







TBB学习笔记七([Algorithms.parallel_reduce])
《Today’s TBB 2nd Edition》
parallel_reduce
先引入两个概念:归约(reduce)和扫描(scan)。reduce通过聚合操作将多个输入值合并为一个输出值。通常和map结合使用,map :将输入数据拆分为独立片段,每个片段生成中间键值对,reducution:对相同 key 的 value 集合进行聚合;而scan模式不仅计算最终聚合结果,还为每个元素生成前缀结果(这个过程类似reduction),scan的实现分块并行。对比图如下。
| Item | Reduce | Scan |
|---|---|---|
| 输出结果 | 单一聚合值(如总和) | 每个元素的前缀结果(如累积和) |
| 数据依赖 | 无依赖(仅需相同 key 的聚合) | 强依赖(需传递前序计算结果) |
| 并行难度 | 高(易分块) | 中(需处理块间依赖) |
| 内存占用 | 低(仅需最终结果) | 高(需存储中间结果) |
tbb::parallel_reduce 是 一个函数模板,它依赖于关联性(associative)来使用并行任务执行执行归约操作。其中一些函数签名如下,包括了lambda-friendly签名以及class-friendly签名。
template<typename Range, typename Value, typename RealBody, typename Reduction>
__TBB_requires(tbb_range<Range> && parallel_reduce_function<RealBody, Range, Value> &&
parallel_reduce_combine<Reduction, Value>)
Value parallel_reduce( const Range& range, const Value& identity, const RealBody& real_body, const Reduction& reduction,
const simple_partitioner& partitioner, task_group_context& context );
template<typename Range, typename Body>
__TBB_requires(tbb_range<Range> && parallel_reduce_body<Body, Range>)
void parallel_reduce( const Range& range, Body& body, const simple_partitioner& partitioner, task_group_context& context ) {
start_reduce<Range,Body,const simple_partitioner>::run( range, body, partitioner, context );
}
tbb::parallel_reduce 核心思想是把数据范围划分为chunk(chunk本意就是“大块”。一如TBB中的chunk,数据划分的基本单位;或者像是内存管理中的chunk管理堆内存),根据硬件特征或者负载均衡策略,划分为合适的块。标识值(identity value)作为一个body的初始值。每个任务计算部分结果,最后调用归约函数合并结果。
case1
文中一个简单的例子,从一个有16个元素的数组中找最大值。图示如下。
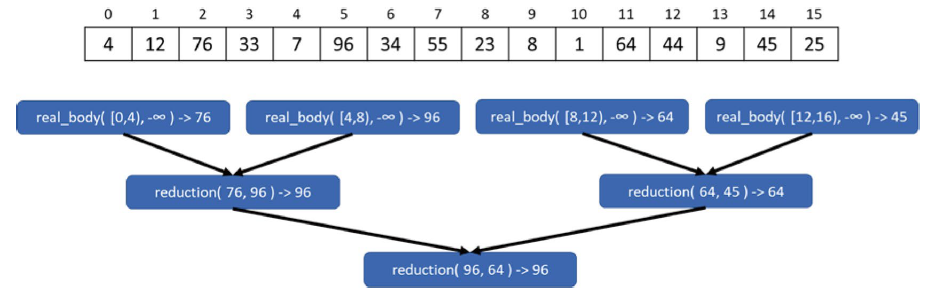
int simpleParallelMax(const std::vector<int>& v) {
int max_value = tbb::parallel_reduce(
/* the range = */ tbb::blocked_range<int>(0, v.size()),
/* identity = */ std::numeric_limits<int>::min(),
/* func = */
[&](const tbb::blocked_range<int>& r, int init) -> int {
for (int i = r.begin(); i != r.end(); ++i) {
init = std::max(init, v[i]);
}
return init;
},
/* reduction = */
[](int x, int y) -> int {
return std::max(x,y);
}
);
return max_value;
}
非常直观且容易理解的例子,分为了三个步骤:
- 分块:使用
