







 Meta推出MobileLLM系列,一种专为移动设备设计的小型语言模型,具有SOTA性能,尤其在零样本任务中优于125M/350M模型。研究关注模型架构优化,包括深度和宽度、嵌入共享与分组查询注意力,以及Block级别的权重共享,以降低能耗和部署成本。
Meta推出MobileLLM系列,一种专为移动设备设计的小型语言模型,具有SOTA性能,尤其在零样本任务中优于125M/350M模型。研究关注模型架构优化,包括深度和宽度、嵌入共享与分组查询注意力,以及Block级别的权重共享,以降低能耗和部署成本。
Meta 推出 MobileLLM 系列,一款适用于移动设备上的「小」模型。
一个新的模型家族:MobileLLM,SOTA 性能,在一系列 zero-shot 任务中,比之前的 SOTA 125M/350M 模型高出 2.7%/4.3%。
「在移动设备上运行 LLM?可能需要 Meta 的一些技巧。」刚刚,图灵奖得主 Yann LeCun 在个人社交平台表示。
他所宣传的这项研究来自 Meta 最新论文《 MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases 》,在众多作者中也有我们熟悉的来自 Meta FAIR 田渊栋。
田渊栋表示:「我们的 MobileLLM 预训练模型(125M/350M),性能达到 SoTA,特别是在聊天 / API 调用方面表现出色。此外,本工作中的一个有趣研究是跨 Transformer 层的权重共享,这样不仅节省了参数,还减少了推理过程中的延迟。」
论文地址:https://arxiv.org/pdf/2402.14905.pdf
现阶段大语言模型(LLM)已经渗透到人类生活的各个方面,尤其是以 ChatGPT 等为代表的模型,这类研究主要在云环境中运行。
然而领先的模型如 ChatGPT4 的参数量已经超过了 1 万亿。我们设想这样一个场景,这个场景广泛依赖 LLM,不仅用于前端的会话界面,也用于后端操作,如推荐系统,覆盖人类约 5% 的时间。在这一假设场景中,假如以 GPT-4 每秒处理 50 个 token 的速率来计算,则需要部署大约一亿个 H100 GPU,每个 GPU 的计算能力为 60 TFLOPs/s。这种计算规模,还不包括通信和数据传输的开销,就已经与 160 个 Meta 规模的公司相当。随之而来的能源消耗和二氧化碳排放将带来巨大的环境挑战。
