理步骤,如提取直线和消失点或拟合房间模型(Manhattan约束),这增加了它们的时间花费。
全景图和使用传统CNN,无法做到区域模式共享(translational weight sharing ineffective.),即在全景图考中心的区域的卷积效果和在全景图顶部卷积效果无法做到一样,因为顶部扭曲更严重,但是标准卷积全局区域都做同样处理。
CORNERS FOR LAYOUT
A. Network Architecture
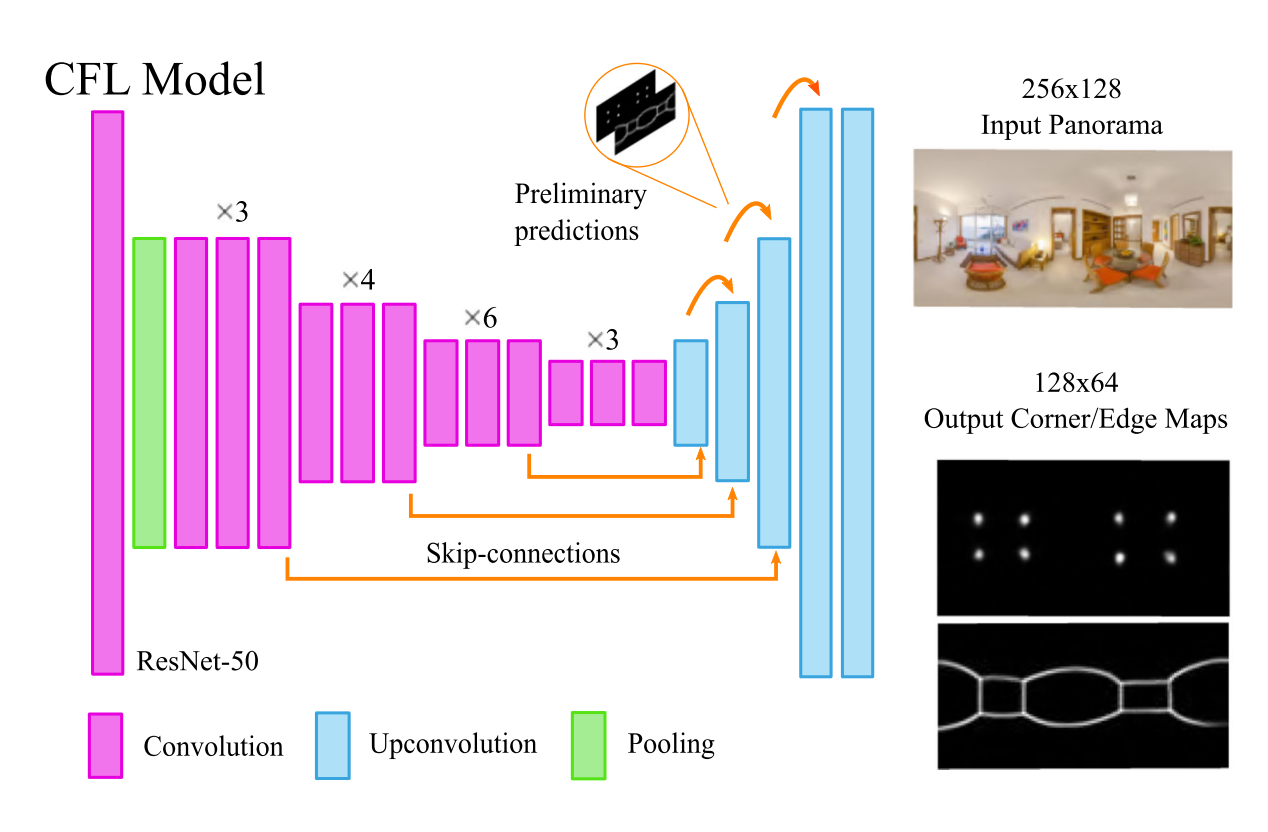
FCN结构
encoder: ResNet-50,在ImageNet预训练学习低级特征。输入256 × 128
decoder: 布局的边(墙线)和角(墙角)位置联合,放在2个输出channel上,而不是输出2个分支。此外,结合了2个不同思想:跳跃连接(skip-connections )。初步预测(preliminary predictions)将低分辨率传递给后续层,确保早期训练可以进行。激活函数:ReLU + Sigmoid(输出层)
根据卷积的不同提出2中网络结构。
CFL StdConvs:encoder使用标准卷积(Standard Convolutions),decoder使用上卷积(up-convolutions)。
CFL EquiConvs:encoder使用球面卷积(Equirectangular Convolutions),decoder使用EquiConvs的 + 上池化(unpooling) 和 上采样(upsample)。
B. Training
1) Objective Output:
和LayoutNet输出类似,2个map:
Y
m
=
{
y
1
m
,
…
,
y
i
m
,
…
}
,
y
i
m
∈
{
0
,
1
}
\mathcal{Y}^{m}=\left\{y_{1}^{m}, \ldots, y_{i}^{m}, \ldots\right\}, y_{i}^{m} \in\{0,1\}
Ym={y1m,…,yim,…},yim∈{0,1}
其中
m
=
e
m=e
m=e表示边,
m
=
c
m=c
m=c表示角。由于边界是一条线,墙角是一个点。所以微小的误差带来损失是比较大的。所以使用Gaussian滤波,loss变为连续值易于收敛。

看网络结构输出应该和输入一样的,为什么不一样了呢?
