







学好并发编程不一定需要了解的MESI和内存屏障
一个从腾讯毕业的孩子,将自己的文章搬运出来
开篇
并发编程一直围绕着3个要素展开,分别是原子性、有序性、可见性。
对于使用者来说,可以通过学习使用一些并发工具类来保证三要素。
例如Java:
synchronize保证了原子性、可见性。(如果撇开DCL问题的话,所有变量都在同步代码块内处理的话,甚至也可以说保证了不同同步代码块之间的有序性)
ReentrantLock等保证原子性、可见性、有序性
volatile保证了可见性、有序性
又例如Golang:
sync.Mutex sync.RWMutex 保证了原子性、可见性
channel技术可以用于保证可见性、有序性
那么本篇文章,主要围绕的是可见性和有序性。语言给定了规则,我们只要遵守相应的规则,使用相应的工具类开发,就能保证并发安全。那么它的底层究竟是怎么工作的,今天的文章希望能给大家带来帮助,同时因为偏底层,如果有错误的地方,欢迎指正~
在进入主题之前,首先我们来看两段经典的伪代码
// cpu0和cpu1方法分别模拟2个CPU正在并行
public class Demo {
int value = 0;
boolean done = false;
void cpu0() {
value = 10;
done = true;
}
void cpu1() {
while (!done) {
}
System.out.println(value == 10);
}
}
package main
var value = 0
var done = false
func setup() {
value = 10
done = true
}
func main() {
go setup()
for !done {
}
println(value == 10)
}
看完上述的代码,它的输出结果是什么吗?以及为什么?
答案是不确定,要分很多种情况讨论。
第一段Java代码中,造成输出结果不确定的原因有
- while (!done) 这段代码很危险,如果done没有用volatile修饰,那么极大可能会出现,编译器将它优化为 while (1) 或者每次都直接从寄存器里取值,就导致原本我们希望通过变量done来控制循环结束,但编译器把它变成一个死循环。而这段代码我在生活中也实验过,如果while (!done) 循环体里面没有任何代码,就极大可能出现死循环。而如果任意插入一段代码,就能破除这个问题。(具体原理还没深究)
- cpu0 中的数据不存在依赖性,因此允许重排序。因此done=true时,并不能保证value=10 已经执行
