









教程:
http://spark.apache.org/docs/latest/streaming-programming-guide.html
pom:
https://search.maven.org/#search%7Cga%7C1%7Cg%3A%22org.apache.spark%22%20AND%20v%3A%222.3.1%22
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可扩展,高吞吐量,容错流处理。数据可以从许多来源(如Kafka,Flume,Kinesis或TCP套接字)中获取,并且可以使用以高级函数表示的复杂算法进行处理map,例如reduce,join和window。最后,处理后的数据可以推送到文件系统,数据库和实时仪表板。实际上,您可以在数据流上应用Spark的 机器学习和 图形处理算法。

在内部,它的工作原理如下。Spark Streaming接收实时输入数据流并将数据分成批处理,然后由Spark引擎处理,以批量生成最终结果流。

Spark Streaming提供称为离散流或DStream的高级抽象,来表示连续的数据流。DStream可以从来自Kafka,Flume和Kinesis等源的输入数据流创建,也可以通过在其他DStream上应用高级操作来创建。在内部,DStream表示为一系列 RDD。
监听本地端口并计算数据信息
使用streaming处理数据流的步骤:
1. 初始化StreamingContext
2. 通过创建输入DStreams来定义输入源
3. 通过将转换和输出操作应用于DStream来定义流式计算
4. 开始接收数据并使用它进行处理streamingContext.start()
5. 等待处理停止(手动或由于任何错误)使用streamingContext.awaitTermination()
6. 可以使用手动停止处理streamingContext.stop()
//初始化StreamingContext,配置Streaming参数,一秒执行一次
SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkStreaming");
JavaStreamingContext javaStreamingContext = new JavaStreamingContext(conf, Durations.seconds(1));
//监听9999端口
JavaReceiverInputDStream<String> lines = javaStreamingContext.socketTextStream("localhost", 9999, StorageLevels.MEMORY_AND_DISK_SER);
//将监听到的数据分词
JavaDStream<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
//计算单词个数
JavaPairDStream<String, Integer> wordPairs = words.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairDStream<String, Integer> wordCounts = wordPairs.reduceByKey((a, b) -> a + b);
wordCounts.print();
javaStreamingContext.start();
javaStreamingContext.awaitTermination();使用netcat向端口9999中写入数据,nc -lk 9999
JavaStreamingContext还可以从现有的JavaSparkContext创建:
import org.apache.spark.streaming.api.java.*;
JavaSparkContext sc = ... //existing JavaSparkContext
JavaStreamingContext ssc = new JavaStreamingContext(sc, Durations.seconds(1));注意:
- 一旦启动了context,就不能设置或添加新的流式计算
- context停止后,无法重新启动
- 在JVM中只能同时激活一个StreamingContext
- StreamingContext上的stop()也会停止SparkContext,如果只想停止StreamingContext,将stop()方法的可选参数stopSparkContext设置为false
- 只要在创建下一个StreamingContext之前停止前一个StreamingContext(不停止SparkContext),就可以重复使用SparkContext来创建多个StreamingContexts
DStreams
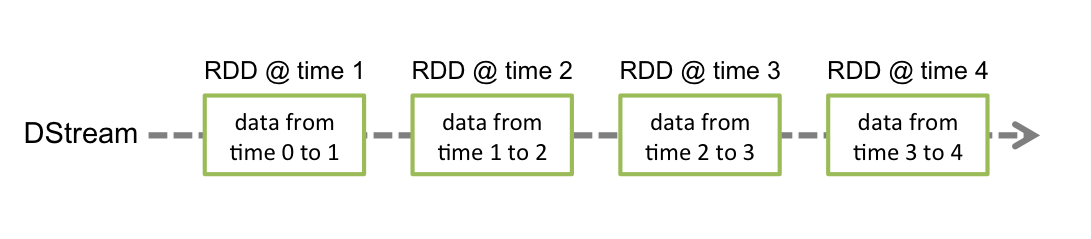
Discretized Stream或DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,在内部,DStream由一系列连续的RDD表示,这是Spark对不可变分布式数据集的抽象。DStream中的每个RDD都包含来自特定时间间隔的数据,如下图所示:
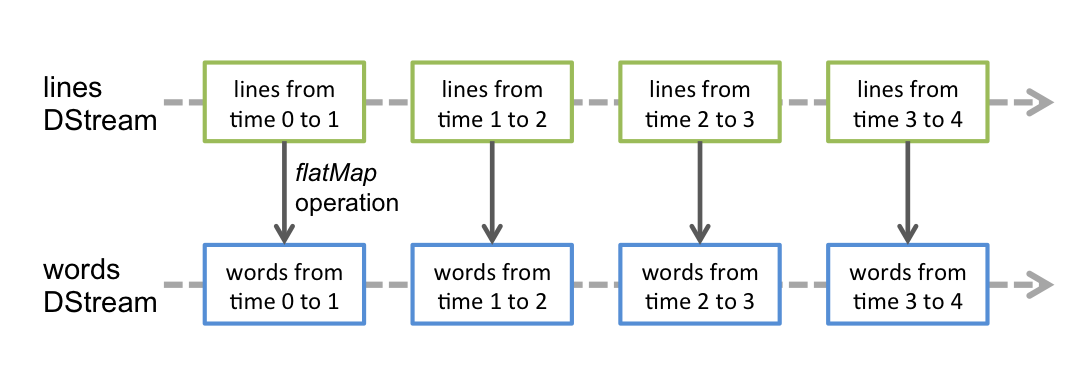
应用于DStream的任何操作都转换为底层RDD上的操作。例如,在先前将行流转换为字的示例中,flatMap操作应用于linesDStream中的每个RDD 以生成DStream的 wordsRDD。如下图所示:
1、输入DStream和Receivers
输入DStream是表示从流源接收的输入数据流的DStream,每个输入DStream都与Receiver对象相关联,该对象从源接收数据并将其存储在Spark的内存中进行处理。如果要在流应用程序中并行接收多个数据流,可以创建多个输入DStream,这将创建多个接收器,这些接收器将同时接收多个数据流。
Spark Streaming提供两类内置流来源:
- 基本来源:StreamingContext API中直接提供的源。示例:文件系统和套接字连接