2) Loss Function:
由于大多数都是背景,即~95%都是0,所以训练时添加类标权重
w
t
=
N
N
t
w_{t}=\frac{N}{N_{t}}
wt=NtN平衡类别失衡,每个map的每个像素交叉熵loss表示为:
L
i
m
=
w
1
(
y
i
m
(
−
log
(
y
^
i
m
)
)
)
+
w
0
(
(
1
−
y
i
m
)
(
−
log
(
1
−
y
^
i
m
)
)
)
\begin{aligned} \mathcal{L}_{i}^{m}=& w_{1}\left(y_{i}^{m}\left(-\log \left(\hat{y}_{i}^{m}\right)\right)\right) +w_{0}\left(\left(1-y_{i}^{m}\right)\left(-\log \left(1-\hat{y}_{i}^{m}\right)\right)\right) \end{aligned}
Lim=w1(yim(−log(y^im)))+w0((1−yim)(−log(1−y^im)))
其中
y
i
m
y_{i}^{m}
yim表示真实值,
y
^
i
m
\hat{y}_{i}^{m}
y^im表示网络预测值。
最小化4种分辨率的loss,之前提到初步预测(preliminary predictions)将低分辨率传递给后续层。loss上表示为:
L
=
∑
k
=
{
1
,
…
,
4
}
∑
m
=
{
e
,
c
}
∑
i
L
i
m
[
k
]
\mathcal{L}=\sum_{k=\{1, \ldots, 4\}} \sum_{m=\{e, c\}} \sum_{i} \mathcal{L}_{i}^{m}[k]
L=k={1,…,4}∑m={e,c}∑i∑Lim[k]
C. From Corner Maps to 3D Layout Current
不像以往使用Manhattan简化3D模型,也被限制在Manhattan布局。当输入的全景图不满足Manhattan假设,那么得到的3D模型可能出错。所以又需要在预处理利用消失点对齐Manhattan假设布局。
CFL采用了被称Soft/Weak Manhattan或Atlanta World的表示,避免了额外的计算。 水平方向不需要互相垂直,即竖直的墙面不要求互相垂直,从而减少对模型的假设。
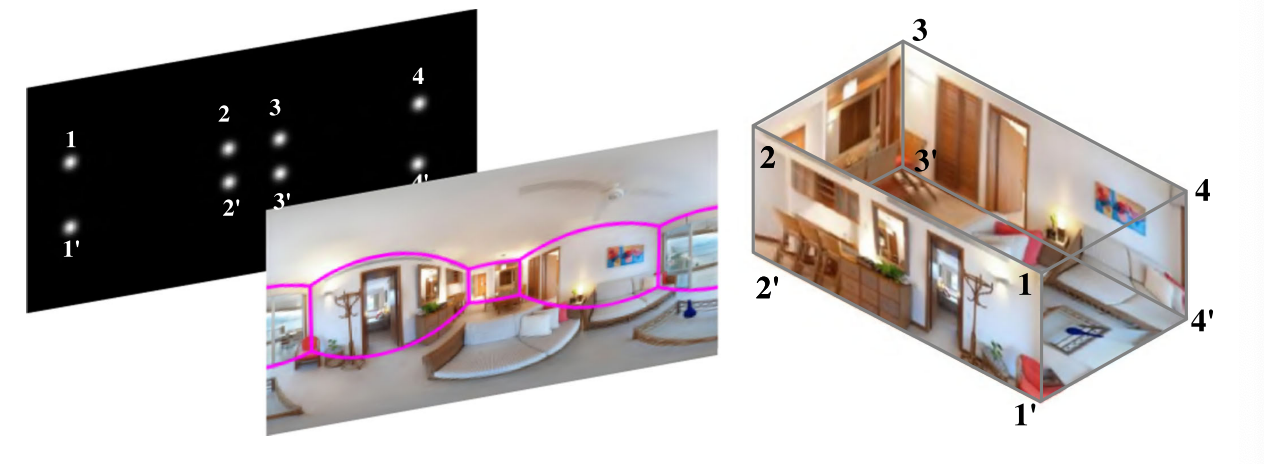
布局生成步骤:
墙角的2D坐标直接选取在map_c(m=c)中的峰值,如果墙角连续则直接连接。只在map_c吗?那map_e的作用仅作为多任务训练调参?
