







C++11新特性
文章目录
1.C++11的诞生来由
- C++11标准是 ISO/IEC 14882:2011 - Information technology – Programming languages – C++ 的简称
- C++11是C++的标准委员会在
2011年更新的C++新特性。说白了就是一个升级包。和JAVA\PYTHON这种更新比较频繁的语言相比,C++更新的就没有那么顺风顺水了,而且每一次更新虽然修复了一些问题,但也带来了更多的“没太大必要”的更新 - 2011年发布的C++标准,对C++98的一次重大修正
2.新特性:{}初始化
2.1 对于{}的使用形式
官方的意思:C++11提供了{}初始化的方法用来简单化列表初始化和其他初始化
int main()
{
//{}初始化的简单使用
int arr1[] = { 1,2,3,4,5 };//直接用{}初始化
int arr2[]{ 1,2,3,4,5 };//去掉赋值符号=也可以用,但代码可读性会变差
pair<int, int>(1, 1);//括号改成{}也能初始化
pair<int, int>{1, 1};//直接用{}初始化
pair<string, int>* pr = new pair<string, int>[2]{ {"sort",1} ,{"good",2} };//直接用{}初始化pari数组
return 0;
}
我的看法:实际使用中我们还是更多的使用new,而不是直接用{},因为这样让代码可读性变差了
2.2 new中{}的使用
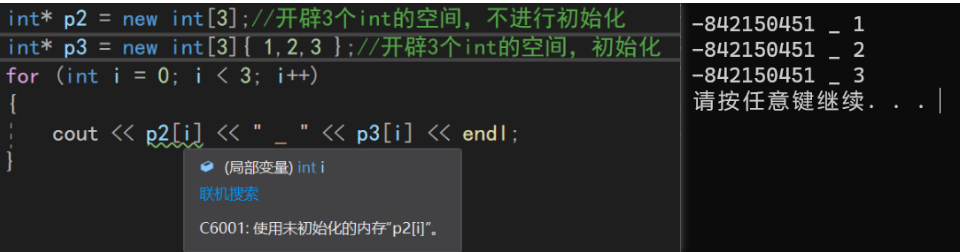
我们曾经使用new有()和 []的区别:int *p1 = new int(3);//开辟一个int的空间,并初始化为3 int *p2 = new int[3];//开辟3个int的空间,不进行初始化 //-------------------------------------------------- //TestA代码 struct TestA { int _a; int _b; }; void TestInit() { int arr1[] = { 1,2,3,4,5 }; TestA t1 = { 1,2 }; int* p2 = new int[3]; int* p3 = new int[3]{1,2,3}; for(int i=0;i<3;i++) { cout<<p2[i]<<"_"<<p3[i]<<endl; } }
- 在C++11中,我们可以直接用花括号,对new开拼出来的数组进行批量初始化。打印的时候,可以看到
p2中的数据都是没有进行初始化(vs也报了警告)而p3中的数据都完成了初始化
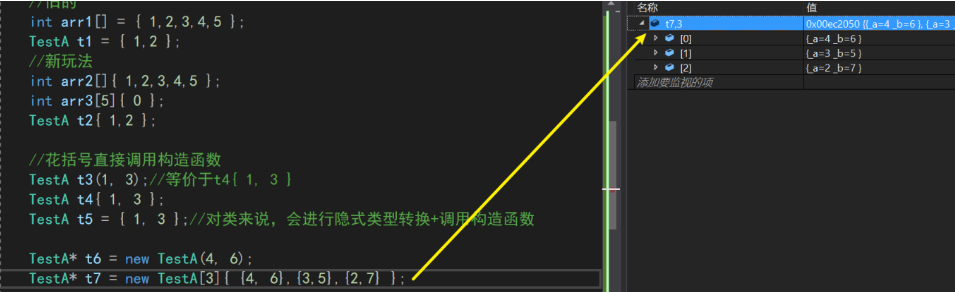
对于结构体数据而言,我们可以用花括号直接调用其构造函数
其中t5是发生了隐式类型转换+调用构造函数进行的初始化
TestA t5 = { 1, 3 };//对类来说,会进行隐式类型转换+调用构造函数通过调试+打断点可以看到其调用了构造函数进行初始化:
- 同样的,调用new的时候,我们可以用多个花括号的方式进行批量初始化。这在
new一个对象数组的时候非常方便


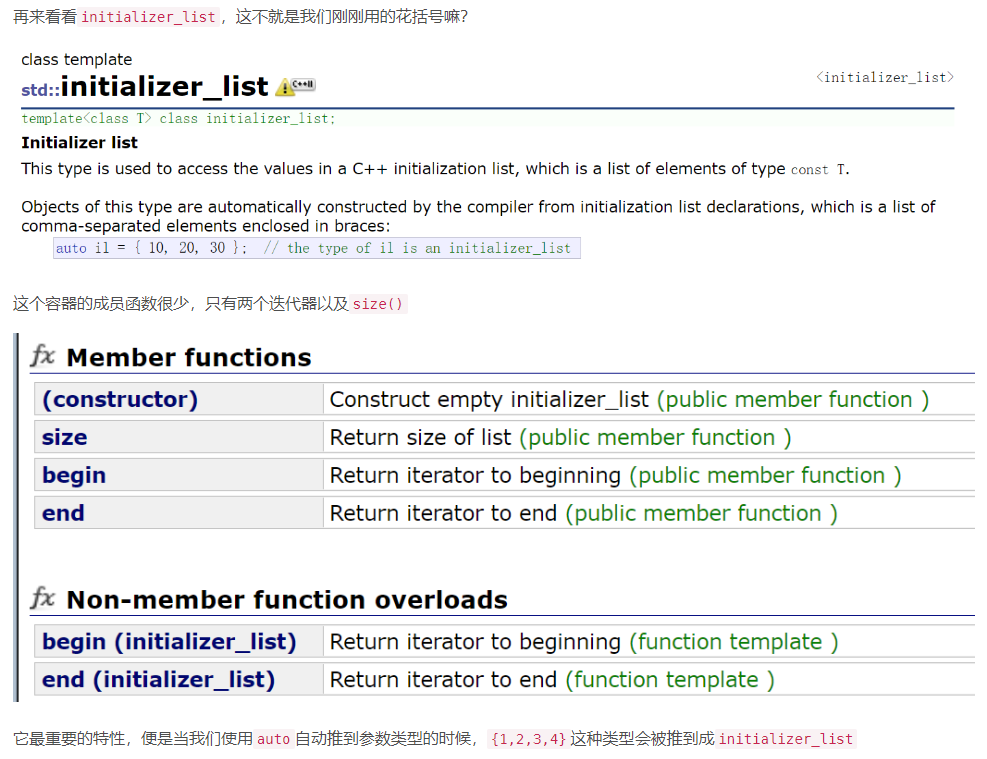
2.3 initializer_list的了解
{}在C++11里面是一个类型,initializer_list,也叫初始化列表,用于表示某种特定类型的值的数组,和vector一样是一种模板类型
//initializer_list函数模板
//initializer_list头文件为#include<initializer_list>
template<class T>
class initializer_list;
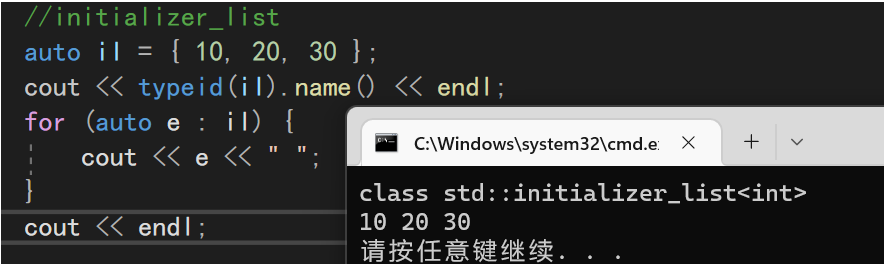
initializer_list的类型的验证:
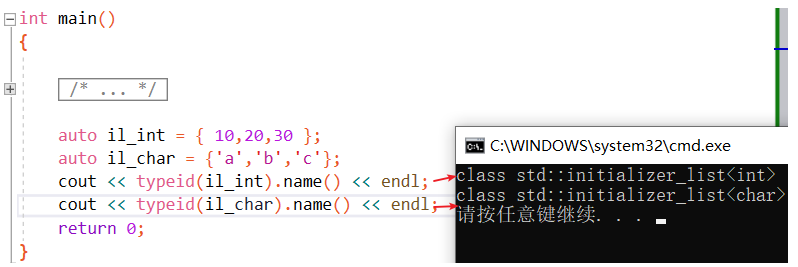
要介绍initializer_list的使用,有必要先谈一谈列表初始化:
C++11扩大了初始化列表的适用范围,使其可用于所有内置类型和用户定义的类型。无论是初始化对象还是某些时候为对象赋新值,都可以使用这样一组由花括号括起来的初始值了。使用初始化列表时,可添加=,也可不添加
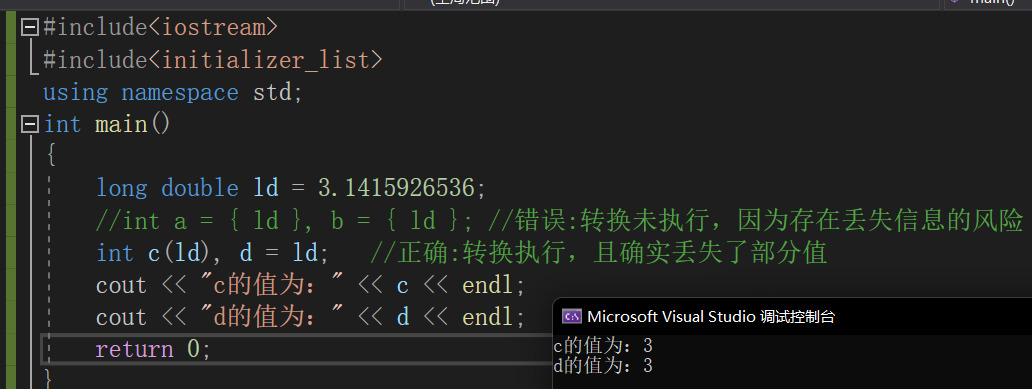
