







 基于著名书籍和自我学习得出的Linux文件系统
基于著名书籍和自我学习得出的Linux文件系统
Linux文件系统
文章目录
1.对文件系统的理解
1.1 文件系统当中的缓冲区
我们来看看下面这段代码,代码当中分别用了两个C库函数和一个系统接口向显示器输出内容,在代码最后还调用了fork函数
#include <stdio.h>
#include <unistd.h>
int main()
{
//c
printf("hello printf\n");
fputs("hello fputs\n", stdout);
//system
write(1, "hello write\n", 12);
fork();
return 0;
}
运行该程序,我们可以看到printf、fputs和write函数都成功将对应内容输出到了显示器上
但是,当我们将程序的结果重定向到log.txt文件当中后,我们发现文件当中的内容与我们直接打印输出到显示器的内容是不一样的
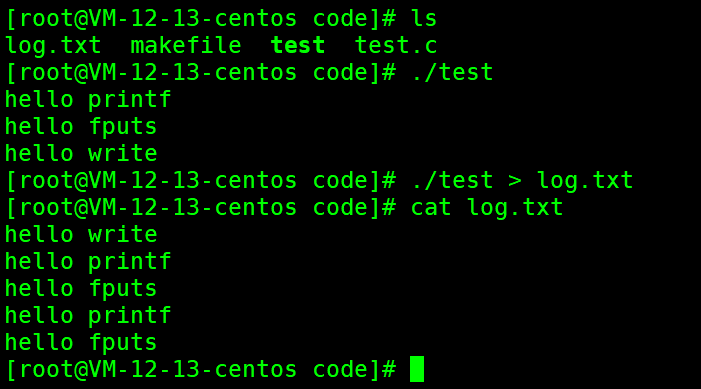
那为什么C库函数打印的内容重定向到文件后就变成了两份,而系统接口打印的内容还是原来的一份呢?
首先我们应该知道的是,缓冲的方式有以下三种:
无缓冲行缓冲 (常见的对显示器进行刷新数据)全缓冲 (常见的对磁盘文件写入数据)
上面C库函数打印两份的原因:
- 当我们直接执行可执行程序,将数据打印到显示器时所采用的就是行缓冲,因为代码当中每句话后面都有\n,所以当我们执行完对应代码后就立即将数据刷新到了显示器上
- 而当我们将运行结果重定向到log.txt文件时,数据的刷新策略就变为了全缓冲,此时我们使用printf和fputs函数打印的数据都打印到了C语言自带的缓冲区当中,之后当我们使用fork函数创建子进程时,由于进程间具有独立性,而之后当父进程或是子进程对要刷新缓冲区内容时,本质就是对父子进程共享的数据进行了修改,此时就需要对数据进行写时拷贝,至此缓冲区当中的数据就变成了两份,一份父进程的,一份子进程的,所以重定向到log.txt文件当中printf和puts函数打印的数据就有两份。但由于write函数是系统接口,我们可以将write函数看作是无缓冲区的,因此write函数打印的数据就只打印了一份
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2704
2704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











