







# GPT-4理解武林外传中的含蓄表述,达人类水平
今日arXiv最热NLP大模型论文
GPT也来欣赏经典。
在人际交谈中,特别是在使用中文这样博大精深的语言时,人们往往不会直接回答问题,而是采用含蓄、隐晦或间接的表达方式。
人类根据以往的经验或是对说话者的了解可以对一些言外之意做出准确的判断,比如我们小时候经历过无数次的对话情景:
“妈妈,我的书放哪啦?”
“在我手上,来拿嘛!”
又或是:
“妈妈,今天我想吃红烧肉可以吗?”
“你看我像不像红烧肉。”
面对妈妈给出的看似回答了又什么都没有说的回应,我们能迅速get到妈妈不想搭理我们的心情。那LLMs在面对类似的会话隐喻(conversational implicature)时能理解到说话人真正的含义吗?
上交最近从经典情景喜剧《武林外传》中提取出首个针对会话隐喻的中文多轮对话数据集,挑选出200个精心设计的符合会话隐喻的问题,并对八个LLMs进行了多项选择题任务和隐喻解释两项任务的测试。结果显示会话隐喻这一任务对LLMs来说仍然充满挑战。
论文标题:
Do Large Language Models Understand Conversational Implicature – A case study with a Chinese sitcom
论文链接:
https://arxiv.org/pdf/2404.19509
数据集构造
本文选取了在中国广受欢迎的情景喜剧《武林外传》作为数据源。该剧不仅包含了大量富有深意的对话,而且对话文笔优美,均基于自然发生的场景,质量上乘,十分适合用于评估语言模型在理解和推断中文对话深层含义方面的能力。
数据集构造原则
合作原则(The Cooperative Principle)是语言学中的一个重要理论,是由牛津大学的美国语言哲学家Grice于1967年的“逻辑与会话”的演讲中提出的。合作原则包括四个范畴,每个范畴又包括一条准则和一些次准则,即:
-
质的准则(Quality)
a)不要说自知是虚假的话(Do not say what you believe is false);
b)不要说缺乏足够证据的话(Do not say that for which you lack adequate evidence); -
量的准则(Quantity)
a)所说的话应该满足交际所需的信息量(Make your contribution as informative as is required);
b)所说的话不应超出交际所需的信息量(Do not make your contribution more informative than is required); -
关系准则:说话要相关 (Be relevant)
例如:当被问到“约翰在办公室吗?”时,山姆回答:“今天是周六,你知道的”。这违反了关系准则,因为回答与问题不直接相关,从而产生了隐含含义:“约翰周末从不工作,所以他不在办公室”。 -
方式准则:说话要清楚、明了 (Be perspicuous)
a)避免晦涩 [Avoid obscurity];
b)避免歧义 [Avoid ambiguity];
c)简练[Be brief (avoid unnecessary prolixity)];
d)井井有条 [Be orderly]。
然而,人们在实际言语交际中,并非总是遵守“合作原则”,出于需要,人们会故意违反合作原则。Grice把这种通过表面上故意违反“合作原则”而产生的言外之意称为“conversational implicature(会话隐喻)”。这解释了听话人是如何透过说话人话语的表面含义而理解其言外之意的,由此来表达另外一种意思,幽默也就时常在这时产生。
本文正是通过以上这些原则来挑选出对话制作针对会话隐喻的多轮对话中文数据集。
隐喻的识别与分类
三位作者从《武林外传》脚本中通过判断是否违反了会话原则而挑选出包含会话隐喻的对话,为了进行更细致的分类,使用子准则作为标准,评估目标句子是否满足每个要求。如果一句话违反了子准则,就认为它违反了该准则。对话可能根据违反的子准则属于多个类别。一个示例数据条目,包括对话、四种解释和类别,如下图所示:
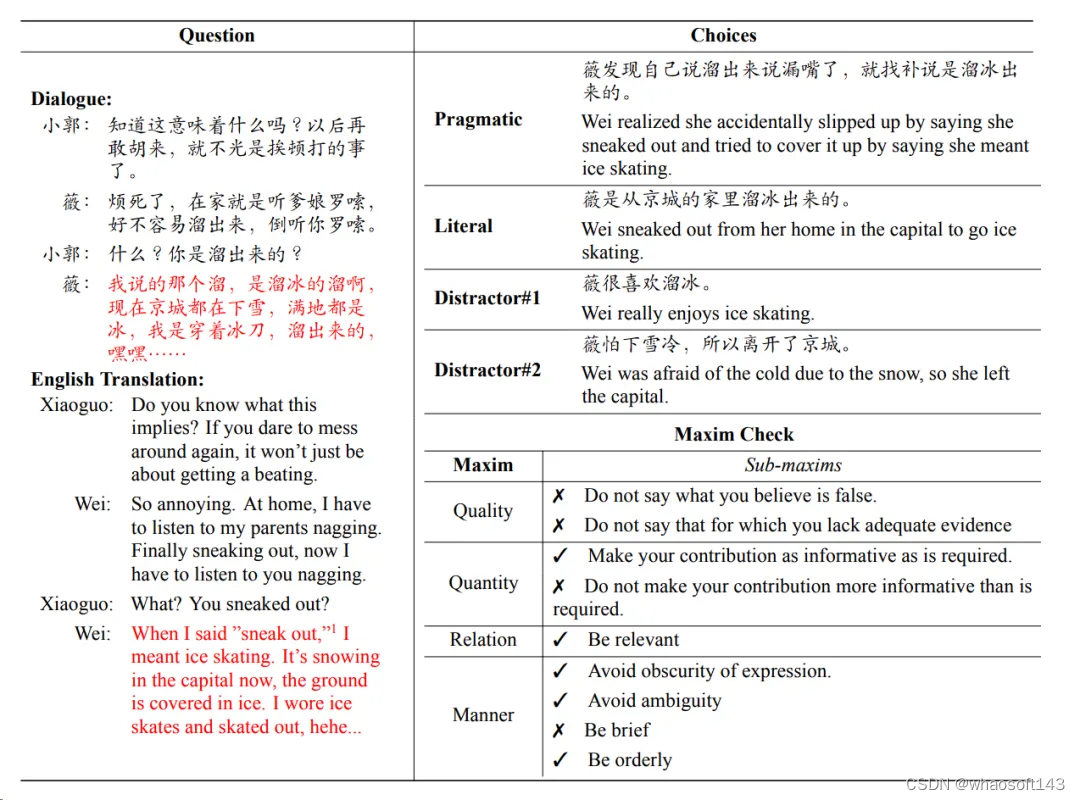
接下来构建对话的四种解释:
-
语用解释(the pragmatic interpretation),也就是正确答案;
-
字面解释(the literal interpretation);
-
两个与上下文相关的干扰项(distractors)
基于以上解释构建了选择题,聘请塞纳名语言学博士作答,并讨论错误答案和推理过程。这个验证过程确保提供的语用理解与常识直觉紧密一致,并能从有限的上下文中推断出来。对话开头补充了必要的信息,如人物关系、性格、社会背景和多模态信息。