//定义一个变量并初始化 int units_sold=0; int units_sold(0); int units_sold={0}; //列表初始化 int units_sold{0}; //列表初始化当初始化列表用于内置类型的变量时,这种初始化形式有一个重要特点:如果我们使用列表初始化值存在丢失信息的风险,则编译器将报错:
#include<iostream> #include<initializer_list>//initializer_list头文件 using namespace std; int main() { long double ld = 3.1415926536; int a = { ld }, b = { ld }; //错误:转换未执行,因为存在丢失信息的风险 int c(ld), d = ld; //正确:转换执行,且确实丢失了部分值 return 0; }
列表初始化就谈到这里,接下来介绍initializer_list的使用
它提供的操作如下:initializer_list<T> lst; //默认初始化;T类型元素的空列表 initializer_list<T> lst{a,b,c...}; //lst的元素数量和初始值一样多;lst的元素是对应初始值的副本 lst2(lst) lst2=lst //拷贝或赋值一个initializer_list对象不会拷贝列表中的元素;拷贝后,原始列表和副本元素共享 lst.size() //列表中的元素数量 lst.begin() //返回指向lst中首元素的指针 lst.end() //返回指向lst中尾元素下一位置的指针需要注意的是,initializer_list对象中的元素永远是常量值,我们无法改变initializer_list对象中元素的值。并且,拷贝或赋值一个initializer_list对象不会拷贝列表中的元素,其实只是引用而已,原始列表和副本共享元素

2.4 initializer_list在STL容器中的使用
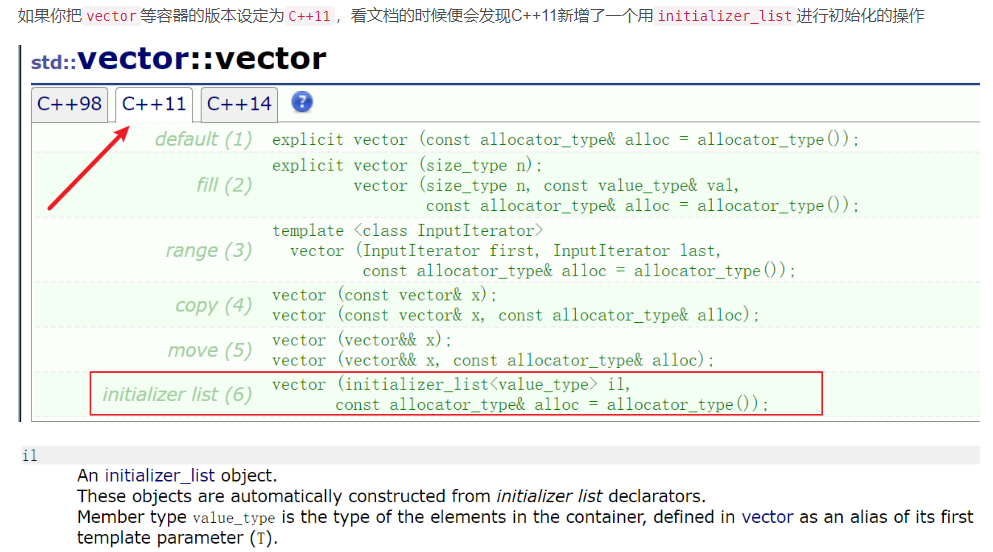
这也解释了为什么上面我们验证initializer_list类型的时候,auto识别出来是initializer_list类型
个人理解,当其他容器使用
initializer_list进行初始化的时候,本质上调用的接口和利用迭代器进行初始化是一样的
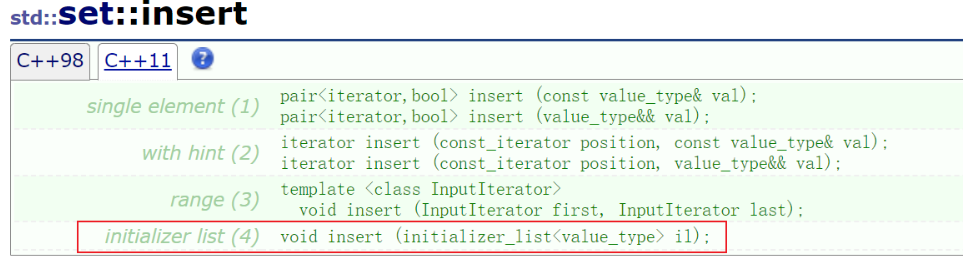
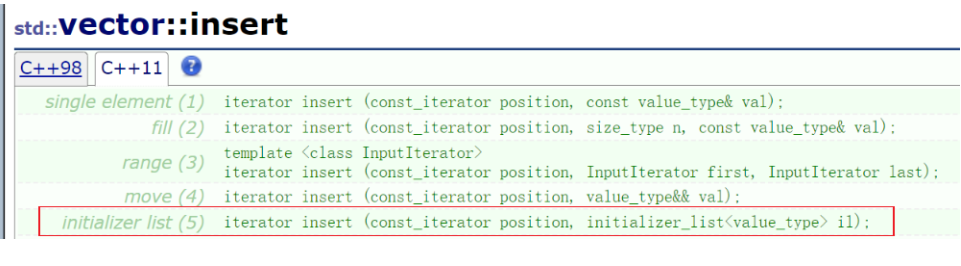
2.5 initializer_list的插入操作扩展
部分容器的
insert函数也添加了使用il进行插入连续数据的操作
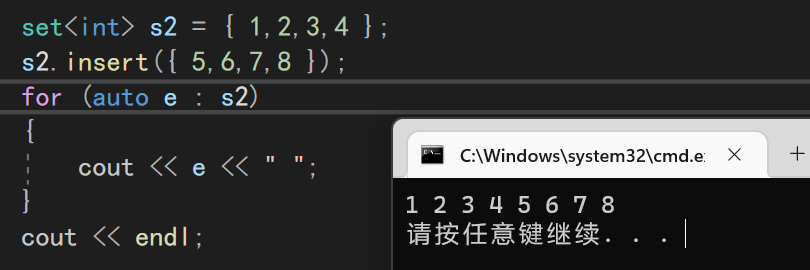
set<int> s2 = { 1,2,3,4 }; s2.insert({ 5,6,7,8 }); for(auto e: s2) { cout<<e<<" "; }
在
vector中使用il插入的时候,需要指定pos位置这个和vector的其他几个插入函数是一样的
3.新特性:变量声明
3.1 变量声明:auto
C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局 部的变量默认就是自动存储类型,所以auto就没什么价值了- C++11给auto上了实现自动类型推断的全新功能,方便我们在定义一个变量的时候直接用
auto进行类型推导auto num = 1;//自动推导num类型为:int auto p = #//自动推导p类型为: int*需要注意的是,如果想用
auto推到,则必须初始化。只给一个auto num是不行的,你都不给我来个值,我怎么推导你呢
3.2 变量声明:decltype
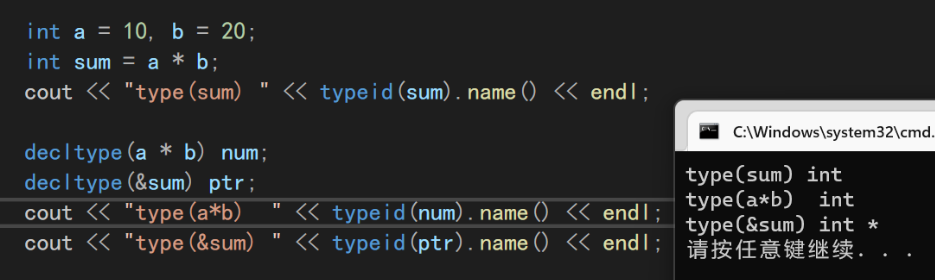
关键字
decltype可以把变量声明成我们想要的目标类型int a = 10, b = 20; int sum = a * b; cout << "type(sum) " << typeid(sum).name() << endl; decltype(a * b) num; decltype(&sum) ptr; cout << "type(a*b) " << typeid(num).name() << endl; cout << "type(&sum) " << typeid(ptr).name() << endl;
3.3 变量声明:typeid
这个关键字上面已经用过好几次了,就是用来打印变量的类型的,
