







输入输出
x = input("这里可以写提示信息!") #输入
print("这里基本遵循C的输出 %s" % x) #输出
print('a','b','c') #输出:a b c,遇到逗号输出空格。
#要在一行写多条语句,可以用分号分割
s = "rat"; t = "car"
注释
#单行注释
''' 多行注释'''
list
#i表示下标,x表示元素,L表示列表[1, 2, 3]
#增
L.insert(i, x) #L.insert(0, 5) 输出[5, 1, 2, 3]
L.append(x) #L.append(5) 输出[1, 2, 3, 5]
L[0:0] = [4,5,6] #在首端插入456,输出[4,5,6,1,2,3]
#删
L.pop(i) #不写i,默认末尾一个,L.pop(0) 输出 [2, 3]
L.remove(x) #L.remove(1) 输出 [2, 3],注意,这里只能删除最先匹配的1,如果有两个1,则依旧还剩一个。
L.clear() #清空列表
L[:] = []
#改
L[i] = x
A[0],A[-1] = A[-1],A[0] #首尾数字交换
change = L
original = L[ : ] #如果此处也赋值L,则修改change,original也会随着改变,所以需要重新建立一个列表。
#查
L = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]#[start : stop : step]
L.count(x) #输出:x在L中的个数。
if x in L:#x是否在列表内
A[-1] #倒序访问,输出:9
L[:5]#同L[0:5],输出:[0, 1, 2, 3, 4]
L[-5:] #输出:[5, 6, 7, 8, 9]
L[1:5] #输出[1, 2, 3, 4]
L[::2] #输出 [0, 2, 4, 6, 8]
L[::-1] #倒序输出[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
#初始化list
A = [x for x in range(10)] #或者 A = list(range(10)) 输出:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
A = [0 for x in range(10)] #输出:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
A = [x*x for x in range(10)] #输出:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
B = list('abcdef')#输出:['a', 'b', 'c', 'd', 'e', 'f']
C = [x for x in range(1,10,2)] #输出: [1, 3, 5, 7, 9]
D = [x for x in A if x%2==0] #条件过滤表达式
E = [i*100+j*10+k for i in range(1,10) for j in range(0,10) for k in range(1,10) if i==k]
#一般不要这么写,让人看着累。
#另一种简单的方法,但是会出现浅拷贝现象,参考https://www.cnblogs.com/btchenguang/archive/2012/01/30/2332479.html
A = [[0]*10]#同样达到上面的效果。输出:[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
A = [[0]*10]*10 #创建二维数组,但是在赋值时,A[0][0]=1,会将所有行的第一个数都设为1,*10的效果还在。
A = [([0]*10) for i in range(10)]#可以修改为如下形式
#合并多个list:
one = [1, 2, 3]
two = ['a', 'b', 'c']
three = one + two #输出:[1, 2, 3, 'a', 'b', 'c']
one.extend(two)#输出:[1, 2, 3, 'a', 'b', 'c']
#用途较广的一种,可以插入任意位置
one[0 : 0] = two #输出: ['a', 'b', 'c', 1, 2, 3]
#删除部分list
three[3 : ] = [] #输出[1, 2, 3]
#注意部分!!!
one = [];two = [1,2,3];one = two;two.clear()#请问one是多少?