- 尽管在cpu0 中没有进行重排序,但是由于不存在happends-before的保证,因此cpu0 和 cpu1不存在可见性的保证
第二段go代码中,造成输出结构不确定的原因有
- for !done 同样有可能会被编译器优化成死循环
- setup里面value同样不能保证在done前执行
- setup里面的value即是在done前执行,也不能保证对主routine可见
那么有什么方式能够保证最终输出结果为true呢?它的底层原理是什么?
那么接下来,我们带着这些疑问,一起走进今天的主题来一探究竟。
一、不同CPU设计的区别
单核CPU

只有一个CPU,读写都直接操作主存。
优点:
设计简单、实现简单
不存在数据一致性问题
缺点
缺点:
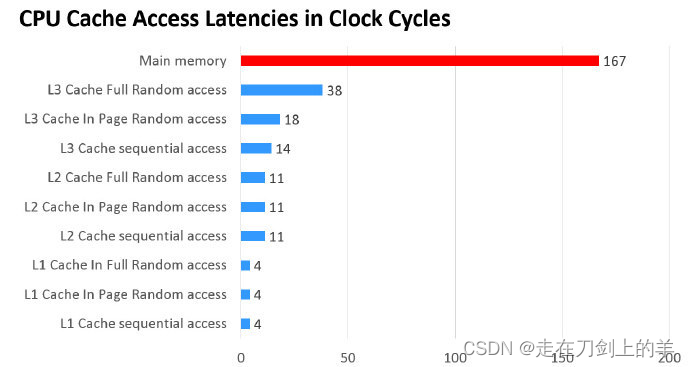
cpu和内存的IO性能差了100倍(cpu是1ns级,而内存是100ns级),频繁的与主存交互数据会影响cpu的性能
单核+高速缓存
为了演示方便,多级高速缓存统一抽象为一级Cache
为了解决单核时代,cpu和内存间读写速度差距过大的问题,在两者之间引入了多级高速缓存

工作方式
cpu从主存中读取数据时,会将数据写入一份数据副本到高速缓存中(在高速缓存中以缓存行的形式保存,一个缓存行是64字节,读取一个数据如果小于64直接,则会把数据附近连续的内存数据一起保存下来以填充满一个缓存行。因此这里衍生出一个知识点,伪共享问题,本篇内容不对伪共享展开讨论)
之后cpu如果重复读写这个数据,就不需要再访问主存,而是直接访问高速缓存中对应的缓存行上的数据。这样就能频繁避免读写内存所带来的开销(CPU和高速缓存间的速度差距比CPU和主存之间小的多得多)
优点:提升了cpu读写数据的速度
缺点:单核CPU瓶颈明显。一台机器的性能取决于cpu在一个时钟周期内可执行的单元数量。
cpu、高速缓存、memory的速度差异
多核CPU + 高速缓存
为了解决上一个时代,单核cpu的性能瓶颈。超频并不是一个很好的解决方案,因为超频不仅会带来硬件寿命的急剧下降,发热问题也会导致cpu性能下降。并且一味的通过超频来提升cpu性能,它的研发成本和收益并不可观。因此,增加核心数是当下更好的方式。
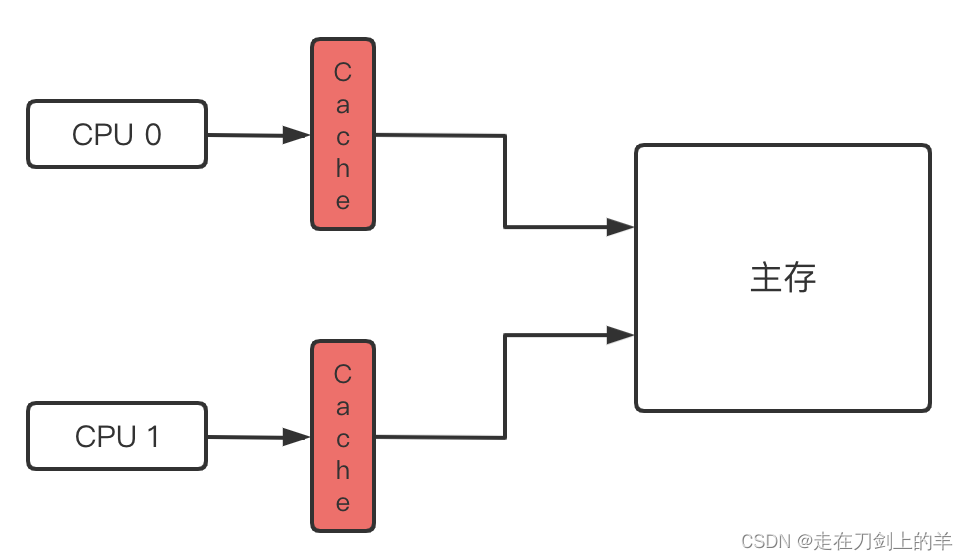
由于增加了核心数,每个核心又拥有它自己的高速缓存。因此对于同一份主存数据,出现了数据不一致性的问题。
为了解决数据一致性问题,第一阶段采用的是总线锁的问题。总线是cpu连接内存的桥梁,多个cpu和内存之间的交互可以被总线进行管理。因此可以通过在总线上加锁的方式,来控制同一时间内,只有一个CPU能访问内存数据。