#include<iostream> using namespace std; class C { }; int main() { int a; C c; cout << typeid(a).name() << endl; cout << typeid(float).name() << endl; cout << typeid(c).name() << endl; return 0; }
4.新特性:范围for遍历
范围for:遍历容器内的所有元素,如果要修改需要加引用,其本质上就是迭代器iterator的遍历


5.新特性:左值右值引用
5.1 左值右值概念的区别
在之前我学习了引用的基本操作,但那个是左值引用。当时我尚未引入左指引用和右值引用的区别,这里来剖析一下
要解答这两种引用的区别,首先我们需要直到
左值/右值分别代指什么:
- 左值:
- 可以存在于
=左边或右边- 可以取地址
- 可以对它赋值(const除外)
- 右值:
- 右值是一个表示数据的表达式,比如:函数返回值
[不能是左值引用返回的]、表达式返回值A+B、字面常量10- 右指只能出现在
=的右边,不能出现在左边(可没见过A+B=C的代码语法)- 右指不能取地址
- 左值和右值最大的区别便是:左值可以取地址,右值不能取地址
比如:
//例子一 int main() { int i = 2;//i是左值,2是右值 int j = i;//j和i都是左值 return 0; } //例子二 int main() { int a = 1; //左值引用 int& b = a; const int& x = 1;//const引用是例外 int& c = 5;//error,左值引用不能接受右值 //右值引用 int&& m = 1; int&& n = a;//error,右值引用不能接受左值 int&& p = move(a);//move可以把左值转为右值,及左值退化为右值 return 0; }
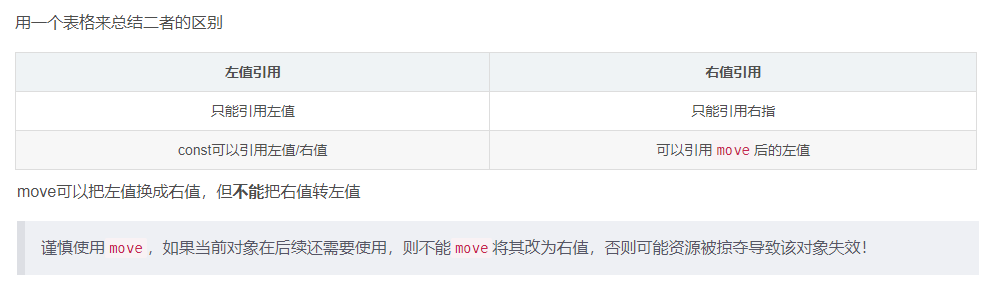
5.2 左值引用
左值引用就是对左值的引用
// a、b、c、*a都是左值 // 对象内部的*this也是左值 int* a = new int(0); int b = 1; const int c = 2; // 以下是对上面左值的 左值引用 int*& rp = a; int& rb = b; const int& rc = c; int& p = *a; // 引用相当于别名,修改引用后的内容相等于修改原本的参数 // 左值引用:其作用主要是在针对出了作用域不会销毁的变量进行引用返回,以节省拷贝的代价。亦或者是引用传参,减少形参拷贝代价
5.3 右值引用
右值引用分为:
将亡值和纯右值两种关于右值引用中
将亡值概念的介绍(了解即可,没啥用):通常指代一个生存周期即将结束的值(因此其资源可以被转移)。是某些涉及到右值引用的表达式的值,根据C++11标准,以下四种情况属于xvalue:
- 调用函数(无论是隐式还是显式)的结果,该函数的返回类型是对对象类型的右值引用
- 对对象类型的右值引用的强制转换
- 类成员访问表达式,指定非引用类型的非静态数据成员,其中对象表达式是xvalue
- 指向成员表达式的*指针,其中第一个操作数是xvalue,第二个操作数是指向数据成员的指针
//纯右值 10; a+b; Add(a,b); //将亡值 string s1("1111");//"1111"是将亡值 string s2 = to_string(1234);//to_string的return对象是一个将亡值 string s3 = s1+"hello" //相加重载的return对象是一个将亡值 move(s1);//被move之后的s1也是将亡值
一般来说,具名的右值引用(named rvalue reference)属于左值,不具名的右值引用(unamed rvalue reference)就属于xvalue(将亡值),而对函数的右值引用不论是否具名都当做左值处理
常见的右值引用:
double x = 1.1, y = 2.2; // 常见的右值 10; x + y; Add(x, y); // 以下都是对右值的右值引用 int&& rr1 = 10; double&& rr2 = x + y; double&& rr3 = Add(x, y); //右值不能出现在=的左边 //10 = 1; //x + y = 1; //fmin(x, y) = 1;
- 虽然我们不能直接对右值进行
取地址/赋值操作,但是在右值引用过后,便可以对引用值进行取地址/赋值操作- 这是因为右值引用的时候,会把当前引用的数据放入一个位置存起来
- 存放位置:普通变量在