人类评分
为了与人类表现进行比较, 邀请了10位母语者随机回答了数据集中抽取的32个问题,平均准确率为93.1%。问卷中各类问题(即对话中违反格赖斯准则的情况)的数量相同。
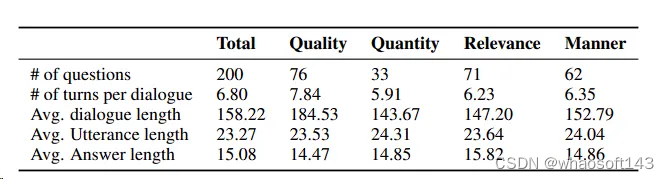
最终的SwordsmanImp语料库包含200个经过精心挑选的问题,按照合作原则分为四类,如下表所示。每个条目包含多轮对话和四个目标句子的解释作为选择项。
实验一:LLM做多选题
实验设置
在这个实验中,模型将看到对话及手动创建的四种解释。任务是针对包含言外之意的语句选择正确的解释。
作者测试了八种模型。包括开源与闭源模型,使用零样本提示来模拟人类日常遇到这些暗含言外之意的真实场景。
对于开源模型,遵循LLM评估的既定做法,即计算“ A”、“B”、“C”、“D”这四个Token在生成后得到的logits,选择具有最高logit值的一个 作为模型预测;对于闭源模型,让它生成答案,然后人工检查生成的文本以确定选择了哪个解释。
实验结果
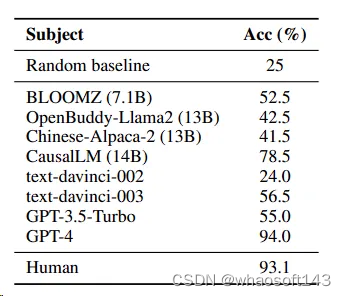
实验结果如下表所示,GPT-4的准确率高达94%,其表现与人类相当,显示出强大的能力。紧随其后的是CausalLM (14B),其准确率为78.5%,也表现出不俗的性能。
然而其他模型面临了较大困难,它们的准确率普遍在20%到60%之间。特别值得注意的是Textdavinci-002的准确率甚至未能达到随机水平(25%),这表明测试模型在理解隐含意义方面仍有很大的提升空间。
下表详细展示了不同模型在违反不同会话准则中的表现:
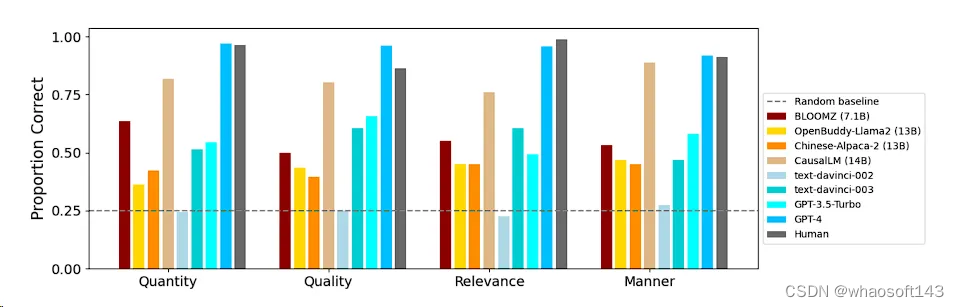
总体来看,模型们在不同准则上的表现各有千秋,没有一个模型在所有准则上都展现出一致的强项或弱点。人类的回答也显示了这种多样性。
在开源模型中,CausalLM (14B)的准确率接近人类水平,在所有开源模型中表现最佳,显示出其强大的对话理解能力。 whaosoft aiot http://143ai.com
而GPT-4在所有模型中的表现最为突出,其准确率在所有类别问题中都超过了90%,再次证明了其在NLP领域的领先地位。
下图展示了模型在解释选择上的分布情况。红色代表模型选择了正确的答案,即语用解释;黄色代表选择了字面含义;而绿色则代表选择了两个干扰项。
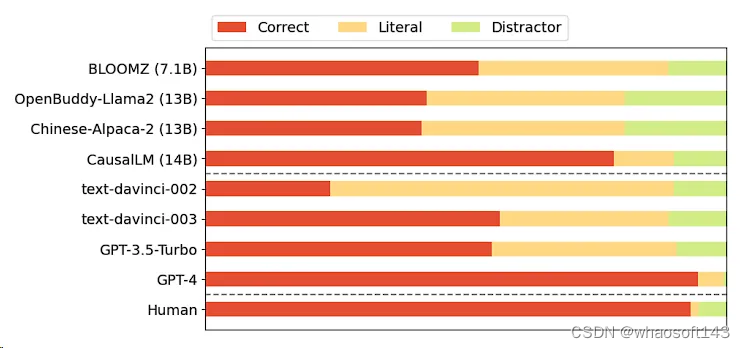
可以看到两个13B模型在选择干扰项上的频率较高,这可能暗示它们较易受到上下文中非相关信息的干扰。
另外,随着GPT模型的不断演进,它们逐渐能够更好地区分字面含义与隐含含义。特别是GPT-4,在解释选择中,对字面理解的比例显著降低,这进一步验证了模型在理解复杂语言现象方面的进步。
实验二:评估LLM生成解释的质量
作者设计了开放性问题,要求模型生成对言外之意的解释,然后由中文母语者根据生成解释的合理性(reasonability)、逻辑性(logic)和流畅性(fluency)进行人工评估。结果如下表所示:
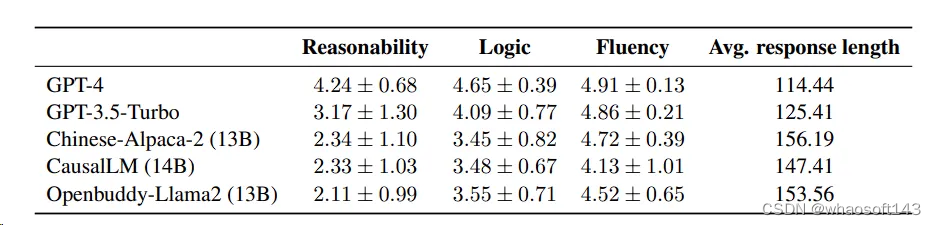
GPT-4在所有三个维度上的得分均位居榜首,且其得分的方差最小,显示出稳定且卓越的性能。GPT-3.5-Turbo的评分虽然也较高,但标准差较大,这反映出其性能存在一定的不稳定性。其他三个模型的评分则相对接近,统计检验显示它们之间没有显著差异。
然而,值得注意的是CausalLM(14B)的得分低于GPT-3.5-Turbo,这与在实验1中的观察结果并不一致。这一发现揭示了模型在特定任务(如从四个选项中选择答案)上的优秀表现,并不一定能保证它们在其他任务(如提供连贯的隐含意义解释)中同样出色。这进一步说明了模型在处理不同任务时可能存在的性能差异。
下图呈现了一个模型生成的典型对话示例。

通过分析湘玉的话语中的隐含意义,我们可以理解到她实际上是在传达石头不宜再饮酒的警示,同时她的言辞中还透露出对石头的讽刺和不满情绪。
在示例中,GPT-4虽然给出了与参考解释相近的简洁说明,但它却错误地理解了讽刺的语气,将其解读为对石头酒量的质疑。
CausalLM(14B)虽然在总体上提供了正确的解释,但答案的质量受到了流畅度不佳的影响,出现了英文单词和无意义的字符序列“NST”。值得注意的是,“forgot his place.”这一表达实际上蕴含了正确的含义,可以将其视为语言代码的切换,而非无意义的输出。
Openbuddy-Llama2(13B)的回应则显得冗长且内容与问题不相关。
分析:LLM理解中文隐喻的能力到底如何?