布局假设只有ceiling-floor 平行,墙没有约束。比如floor的墙角
1
′
,
2
′
,
3
′
,
4
′
1',2',3',4'
1′,2′,3′,4′,ceiling墙角
1
,
2
,
3
,
4
1,2,3,4
1,2,3,4在floor的正上方,也就是说要求竖直的墙垂直于floor和ceiling,但不要求墙和墙(竖直方向)是垂直的。Soft/Weak Manhattan。
CFL的限制:直接从左向右连接墙角意味着一旦一个墙角被遮挡模型将是错误的。可以添加后处理,但是费时而且需要Manhattan World假设。
其实前面这些部分都没啥创新性,对比18年的layoutnet,网络结构使用的还是FCN,编码表示也无太大区别,loss引入类别权重。最后的布局生成,就是将其简化,减弱约束来达到处理时间缩短,效果可能还没有之前的好。真正创新和提高的地方是EquiConvs。
EQUIRECTANGULAR CONVOLUTIONS
本文重点
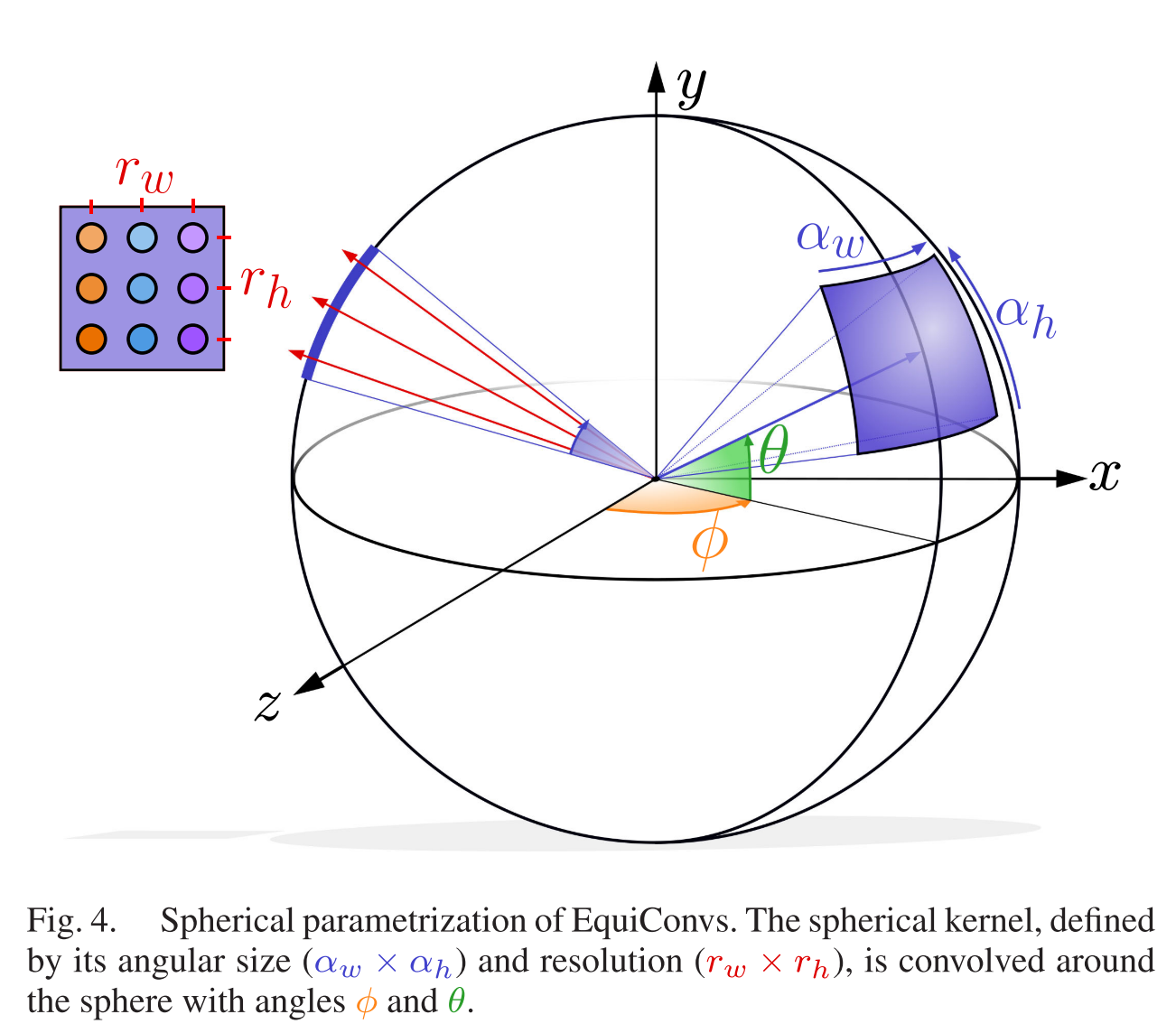
提出一种变形卷积EquiConv,它对全景图进行操作是可以做到区域模式共享(translational weight sharing ineffective.),这里翻译不准确,更一般说法应该是权值共享。
标准全景kernel有size表示卷积窗口大小,EquiConv的size用角度
α
w
\alpha_{w}
αw 和
α
h
\alpha_{h}
αh表示卷积窗口接收的FOV。
标准卷积用图像的行和列定位卷积窗口的中心,EquiConv用球面坐标
ϕ
\phi
ϕ和
θ
\theta
θ定位卷积窗口的中心。
除此之外, EquiConv还需定义对应角度的分辨率参数,所以size表示为角度size
(
α
w
×
α
h
)
\left(\alpha_{w} \times \alpha_{h}\right)
(αw×αh)和分辨率
(
r
w
×
r
h
)
\left(r_{w} \times r_{h}\right)
(rw×rh)。在实现时,一般保存长宽具有一样的纵横比(aspect ratio)
α
w
r
w
=
α
h
r
h
\frac{\alpha_{w}}{r_{w}}=\frac{\alpha_{h}}{r_{h}}