栈,全局变量/静态变量在静态区int&& rr1 = 10;//rr1对右值取地址,从而进行间接的赋值等操作 cout << rr1 << endl;//打印:10 rr1 = 3; cout << rr1 << endl;//打印:3 int* p = &rr1; *p = 2; cout << rr1 << endl;//打印:2
5.4 右值引用使用场景
右值引用可以提高
移动构造/移动赋值等深拷贝场景的效率
- 什么场景可以使用左值引用提高效率?
- 操作符重载:
前置++- 操作符重载:
+=- 出了作用域后不会销毁的变量,如输出型参数(即传入函数进行处理的参数)
- 而有一些场景是左值引用无法处理的:
- 操作符重载:
后置++(需要返回一个全新变量)- 操作符重载:
+(需要返回一个全新变量)- 模拟实现string中的
to_string函数- 这些场景大多有一个特性,那就是会生成一个全新的变量(对象)其对象生命周期出了函数作用域便会销毁(将亡值)
- 如果使用左值引用返回,就会出现访问已经销毁了的对象的错误
对于移动构造的理解:
- 假如现在需要一个一次性对象A来拷贝构造另一个生命周期更长的对象B,一次性对象A用完就销毁了,但是拷贝构造B前还是得去构造这个一次性对象A,是不是觉得有点浪费
- 反正这个一次性对象A的作用也是拷贝出另一个对象B,反正一次性对象A用完就要销毁了,那我们有没有一种办法把A的资源“偷走”给拷贝出来的对象B,这样不就可以减少一次拷贝构造
- 因此就有了移动构造这种方法,来解决这个问题
比如:
test::string to_string(int val) { bool flag = true; if (val < 0) { flag = false; val = 0 - val; } test::string str; while (val > 0) { int x = val % 10; val /= 10; str += ('0' + x); } if (flag == false) { str += '-'; } std::reverse(str.begin(), str.end()); return str; }
- 在默认情况下,如果想使用这个
to_string函数,就需要进行深拷贝进行传值返回,这是无可避免的代价。但是,如果使用左值引用返回,这里就会有bug。因为出了函数作用域后,临时对象str会被销毁。而如果我们使用左值引用取别名,在进行赋值的时候,便会出现利用str的别名进行拷贝构造,而str是一个已经销毁的对象的问题- 而如果我们使用右值引用返回,则不会出现这种问题。前提是我们自己实现了右值引用的构造函数和赋值重载
- 一般我们把右值引用的构造函数/赋值重载称作
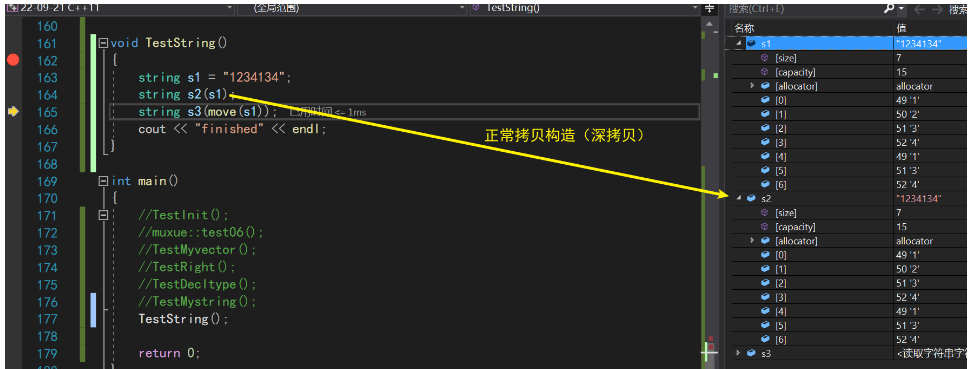
移动构造/移动赋值—为什么叫移动呢?因为右值引用是会直接拿取对象的资源string s1 = "1234134"; string s2(s1); string s3(move(s1));
- 正常深拷贝构造函数
- 右值引用构造函数
右值引用优化:在使用右值进行返回的时候,编译器会进行一波优化,直接使用移动构造拿取资源,避免多次拷贝构造造成的空间和时间损失

5.5 move()函数的理解和万能引用概念
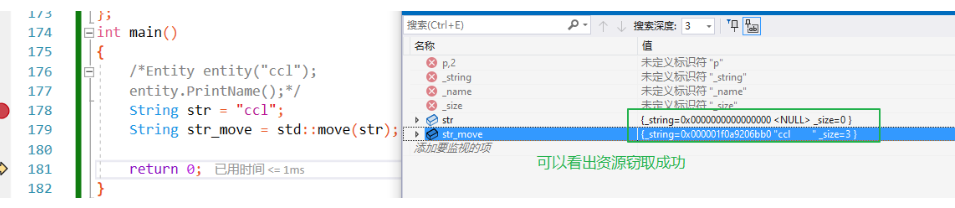
1.move()函数的理解:move的作用就是将左值转为右值使用
上面通过拷贝构造窃取了资源,那假如我们想通过赋值来直接窃取资源呢?方法:重载=即可
注意:处理旧数据,不能窃取自己的资源,防止一块内存被析构两次
String& operator=(String&& other) { if (this != &other)//窃取的不是自己的资源 { //处理旧数据,防止内存泄漏 delete[] _string; //窃取资源 _string = other._string; _size = other._size; //防止一块内存被析构两次 other._string = nullptr; other._size = 0; return *this; } }调用时得用move转成右值取匹配赋值的右值版本
用move时得注意可能把数据转走了,毕竟是把左值转成了右值去使用,要是资源被窃取走了还去用就会造成一下问题
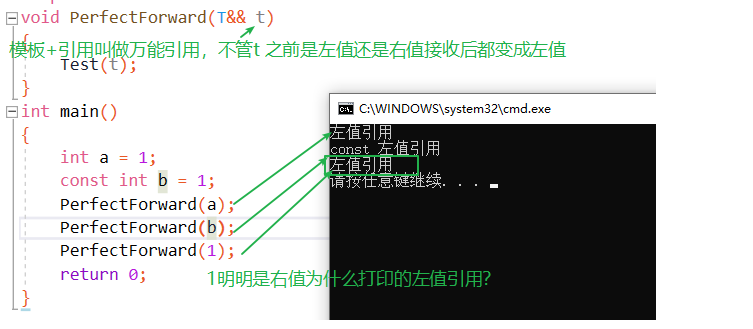
2.万能引用概念
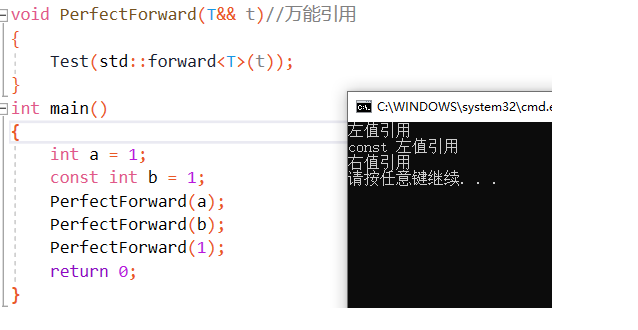