本文着眼于大语言模型的延时和开发云成本不断增长的问题,希望探索轻量化且高质量的大语言模型,这里着重强调的是参数量小于 1B 的模型,这种配置也是移动部署中实用的选择。
与强调大模型数据质量和参数量的很多工作普遍强调的点不同,本文的研究着力于模型架构对 1B 参数量级别的 LLM 的重要性。本文提出的模型称为 MobileLLM,它的架构是 Deep and thin 的,且结合了词嵌入的共享和分组查询注意机制,比之前的 125M/350M 最先进的模型获得了显著的 2.7%/4.3% 的准确率提升。
本文最终得到的是一个新的模型家族:MobileLLM,SOTA 性能,在一系列 zero-shot 任务中,比之前的 SOTA 125M/350M 模型高出 2.7%/4.3%。
此外,本文还提出了一种直接的 Block 级别的权重共享方法,不增加模型大小,且延迟开销小幅增加。用这种方法训练的模型 MobileLLM-LS,精度比 MobileLLM 125M/350M 进一步提高了 0.7%/0.8%。此外,MobileLLM 模型家族的性能也有显著的改进,而且在 API 调用任务中的精度也与 LLAMA-v2 7B 很接近,这就证明了小模型对于端侧设备的能力。
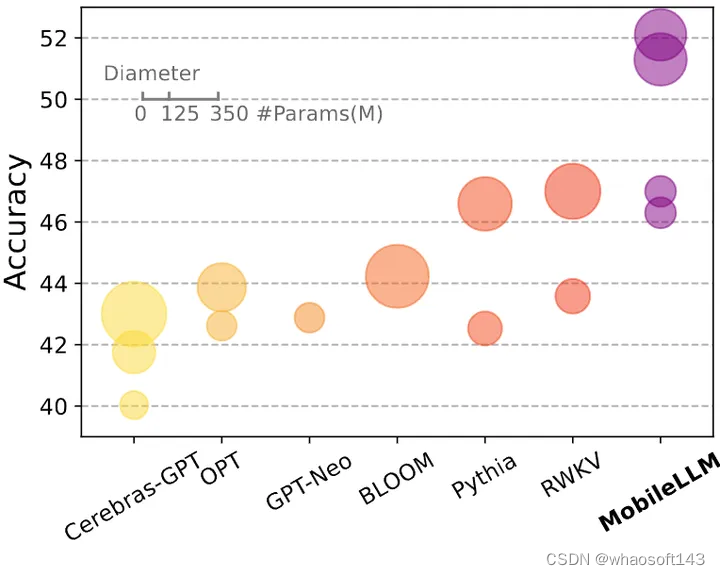
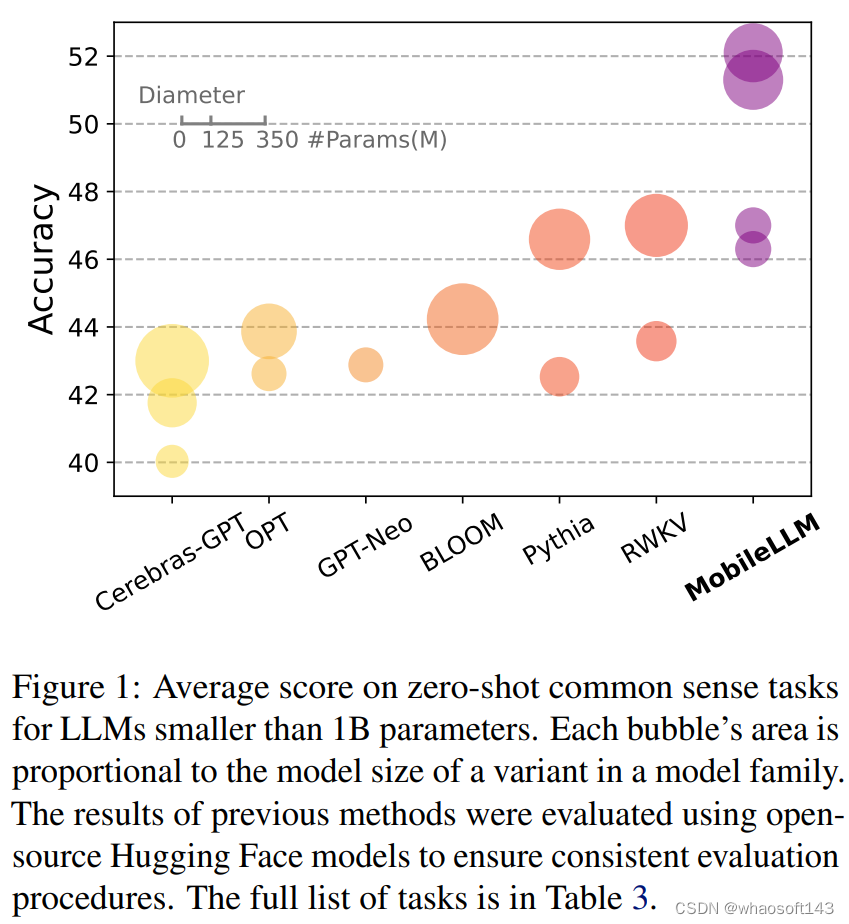
图1:MobileLLM 精度与其他模型对比
具体结论
1) 网络架构:
-
与 Scaling Law[1]相反,本文证明了深度比宽度对于小的 LLM 更加重要。一个 deep-and-thin 的模型结构擅长捕捉抽象概念,从而获得更好的最终性能。
-
重新思考了 OPT[2]中提出的 Embedding sharing 方法,并将 Grouped Query Attention[3]实现在小的 LLM 中。
2) 推理策略:
-
本文提出 Block-wise 的权重共享,用于内存移动成为延时瓶颈的情形。两个相邻 Block 之间的权重共享避免了移动权重这样的费时操作,只需要计算同一个 block 两次就可以,这样一来就可以降低延迟的开销。
MobileLLM:优化 1B 参数之下的语言模型
论文名称:MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
论文地址:http://arxiv.org/pdf/2402.14905.pdf
缩小语言模型的规模势在必行