rwαw=rhαh,并且使用长宽一样的方核???(square kernels)有:
α
(
α
w
=
α
h
)
\alpha\left(\alpha_{w}=\alpha_{h}\right)
α(αw=αh),
r
(
r
w
=
r
h
)
r\left(r_{w}=r_{h}\right)
r(rw=rh),
r
r
r和
α
\alpha
α理解:

为了便于计算,可以令数值上
r
=
α
r=\alpha
r=α。此时投影的圆半径为1,看下图:
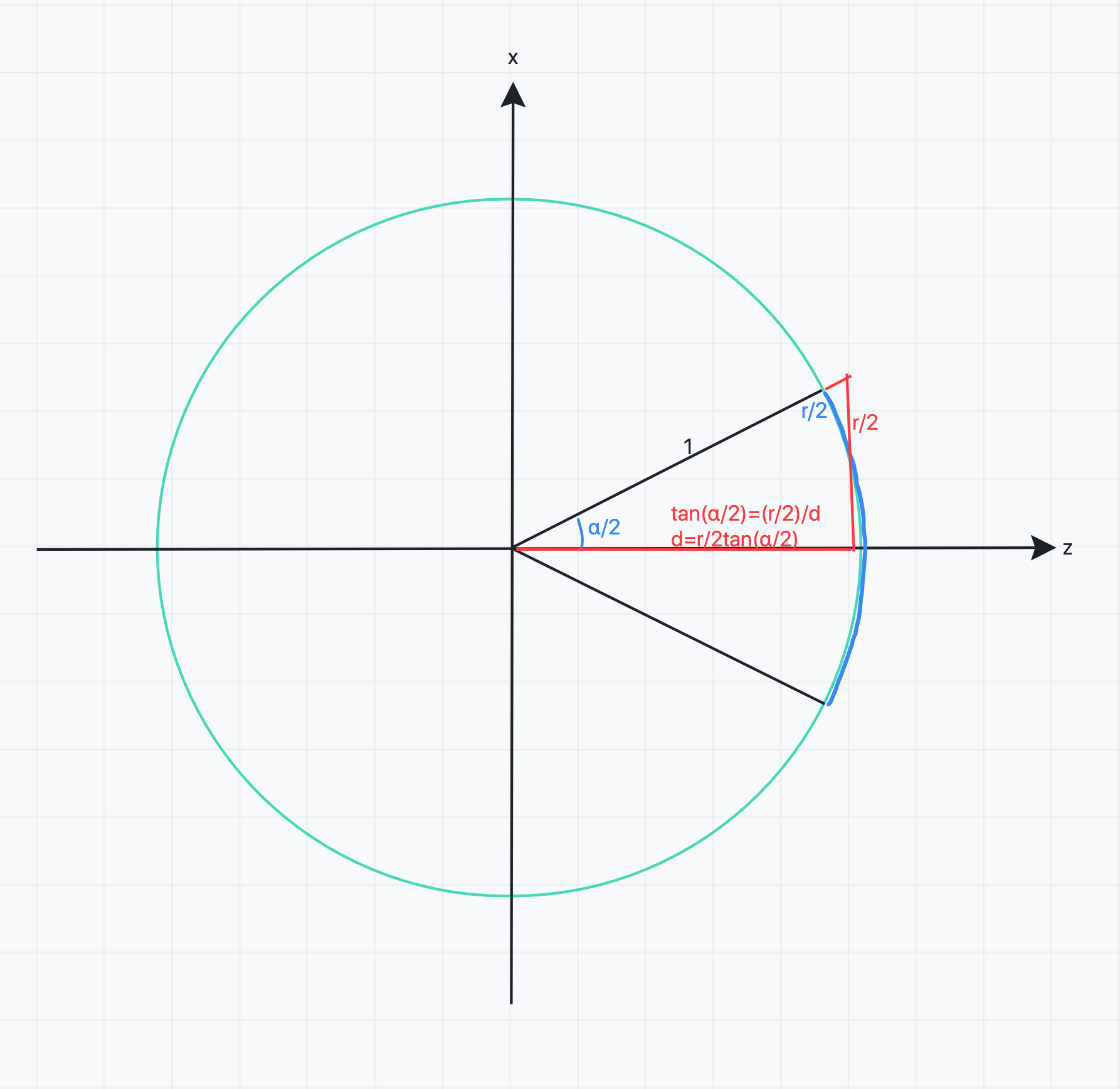
设投影球的半径为
x
x
x,则有:
α
/
2
2
π
=
r
/
2
2
π
x
\frac{\alpha/2}{2\pi} = \frac{r/2}{2\pi x}
2πα/2=2πxr/2
由于
r
=
α
r=\alpha
r=α,所以
x
=
1
x=1
x=1
A. EquiConvs Details
EquiConv的核心实现就是全景图不同位置对于的卷积核实际上是不一样的,这种不一样不是通过学习得到,而是根据
ϕ
\phi
ϕ和
θ
\theta
θ来确定。
定义EquiConv的在等距投影的全景图位置用uv坐标表示: ( u 0 , 0 , v 0 , 0 ) \left(u_{0,0}, v_{0,0}\right) (u0,0,v0,0),表示kernel的中心位置。
下面进行推导,给定中心uv位置,如何确定kernel元素的位置
kernel的元素在球面投影上坐标表示:
p
^
i
j
=
[
x
^
i
j
y
^
i
j
z
^
i
j
]
=
[
i
j
d
]
\hat{p}_{i j}=\left[\begin{array}{l} \hat{x}_{i j} \\ \hat{y}_{i j} \\ \hat{z}_{i j} \end{array}\right]=\left[\begin{array}{l} i \\ j \\ d \end{array}\right]
p^ij=⎣⎡x^ijy^ijz^ij⎦⎤=⎣⎡ijd⎦⎤
i
i
i,
j
j
j是元素的下标,范围
[
−
r
−
1
2
,
r
−
1
2
]
\left[-\frac{r-1}{2}, \frac{r-1}{2}\right]