- 高级资源:Kafka,Flume,Kinesis等资源可通过额外的实用程序类获得,这些需要额外的依赖关系
基本来源
除了根据通过TCP套接字连接接收的文本数据创建DStream(ssc.socketTextStream(…)),StreamingContext API还提供了从文件创建DStream作为输入源的方法。
对于从与HDFS API兼容的任何文件系统(即HDFS,S3,NFS等)上的文件读取数据:
streamingContext.fileStream<KeyClass, ValueClass, InputFormatClass>(dataDirectory);对于文本文件:
streamingContext.textFileStream(dataDirectory);2、DStreams的转换
| 转换 | 含义 |
|---|---|
| map(func) | 通过将源DStream的每个元素传递给函数func来返回一个新的DStream |
| flatMap(func) | 与map类似,但每个输入项可以映射到0个或更多输出项 |
| filter(func) | 通过仅选择func返回true 的源DStream的记录来返回新的DStream |
| repartition(numPartitions) | 通过创建更多或更少的分区来更改此DStream中的并行度级别 |
| union(otherStream) | 返回一个新的DStream,它包含源DStream和otherDStream中元素的并集 |
| count() | 通过计算源DStream的每个RDD中的元素数量,返回单元素RDD的新DStream |
| reduce(func) | 通过使用函数func聚合源DStream的每个RDD中的元素,返回单元素RDD的新DStream |
| countByValue() | 返回(K,Long)对的新DStream,每个键的值是其在源DStream的每个RDD中的频率 |
| reduceByKey(func,[ numTasks ]) | 返回(K,V)对的新DStream,其中使用给定的reduce函数聚合每个键的值 |
| join(otherStream,[ numTasks ]) | 当在(K,V)和(K,W)对的两个DStream上调用时,返回(K,(V,W))对的新DStream |
| cogroup(otherStream, [numTasks]) | 当在(K,V)和(K,W)对的DStream上调用时,返回(K,Seq [V],Seq [W])元组的新DStream。 |
| transform(func) | 通过将RDD-to-RDD函数应用于源DStream的每个RDD来返回新的DStream |
| updateStateByKey(func) | 返回一个新的“状态”DStream,其中通过在键的先前状态和键的新值上应用给定函数来更新 每个键的状态。 |
updateStateByKey
使用updateStateByKey可以在数据原先状态或者初始化状态上进行更新,而不是以每次接收到的数据为一个批次进行计算
SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("JavaStatefulNetworkWordCount");
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(1));
ssc.checkpoint(".");
JavaReceiverInputDStream<String> lines = ssc.socketTextStream("localhost", 9999,StorageLevels.MEMORY_AND_DISK_SER_2);
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(SPACE.split(x)).iterator());
JavaPairDStream<String, Integer> wordsDstream = words.mapToPair(s -> new Tuple2<>(s, 1));
//第一个参数就是key传进来的数据,第二个参数是曾经已有的数据
Function2<List<Integer>, Optional<Integer>, Optional<Integer>> updateFunction =
(values, state) -> {
Integer newSum =state.isPresent()?state.get():0;
for (Integer value : values) {
newSum += value;
}
return Optional.of(newSum);
};
JavaPairDStream<String, Integer> runningCounts = wordsDstream.updateStateByKey(updateFunction);
runningCounts.print();
//定义初始化状态
List<Tuple2<String, Integer>> tuples = Arrays.asList(new Tuple2<>("hello", 1), new Tuple2<>("world", 1));
JavaPairRDD<String, Integer> initialRDD = ssc.sparkContext().parallelizePairs(tuples);
//定义更新状态函数,可以对监听到的数据源数据和初始化状态进行计算
//参数含义分别为:原key,原value,状态值,输出元组
Function3<String, Optional<Integer>, State<Integer>, Tuple2<String, Integer>> mappingFunc = (word, one, state) -> {
int sum = one.orElse(0) + (state.exists() ? state.get() : 0);
Tuple2<String, Integer> output = new Tuple2<>(word, sum);