大语言模型 (LLM) 已经渗透到人类生活的各个方面,不仅影响人们交流和工作的方式,还影响日常娱乐体验。领先的 LLM 产品,如 ChatGPT 和 Perplexity AI,主要在云环境中运行。ChatGPT4 等领先模型超过1万亿个参数,那么我们可以设想这样的一个未来的场景:人类在前端对话界面以及后端推荐系统中广泛地依赖于 LLM,它们甚至占据了人们每天时间的约 5%。在这个假设的场景中,以 50 tokens/s 的处理速度使用 GPT-4 需要部署大约 100 万个 算力为 60 TFLOPs/s 的 H100 GPU。这样的计算规模,不包括通信和数据传输开销,就已经与足足160 个 Meta 相当了。随之而来的能源消耗和二氧化碳排放将带来惊人的环境挑战。
因此,最好的解决方案是缩小 LLM 的规模。
此外,在当前的移动技术领域,由于主内存(DRAM)容量的限制,将像 LLaMAv2 7B 这样的 LLM 与 8 位权重整合起来代价过高。移动设备中普遍的内存层结构如图 2 所示。随着 DRAM 容量从 iPhone 15 的 6GB 到 Google Pixel 8 Pro 的 12GB 不等,一个移动应用不应超过 DRAM 的 10%,因为 DRAM 需要与操作系统和其他应用程序共享。这一要求促进了部署小于十亿参数 LLM 更进一步的研究。
而且,对可移植性和计算成本的考虑也推动了在智能手机和移动设备上部署 LLM 的必要性。在现代的移动设备技术中,由于 DRAM 容量的限制,将 LLaMA V2 7B[4]等具有8位权重的 LLM 集成到移动设备中是非常昂贵的。下图2展示了移动设备中流行的内存层次结构。iPhone 15 的 DRAM 容量约 6GB,而 Google Pixel 8 Pro 的约为 12GB。而且,原则是移动应用程序所占的空间不应超过 DRAM 的 10%[5],因为 DRAM 还要放操作系统和其他应用程序。而且 LLM 的能耗也是一个很大的问题:7B 参数的 LLM 的能耗为 0.7 J/token。一个充满电的 iPhone 手机大约有 50kJ 的能量,可以以 10 tokens/s 的速度在对话中使用这个模型 2h,每次生产 64 个 tokens 就会耗掉 0.2% 的电池电量。