实验一的结果表明,GPT-4在本文设定的基准测试中展现出了与人类相媲美的表现,而其他模型至少落后了15分,其中包括GPT-3.5-turbo。
这表明,虽然理论上最先进的LLMs有能力学习并理解中文隐喻,但对于大多数LLMs来说,这仍然是一项具有挑战性的任务。
实验二的结果揭示:一个在多项选择题中表现出色的模型(如CausalLM-14B),在自由文本生成任务中,即当需要自行解释言外之意时,可能会失败。这一发现让我们认识到,仅仅依赖多项选择题并不足以全面评估语言模型的语言能力。未来可以设计更复杂方法,以更好地量化模型对会话隐喻的自由形式的解释。
结论
本文构建了SwordsmanImp,这是首个用于评估LLMs对会话隐喻理解的细粒度中文数据,并进行了多项选择和自由生成解释两项任务评估LLMs对中文会话隐喻的理解能力。GPT-4在所有的对比模型中仍然是最能打的,甚至在多选题回答上达到了人类水平。
# 关于AI大模型的思考和讨论
大模型最近各大厂搞得火热,而大模型究竟是如何去界定的?以及大模型真的是AI的未来吗?
三问大模型,AI的路在何方
近日内部有关大模型的讨论比较多,也组织了几次内部的分析和研讨,有赞同、有批判、有质疑、有期许,抱着略懂的心态,本着“胡说八道”的精神,借着弹窗的周末时间,谈谈对大模型的一些看法。想到哪里就写到哪里,比较细碎,由于胡说八道所以就以字为主,方便讨论,省流的话直接看加粗字体部分。
1. 大模型到底大在哪里?
要想回答这个问题,首先要思考“大模型”到底是什么,只有定义好这个边界,我们才能有所有后续的“胡说八道”。
大模型这个关键词的热度在学术界应该起于两篇论文GPT-3 [1] 和 ViT [2]。(注:由于我以前的研究背景都在视觉上,所以对GPT相关的工作是真的胡说,后文的思考还是以CV领域的感受为主)GPT-3给大家的直观感受就是参数量暴涨、计算量暴涨、数据量和性能暴涨,很强!ViT给做视觉的同学们带来的感受有点文艺复兴的意思,因为把图像切成很多块的方式是深度学习之前的视觉最基本的操作,不规则的就是传统的SIFT [3],规则的切patch方式就是HoG [4],在十年前的很多比赛中也都取得了不错的结果(CV和NLP领域经常互相借鉴,Bag-of-visual-words也是从NLP领域借鉴过来的)。话又说回来,ViT对视觉领域的从业人员来说,更直接的感受像让子弹飞中的张麻子(枪在手,跟我走),新架构终于来了,赶紧跟!谁下手快谁引用高!
那么,以视觉为例,到底什么是大模型呢?大是一个形容词,比较出来的结果,如果拿ViT与也是基于谷歌的工作卷积网络(CNN)架构FixEfficientNetV2-L2(480M参数,585G计算量)做对比,ViT-Large(307M参数,190.7G计算量,很多人其实没有细想过,我有时候会觉得,ViT这种架构只是在不想增加FLOPS的情况下,努力增加参数量,能吃下更多数据的一种方案)似乎也没有特别大 [6]。不过,由于架构的不一致,ViT这种具有更高参数容量的模型在更大的数据集(谷歌JFT,也有一种说法这个数据集一定程度包含了ImageNet,所以结论存疑)上做预训练可以达到更好的性能。此外,之前在智源的一次活动中跟山世光等老师们讨论过,视觉跟语言的模型不一样,视觉模型的输入维度很高,比如经典的ResNet系列,输入数据的维度是一张有224*224*3个像素的图像,所以大不大其实也要看计算量,比如上面提到的94B已经非常恐怖了。
结合最近的一些论文、公众号、讲座、内部研讨、访谈,我总试图想定义一下,到底什么是大模型,可行的有两个可以量化的角度:
a) 100M参数以上,在多个任务(不同loss|不同dataset|不同task)上进行预训练的模型就叫大模型。正例很多,ViT和各种变种,也有我们自己鼓捣出来的底层视觉大模型IPT [5]。不过,这个结论很快被组里的一位机智的小伙伴推翻了,因为EfficientNet或者某些CV backbone经过放大之后可以轻易超过100M参数,并且在ImageNet上预训练之后可以在检测、分割等任务上做出很好的表现,不是新东西。
b) 用到了Transformer的架构,支持预训练就叫大模型。本来以为这个定义似乎清晰了一些,但是又想到大家开始在ViT架构中猛插卷积(convolution)并且取得了更好的效果,所以大模型似乎也不应该跟Transformer绑定。
所以,这一环节的结论,仍然是无法清晰地给定,什么是大模型。或许,在技术上就不存在这样一个新概念,只要随着数据不断增长,算力持续提升,优化手段越来越好,模型总是会越来越大的。
2. 大模型到解决了什么大问题?