state.update(sum);
return output;
};
//设置更新状态函数
JavaMapWithStateDStream<String, Integer, Integer, Tuple2<String, Integer>> stateDstream =
wordsDstream.mapWithState(StateSpec.function(mappingFunc).initialState(initialRDD));
stateDstream.print();
ssc.start();
ssc.awaitTermination();
ssc.close();滑动window计算
例如,可以定义对20秒内的数据进行归约操作
JavaPairDStream<String, Integer> wordCounts1 = wordPairs.reduceByKeyAndWindow((a, b) -> a + b,Durations.seconds(20));
使用dataframe进行sql操作
package com.kexin.spark;
import java.util.Arrays;
import java.util.regex.Pattern;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.api.java.StorageLevels;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
/**
* @Author KeXin
* @Date 2018/8/30 下午1:48
**/
public class JavaSqlNetworkWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("JavaSqlNetworkWordCount");
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(1));
JavaReceiverInputDStream<String> lines = ssc.socketTextStream("localhost", 9999, StorageLevels.MEMORY_AND_DISK_SER);
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(SPACE.split(x)).iterator());
// Convert RDDs of the words DStream to DataFrame and run SQL query
words.foreachRDD((rdd, time) -> {
SparkSession spark = JavaSparkSessionSingleton.getInstance(rdd.context().getConf());
// Convert JavaRDD[String] to JavaRDD[bean class] to DataFrame
JavaRDD<JavaRecord> rowRDD = rdd.map(word -> {
JavaRecord record = new JavaRecord();
record.setWord(word);
return record;
});
Dataset<Row> wordsDataFrame = spark.createDataFrame(rowRDD, JavaRecord.class);
// Creates a temporary view using the DataFrame
wordsDataFrame.createOrReplaceTempView("words");
// Do word count on table using SQL and print it
Dataset<Row> wordCountsDataFrame = spark.sql("select word, count(*) as total from words group by word");
System.out.println("========= " + time + "=========");
wordCountsDataFrame.show();
});
ssc.start();
ssc.awaitTermination();
}
}
/**
* Lazily instantiated singleton instance of SparkSession
*/
class JavaSparkSessionSingleton {
private static transient SparkSession instance = null;
public static SparkSession getInstance(SparkConf sparkConf) {
if (instance == null) {
instance = SparkSession.builder().config(sparkConf).getOrCreate();
}
return instance;
}
}
class JavaRecord implements java.io.Serializable {
private String word;
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
}
缓存/持久性
与RDD类似,DStreams还允许开发人员将流的数据保存在内存中。也就是说,persist()在DStream上使用该方法将自动将该DStream的每个RDD保留在内存中。如果DStream中的数据将被多次计算(例如,对相同数据进行多次操作),这将非常有用。对于像reduceByWindow和这样的基于窗口的操作和reduceByKeyAndWindow基于状态的操作updateStateByKey,这是隐含的。因此,基于窗口的操作生成的DStream会自动保留在内存中,而无需开发人员调用persist()。
















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











