







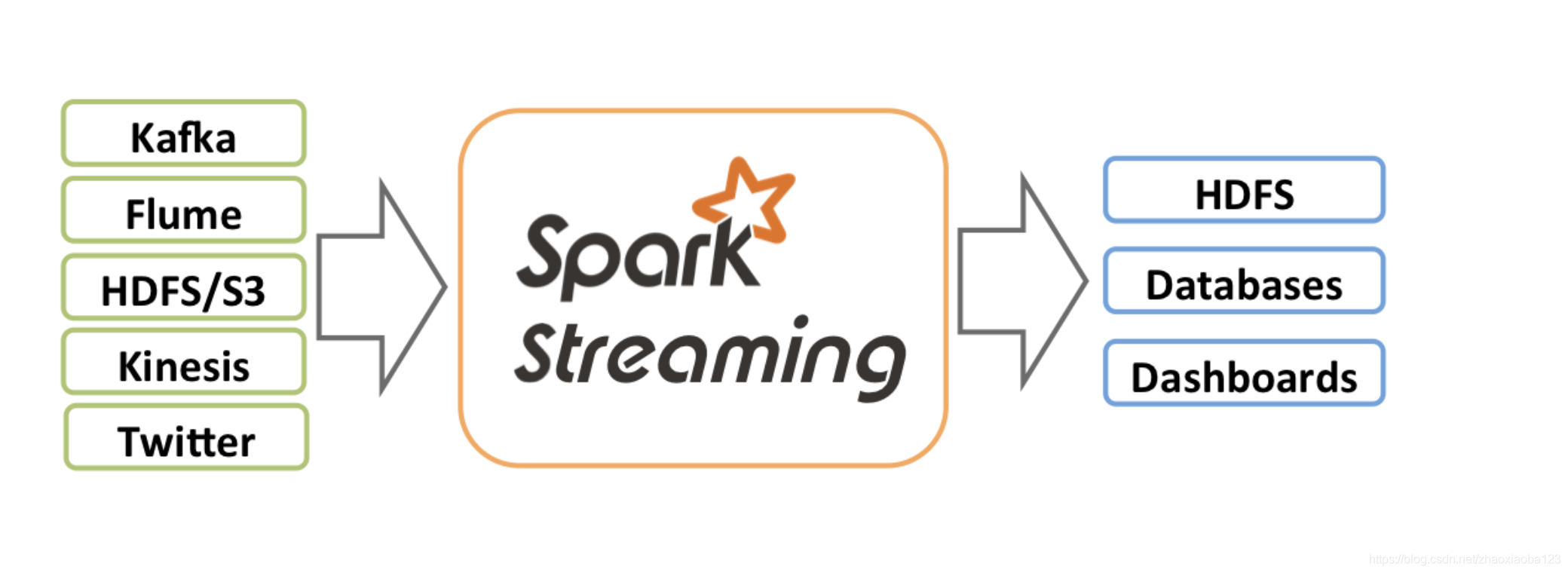
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data stre
Spark流是核心Spark API的扩展,它支持对实时数据流进行可伸缩、高吞吐量、容错的流处理。数据可以从许多源(如Kafka、Flume、kinisis或TCP sockets)摄取,并且可以使用复杂的算法(用高级函数(如map、reduce、join和window)进行处理。最后,处理后的数据可以推送到文件系统、数据库和实时仪表板。实
际上,您可以在数据链上应用Spark的机器学习和图形处理算法
实施流处理框架对比
storm:真正的实时流处理 真正的流处理框架 Java开发
spark streaming:并不是真正的实时流处理,而是一个mini batch操作 (他是一个把流数据拆分成一个一个批次 每间隔几秒执行一次)scala java python 都可开发 使用spark一站式解决问题
flink:底层是流处理,可以用批处理进行交互
kafka stream:
Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.
在内部,它的工作原理如下。Spark Streaming接收实时输入的数据流,并将数据分成若干批,然后由Spark引擎对这些数据进行处理,以成批生成最终的结果流。
Spark Streaming provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data. DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs.
This guide shows you how to start writing Spark Streaming programs with DStreams. You can write Spark Streaming programs in Scala, Java or Python (introduced in Spark 1.2), all of which are presented in this guide. You will find tabs throughout this guide that let you choose between code snippets of different languages.
Note: There are a few APIs that are either different or not available in Python. Throughout this guide, you will find the tag Python API highlighting these differences.
Spark流提供了一个高级抽象,称为离散流或DStream,它表示一个连续的数据流。数据流可以从卡夫卡、Flume和Kinesis等源的输入数据流创建,也可以通过对其他数据流应用高级操作来创建。在内部,一个数据流被表示为一个rdd序列。