如下代码中,模板里的&&叫做万能引用,而不是右值引用void Test(int&) { cout << "左值引用" << endl; } void Test(const int&) { cout << "const 左值引用" << endl; } void Test(int&&) { cout << "右值引用" << endl; } void Test(const int&&) { cout << "const 右值引用" << endl; } template<class T> void PerfectForward(T&& t)//万能引用 { Test(t);//万能引用 右值接受后变成左值 } int main() { int a = 1; const int b = 1; PerfectForward(a); PerfectForward(b); PerfectForward(1); return 0; }
万能引用改变了值的左右值属性,该怎么保留之前的属性呢,此时就需要std::forward完美转发保留传参过程中对象的原生类型属性
扩展:完美转发
完美转发概念:完美转发的概念很简单,即在函数内部完美转发函数实参的原始类型和值类型,即如果函数传入实参A是左值引用类型且值类型为左值,转发时应保持A的左值属性和左值引用类型std::forward<T>(arg)可以实现完美转发,即如果arg是一个右值引用,则转发之后结果仍是右值引用;反之,如果arg是一个左值引用,则转发之后结果仍是左值引用template<class T> void PerfectForward(T&& t)//万能引用 { Test(std::forward<T>(t));//完美转发 }
完美转发的引用折叠规则:
- 右值引用和右值引用叠加将得到右值引用
- 右值引用和左值引用叠加将得到左值引用
- 左值引用和左值引用叠加将得到左值引用
template <typename T> using TR = T&;//左值引用 // v 的类型 TR<int> v; // int& TR<int>& v; // int& TR<int>&& v; // int& //-------------------------------------- template <typename T> using TRR = T&&;//右值引用 // v 的类型 TRR<int> v; // int&& TRR<int>& v; // int& TRR<int>&& v; // int&& 结论: 1.所有右值引用折叠到右值引用上仍然是一个右值引用(v&& && 变成 v&&) 2.所有的其他引用类型之间的折叠都将变成左值引用(v& & 变成 v&; v& && 变成 v&; v&& & 变成 v&)完美转发的原理:
template< class T > T&& forward( typename std::remove_reference<T>::type& t ) noexcept;//左值引用 template< class T > T&& forward( typename std::remove_reference<T>::type&& t ) noexcept;//右值引用
std::remove_reference<T>的作用就是去掉T中的引用,它是通过模板特化来实现:template< class T > struct remove_reference {typedef T type;}; template< class T > struct remove_reference<T&> {typedef T type;}; template< class T > struct remove_reference<T&&> {typedef T type;};根据上述引用折叠规则,如果
T是int&,则T&&即为int&;反之,如果T是int&&,则T&&为int&&
6.新特性:新增的默认成员函数
在初识类和对象的时候,提到了C++的几个默认成员函数:
- 构造函数
- 拷贝构造函数
- 析构函数
- 拷贝赋值重载
- 取地址重载
- const取地址重载
- 在
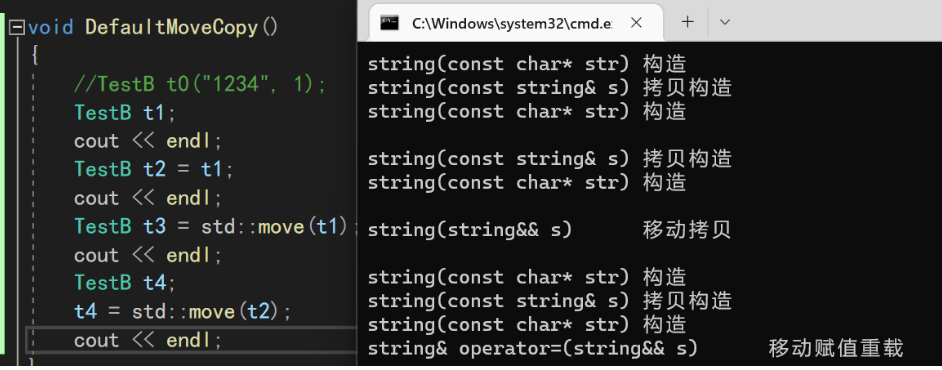
C++11中也多了两个成员函数,那便是前文所讲述的移动构造/移动赋值- 但是想让编译器默认生成移动构造可没那么容易:只有你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,编译器才会帮你整一个移动构造出来
- 编译器默认生成的移动构造:对于内置类型会执行逐成员按字节拷贝;对自定义类型成员,则需要看这个成员是否实现移动构造, 如果实现了就调用移动构造,没有实现就调用拷贝构造