#Lock 信号会把总线上的并行化操作变成了串行,使得某个处理器能够独占内存。因此这是一个锁粒度和开销都很大的操作
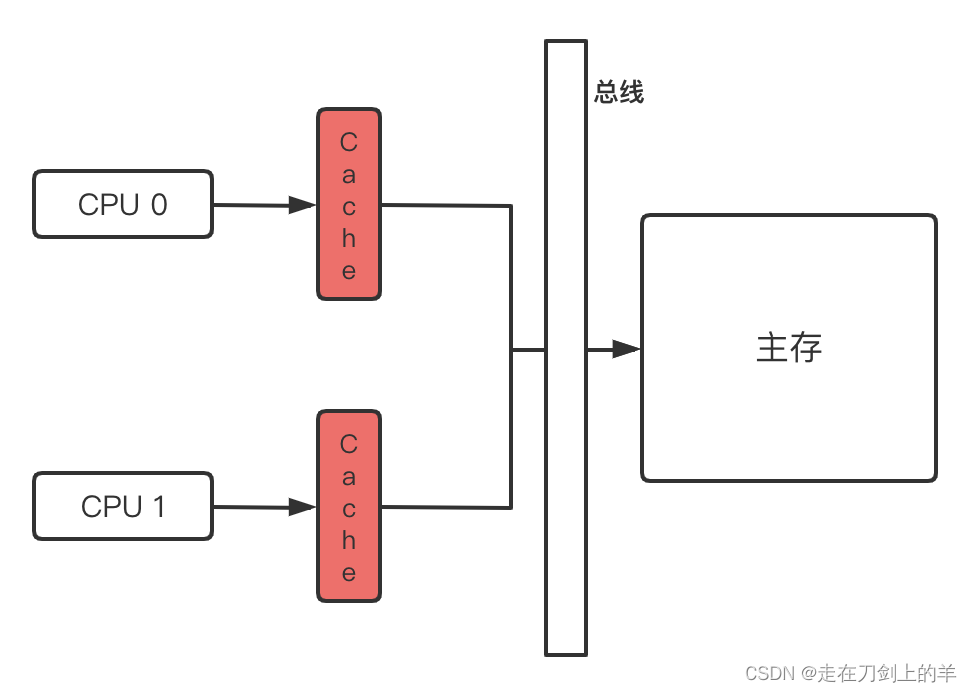
优点:多核CPU并行工作提升了计算机的处理速度
缺点:
- 带来了缓存一致性问题
- 总线锁的方式开销太大
二、缓存一致性协议(MESI)
由于通过总线锁的方式来保证一致性所带来的性能开销太大,因为MESI协议的目的就是以一种更优的方式来管理数据一致性,同时保证CPU的高性能。它的思想是通过降低锁的粒度以及减少使用总线锁的频率来提高并行度从而达到性能优化。

缓存行的状态
它将高速缓存中每个缓存行(Cache Line)赋予了一个状态属性,分别是
- Modified
- Exclusive
- Shared
- Invalid
Exclusive
- 本地缓存独占
- 缓存行有效
- 与 主存 数据一致
当某个数据,只有一个CPU需要使用这个数据时。并且它从主存读到缓存行后,没有进行任何修改操作。那么此时,这份数据的状态就是Exclusive
Modified
- 本地缓存独占
- 缓存行有效
- 缓存行 和 主存 的数据不一致
当某个数据,只有一个CPU需要使用这个数据时。那么这个CPU对当前数据的读写,就不需要马上同步到主存中(因为没有其他CPU需要,不存在数据一致性问题)。cpu直接与cache进行交互,不需要和主存进行交互,从而提升了读写速度
Shared
- 多个CPU缓存共享
- 缓存行有效
- 与 主存 数据一致
当某个数据存在于多个CPU的缓存行时。数据没有被任意一个CPU修改,因此每一个CPU缓存中所维护的数据副本,都与主存完全一致,数据是有效的
Invalid
- 多个CPU缓存共享
- 缓存行无效(既当前数据和主存的不一致,不能直接读缓存行,否则会读到脏数据)
- 与 主存 数据不一致
当某个数据存在于多个CPU的缓存行时。其他CPU对数据进行了修改,从而使得当前CPU维护的数据副本失效。位于Invalid状态的数据,CPU在进行读操作时,需要从主存中读取最新的有效数据
事件
而引起缓存行状态的变化,由以下4类事件触发:
本地写
本地处理器进行数据写入
本地读
本地处理器进行数据读取
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1992
1992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