#one是空,注意这里赋值要用 one = two[:]
#函数:
#将多维列表行变列,列变行
zip(*list[list])
dict
dict的第一个特点是查找速度快,无论dict有10个元素还是10万个元素,查找速度都一样。而list的查找速度随着元素增加而逐渐下降。
不过dict的查找速度快不是没有代价的,dict的缺点是占用内存大,还会浪费很多内容,list正好相反,占用内存小,但是查找速度慢。
由于dict是按 key 查找,所以,在一个dict中,key不能重复。dict的第二个特点就是存储的key-value序对是没有顺序的!这和list不一样
test = {'Alice':'21',
'Bob':'22',
'Clike':'23'}
#增
test['newName'] = 'newNum' #动态语言,直接写
#删
del dict['Bob'] #删除某个键值
test.pop('Bob') #输出22,删除这个键值
test.clear() #清空字典
#改
test['Bob'] = 23 #直接改
d1 = {'Daul': 75} #检查test是否有Daul,没有则加入
if not 'Paul' in test:
test.update(d1)
#查
test.keys() #输出:不是一个列表或者元组,只能看看,不能操作 dict_keys(['Alice', 'Bob', 'Clike'])
test.values() #输出:dict_values(['21', '22', '23'])
test['Bob'] #输出22,找不到报错
test.get('Bob') #输出22,找不到返回空,不会报错。
len(test) #输出3
函数:
#返回一个字典,键为list的元素,值为元素个数,很好用。
dic = collections.Counter(list)
tuple
tuple一旦创建完毕,就不能修改了, 创建tuple和创建list唯一不同之处是用( )替代了[ ]。
A= tuple(range(10)) #输出: (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
B = tuple(x for x in range(1,10)) #输出: (1, 2, 3, 4, 5, 6, 7, 8, 9)
C = (a,) #只有一个元素要加逗号
set
set 持有一系列元素,这一点和 list 很像,但是set的元素没有重复,而且是无序的,这点和 dict 的 key很像。set的内部结构和dict很像,唯一区别是不存储value,因此,判断一个元素是否在set中速度很快。
set存储的元素和dict的key类似,必须是不变对象,因此,任何可变对象是不能放入set中的。
#默认x是元素,i是下标
a = [1,'b','b',3,3,3,'d','d','d','d',5,5,5,5,5,'f','f','f','f','f','f',
7,7,7,7,7,7,7,'h','h','h','h','h','h','h','h',9,9,9,9,9,9,9,9,9,
'j','j','j','j','j','j','j','j','j','j',11,11,11,11,11,11,11,11,11,11,11]
#增
b = set() #定义空集合
b.add(x) #添加元素x
b.update(x) #添加元素x
#删
s.remove(x) #删除x,不存在会报错
s.discard(x) #删除x,不存在不会报错
s.pop() #随机删除一个元素,不接受参数
s.clear() #清空
#改
for x in set(a): #去除重复的值
b[a.count(x)] = x #去重后做计数,把数量和值写到字典b
for e in reversed(sorted(b.keys())[-10:]):
print e,':',b[e] #排序列表键值并取后10个(数量最大的10个),翻转后打印出数量与值。
#查
s = set([('Adam', 95), ('Lisa', 85), ('Bart', 59)])
for x in s:
print x[0],':',x[1]
s = set([1,2,3])
#集合操作
a = set('abracadabra')
b = set('alacazam')
a - b #输出:集合a中不包含b的元素
a | b #输出:并集
a & b #输出:交集
a ^ b #输出:不同时包含于a和b的元素
#也可以使用函数
set.intersection(a,b)#获取a,b的交集
a.intersection(b)
a.union(b)#并集
a.difference(b)#获取差集a-b
str
#增
one = 'abc'
two = 'efg'
three = one + two = 'abcefg'
#列表转字符串
ls1 = ['a', 1, 'b', 2]
ls2 = [str(i) for i in ls1]
#输出:['a', '1', 'b', '2']这一步必须,否则不能用下面的函数
ls3 = ''.join(ls2) #输出:'a1b2',还有'/'.join(ls2),输出'a/1/b/2'
#删
#一先转换为列表,修改完再转回来,同上
#改
#字符串不能更改,一般使用以下方式:
#切片,只能取,不能改
s='Hello World'
s=s[:6] + 'Bital'
#用replace函数
s='abcdef'
s=s.replace('a','A')
char = chr(num)#和下面相反
num = ord(char)#将字符转换为它的ASCII码
'hello python'.title() #输出 Hello Python
'HELLO PYTHON'.lower() #输出 hello python
'hello python'.upper() #输出 HELLO PYTHON
#查
s.find(x)#返回:x在字符串中出现较低的位置