class TestB { private: test::string _s; int _a; public: TestB(const test::string& s="", int a=0) :_s(s), _a(a) {} }; void DefaultMoveCopy() { TestB t1; cout << endl; TestB t2 = t1; cout << endl; TestB t3 = std::move(t1); cout << endl; TestB t4; t4 = std::move(t2); cout << endl; }
7.新特性:新的关键字
- C++11新加入了关键字:default、delete、final、override
default:成员函数加上=default表示强制生成默认的函数delete:成员函数加上=delete表示删除这个函数,表现为只声明不实现final:被final修饰的类不能继承,修饰的变量成为常量且经初始化后不能改变,修饰的虚函数子类无法重写override:写在函数参数列表后面表示这个函数重写了父类的虚函数,编译器就会去检查是否重写了,如果没有重写就会报错
8.新特性:可变模板参数
可变参数就是参数的个数和类型都是任意的

下面就是一个可变参数的函数模板:
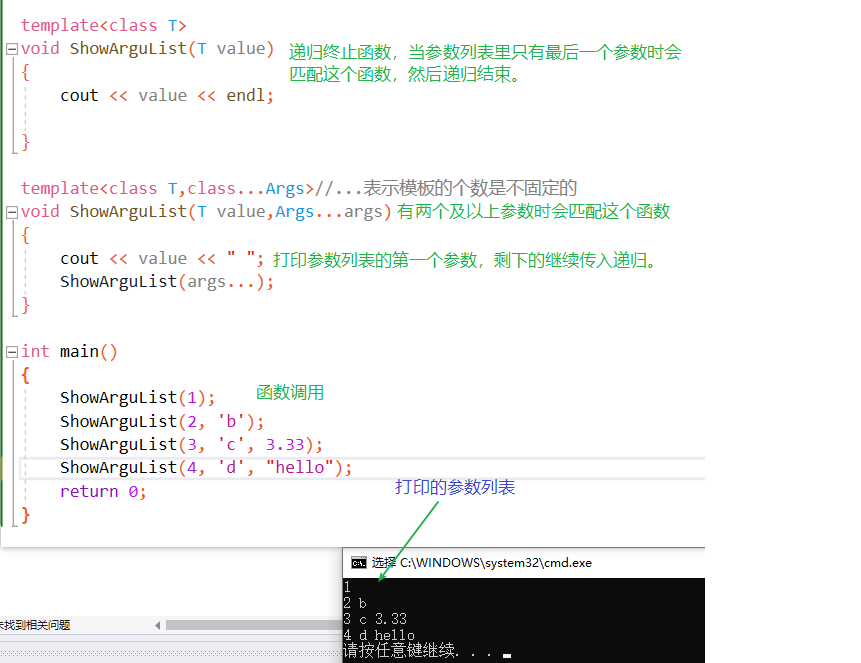
template<class...Args>//...表示模板的个数是不固定的
void ShowArguList(Args...agrs){}
我们把…当作为参数包,我们无法直接获取参数包里的具体参数,需要一点特别的办法来展开参数包获取具体的参数,下面列举两种方法:递归式和逗号表达式展开
1.递归展开
template<class T> void ShowArguList(T value)//递归终止 { cout << value << endl; } template<class T,class...Args>//...表示模板的个数是不固定的 void ShowArguList(T value,Args...args) { cout << value << " "; ShowArguList(args...); } int main()//调用 { ShowArguList(1); ShowArguList(2, 'b'); ShowArguList(3, 'c', 3.33); ShowArguList(4, 'd', "hello"); return 0; }
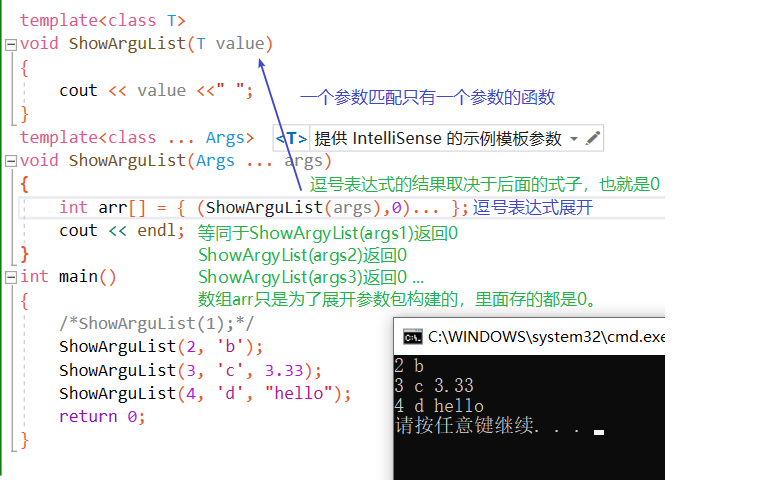
2.逗号表达式展开
template<class T> void ShowArguList(T value) { cout << value <<" "; } template<class ... Args> void ShowArguList(Args ... args) { int arr[] = { (ShowArguList(args),0)... }; cout << endl; } int main() { //ShowArguList(1); ShowArguList(2, 'b'); ShowArguList(3, 'c', 3.33); ShowArguList(4, 'd', "hello"); return 0; }
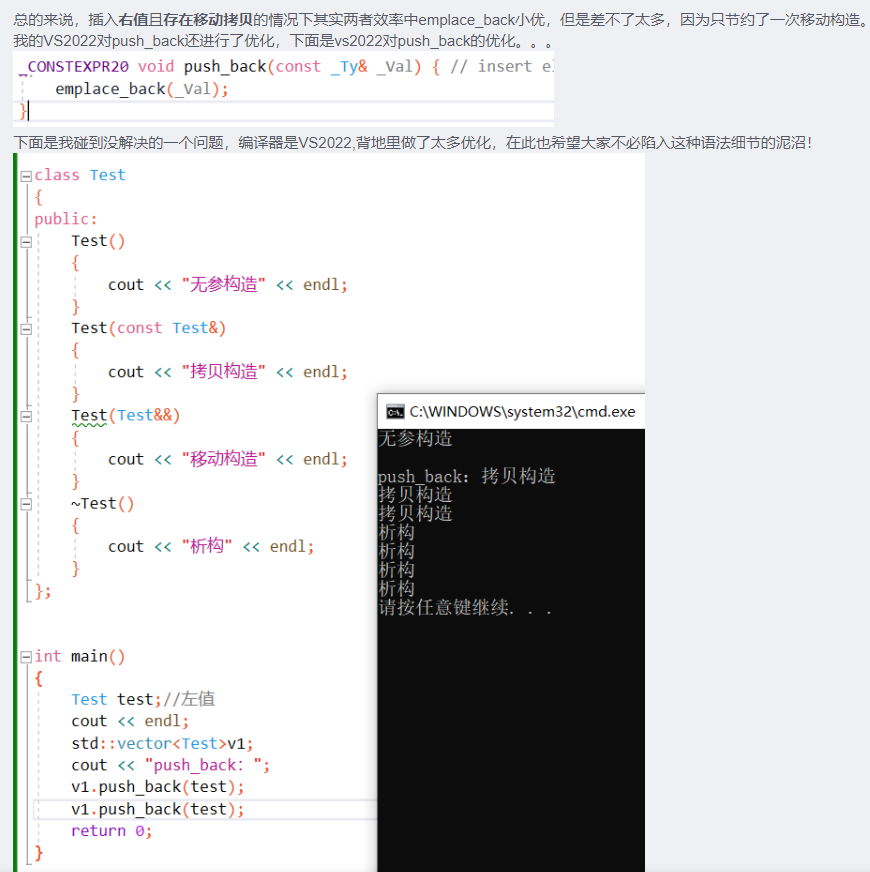
扩展:C++11中的emplace_back和push_back的效率问题
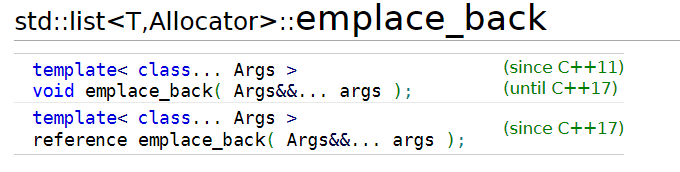
- 可以看到参数列表是可变参数和万能引用。直接给结论:emplace_back的效率确实比push_back高一点
- 一般对于传过来的参数都是就地构造(不需要移动或者拷贝),而push_back需要先构造出来再拷贝,如果传的是右值且存在移动构造,那emplace_back比push_back高效一点(可以少进行一次移动构造)
9.新特性:lambda表达式
lambada表达式格式:
[capture-list](parameters)mutable -> return-type{statement}
说明一下各个位置分别写的是啥玩意:
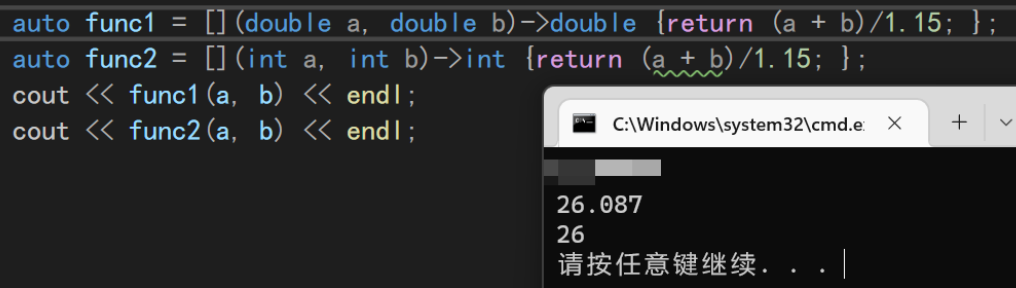
[capture-list]捕捉列表,用于编译器判断为lambda表达式,同时捕捉该表达式所在域的变量以供函数使用(parameters)参数,和函数的参数一致。如果不需要传参则可连带()一起省略mutable默认情况下捕捉列表捕捉的参数是const修饰的,该关键字的作用是取消const使其可修改-> return-type函数返回值类型{statement}函数体,和普通函数一样。除了可以使用传入的参数,还可以使用捕捉列表获取的参数简单lambda使用举例(只用参数列表、可变规则、返回类型、函数体):