既然有大模型,我想,其他的AI模型都应该是“小模型”了吧,那我们需要思考的就是大模型在关键的问题上真的全面超过小模型了没有?感觉前面啰嗦了太多,当然问题定义也比较重要,我们沿用1.a的定义去思考,大模型与小模型的对比。
a) 在ImageNet这种大规模数据集上,或者更大的数据集,目前的证据确实是越大的模型(尤其引入了Transformer和切patch之后),精度越来越高。不过限定的一些实际用到的数据集往往也会发现,小容量(<100M)的网络也能摸到数据集的极限,小模型还有速度、内存、功耗、训练成本等优势。所以,越复杂的任务,参数越多,模型越大,作用越大,也有点胜读一席话的意思了。
b) 多个任务一起预训练,这么多年机器学习也都是一直这么干的,那我们剥离模型本身,就看多任务预训练一定会让模型在后续任务中fine-tuning之后效果更好吗?答案是否定的,我们之前的工作中就发现了,在底层视觉的任务里,有些任务是打架的,联合训练会导致一定程度的精度恶化。甚至如果优化器做得好,直接train from scratch可以比pre-train + fine-tuning效果更好,确实也有点离谱。相似的任务一起预训练还是会有一定帮助的,也可以理解成为某种程度的数据扩充,见得多总是要识得广。
c)大模型经过调整之后,经过一系列模型优化手段之后,是不是能一定超过小模型?答案也是否定的,很多任务是具有很专业化的领域知识支撑才可以做好的,而不简单是一个大模型就包打天下。如果不理解任务不理解数据特性,大模型甚至达不到领域内SOTA模型的精度。此外,很多任务的逻辑不一样,模型架构也是完全不一样的,强扭的瓜不甜,我感觉为了融合而融合达不到很好的效果。用大模型对小模型蒸馏一定会产生更好的结果吗?不好意思,因为架构差异太大,这还是个需要探索的问题。
个人感觉有价值的方向还是2.a和2.b中提到的,难的任务,相似的功能,相同的数据,大模型可以吃得下,就有其优势。 题外话是算力和优化器能否支撑这么大的模型,还有硬件之间的连接和通信。
3. 大模型中最大的挑战是什么?
大模型从热度伊始就在学术界有两种声音,一种是大模型功能多性能强,一种是大模型就是一阵风。所谓韭菜的共识也是共识,我们再想想大模型面临的挑战。上面也说了,NLP我确实不怎么懂,主要的感官还是来自计算机视觉。
a)模型规模继续加大,参数量继续增多,精度还能上涨吗? 目前来看在新的架构出来之前,似乎CNN、Transformer、CNN+Transformer都已经达到了一定程度的极限,一旦主流任务刷不动了,大家又要开始去别的领域应用了,例如AI4Science,我个人不觉得关键点在于大模型。不过这也是个好事,技术阶段性成熟,积极变现转化成新的力量。另外一个角度是一位同学跟我说的MoE(Mixture of Experts),通过稀疏化把多个模型集成在一起,轻松提升模型参数量。嗨!学术界的营销能力其实一直都不比工业界差,MoE也不是个新概念,有几十年历史。类似的一些优秀工作也有Slimmable Network和Dynamic Network等,未来到底AI架构何去何从,共勉吧。