本指南向您展示如何开始使用数据流编写Spark流式程序。您可以用Scala、Java或Python(在Spark 1.2中引入)编写Spark流程序,所有这些都将在本指南中介绍。您将在本指南中找到一些选项卡,这些选项卡允许您在不同语言的代码段之间进行选择。
注意:有一些api在Python中要么不同,要么不可用。在本指南中,您将发现Python API标记突出显示了这些差异。
从词频统计案例来了解SparkStreating
The complete code can be found in the Spark Streaming example NetworkWordCount.
If you have already downloaded and built Spark, you can run this example as follows. You will first need to run Netcat (a small utility found in most Unix-like systems) as a data server by using
完整的代码可以在Spark流示例NetworkWordCount中找到。
如果您已经下载并构建了Spark,那么可以如下运行这个示例。首先需要使用
1、启动SparkStreating 端口: nc -lk 9999
Then, in a different terminal, you can start the example by using
Then, any lines typed in the terminal running the netcat server will be counted and printed on screen every second. It will look something like the following.
然后,在另一个终端中,可以使用
然后,在运行netcat服务器的终端中键入的任何行将被计数并每秒打印在屏幕上。它看起来像下面这样。
2、启动SparkStreating:./bin/spark-submit examples/src/main/python/streaming/network_wordcount.py localhost 9999
A Quick Example
Before we go into the details of how to write your own Spark Streaming program, let’s take a quick look at what a simple Spark Streaming program looks like. Let’s say we want to count the number of words in text data received from a data server listening on a TCP socket. All you need to do is as follows.
一个简单的例子
在我们详细介绍如何编写自己的Spark流媒体程序之前,让我们先快速了解一下简单的Spark流媒体程序是什么样子的。假设我们要计算从数据服务器接收到的文本数据中的单词数,该数据服务器监听TCP套接字。你所需要做的就是如下。
First, we import StreamingContext, which is the main entry point for all streaming functionality. We create a local StreamingContext with two execution threads, and batch interval of 1 second.
首先,我们导入StreamingContext,它是所有流功能的主要入口点。我们用两个执行线程创建一个本地StreamingContext,批处理间隔为1秒。
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
Create a local StreamingContext with two working thread and batch interval of 1 second
sc = SparkContext(“local[2]”, “NetworkWordCount”)
ssc = StreamingContext(sc, 1)
Using this context, we can create a DStream that represents streaming data from a TCP source, specified as hostname (e.g. localhost) and port (e.g. 9999).
使用此上下文,我们可以创建一个表示来自TCP源的流数据的数据流,指定为主机名(例如localhost)和端口(例如9999)。
Create a DStream that will connect to hostname:port, like localhost:9999
lines = ssc.socketTextStream(“localhost”, 9999)
This lines DStream represents the stream of data that will be received from the data server. Each record in this DStream is a line of text. Next, we want to split the lines by space into words.
这行DStream表示将从数据服务器接收的数据流。此数据流中的每个记录都是一行文本。接下来,我们要按空格将这些行拆分成单词。
Split each line into words
words = lines.flatMap(lambda line: line.split(" "))
flatMap is a one-to-many DStream operation that creates a new DStream by generating multiple new records from each record in the source DStream. In this case, each line will be split into multiple words and the stream of words is represented as the words DStream. Next, we want to count these words.
flatMap是一个一对多的DStream操作,它通过从源DStream中的每个记录生成多个新记录来创建新的DStream。在这种情况下,每一行将被分割成多个单词,并且单词流被表示为单词DStream。接下来,我们要数这些单词。
Count each word in each batch
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.pprint()
The words DStream is further mapped (one-to-one transformation) to a DStream of (word, 1) pairs, which is then reduced to get the frequency of words in each batch of data. Finally, wordCounts.pprint() will print a few of the counts generated every second.
Note that when these lines are executed, Spark Streaming only sets up the computation it will perform when it is started, and no real processing has started yet. To start the processing after all the transformations have been setup, we finally call
将单词DStream进一步映射(一对一转换)到(word,1)对的DStream,然后将其缩小以获得每批数据中单词的频率。最后,wordCounts.pprint()将每秒打印一些生成的计数。
请注意,当执行这些行时,Spark Streaming只设置它在启动时将执行的计算,而尚未启动真正的处理。为了在所有转换都设置好之后开始处理,我们最后调用
ssc.start() # Start the computation
ssc.awaitTermination() # Wait for the computation to terminate
#!/usr/bin/python
-- coding:utf-8 --
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if name == ‘main’:
if len(sys.argv) != 3:
print("Usage: spark0901.py ", file=sys.stderr)
sys.exit(-1)
#可以从SparkContext对象创建StreamingContext对象。
sc = SparkContext(appName="spark0901")
ssc = StreamingContext(sc, 5)
#业务主体开发自己的业务开始
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
counts = lines.flatMap(lambda line:line.split(" "))\
.map(lambda word:(word,1))\
.reduceByKey(lambda a,b:a+b)
counts.pprint()
#业务主体开发自己的业结束
ssc.start()
ssc.awaitTermination()















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