tbb::block_range定义数据范围,经由策略划分为块; - 初始值与任务计算:identity value定义为 − ∞ -\infty −∞ ,遍历块内元素,求最大值;
- 任务结果归约:lambda的归约比较返回最大值过程。
对于tbb::parallel_for而言,无需显式构造tbb::blocked_range对象,是单维度顺序遍历的并行化。而tbb::parallel_reduce需要显式传递tbb::blocked_range对象,我们需要去控制范围的分割。
case2
下面是一个略微复杂的例子,通过数值积分的方式去计算
π
\pi
π,就是计算出每个矩形的高度,单位圆四分之一的面积乘以
4
4
4即为圆的面积
π
\pi
π,代码如下。
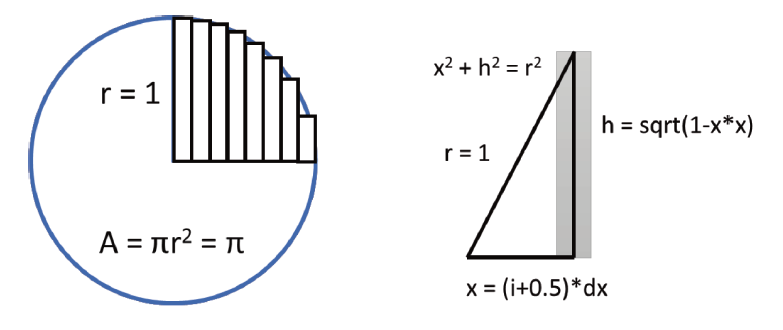
double serialPI(int num_intervals) {
double dx = 1.0 / num_intervals;
double sum = 0.0;
for (int i = 0; i < num_intervals; ++i) {
double x = (i+0.5)*dx;
double h = std::sqrt(1-x*x);
sum += h*dx;
}
double pi = 4 * sum;
return pi;
}
使用tbb:parallel_reduce实现并行化。步骤包括了
- 积分区间划分:将区间 [ 0 , 1 ] [0,1] [0,1]划分为 n u m _ i n t e r v a l s num\_intervals num_intervals 个小区间,每个小区间宽度为 d x = 1.0 / n u m _ i n t e r v a l s dx = 1.0 / num\_intervals dx=1.0/num_intervals;
- 并行计算部分和:每个线程处理一个子区间,计算该子区间内中点处的函数值 ( 1 − x 2 ) \sqrt{(1 - x^2)} (1−x2)乘以 d x dx dx的累加和;
- 归约:将各线程和汇总。
并行代码如下。
double parallelPI(int num_intervals) {
double dx = 1.0 / num_intervals;
double sum = tbb::parallel_reduce(
/* range = */ tbb::blocked_range<int>(0, num_intervals),
/* identity = */ 0.0,
/* func */
[=](const tbb::blocked_range<int>& r, double init) -> double {
for (int i = r.begin(); i != r.end(); ++i) {
double x = (i + 0.5)*dx;
double h = std::sqrt(1 - x*x);
init += h*dx;
}
return init;
},
/* reduction */
[](double x, double y) -> double {
return x + y;
}
);
double pi = 4 * sum;
return pi;
}
本篇主要专注tbb:parallel_reduce算法,遵循一种分治的设计思想,拆解大任务为独立的子任务并行处理,最终通过归约操作合并最终结果。通过tbb::blocked_range动态划分任务粒度,自动平衡负载,使得线程的利用率最大化。tbb::blocked_range默认按照独立内存块划分任务,利用了CPU缓存局部性减少数据访问延迟。我们无需去加锁,其一TBB的任务调度性采用的是无锁机制,其二,连续的内存划分独立任务,每个子任务仅依赖自身数据,避免共享数据的锁需求,其三,归约操作的原子性合并或者无锁任务合并,最后,lambda函数或者仿函数生成副本,又避免多线程修改同一变量。总之,分治模式结合动态负载均衡,以及缓存友好和无锁合并,实现了tbb:parallel_reduce简洁性和高效性,成为一种归约行为下的优秀算法工具。
最后,还有一个tbb::parallel_deterministic_reduce算法。与tbb::parallel_reduce不同的是,它通过强制关联操作确保相同输入数据在同一机器上多次执行时结果一致。这对于需要严格结果验证的场景(如测试、调试)至关重要 。有得必有失,因而tbb::parallel_deterministic_reduce可能会到来些许的性能损失。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