b)现在大模型是一个工程问题,还是一个技术问题? 大胆的说一下,更多我们见到的大模型都是工程问题,背后有杰出的工程师做数据收集、数据清洗、模型结构设计、模型调优、多机多卡优化等等复杂繁琐的工程性工作。产生的价值见仁见智。两年前,一位业界大佬在重要的讲座中讲到,大模型的工作里面都是工程、工程、还是工程问题。在合适的任务上还是有其优势的,但是我们也要思考,现有的优化器能否支撑大模型的参数量和任务复杂度。单说ImageNet这个经典任务,非Transformer架构,不用预训练,通过系统性地适配优化器、训练参数、数据扩充、甚至随机数种子等等,也可以超过ViT。当然,这也是一些炼丹工作,但是炼丹炼着炼着其实也能发现科学,比如最近的一些Rep系列工作(重参数化),我觉得也是一种很不错的优化器改进的方法,也会鼓励大家去使用。
惯例还是要及时总结: 写完这些,越来越让我觉得大模型是一个被大家揣着明白装糊涂的概念性词汇,大家似乎也没有定义清楚啥是大模型,无论是1.a还是1.b都有一定的可取之处,对AI架构有一定年头积累的专业人员也都知道“大模型”的优劣。但是,大家似乎都沉浸在大模型欣欣向荣、歌舞升平的状态中,大多数工业界的场景中,大模型并不能直接发挥价值。在不同的任务里还是要根据实际场景去谈具体的模型和算法,不建议逢解决方案就提大模型,也不建议把大模型当成一个主要的技术方案去忽悠不是特别懂这一块技术的人,事实上在学术界的论文中也不会有人说我们用一个Big Model解决了所有问题。未来大模型应该可以在2.c所提的方向上持续发力,但肯定也会演变出来一系列千奇百怪或优或劣的AI架构,大浪淘沙,去伪存真。
# ICLR 2024首个时间检验奖公布
ICLR 2024 评选出的时间检验奖,在各自领域可谓是开山之作。10年前VAE经典论文获奖
由深度学习巨头、图灵奖获得者 Yoshua Bengio 和 Yann LeCun 在 2013 年牵头举办的 ICLR 会议,在走过第一个十年后,终于迎来了首届时间检验奖。
为了评选出获奖论文,项目主席审查了 2013 年和 2014 年 ICLR 论文,并寻找具有长期影响力的论文。
今年,由 Diederik P. Kingma、Max Welling 合作撰写的论文获得了该奖项,获奖论文为《 Auto-Encoding Variational Bayes 》;论文《 Intriguing properties of neural networks 》获得了亚军。
ICLR 2024 时间检验奖
论文《 Auto-Encoding Variational Bayes 》作者共有两位,他们当时均来自于阿姆斯特丹大学。
-
论文地址:https://arxiv.org/pdf/1312.6114
-
论文标题:Auto-Encoding Variational Bayes
-
作者:Diederik P. Kingma 、 Max Welling
获奖理由:概率建模是对世界进行推理的最基本方式之一。这篇论文率先将深度学习与可扩展概率推理(通过所谓的重新参数化技巧摊销均值场变分推理)相结合,从而催生了变分自动编码器 (VAE)。这项工作的持久价值源于其优雅性。用于开发 VAE 的原理加深了我们对深度学习和概率建模之间相互作用的理解,并引发了许多后续有趣的概率模型和编码方法的开发。这篇论文对于深度学习和生成模型领域产生了重大影响。
作者介绍
