






访问方法
MySQL服务器在获得SQL语句之后需要对表进行访问
对于查询的讲解都通过如下的建表语句
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
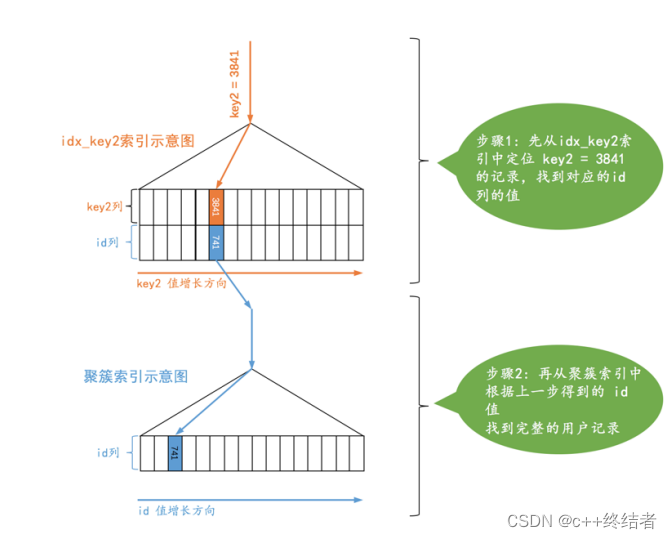
const访问
定义:通过主键列和唯一的二级索引(unique)进行等值查询时通过const方式访问,const访问的时间复杂度是常数级别的(也就是可以忽略的)
ref
定义:通过二级索引(不是unique的index)进行等值查询的方式称为ref访问
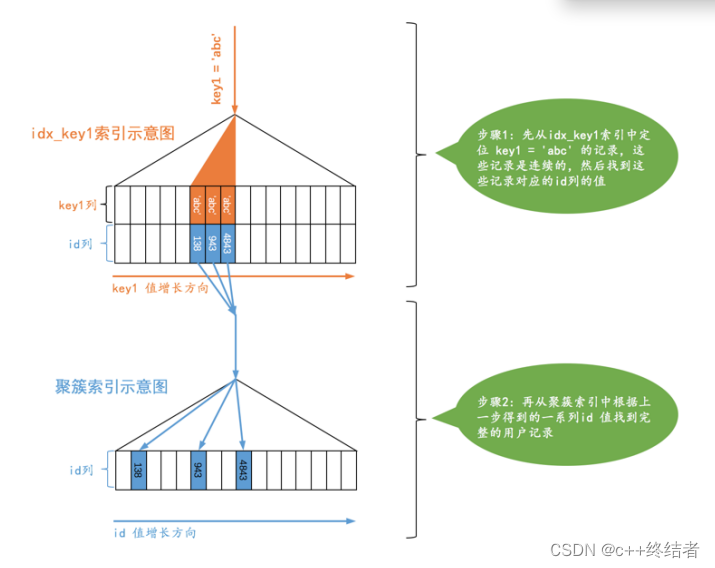
和const访问的区别是可能需要多次回表
ref_or_not_null
定义:在二级索引查询的等值查询基础上还需要对NULL值也一并查询出来,与ref方式无特别大的差别
range
定义:对二级进行范围查询
index
对开始的table执行如下的sql操作
SELECT key_part1, key_part2, key_part3 FROM single_table WHERE key_part2 = 'abc';
虽然key_part2并不是联合索引的最左边节点,但是该SQL满足如下条件
- 欲查询的列都在同一个联合索引
- 搜索条件也在查询列在的联合索引中
对于满足该两个条件的查询,MySQL会直接对联合索引的叶子节点进行挨个比较然后得到结果(由于联合索引的大小比聚簇索引小,所以运行效率高)
all
如果上文的方式都无效只能进行全表扫描
注意事项
- 一般情况下只能利用单个二级索引进行查询,对于下面的查询
SELECT * FROM single_table WHERE key1 = 'abc' AND key2 > 1000;
优化器会识别到查询中的两个条件,一个等值查询,一个范围查询,选择其中比较行数较少的一个二级索引(一般而言等值查询会优于范围查询),然后对这个二级索引进行查询,回表,在回表的过程中对where中的其他条件进行过滤
- 明确range访问的范围
对于一个范围查询和一个不在索引项中的值
若有
SELECT * FROM single_table WHERE key2 > 100 OR common_field = 'abc';
由于common_field并不在索引中,故该查询会被改成
SELECT * FROM single_table WHERE key2 > 100 OR TRUE;
#也就是
SELECT * FROM single_table WHERE TRUE;
如果强制使用key2进行二级索引,那将比全表查询更加慢(多了回表)
索引合并
一次查询一般只用到一个二级索引,但在有些情况下会发生索引合并,具体的有以下三种
intersection合并
对于以下的SQL语句
SELECT * FROM single_table WHERE key1 = 'a' AND key3 = 'b';
如果使用intersection合并,那么流程是
- 分别查询key1和key3的二级索引
- 对这些二级索引进行比较,求出其中主键的交集
- 对这些交集进行回表得到结果
执行intersection的情况
- 二级索引是等值匹配,对于联合索引来说,每个列都必须等值匹配
- 主键列可以是范围匹配
union合并
不同搜索条件之间用OR连接起来并且满足如下的情况才会使用到union合并
- 二级索引是等值匹配的情况,对于联合索引,每个列都必须是等值匹配
- 主键列可以是范围匹配
- 使用intersection索引合并的搜索条件
sort-union合并
对于以下的SQL语句
SELECT * FROM single_table WHERE key1 < 'a' OR key3 > 'z'
这个查询显然不满足上面提到的Union合并的条件,但可以使用sort-union合并
步骤如下
-先根据key1的索引查到满足的二级索引叶节点,再将这些叶节点根据key1排序
- 对key2的索引进行同样的操作
- 再用匹配交集的方式进行回表即可
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