[−2r−1,2r−1]
为了使得元素包含fov为
α
\alpha
α
d
=
r
2
tan
(
α
2
)
d=\frac{r}{2 \tan \left(\frac{\alpha}{2}\right)}
d=2tan(2α)r
这里的 d d d不是指的投影球的半径,而是值元素3D坐标的z值,初始时 ϕ \phi ϕ和 θ \theta θ均为0。表示的是kernel元素在z=d平面上可以使用 i i i, j j j平面坐标表示,同时 i i i, j j j又可以对应(投影,因为不具有深度,一个点可以表示无穷多不同深度的点)到球面坐标上,而球面坐标可以转为uv坐标。这样的好处是可以避免元素使用球面坐标表示。
接着是正则化和应用旋转矩阵:
p
i
j
=
[
x
i
j
y
i
j
z
i
j
]
=
R
y
(
ϕ
0
,
0
)
R
x
(
θ
0
,
0
)
p
^
i
j
∣
p
^
i
j
∣
p_{i j}=\left[\begin{array}{l}x_{i j} \\ y_{i j} \\ z_{i j}\end{array}\right]=R_{y}\left(\phi_{0,0}\right) R_{x}\left(\theta_{0,0}\right) \frac{\hat{p}_{i j}}{\left|\hat{p}_{i j}\right|}
pij=⎣⎡xijyijzij⎦⎤=Ry(ϕ0,0)Rx(θ0,0)∣p^ij∣p^ij
R
a
(
β
)
R_{a}(\beta)
Ra(β)表示一个绕
a
a
a轴旋转
β
\beta
β的旋转矩阵
对应3D坐标系,等距投影图的中心为角度起始:
ϕ
0
,
0
=
(
u
0
,
0
−
W
2
)
2
π
W
;
θ
0
,
0
=
−
(
v
0
,
0
−
H
2
)
π
H
\phi_{0,0}=\left(u_{0,0}-\frac{W}{2}\right) \frac{2 \pi}{W} ; \quad \theta_{0,0}=-\left(v_{0,0}-\frac{H}{2}\right) \frac{\pi}{H}
ϕ0,0=(u0,0−2W)W2π;θ0,0=−(v0,0−2H)Hπ
所以当知道kernel的中心uv坐标时可以转到经纬坐标再得到3D坐标。