Diederik P. Kingma 现在是谷歌的一名研究科学家。根据领英介绍,Kingma 曾经是 OpenAI 初创团队的一员,在 OpenAI 工作期间领导了一个算法团队,专注于基础研究。2018 年,Kingma 跳槽到谷歌,加入 Google Brain(现在合并为 Google DeepMind),专注于生成式模型研究,包括扩散模型和大型语言模型。
Kingma 主要研究方向是可扩展的机器学习方法,重点是生成模型。他是变分自编码器 (VAE,即本次获奖研究)、Adam 优化器、Glow 和变分扩散模型等研究的主要作者。根据 Google Scholar 显示,Kingma 的论文引用量达到 24 万多次。
论文另一位作者 Max Welling 现在为阿姆斯特丹大学机器学习教授。和一般机器学习研究者不同,Max Welling 并不是计算机专业科班出身,而是在世界顶尖公立研究型大学 —— 荷兰乌得勒支大学学了 11 年的物理,而且导师是荷兰理论物理学家、1999 年诺贝尔物理学奖得主 Gerard 't Hooft。在 Hooft 的指导下,Max Welling 于 1998 年拿到了量子物理学博士学位。
之后,Max Welling 曾先后在加州理工学院(1998-2000)、伦敦大学学院(2000-2001)和多伦多大学(2001-2003)担任博士后研究员。2003-2013 年,他历任加州大学欧文分校的助理教授、副教授和教授。2012 年,他开始担任阿姆斯特丹大学的教授和机器学习研究主席。
Max Welling 在 2011 年参与的一篇论文《 Bayesian Learning via Stochastic Gradient Langevin Dynamics 》还获得了 ICML 2021 时间检验奖,主题是「基于随机梯度 Langevin 动力学的贝叶斯学习」。在学术成就方面,Max Welling 的论文被引量达到了 13 万多次。
在得知获奖的消息后,Kingma、Max Welling 师徒俩人还进行了互动:
时间检验奖亚军论文
ICLR 2024 亚军论文颁给了《 Intriguing properties of neural networks 》。论文作者共有七位,他们当时分别来自谷歌、纽约大学、蒙特利尔大学。
在过去的十年中,他们中的大多数已经离开了原来的公司和机构。
Christian Szegedy 现在为 xAI 联合创始人;Wojciech Zaremba 为 OpenAI 联合创始人;Ilya Sutskever 是 OpenAI 联合创始人(不过自从 OpenAI 发生宫斗后,暂无消息 );Joan Bruna 现在为纽约大学副教授(Associate Professor);Dumitru Erhan 为谷歌 DeepMind 研究总监;Ian Goodfellow 加入谷歌DeepMind;Rob Fergus 现在为谷歌 DeepMind 的研究科学家。
-
论文地址:https://arxiv.org/pdf/1312.6199
-
论文标题:Intriguing properties of neural networks
-
作者:Christian Szegedy、Wojciech Zaremba、Ilya Sutskever、Joan Bruna、Dumitru Erhan、Ian Goodfellow 、 Rob Fergus