这些问题其实都可以归结为我们需要更加紧凑的 LLM 模型来在手机设备上面运行。比如一个参数量为 350M 的 8-bit 模型,仅消耗 0.035 J/token,那么 iPhone 就可以支持其使用一整天。而且,解码速度可以显着增强:比如一个 125M 的模型的解码速度可以达到 50 tokens/s。而最先进的 iPhone App MLC Chat 使用的是 LLaMA 7B 模型,解码速度仅为 3∼6 tokens/s。鉴于这些考虑,本文的动机是设计参数低于 1B 的 LLM 模型。
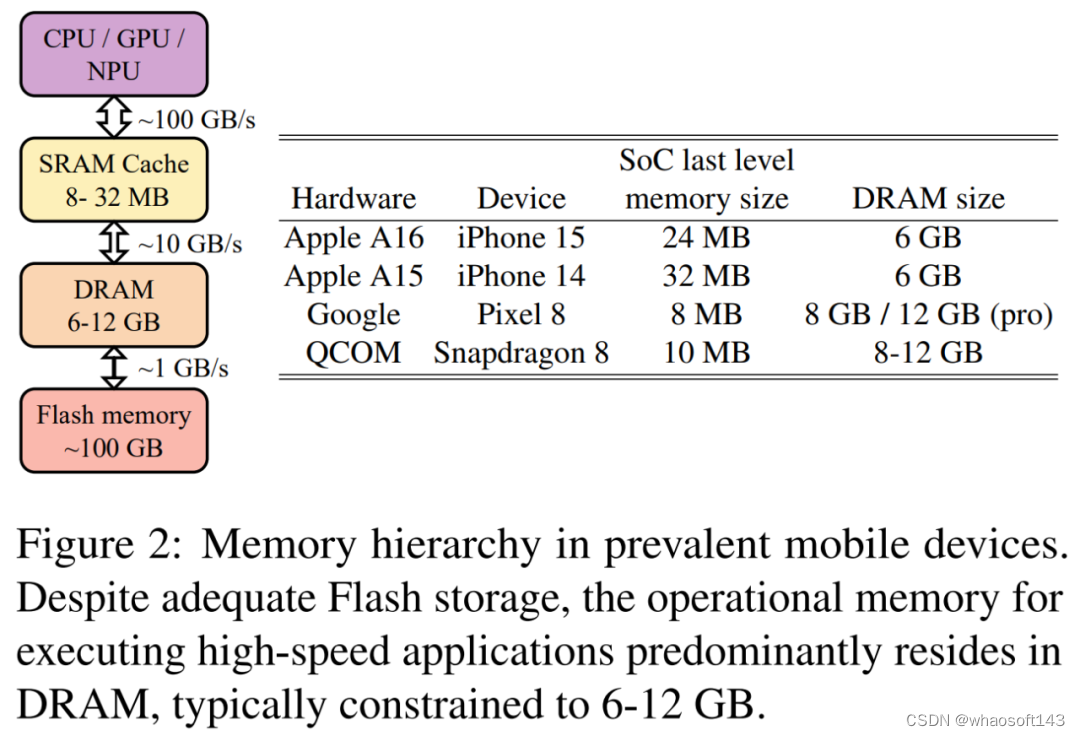
图2:流行的移动设备中的内存层次结构。尽管有足够的 Flash 存储,但是执行高速应用程序主要依赖于 DRAM,通常限制为 6-12GB 大小
基于上述考量,来自 Meta 的研究者专注于设计参数少于十亿的高质量 LLM,这是在移动端部署 LLM 比较好的解决方案。
与强调数据和参数数量在决定模型质量方面的关键作用的普遍观点相反,Meta 强调了模型架构对少于十亿(sub-billion)规模 LLM 的重要性。
基于深而窄的架构,加上嵌入共享和分组查询注意力机制,Meta 建立了一个强大的基线网络,称为 MobileLLM,与之前的 125M/350M 最先进模型相比,其准确率显著提高了 2.7%/4.3% 。这也说明了与缩放定律(scaling law)相反,该研究证明对于小型 LLM 来说深度比宽度更重要,一个深而窄的模型结构在捕获抽象概念方面更为出色。
此外,Meta 还提出了一种及时逐块权重共享( immediate block-wise weight sharing)方法,该方法不会增加模型大小,所得模型表示为 MobileLLM-LS,其准确率比 MobileLLM 125M/350M 进一步提高了 0.7%/0.8%。此外,在下游任务中,例如 Chat 和 API 调用,MobileLLM 模型家族显著优于同等规模的模型。在 API 调用任务中,与规模较大的 LLaMA-v2 7B 相比,MobileLLM 甚至实现了相媲美的分数。
看到这项研究后,网友纷纷表示「我们应该向 Meta 致敬,很高兴看到这个领域的活跃玩家。该机构通过使用低于 10 亿参数的模型,并且 350M 8 位模型的能源消耗仅为 0.035 J/token ,要是部署在 iPhone 上的话,可以支持用户一整天的会话使用。」优化 1B 参数之下的语言模型的路线图
下面开始介绍从参数量为 1B 以下的 Baseline 的 LLM 到最终模型的整个过程,如图3所示。作者尝试了 125M 和 300M 这两种尺寸的模型,对于一些模型大小是主要限制条件的设备而言,如何高效分配模型的参数非常关键。本文探索的结论可以概括为:
-
采用 SwiGLU FFN。
-
采用 Deep-and-thin 的架构。
-
采用 OPT[2]中提出的 Embedding sharing 方法。
-
采用 Grouped Query Attention[3]。
-
提出 Block 级别的权重共享策略,进一步提高了精度,而且不会产生任何额外的内存开销。
探索实验在 32 A100 GPU 上面进行,训练长度是 120k iterations,文本是 0.25T tokens。评测方法是在零样本常识推理任务上评估,还有问答和阅读理解任务。
改进十亿以下参数规模的 LLM 设计
研究者介绍了从十亿以下参数规模的基线模型到新的 SOTA 模型的演进之路(如下图 3 所示)。他们分别研究了 125M 和 350M 参数规模的模型,并在这两个规模下展示了一致的改进。对于模型尺寸成为主要制约因素的设备用例而言,如何有效地分配有限的权重参数变得比以往更加重要。
研究者首先通过测试四种有益于十亿以下规模 LLM 的模型设计方法,提出了一个名为MobileLLM 的强大基线模型。这四种模型设计方法包括 1)采用 SwiGLU FFN,2)强制使用深和薄的架构,3)重新审视嵌入共享方法,4)利用分组查询注意力。
接下来,研究者开发了一种直接的逐块层共享方法,基于该方法可以进一步提高准确度,而不产生任何额外的内存开销,并在内存有限的 LM 解码过程中产生很小的延迟开销。他们将具有层共享的模型表示为 MobileLLM-LS。
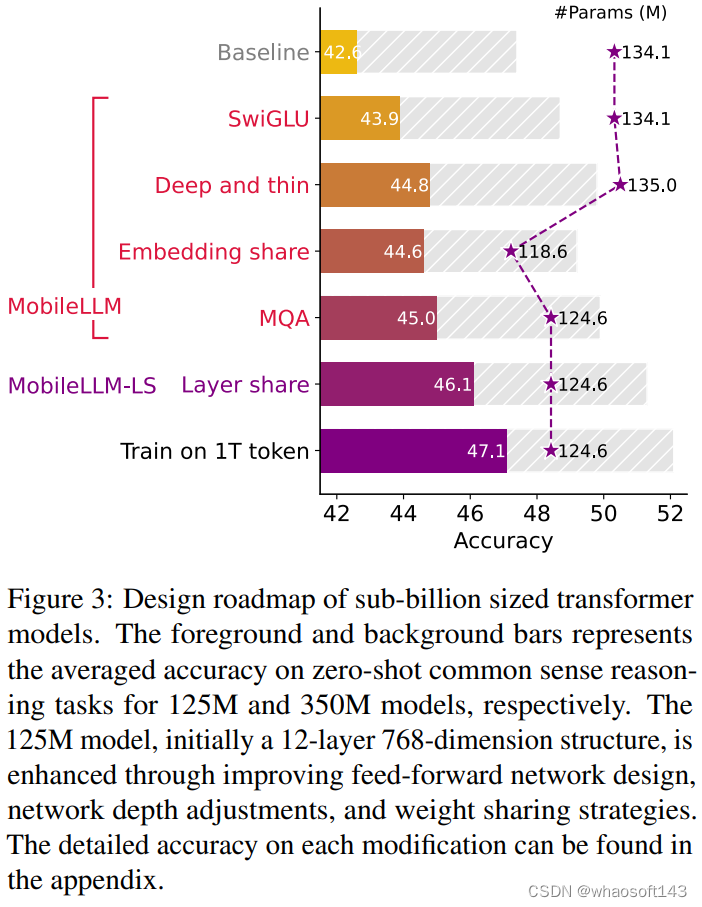
图3:探索实验结果。前景和背景分别代表 125M 和 300M 的模型的 Zero-Shot 的常识推理任务的结果
前馈网络选择
作者首先把原始的 FFN (FC →ReLU → FC) 替换为了 SwiGLU,这使得 125M 模型 Zero-Shot 推理任务的平均性能从 42.6 提高到 43.9。因此,作者以后都使用 SwiGLU 进行实验。
架构宽度和深度
一个普遍存在的认知是 Transformer 模型的性能主要由参数数量、训练数据集的大小和训练迭代次数决定。这个认知假设架构设计对变压器模型的性能的影响是可以忽略不计的。但本文的研究结果表明,这对于较小的模型可能不成立。本文的实验结果,尤其是对于容量有限的小模型,表明深度对于提高模型的性能非常重要。