可以看到,这个表达式的使用方法和函数完全一致,也成功提供了结果,因为我们返回值的类型是明确的,所以这里可以省略类型,让编译器自己来推断。当然也可以显示指定类型,这样可以更精确的控制
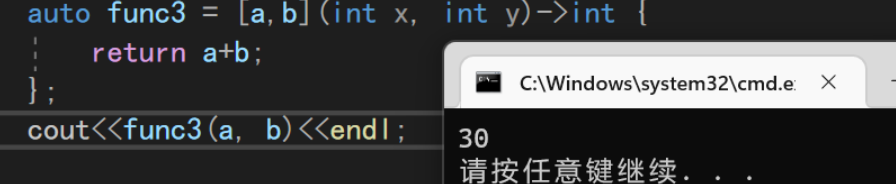
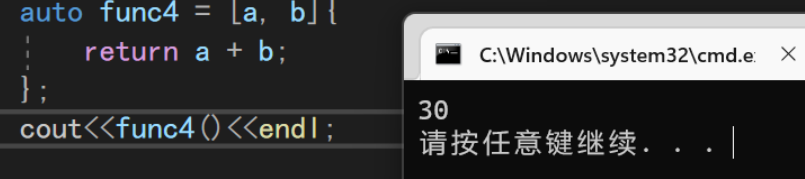
void TestLambda1() { int a = 10, b = 20; auto func3 = [a,b](int x, int y)->int {return a+b;}; //这里我们捕捉了函数作用域里面的局部变量a/b,直接在lambda表达式内部使用 cout<<func3(a, b)<<endl; }
因为不需要传入参数,所以我们可以直接把参数
()和返回值一并省略掉
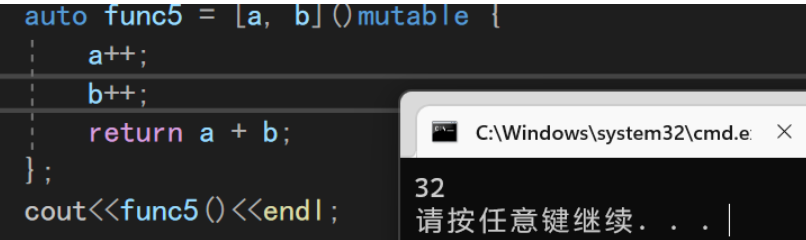
默认情况下:我们捕捉到的参数是带
const的,我们并不能对其进行修改,所以我们需要使用C++11中的新关键字mutable(lambda表达式格式里的)这个关键字使用的时候必须带上函数参数的
()
复杂的lambda表达式(增加使用捕获列表):
注意,当我们在对象里面以值传递方式捕获参数的时候,还需要捕获this指针来调用类内部的函数
[val]:表示值传递方式捕捉变量val [=]:表示值传递方式捕获所有父作用域中的变量(包括this) [&val]:表示引用传递捕捉变量val [&]:表示引用传递捕捉所有父作用域中的变量(包括this) [this]:表示值传递方式捕捉当前的this指针捕获列表有三种情况:全捕获=、引用全捕获&、全捕获+单独操作
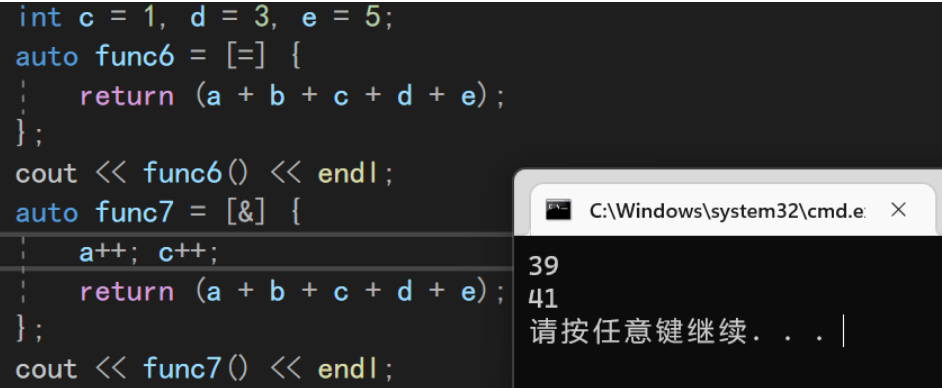
全捕获=:
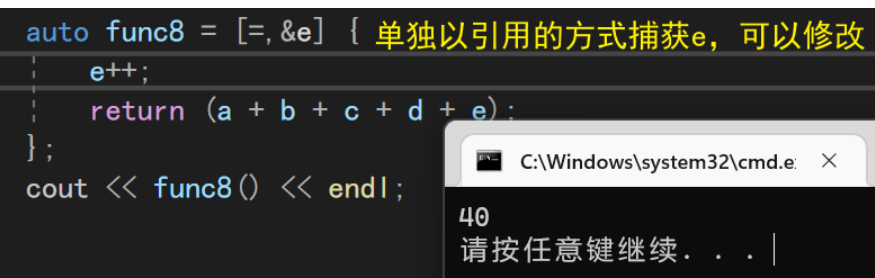
int a = 10, b = 20; int c = 1, d = 3, e = 5; auto func6 = [=]//全捕获= { return (a + b + c + d + e); }; cout << func6() << endl;
- 引用全捕获&:
- 全捕获+单独操作:e默认带const不能修改,需要用其引用
lambda表达式的适用场景:
- 当我们使用
sort函数的时候,就不再需要用仿函数了,而是可以直接用lambda表达式来完成相同的操作,大大增加代码可读性!- 这是因为排序所用的方法直接就在sort这里用
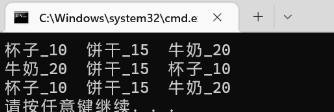
lambda的形式给出了,看代码的时候,也不需要去找定义,更不用担心函数命名规则的问题了vector<Goods> v1 = { {"牛奶",20,100},{"杯子",10,200},{"饼干",15,50} }; //价格升序 sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2) {return g1._price < g2._price; }); for (auto& e : v1) { cout << e._name << "_" << e._price << " "; } cout << endl; v1 = { {"牛奶",20,100},{"杯子",10,200},{"饼干",15,50} }; //价格降序 sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2) {return g1._price > g2._price; }); for (auto& e : v1) { cout << e._name << "_" << e._price << " "; } cout << endl; v1 = { {"牛奶",20,100},{"杯子",10,200},{"饼干",15,50} }; //名称字典序 sort(v1.begin(), v1.end(), [](const Goods& g1, const Goods& g2) {return g1._name < g2._name; }); for (auto& e : v1) { cout << e._name << "_" << e._price << " "; } cout << endl;
lambda底层剖析:仿函数
实际上,lambda的底层就是把自己转成了一个仿函数供我们调用。这也是为何sort可以以
lambda来作为排序方法的原因,底层都是仿函数嘛!