s.rfind(x)#返回:x在字符串中出现较高的位置
'abcdef'.find('abc') #find:找不到返回-1 、 而in函数返回bool值。
#类似的函数,index。找不到返回ValueError,适合用在try except语句中。
s.index(x, j)#从j以后的位置找,find也有此参数,返回:x在字符串中出现较低的位置
#内置函数
'123456'.isdigit() #判断数字输出 True
'12345 python'.isalnum()#判断是否数字字母混合输出 True
'abcdef'.isalpha() #输出 True
'hello python'.split() #输出['hello', 'python'],中间可以为任意空格
#istitle(): 判定字符串是否每一个单词有且只有第一个字符是大写。
#islower():是否全是小写,返回bool
#isupper():是否全是大写,返回bool
#title(): lower(),upper()实现上述功能。
#reversed函数:倒转字符串,返回一个地址
list(reversed(ls3)) #输出 倒置的列表
#正则表达,挺多
import re
s = "abc 123"
li = re.findall("[a-z0-9]+", s)
python常用函数
函数
#sorted 排序函数
sorted(s)
#enumerate函数:可以输出索引和值
for index, num in enumerate(L):
print(index,num)
#isinstance函数:判断x是不是字符串
isinstance(x, str)
#eval函数:输出65280;将字符串转换为表达式,并输出二进制
str1 = '0xff00'
print (eval(str1))
#random函数:输出函数返回数字 N ,N 为 a 到 b 之间的数字(a <= N <= b),包含 a 和 b。
import random
print(random.randint(a,b))
一、介绍
课程来源:慕课网 python入门
读完python入门课程和后续课程后,觉得比较混乱,想整理一下自己的知识点。如果对你有帮助那再好不过。前面会给出代码,如果觉得看的懂可以直接跳过我给的解释,如果觉得有疑问,后面的我会给出详细的解释。
@python是动态语言,你会发现定义一个变量可以任意,甚至随便赋值都可以。这和静态语言严格申明变量类型有所不同,下面是一些关于两种语言的摘要,静态语言以Java为例。
静态类型有利于工具做静态分析,有利于性能优化,有利于代码可读性
有些人总是拿完成同样任务所用代码量来做比较,得出python优于java的结论,不得不说这是非常片面的观点。java是有些啰嗦,不过ide能帮忙减少80%以上的键盘敲击,同时静态分析能帮忙解决80%以上的低级错误,代码提示能帮忙减少80%以上的查文档时间,至于强大的重构能力更是python望尘莫及的,所以只要是稍微大的项目,用java很可能比python开发速度更快。
越是复杂的项目,使用静态语言可以利用编译器更早的发现和避免问题。这并不是说动态语言并不能用于大型项目,但是在超过一定规模之后,动态语言轻便灵活的优势就会被重构时的overhead给抵消掉。另一个原因是性能上的。同理,也不是动态语言写不出高效的代码,而是你花在优化上的时间会更多,而团队人多了水平难免参差不齐,不如静态语言稳妥。
那静态类型语言的优势究竟是什么呢?我认为就是执行效率非常高。所以但凡需要关注执行性能的地方就得用静态类型语言。其他方面似乎没有什么特别的优势。
@优雅,明确,简单。适合开发系统工具和脚本,网站。代码量最少,开发快,但运行较慢。不适合贴近硬件,游戏适合用C要用到渲染等技术,ios和Android都有自己的语言。
@python2.7版本和3.X版本不兼容,用的早的程序大多是2.7,但是2020后,2.7就不在用了,主要用于维护。所以现在开始学习的可以学3.X。虽然上面那个课程是2.7版本的。
本书把大一点的Python脚本称为程序,简单的Python称为脚本。
@跨平台,几个系统下都能运行。
@Python的优点是具有强大的模块功能。
@Python解释器会将.py文件编译为.pyc字节码文件,再编译为.pyo文件计算机可以识别。
@命名规则:
模块名,就是文件名,用小写加下划线的形式。lower_with_under
类名:Pascal风格,CapWords
Functions: 小驼峰命名,myFirstName
@安装python很简单,到官网下载下一步安装,记住安装路径,一般不要安装到C盘,除非你的C盘很大。可以在DOS窗口里查看

出现这种错误需要修改环境变量,将你的python路径添加进去,
我的电脑–》属性–》高级系统设置–》环境变量–》系统变量Path
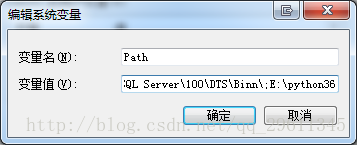
记住前面加分号**“;”**不是冒号。安装的时候提醒过你记住你的安装位置了。
@在Python中,等号=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量,这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。
@对缩进要求严格,首行不能有空格。
@理解变量在计算机内存中的表示也非常重要。当我们写:a = 'ABC’时,Python解释器干了两件事情:
- 在内存中创建了一个’ABC’的字符串;
- 在内存中创建了一个名为a的变量,并把它指向’ABC’。
@用PDB调试
Import pdb
pdb.set_trace() #相当于运行断点,停在这里,然后可以用p 变量名 ,查看变量。或者用命令c继续运行。IDE最上面有基本调试工具。















 680
680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