本文的研究涉及 19 个模型的训练,包括 9 个具有 ∼125M 参数的模型和 10 个具有 ∼350M 参数的模型。每个模型都的设计大小相似,但在深度和宽度方面有所不同。作者在 8 个 Zero-Shot 的尝试推理任务以及问答和阅读理解的基准上进行了实验。实验的结果如下图4所示。更深的模型在大多数 Zero-Shot 的推理任务中都表现出了更加卓越的性能,这些任务包括 ARC-easy、ARC-challenge、PIQA、HellaSwag、OBQA、Winogrande 等。
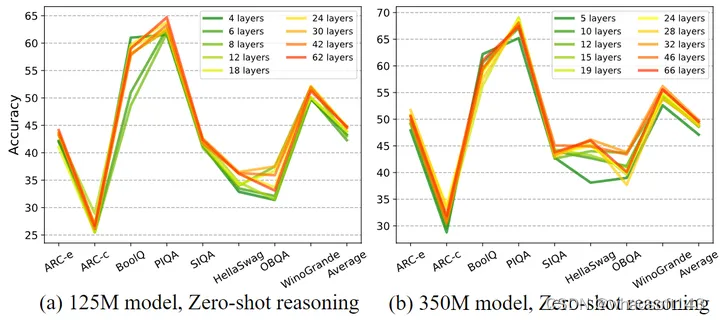
图4:在相似的模型大小下,更深更薄的模型通常在各种任务中都优于更广泛和更浅的模型,例如零样本常识推理、问答和阅读理解
而且,这种趋势在 TQA 和 RACE 数据集上更为明显,如下图5所示。对于大小为 125M 的 Transformer 模型,具有 30 甚至 42 层的模型比具有 12 层的模型表现得更好。
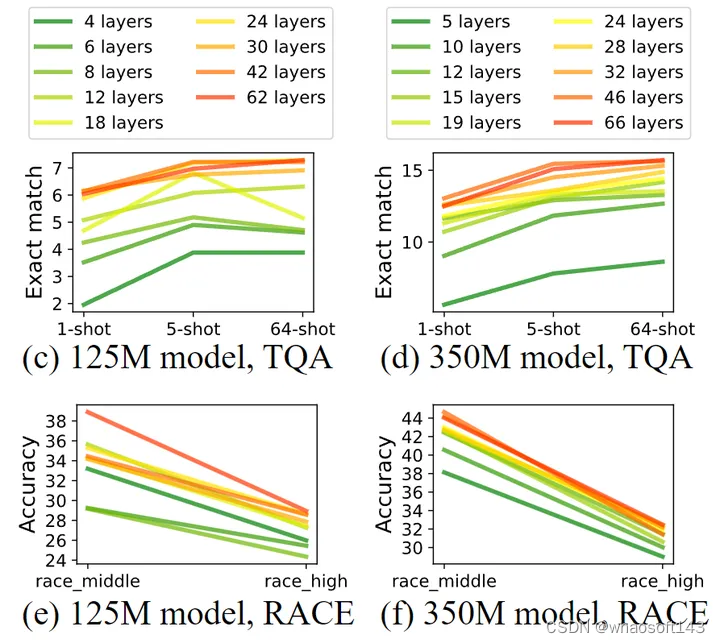
图5:在相似的模型大小下,更深更薄的模型通常在各种任务中都优于更广泛和更浅的模型,例如零样本常识推理、问答和阅读理解
嵌入层共享
对于一个 1B 规模的语言模型而言,嵌入层 (Embedding Layer) 构成了参数量的很大一部分。对于一个嵌入维度为 512,词汇表大小为 32K 的模型而言,输入和输出的嵌入层各包含 16 万个参数,它们占据了 125M 参数模型规模的 20% 以上。相比之下,在更大的语言模型中,这个比例要低得多:输入和输出的嵌入层仅占 LLaMA-7B 模型中参数量总数的 3.7%,在 LLaMA-70B 模型中仅占 0.7%。
作者在小语言模型设计的工作中,重新回顾了嵌入层共享这一概念:
-
LLM 模型的输入嵌入层 (Input Embedding) 的作用是:把一个 token 的 id 映射为一个向量,其维度是:(vocab_size, embedding_dim)。
-
LLM 模型的输出嵌入层 (Output Embedding) 的作用是:把一个向量反映射为 token 的 id,以转化成具体的词汇表的 logit 预测结果,其维度是:(vocab_size, embedding_dim)。
通过输入嵌入和输出嵌入层的权重共享,就可以得到更加高效和紧凑的模型架构。