获奖理由:随着深度神经网络在实际应用中越来越受欢迎,了解神经网络何时以及如何出现不良行为非常重要。本文强调了神经网络可能容易受到输入中几乎察觉不到的微小变化的影响。这一想法催生了对抗性攻击(试图欺骗神经网络)以及对抗性防御(训练神经网络不被欺骗)的研究。
这篇论文发表于 2014 年,可以说是对抗样本(Adversarial Examples)的开山之作。论文发现神经网络对数据的理解跟人类的理解方式并不相同,在此基础上,研究者又发现给输入数据添加扰动(也就是噪声),神经网络的输出会产生变化,他们将这种扰动后的图像称为对抗样本。
参考链接:https://blog.iclr.cc/2024/05/07/iclr-2024-test-of-time-award/
# GPT4V、Gemini等多模态大模型竟都没什么视觉感知能力?
2023-2024年,以 GPT-4V、Gemini、Claude、LLaVA 为代表的多模态大模型(Multimodal LLMs)已经在文本和图像等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。
然而,对于这些模型的评测多集中于语言上的任务,对于视觉的要求多为简单的物体识别。相对的,计算机视觉最初试图解读图像作为3D场景的投影,而不仅仅处理2D平面“模式”的数组。
为响应这一情况,本文提出了BLINK,这是一个新的测试集,包含了重新构想的传统计算机视觉问题,使我们能够更全面评估多模态大模型的视觉感知能力,带你揭开GPT4V、Gemini等大模型的视觉界限秘密。
作者相信BLINK将激励社区帮助多模态LLMs达到与人类同等级别的视觉感知能力。
论文链接:https://zeyofu.github.io/blink
什么是BLINK?
BLINK 是一个针对多模态语言模型(Multimodal LLMs)的新基准测试,专注于评估其核心视觉感知能力,这些能力在其他评估中并未涉及。
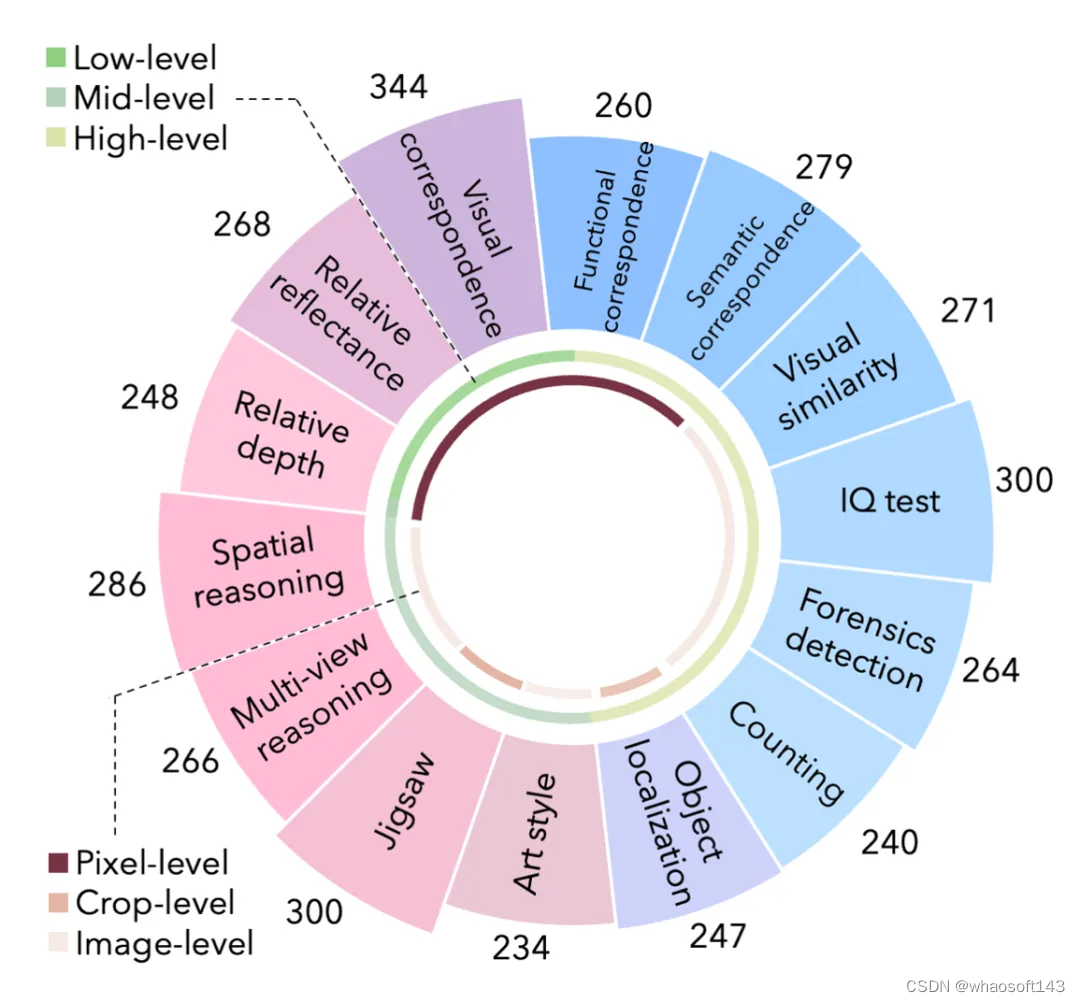
BLINK包含 14 项视觉感知任务,拥有3.8k个选择题和7.3k张图像。
人类可以“一眨眼”之间解决这些任务 (例如,相对视深、视觉对应、目标定位,和多视角推理等);但对当前的多模态大型语言模型(Multimodal LLMs)而言,这些任务构成了重大挑战,因为它们难以通过自然语言处理来解决。
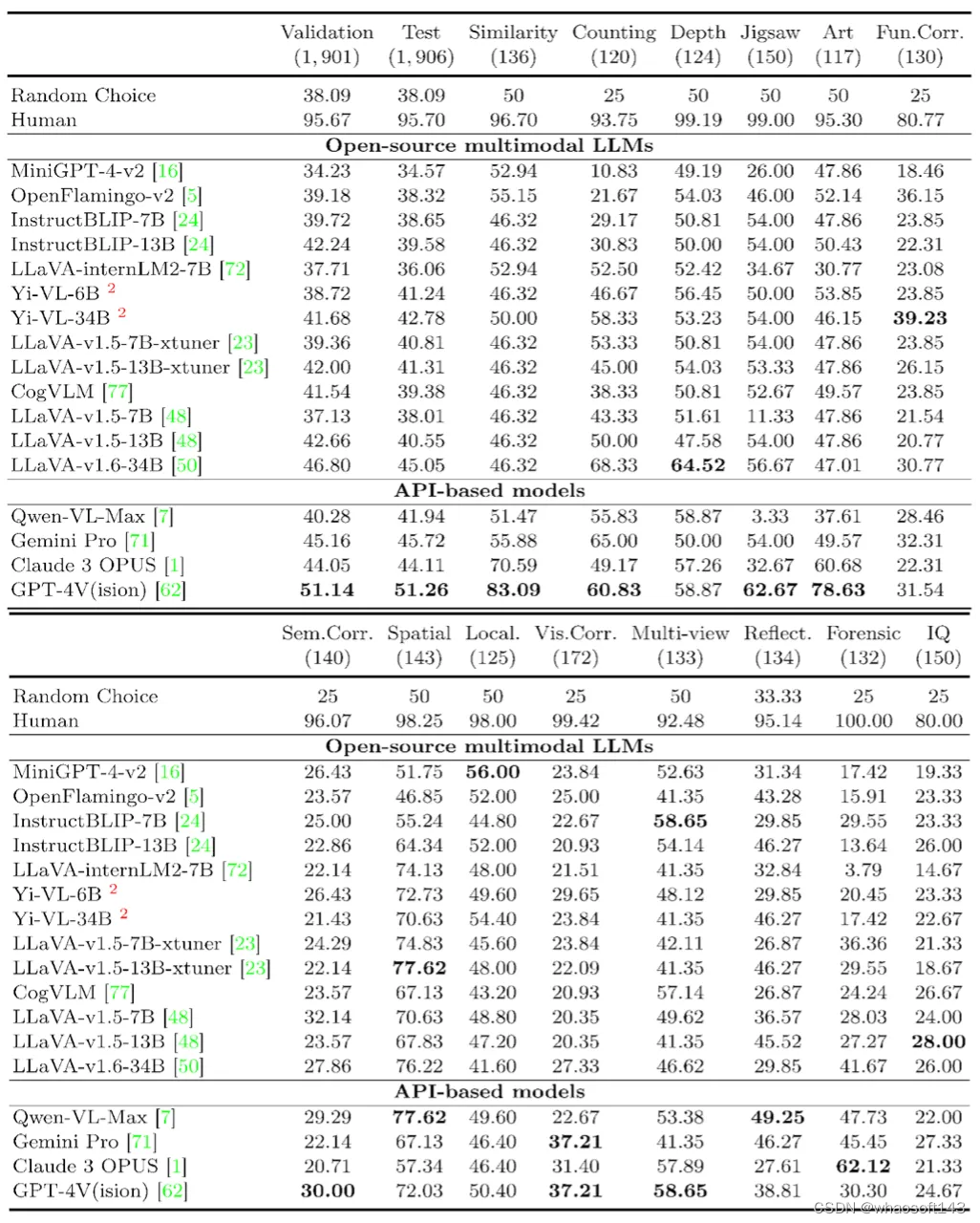
平均而言,人类在这些任务上的准确率为95.70%,然而即使是GPT-4V和Gemini也只达到了51.26%和45.72%的准确率,比随机猜测仅高出13.17%和7.63%。
BLINK与其他基准测试的区别
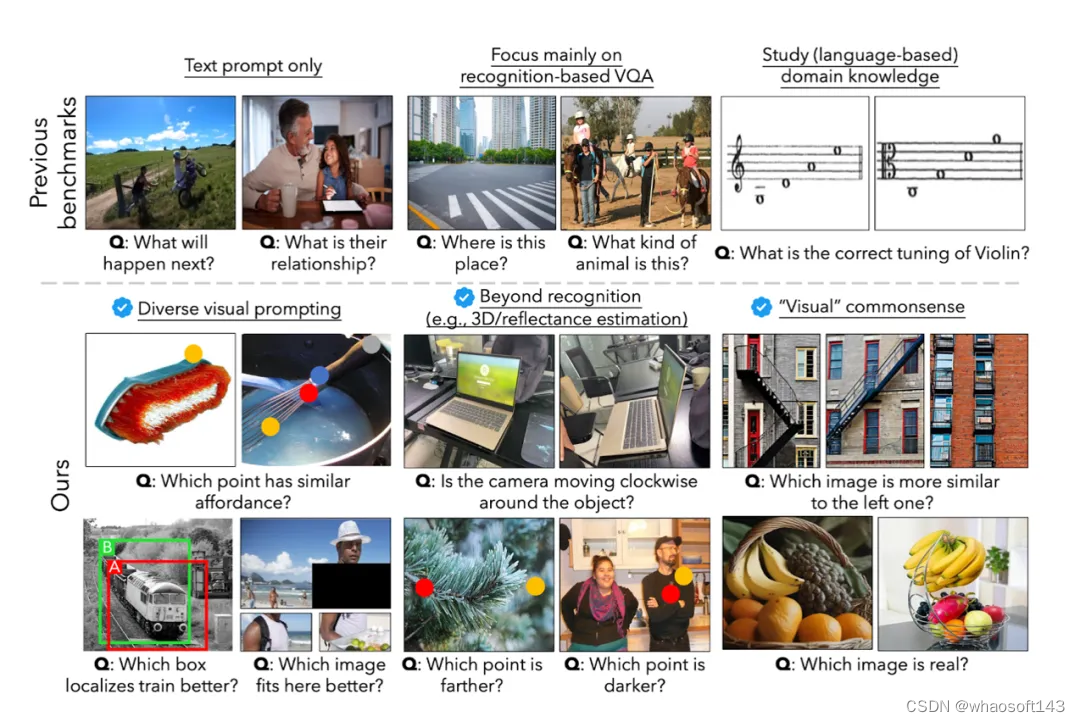
(1)BLINK 运用了多种的视觉prompts, 如圆形、盒形, 和图像遮罩 masks, 而以前的基准测试仅包含文本问题和答案。
(2)BLINK评估了更全面的视觉感知能力,如多视角推理、深度估算和反射率估算。以往的基准测试通常更侧重于基于物体识别的视觉问答(VQA)。
(3)BLINK只包含“视觉”常识性问题,这些问题人类不需要接受教育就可以在一秒钟内回答,而以前的基准测试像MMMU这样的则需要专业领域知识。
(4)BLINK涵盖了14个需求感知的任务,这些任务受到经典计算机视觉问题的启发。虽然这些问题仅需人类“一眨眼”的时间即可解决,但它们超出了当前多模态大型语言模型的能力。