10.新特性:包装器function
- function包装器,也叫作适配器。C++中的function本质是一个类模板,也是一个包装器
- 那么这个东西是用来干啥的呢?—> 把所有的可调用对象封装成统一的格式
- 什么是可调用对象?—> 函数指针、仿函数对象、lambda表达式
我们可以用
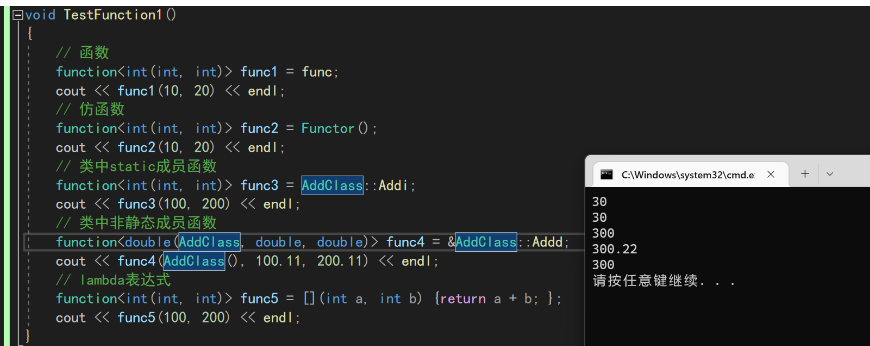
function来包装这些不同的可调用对象,说白了就是产生了另外一个相同的可调用对象。类似于“引用”了这个函数class AddClass{ public: static int Addi(int a, int b){ return a + b; } double Addd(double a, double b){ return a + b; } }; int func(int a,int b){ return a + b; } struct Functor{ int operator()(int a,int b){ return a+b; } }; void TestFunction1() { // 函数 function<int(int, int)> func1 = func; cout << func1(10, 20) << endl; // 仿函数 function<int(int, int)> func2 = Functor(); cout << func2(10, 20) << endl; // 类中static成员函数 function<int(int, int)> func3 = AddClass::Addi; cout << func3(100, 200) << endl; // 类中非静态成员函数 function<double(AddClass, double, double)> func4 = &AddClass::Addd; cout << func4(AddClass(), 100.11, 200.11) << endl; // lambda表达式 function<int(int, int)> func5 = [](int a, int b) {return a + b; }; cout << func5(100, 200) << endl; }
扩展:bind函数绑定
在上面我们用fuction包装一个对象内部的成员函数时,需要利用匿名对象传入一个this指针。这样就很不方便了,明明是两个参数的函数,非要传入第三个参数
要是我们再用map的方式来封装一个可调用的表,那带this指针的函数就没办法一起包装了
比如:
class AddClass
{
public:
static int Addi(int a, int b)
{
return a + b;
}
int Addii(int a, int b)
{
return a + b;
}
};
int func(int a,int b)
{
return a + b;
}
struct Functor
{
int operator()(int a,int b)
{
return a+b;
}
};
map<string, function<int(int, int)>> FuncMap =
{
{"函数",func},
{"仿函数",Functor()},
{"静态成员函数",AddClass::Addi},
{"非静态成员函数",&AddClass::Addii}
};

这时候我们就可以使用bind来进行参数绑定
函数绑定bind函数用于把某种形式的参数列表与已知的函数进行绑定,形成新的函数。这种更改已有函数调用模式的做法,就叫函数绑定。需要指出:bind就是函数适配器
function<int(int, int)> func7 = bind(&AddClass::Addii,AddClass(), placeholders::_1, placeholders::_2);
cout << func7(100, 200) << endl;

补充:占位符placeholders,placeholders是用来占位的,代表这里的参数需要用户手动传入,而_1代表传入的第一个参数,_2就是传入的第二个参数,以此类推
function<int(int, int)> func7 = bind(&AddClass::Addii,AddClass(), placeholders::_1, placeholders::_2);
因为有不同的后缀,所以我们还可以调整绑定的参数顺序:
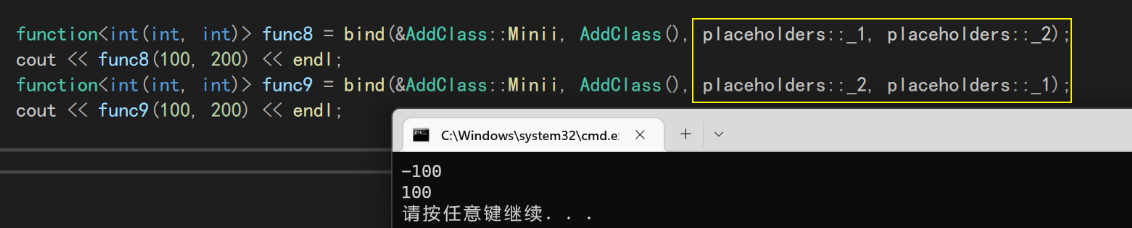
//Minii的作用是a-b
function<int(int, int)> func8 = bind(&AddClass::Minii, AddClass(), placeholders::_1, placeholders::_2);
cout << func8(100, 200) << endl;
function<int(int, int)> func9 = bind(&AddClass::Minii, AddClass(), placeholders::_2, placeholders::_1);
cout << func9(100, 200) << endl;















 2435
2435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