作者在一个 30 层的大小为 125M 的模型上面进行了实验,结果如图6所示。可以看到输入和输出嵌入层的权重共享将参数量减少了 16M,占总参数量的 11.8%,而平均精度仅仅下降了 0.2。这个极小的精度下降我们可以通过额外加一些层来弥补。与原始的 135M 的模型相比,把层数增加至 24 可以带来约 0.4 的精度增益。在 350M 量级的模型里面仍然可以观察到类似的结果。这些发现也进一步表明,在给定有限的模型存储预算的前提下,可以通过权重共享来最大化权重的利用效率以提升模型性能。

图6:使用 512 嵌入维度的 30 层模型进行输入输出嵌入共享的消融实验结果,任务是 Zero-Shot 的常识推理任务
Heads 的数量

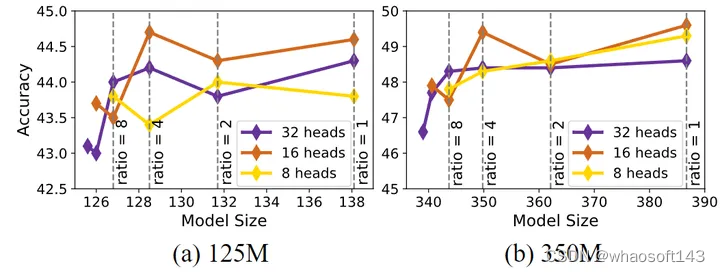
图7:Heads 数量和 kv-heads 数量的消融实验结果
这一步得到的模型称之为 MobileLLM。
作者探索了 125M 和 300M 两种大小的 Transformer 模型的最优 Head 数量,实验结果如图7所示。可以看到使用 16 个 query heads 获得的结果是最好的。而且,把 kv-heads 的数量从 16 个减少到 4 个不影响 125M 模型的性能,且只会使得 300M 模型的性能轻微下降 0.2,但却能够带来 10% 的参数量削减。通过使用 Grouped Query Attention,同时适当增加模型宽度以维持参数量,使得 125M 大小模型的精度进一步提升了 0.4。
训练设置
研究者在 32 个 A100 GPU 上进行实验,其中每个 GPU 的批大小为 32。他们在 0.25T 的 tokens 上执行了 120k 次迭代的探索性实验。下文中表 3 和表 4 报告了在 1T 的 tokens 上执行 480k 次迭代训练的 top 模型。
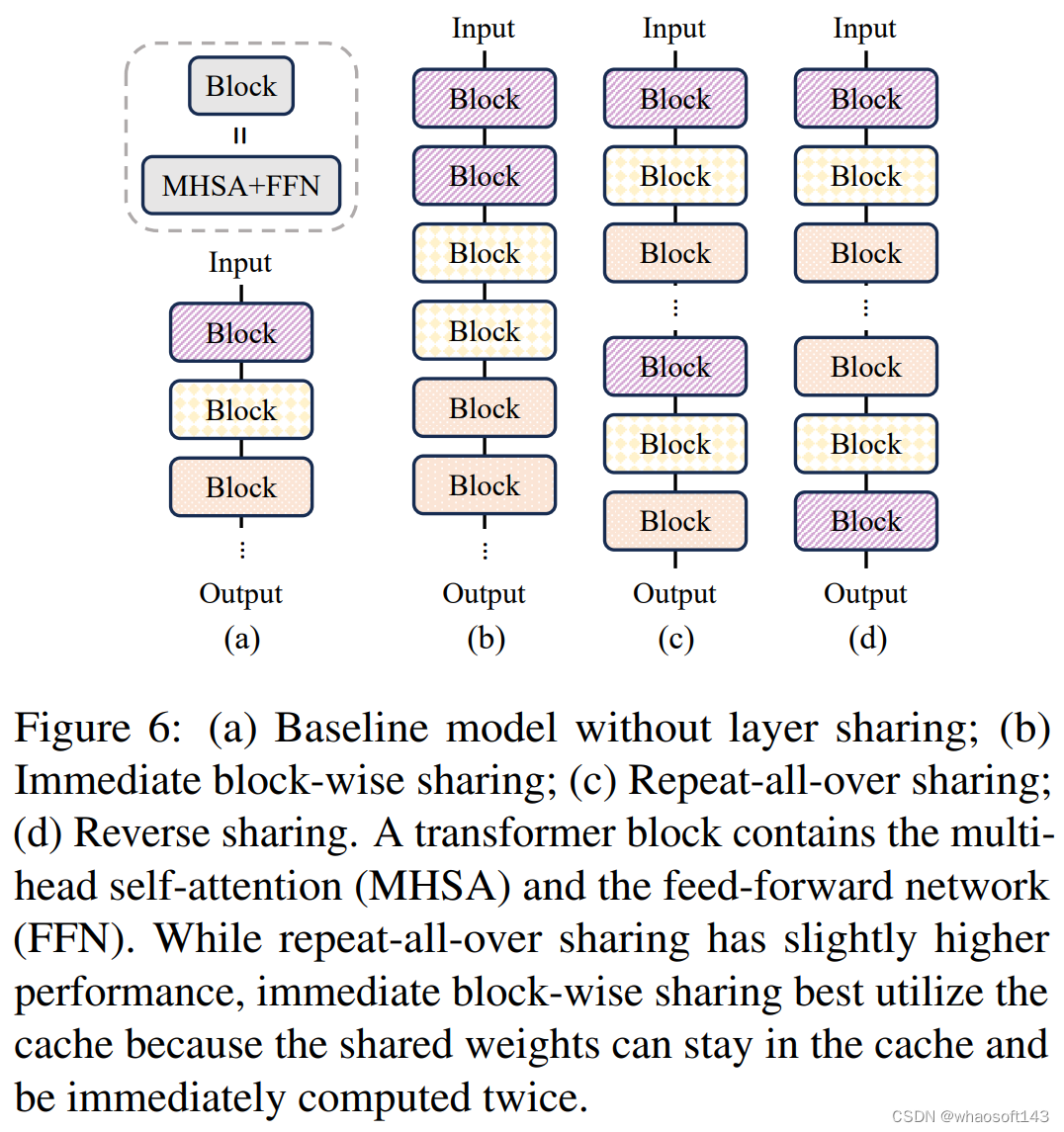
层共享
关于层深度与宽度影响的研究结果表明,更深的层有利于小型 transformer 模型。这促使本文研究层共享作为增加隐藏层数量而不增加存储成本的策略。这种方法在模型大小成为主要制约因素的场景中尤其有用。
令人惊讶的是,实验结果表明,通过简单地复制 transformer 块就可以提高准确度而无需任何架构修改或扩大模型尺寸。研究者进一步探究三种不同的权重共享策略,具体如下图 6 所示。
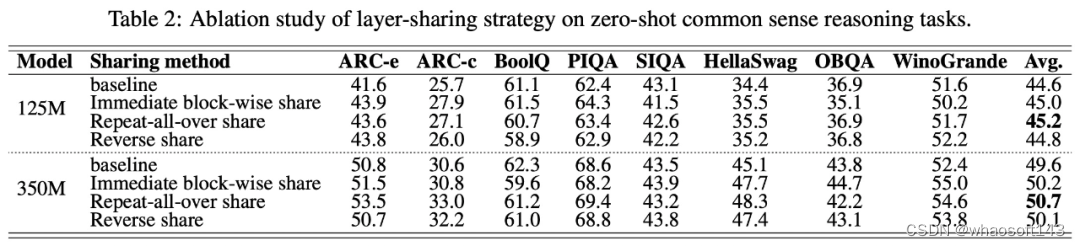
