







 文章介绍了ODISE,一个结合预训练的文本-图像扩散模型和判别模型的开放词汇全景分割方法。该模型在仅使用COCO训练的情况下,在ADE20K数据集上取得了23.4PQ和30.0mIoU的成果,优于现有方法。ODISE通过利用扩散模型的语义理解和判别模型的分类能力,解决了开放词汇认知的挑战。
文章介绍了ODISE,一个结合预训练的文本-图像扩散模型和判别模型的开放词汇全景分割方法。该模型在仅使用COCO训练的情况下,在ADE20K数据集上取得了23.4PQ和30.0mIoU的成果,优于现有方法。ODISE通过利用扩散模型的语义理解和判别模型的分类能力,解决了开放词汇认知的挑战。
本文作者提出了基于扩散模型的开放词汇全景分割ODISE,该模型将预训练的文本-图像扩散模型与判别模型统一起来,用于开放词汇全景分割任务。仅使用COCO训练就能在ADE20K数据集上达到23.4 PQ和30.0 mIoU。 搬来大佬的 勿怪呀 ~ UCSD与NVIDIA提出全景分割
论文地址:https://arxiv.org/abs/2303.04803
在这篇文章中,作者提出了ODISE:基于扩散模型的开放词汇全景分割(Open-vocabulary DIffusion-based panoptic SEgmentation),该模型将预训练的文本-图像扩散模型与判别模型统一起来,用于开放词汇全景分割任务。作者认为:文本-图像扩散模型具有出色的能力,可以根据各种开放词汇语言描述生成高质量图像。这表明它们内部的表征空间与现实世界中的开放概念高度相关。另一方面,像CLIP这样的文本-图像判别模型擅长将图像分类为开放词汇标签。因此作者利用冻结的扩散模型与判别模型来实现开放类别的全景分割。ODISE在开放词汇全景分割和语义分割任务上的表现优于以前的最先进方法。值得注意的是,该模型仅使用COCO训练就能在ADE20K数据集上达到23.4 PQ和30.0 mIoU,相对于以前的最先进方法,PQ和mIoU分别提高了8.3和7.9。
Introduction
人类可以看到世界并识别出无限的类别。例如在上图中,除了将每辆车辆都识别为“卡车”之外,我们也可以立即理解其中一辆卡车需要挂接拖车才能移动另一辆卡车。为了研究这种细粒度和近似无限理解能力的智能,开放词汇认知问题最近在计算机视觉领域引起了很大关注。然而,只有少数工作能够提供一个统一的框架,同时解析所有对象实例和场景语义,也即全景分割。ODISE是首个结合扩散模型与判别模型的全景分割方法。至于为什么要结合这两个模型,作者给出了以下观点:
首先,目前大多数开放词汇认知方法都应用了在大规模数据上训练的文本-图像判别模型(例如CLIP)。多个研究也证明了这样的模型在开放词汇任务中的潜力。然而,作者认为虽然这样的预训练模型擅长分类单独图像,但它们不一定是场景级别,或者像素级别结构理解的最佳选择。事实上,研究已经表明CLIP经常混淆对象之间的空间关系(参考Reclip)。在本文中作者也同样假设文本-图像判别模型中缺乏空间和关系理解是开放词汇全景分割的瓶颈。
基于这样的思考,作者尝试引入扩散模型。最近诞生的许多扩散模型提供了前所未有的图像质量、泛化能力、以及语义控制能力。为了将生成的图像限制在提供的文本上,扩散模型在文本的Embeddings和它们的视觉表示之间计算交叉注意力。这种设计意味着扩散模型潜在的特征可能与语言描述的高级语义概念有良好的区分和相关性。同时,由于需要生成正确的图片,扩散模型对于图片的空间信息也会有更好的理解。