在3D坐标上计算元素的3D坐标(在z=d的平面上偏移量
i
,
j
i,j
i,j,再经过旋转矩阵),再反推kernel元素的uv坐标:
3D坐标到经纬坐标:
ϕ
i
j
=
arctan
(
x
i
j
z
i
j
)
;
θ
i
j
=
arcsin
(
y
i
j
)
\phi_{i j}=\arctan \left(\frac{x_{i j}}{z_{i j}}\right) ; \quad \theta_{i j}=\arcsin \left(y_{i j}\right)
ϕij=arctan(zijxij);θij=arcsin(yij)
经纬坐标到uv坐标:
u
i
j
=
(
ϕ
i
j
2
π
+
1
2
)
W
;
v
i
j
=
(
−
θ
i
j
π
+
1
2
)
H
u_{i j}=\left(\frac{\phi_{i j}}{2 \pi}+\frac{1}{2}\right) W ; \quad v_{i j}=\left(-\frac{\theta_{i j}}{\pi}+\frac{1}{2}\right) H
uij=(2πϕij+21)W;vij=(−πθij+21)H
最终Kenel由原始的中心uv坐标和经过反推的元素uv坐标表示。


在纬度高的位置(
θ
\theta
θ大),图像变形严重,卷积核也发生更大变形以适应。注意到,EquiConvs不需要设置padding,因为kernel元素坐标是从球面上反推回来,360度连续。
EXPERIMENTS
A. Datasets
SUN360
Stanford 2D-3D-S
B. Implementation Details
具体参数设置
r
=
3
r=3
r=3 ,
α
=
r
f
o
v
W
,
\alpha=r \frac{f o v}{W},
α=rWfov, 其中
f
o
v
=
36
0
∘
f o v=360^{\circ}
fov=360∘
The training time for StdConvs is around 1 hour and the test time is 0.31 seconds per image.
For EquiConvs, training takes 3 hours and test around 3.32 seconds per image.