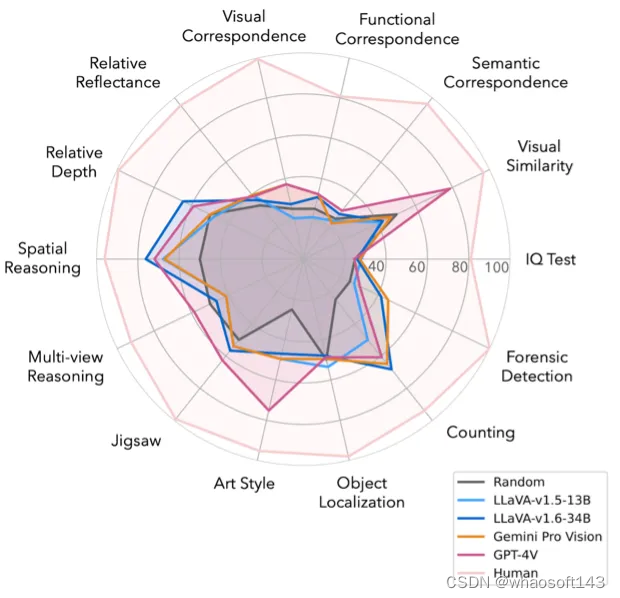
本文评估了17个不同大小(即7B,13B,34B)的多模态LLMs在BLINK上的表现。并观察到一个悖论:尽管这些问题对于人类来说很容易(平均准确率为95.70%),但对现有机器来说却极其困难。
7B和13B开源多模态大型语言模型(LLMs)的平均准确率大约在35-42%之间,与随机猜测(38.09%)相似。
最好的开源模型是LLaVA-v1.6-34B,达到了45.05%的准确率。
即使是最新的大模型,如GPT-4V、Gemini Pro和Claude 3 OPUS,其准确率也仅为51.26%、45.72%和44.11%。它们的表现仅比随机猜测好13.17%、7.63%和6.02%,并且比人类的表现差44.44%、49.98%和51.59%。
值得注意的是,在某些任务上,如拼图、语义对应、多视角推理、对象定位和相对反射率,一些多模态LLMs甚至表现不如随机猜测。
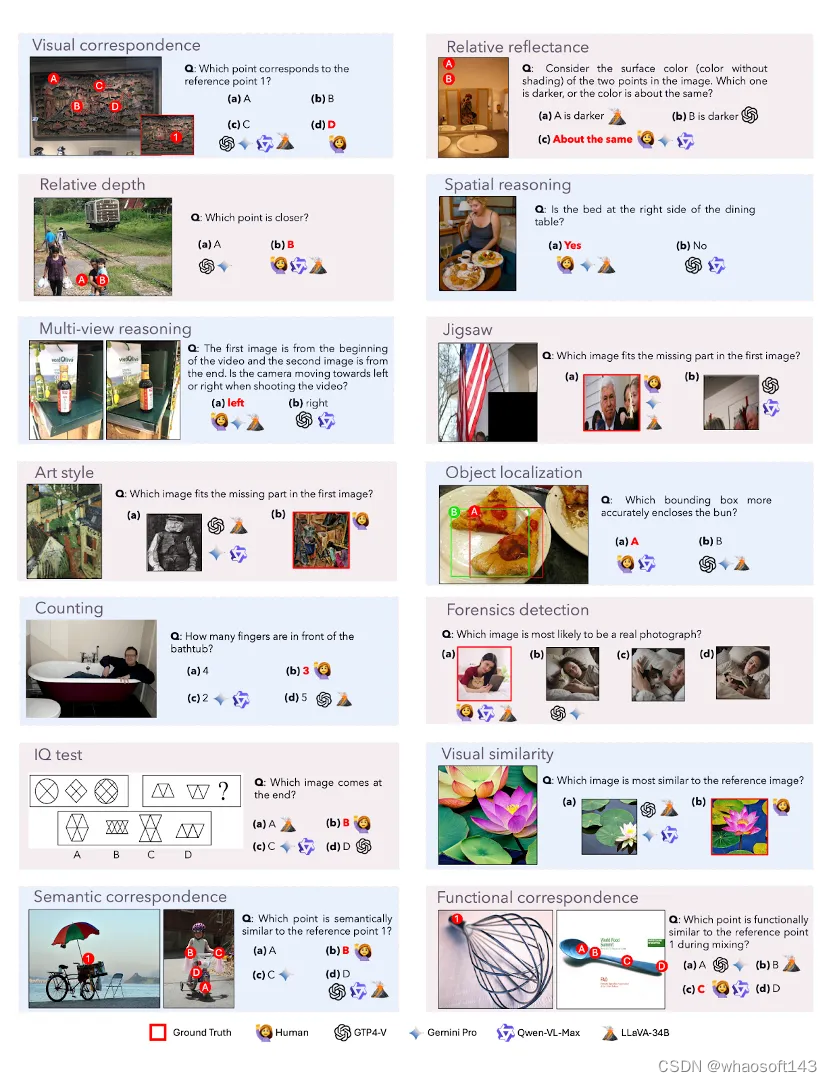
BLINK展示大模型的错误范例
对于每项任务,该文章展示了LLaVAv1.6-34B、Qwen-VL-Max、Gemini Pro、GPT-4V和人类的选择。红色选项指的是正确答案。请注意,为了视觉效果,作者故意放大了标记,并且将一些图片做成插图以节省空间。
对于智力测验,第三张图片是通过叠加第一张和第二张图片构成的。
 BLINK实验分析
BLINK实验分析
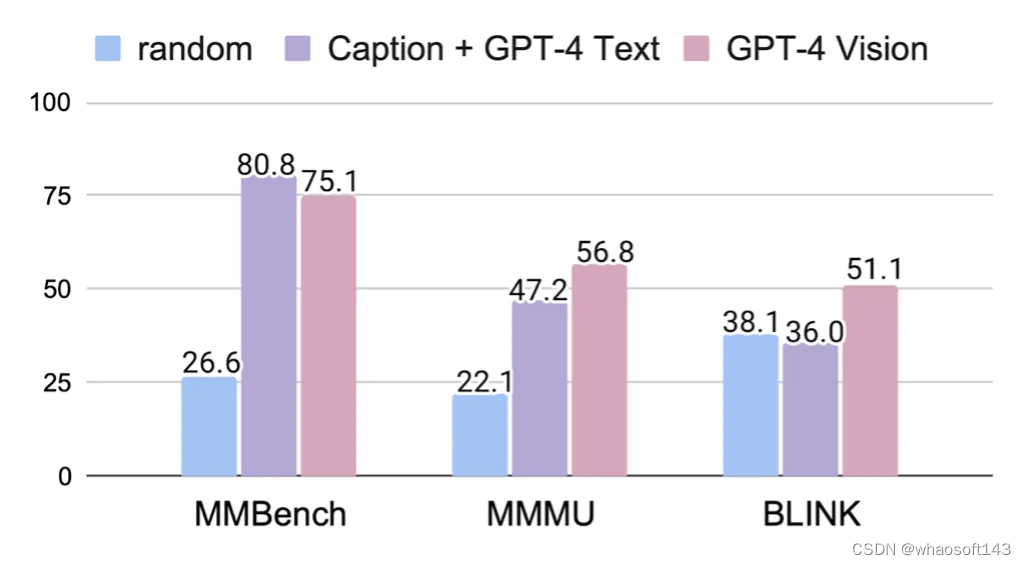
(1)把图片转换成文字是否是解决多模态问题的正确选择?
为了回答这个问题,本文使用GPT-4V将图片转换为与任务无关的密集图片字幕,并使用基于文本的LLM来完成任务(Caption + LLM)。这种密集字幕利用语言描述了图像及视觉提示的详细信息(例如,每个圆圈的位置)。
作者在BLINK、MMBench和MMMU上进行了实验。令人惊讶的是,Caption + LLM的配置在MMBench和MMMU上的结果远优于BLINK。这些结果表明,图像字幕携带了回答其他基准所需的大部分视觉信息。同时,BLINK需要的高级感知能力超出了通用字幕目前可达到的范围。
(2)视觉提示(visual prompts)对多模态大模型能产生多大的影响?
本文分析了BLINK中多个任务上圆圈大小和颜色的影响。
实验表明,视觉提示可能对多模态LLM的性能产生重大影响,改进视觉提示或提高模型对提示变化的鲁棒性是未来研究的有前景的方向。根据分析,作者发现最佳圆圈大小依赖于具体任务,平均而言,10px的圆圈效果最好。同样,对于所有任务来说,红色比灰色更好。
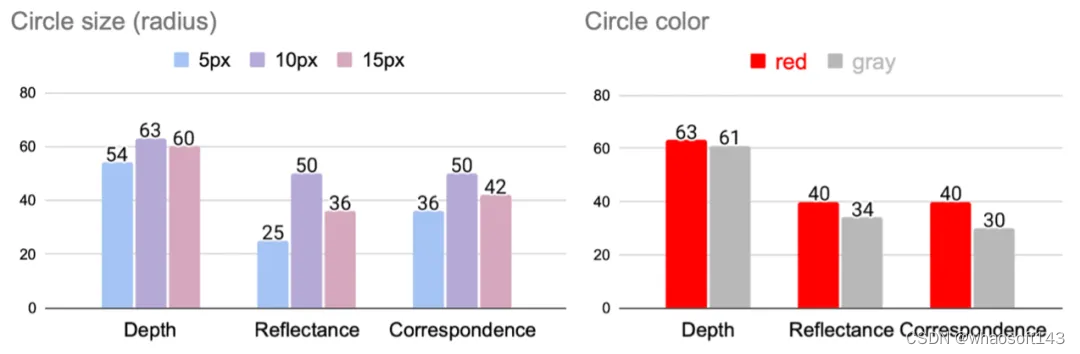
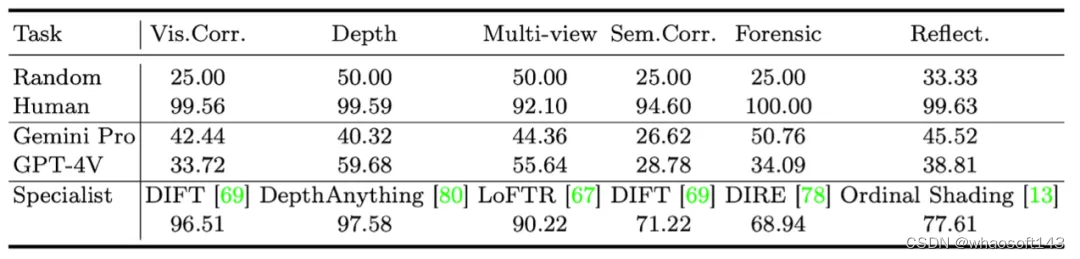
(3)传统计算机视觉专家模型能解决BLINK任务吗?
专家可以作为多模态LLM可能达到的上限的代理。这揭示了一个可能性,即多模态LLM可能因正确的数据和培训策略而在这些任务上取得进展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