基于以上的思考,作者提出了ODISE:基于扩散的开放词汇全景分割(Open-vocabulary DIffusion-based panoptic SEgmentation),该模型利用大规模文本-图像扩散和判别模型来完成全景分割。该方法概述如下图所示。
它包含一个预训练的冻结的文本-图像扩散模型,模型接受一个图像及其标题作为输入,并提取其扩散模型的内部特征。模型使用这些特征作为输入,其中的掩模生成器生成图像中所有可能对象的掩膜。作者使用训练集中带注释的掩模来训练掩模生成器。而掩膜分类器通过将每个预测掩模的Diffusion特征与几个对象类别名称的文本Embeddings相关联,将每个掩模分类为许多开放词汇类别之一。作者使用训练数据集中的掩模类别标签或图像级标题来训练分类模块。训练完成后,用文本-图像扩散和判别模型执行开放词汇全景推理以对预测掩模进行分类。实验证明,作者的方法大幅超过了现有的baseline方法。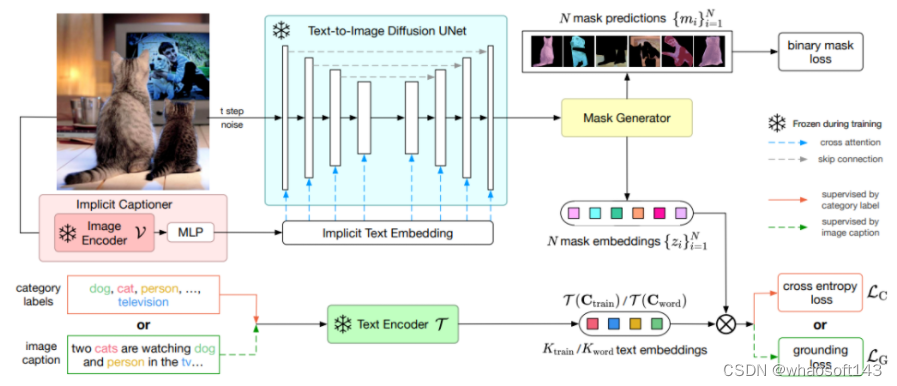 总的来说,作者的贡献如下:
总的来说,作者的贡献如下:
-
首次提出了将扩散模型用于开放词汇分割任务的方法。
-
提出了一种新的流程,有效利用文本-图像扩散模型和判别模型执行开放词汇全景分割。
-
作者的方法在许多开放词汇识别任务上超越了所有现有的baseline方法,从而达到了新的SOTA。
Method
1. 问题定义 2. 扩散模型的引入
2. 扩散模型的引入
目前的扩散模型通常使用UNet架构来学习去噪过程。UNet由卷积块、上采样和下采样块、跳跃连接和注意力块组成,它们在文本Embeddings和UNet特征之间执行进行交叉注意力计算。在去噪过程中,扩散模型使用文本输入来推断噪声输入图像的去噪方向。文本是通过交叉注意力层注入到模型中的,作者这样的设计是为了让视觉特征与丰富的语义描述相关联。因此,UNet块输出的特征图可以为全景分割提供丰富而密集的特征。 whaosoft aiot http://143ai.com  3. 掩膜生成器
3. 掩膜生成器 4. 掩膜分类器
4. 掩膜分类器 5. 前向过程
5. 前向过程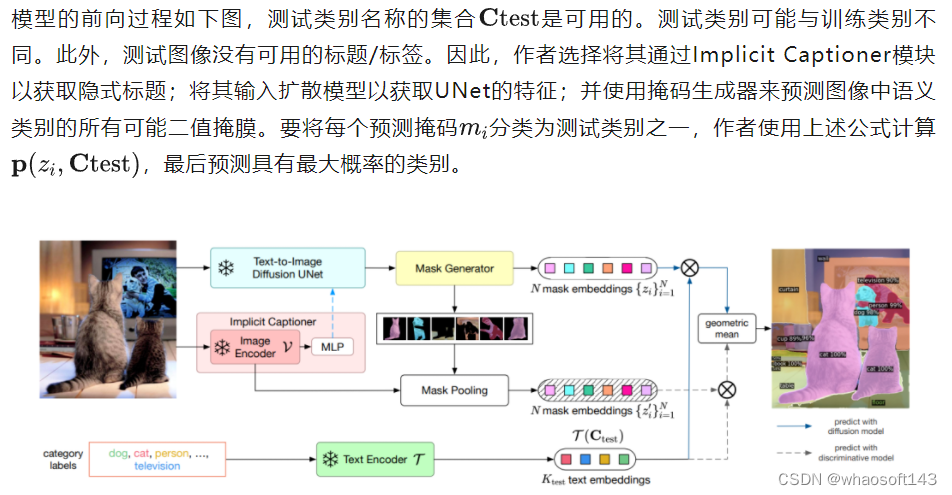

讨论
本文的出发点很有意思,目前常见的开放式语义分割都使用多模态大模型处理未见类,而CLIP,ALIGH这类模型,训练时都是以图片为单位的,很可能缺少分割任务所需的空间信息。在这里,作者给出的解决方案是:通过引入扩散模型来弥补多模态大模型的缺陷。因此就有了这样的工作:同时使用Diffusion和CLIP全景分割模型。具体来说,作者的工作可以总结为以下几点。
-
第一次利用大规模文本-图像扩散模型来完成分割任务
-
在全景分割任务中超越以往的模型,实现了新的SOTA
-
该架构的成功证明了扩散模型不仅仅能用于做生成,同时也能学习到良好的语义表示,对图片的空间信息把握更到位。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