EquiConvs是更慢的,所以本文提到加速方法只是作用在简化预处理和后处理上
C. Network’s Output Evaluation

在处理边界时,EquiConvs好于StdConvs,StdConvs无法做到左右边界连续,而是各自预测墙角。
消融实验:
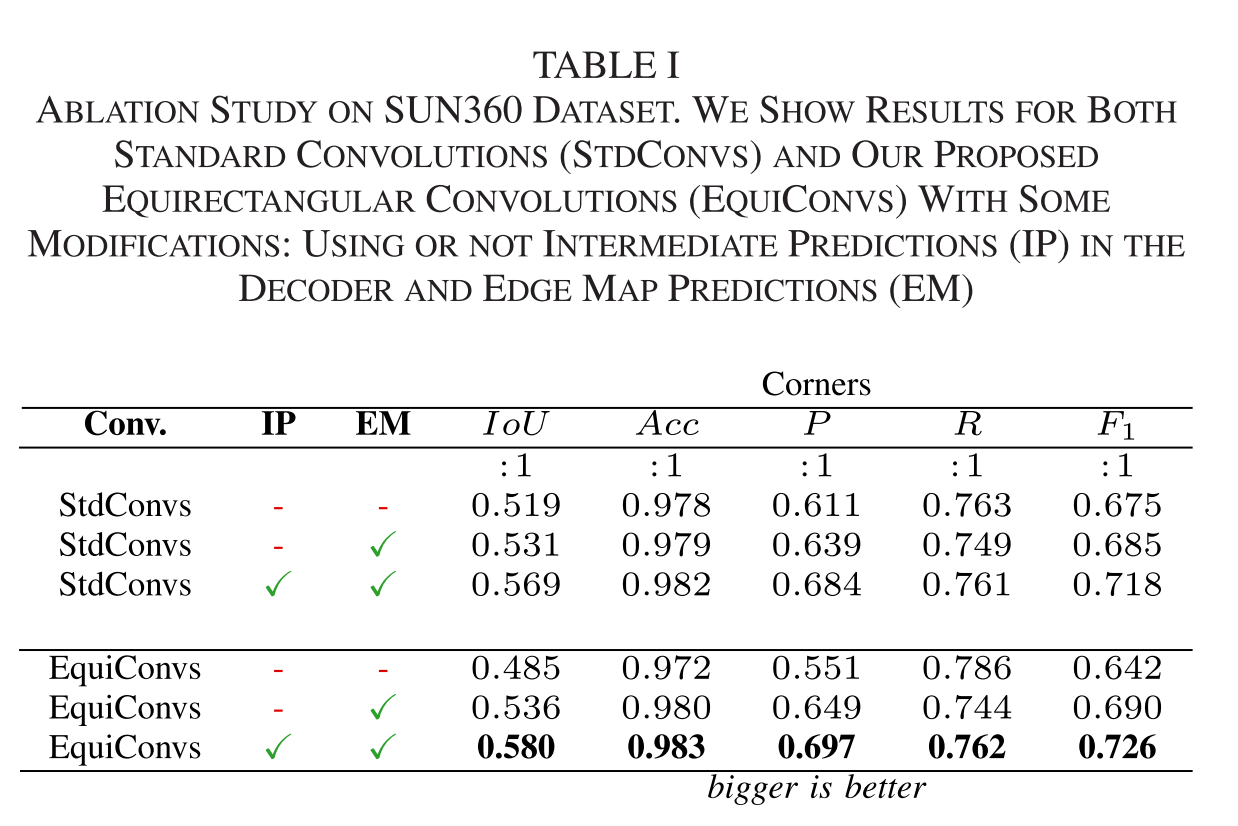
提升效果不是很大。

随机擦除模拟遮挡,可以看到这种做法可以让网络学习遮挡后恢复布局能力。

测试位移和旋转全景图,结果表明,EquiConvs不仅具有更好的整体性能,而且由于不存在因边界缺乏连续性而导致错误的特殊情况,其标准差也小得多。
E. 3D Layout Comparison
和其他方法对比:
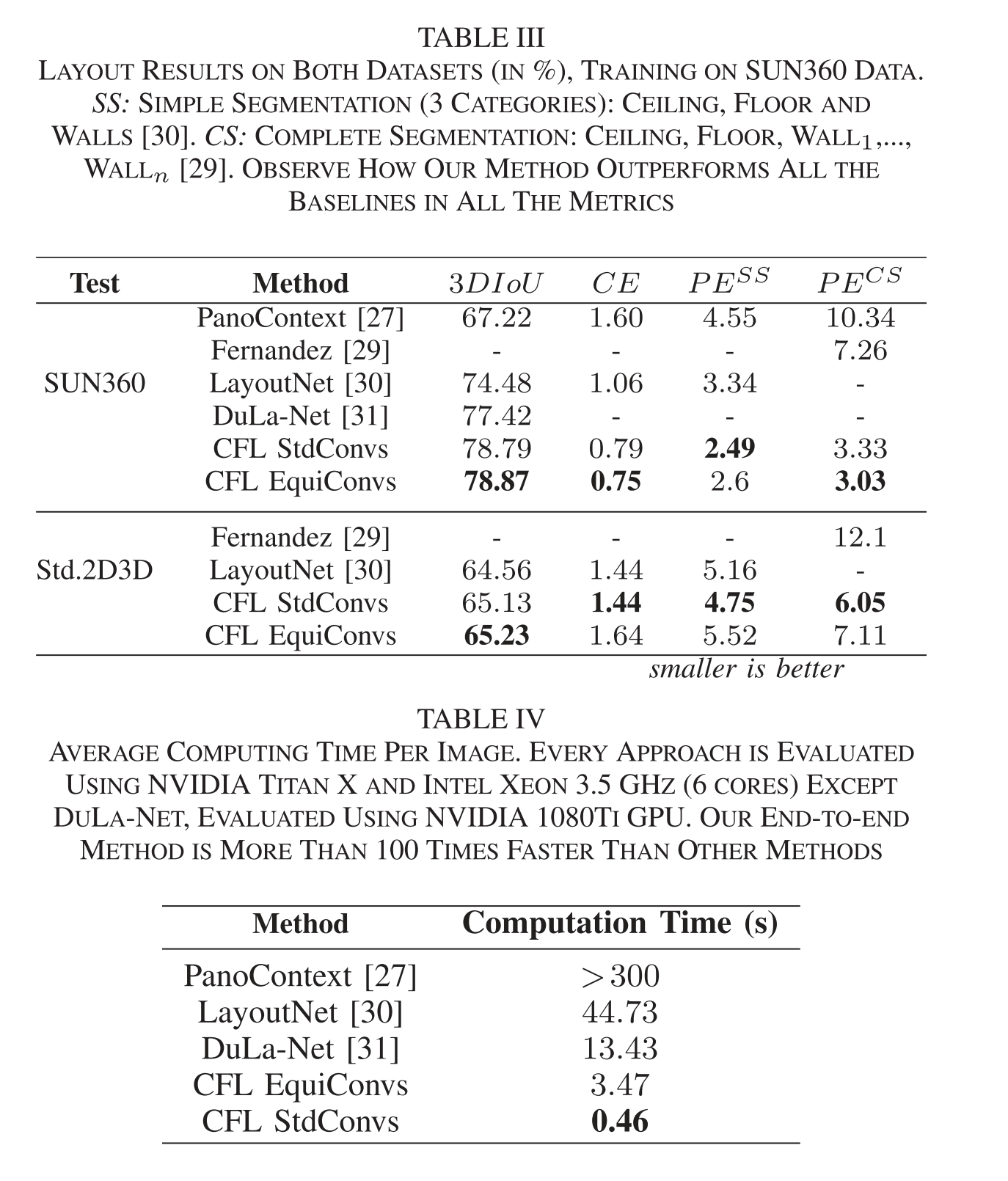
C
E
CE
CE墙角的误差,
P
E
S
S
PE^{SS}
PESS是只区分ceiling, floor and walls三种像素误差,
P
E
C
S
PE^{CS}
PECS没每面墙都区分。处理时间上更快。
CONCLUSION
去除不必要预处理和后处理使得更快(准确度上只能说没有下降,毕竟提升不明显)。2种CFL,StdConvs追求速度(适用于三脚架拍摄的图像),EquiConvs具有更好的鲁棒性(适用于手持相机拍摄的图像)。
全文看下来,大致就是去掉不必要的预处理(线段检测,消失点估计,Manhattan对齐)和后处理(布局生成,Manhattan假设约束),使得在准确率不下降情况下速度提升100倍(StdConvs CFL)。
使用EquiConvs带来的准确度提升并没有预期的那么高,更重要的是EquiConvs更鲁棒,但是时间是StdConvs的9倍。














 1354
1354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