下表 2 结果表明,重复层共享策略在立即块重复、全面重复(repeat all-over)和反向共享策略中产生了最佳性能。
不过,考虑到硬件内存的层级结构(如图 2),用于计算的 SRAM 通常限制在了 20M 左右。该容量通常仅够容纳单个 transformer 块。因此,将共享权重放入缓存中并立即计算两次则无需在 SRAM 和 DRAM 之间传输权重,提高了自回归推理的整体执行速度。
研究者在模型设计中选择了直接的分块共享策略,并将提出的带有层共享的模型表示为 MobileLLM-LS。
实验结果
该研究进行实验比较了模型在零样本(zero-shot)常识推理任务、问答和阅读理解任务上的性能。
零样本常识推理任务的实验结果如下表 3 所示:
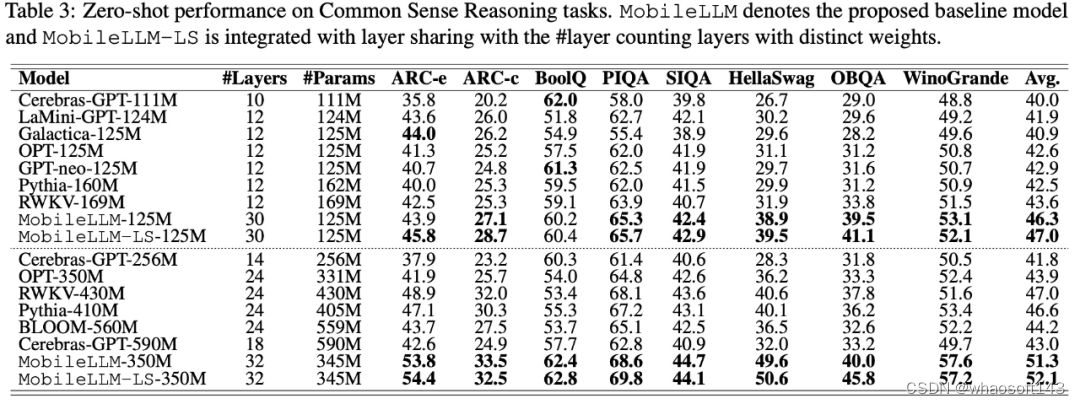
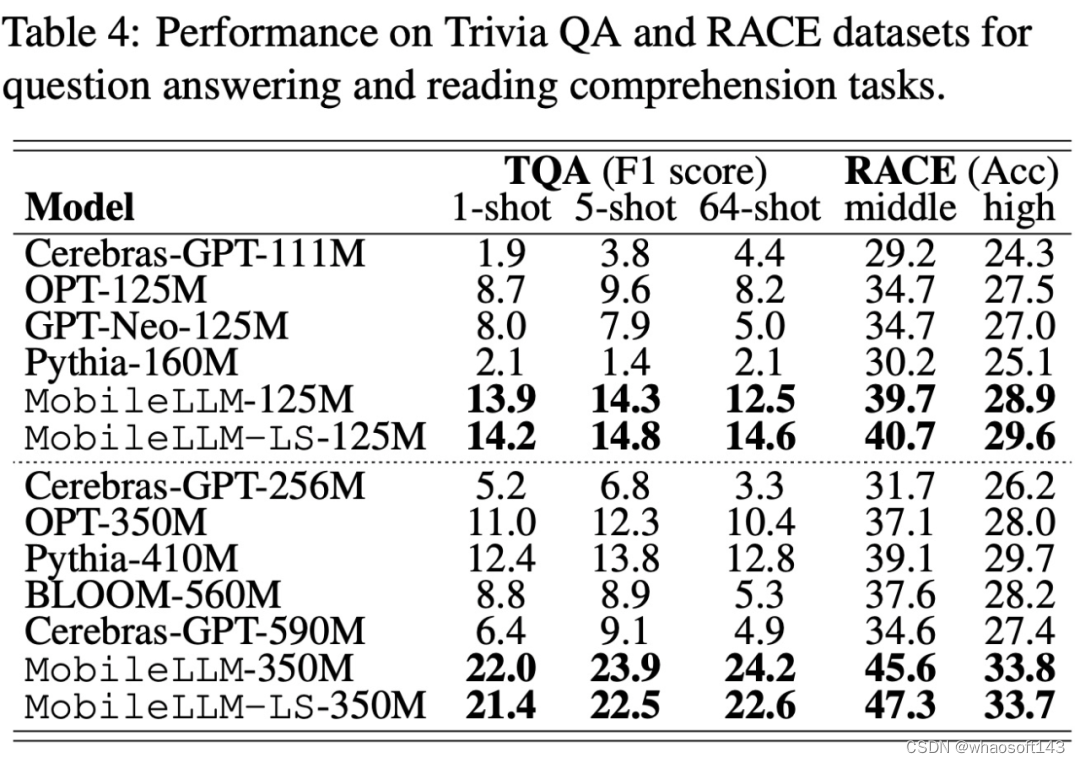
在问答和阅读理解任务上,该研究采用 TQA 问答基准和 RACE 阅读理解基准来评估预训练模型,实验结果如下表 4 所示:
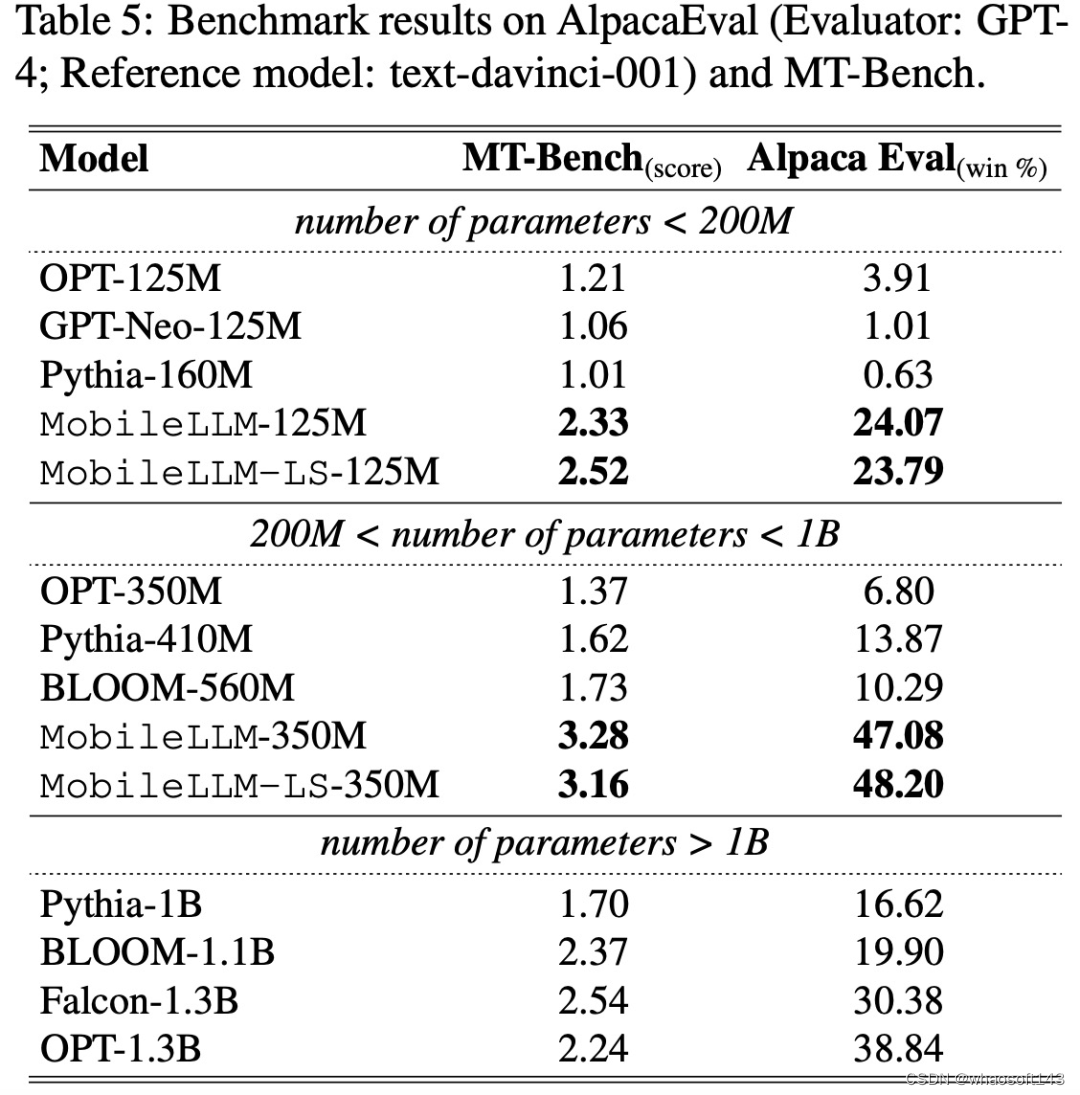
为了验证将模型用于设备上应用程序的有效性,该研究评估了模型在两个关键任务上的性能:聊天和 API 调用。
针对聊天任务,该研究在两个基准上进行了评估实验:AlpacaEval(单轮聊天基准)和 MT-Bench(多轮聊天基准),实验结果如下表 5 所示: whaosoft aiot http://143ai.com
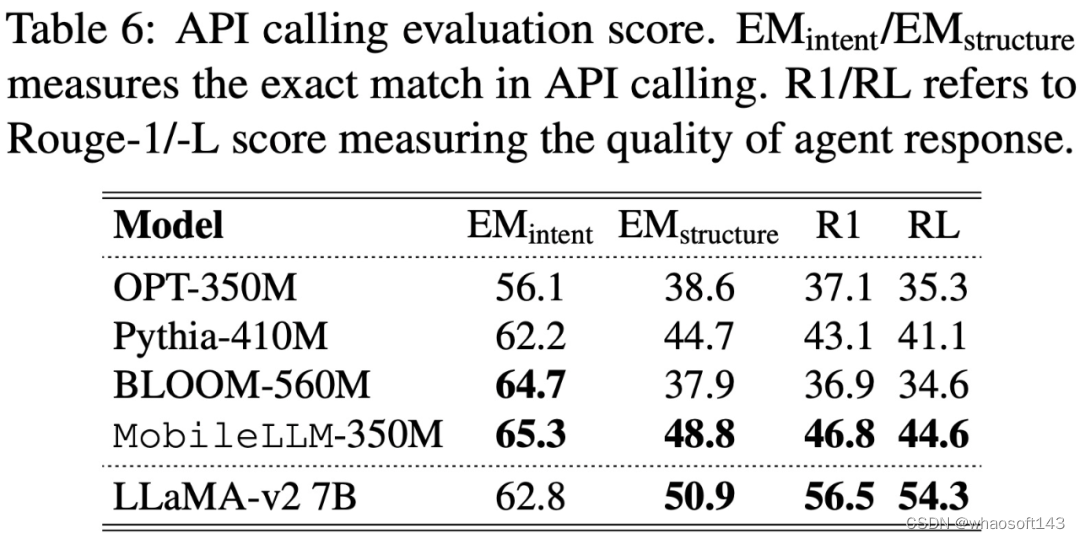
在 API 调用方面,如下表 6 所示,MobileLLM-350M 表现出与 LLaMA-v2 7B 相当的 EM_intent 和 EM_structure,其中 EM_intent 越高,表明模型对用户计划调用 API 的预测就越准确,而 EM_structure 反映了预测 API 函数内内容的熟练程度。
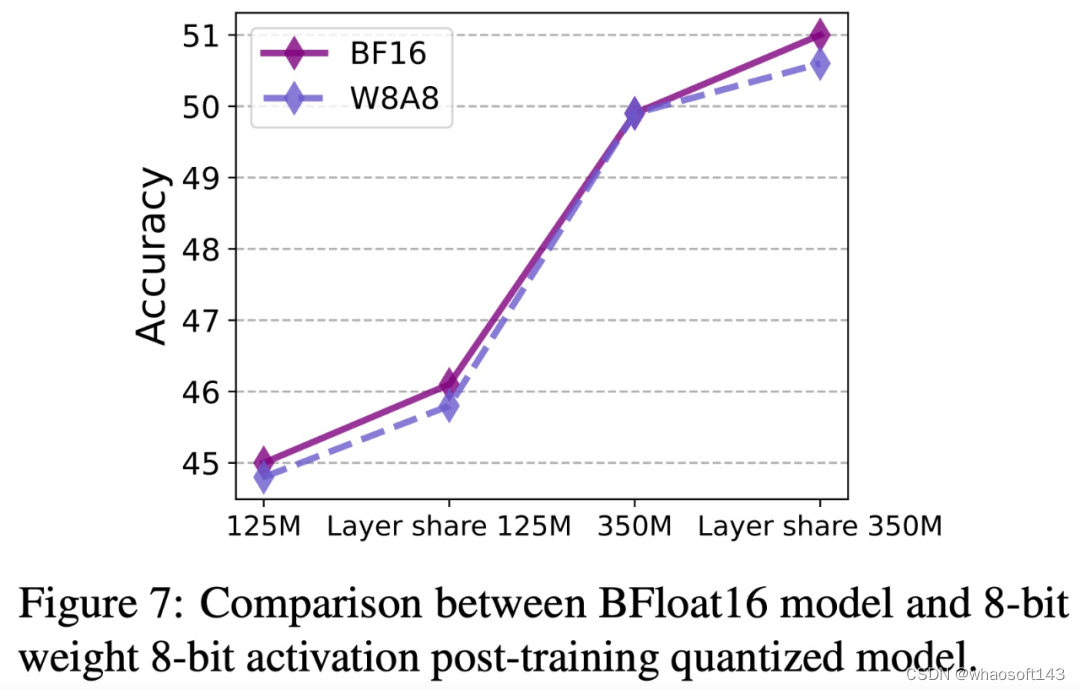
该研究进一步在 MobileLLM 和 MobileLLM-LS 模型上针对每个 token 进行最小 / 最大训练后量化 (PTQ) 实验,模型大小分别为 125M 和 350M,在 0.25T token 上进行训练,实验结果如下图 7 所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









