







数理统计研究的对象是受随机因素影响的数据,以下数理统计就简称统计,统计是以概率论为基础的一门应用学科。 数据样本少则几个,多则成千上万,人们希望能用少数几个包含其多相关信息的数值来体现数据样本总体的规律。
描述性统计就是搜集、整理、加工和分析统计数据, 使之系统化、条理化,以显示出数据资料的趋势、特征和数量关系。它是统计推断的基础,实用性较强,在统计工作中经常使用。 面对一批数据如何进行描述与分析,需要掌握参数估计和假设检验这两个数理统计的基本方法。 我们将用 Matlab 的统计工具箱(Statistics Toolbox)来实现数据的统计描述和分析.
目录
(i)正态分布 (ii) 分布(Chi square) (iii)t分布 (iv)F 分布
1.4.3 Matlab 统计工具箱(Toolbox\Stats)中的概率分布
2.1 点估计 2.2 区间估计 2.3 参数估计的 Matlab 实现
3.1.1 已知 ,关于μ 的检验(Z 检验) 3.1.2 σ未知,关于μ 的检验(t检验)
3.3.1 检验法 3.3.2 偏度、峰度检验(留作习题1)
3.5.1 signrank函数 3.5.2 signtest函数 习题:
统计的基本概念
1.1 总体和样本
总体是人们研究对象的全体,又称母体,如工厂一天生产的全部产品(按合格品及 废品分类),学校全体学生的身高。 总体中的每一个基本单位称为个体,个体的特征用一个变量(如 x)来表示,如一 件产品是合格品记 x=0 ,是废品记 x=1 ;一个身高 170(cm)的学生记 x=170 。
从总体中随机产生的若干个个体的集合称为样本,或子样,如n件产品,100 名学 生的身高,或者一根轴直径的 10 次测量。实际上这就是从总体中随机取得的一批数据, 不妨记作 ,n称为样本容量。 简单地说,统计的任务是由样本推断总体。
1.2 频数表和直方图
一组数据(样本)往往是杂乱无章的,做出它的频数表和直方图,可以看作是对这 组数据的一个初步整理和直观描述。 将数据的取值范围划分为若干个区间,然后统计这组数据在每个区间中出现的次 数,称为频数,由此得到一个频数表。以数据的取值为横坐标,频数为纵坐标,画出一 个阶梯形的图,称为直方图,或频数分布图。
若样本容量不大,能够手工做出频数表和直方图,当样本容量较大时则可以借助 Matlab 这样的软件了。让我们以下面的例子为例,介绍频数表和直方图的作法。
例 1 学生的身高和体重 学校随机抽取 100 名学生,测量他们的身高和体重,所得数据如表1.

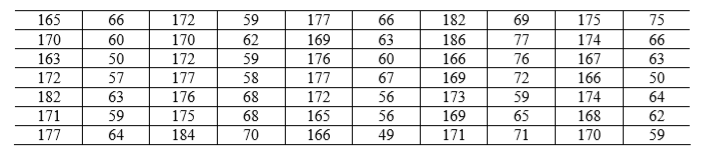
(i) 数据输入
数据输入通常有两种方法,一种是在交互环境中直接输入,如果在统计中数据量比 较大,这样作不太方便;另一种办法是先把数据写入一个纯文本数据文件 data.txt 中, 格式如例 1 的表 1,有 20 行、10 列,数据列之间用空格键或 Tab 键分割,该数据文件 data.txt 存放在 matlab\work 子目录下,在 Matlab 中用 load 命令读入数据,具体作法是:
load data.txt
这样在内存中建立了一个变量 data,它是一个包含有 20× 10个数据的矩阵。 为了得到我们需要的 100 个身高和体重各为一列的矩阵,应做如下的改变:
high=data(:,1:2:9);high=high(:)
weight=data(:,2:2:10);weight=weight(:) (ii)作频数表及直方图
求频数用 hist 命令实现,其用法是: [N,X] = hist(Y,M)
得到数组(行、列均可)Y 的频数表。它将区间[min(Y),max(Y)]等分为 M 份(缺省时 M 设定为 10),N 返回 M 个小区间的频数,X 返回 M 个小区间的中点。
命令 hist(Y,M) 画出数组 Y 的直方图。
对于例 1 的数据,编写程序如下:
load data.txt;
high=data(:,1:2:9);high=high(:);
weight=data(:,2:2:10);weight=weight(:);
[n1,x1]=hist(high)
%下面语句与hist命令等价
%n1=[length(find(high<158.1)),...
% length(find(high>=158.1&high<161.2)),...
% length(find(high>=161.2&high<164.5)),...
% length(find(high>=164.5&high<167.6)),...
% length(find(high>=167.6&high<170.7)),...
% length(find(high>=170.7&high<173.8)),...
% length(find(high>=173.8&high<176.9)),...
% length(find(high>=176.9&high<180)),...
% length(find(high>=180&high<183.1)),...
% length(find(high>=183.1))]
[n2,x2]=hist(weight)
subplot(1,2,1), hist(high)
subplot(1,2,2), hist(weight) 计算结果略,直方图如图 1 所示。

从直方图上可以看出,身高的分布大致呈中间高、两端低的钟形;而体重则看不出 什么规律。要想从数值上给出更确切的描述,需要进一步研究反映数据特征的所谓“统 计量”。直方图所展示的身高的分布形状可看作正态分布,当然也可以用这组数据对分 布作假设检验。
例 2 统计下列五行字符串中字符 a、g、c、t 出现的频数
1.aggcacggaaaaacgggaataacggaggaggacttggcacggcattacacggagg
2.cggaggacaaacgggatggcggtattggaggtggcggactgttcgggga
3.gggacggatacggattctggccacggacggaaaggaggacacggcggacataca
4.atggataacggaaacaaaccagacaaacttcggtagaaatacagaagctta 5.cggctggcggacaacggactggcggattccaaaaacggaggaggcggacggaggc
解 把上述五行复制到一个纯文本数据文件 shuju.txt 中,放在 matlab\work 子目录 下,编写如下程序:
clc
fid1=fopen('shuju.txt','r');
i=1;
while (~feof(fid1))
data=fgetl(fid1);
a=length(find(data==97));
b=length(find(data==99));
c=length(find(data==103));
d=length(find(data==116));
e=length(find(data>=97&data<=122));
f(i,:)=[a b c d e a+b+c+d];
i=i+1;
end
f, he=sum(f)
dlmwrite('pinshu.txt',f); dlmwrite('pinshu.txt',he,'-append');
fclose(fid1); 我们把统计结果后写到一个纯文本文件 pinshu.txt 中,在程序中多引进了几个变 量,是为了检验字符串是否只包含 a、g、c、t 四个字符。
1.3 统计量
假设有一个容量为n 的样本(即一组数据),记作 ,需要对它进 行一定的加工,才能提出有用的信息,用作对总体(分布)参数的估计和检验。统计量 就是加工出来的、反映样本数量特征的函数,它不含任何未知量。 下面我们介绍几种常用的统计量。
(i)表示位置的统计量—算术平均值和中位数

(ii)表示变异程度的统计量—标准差、方差和极差

(iii)中心矩、表示分布形状的统计量—偏度和峰度

在以上用 Matlab 计算各个统计量的命令中,若 x 为矩阵,则作用于 x 的列,返回 一个行向量。
对例 1 给出的学生身高和体重,用 Matlab 计算这些统计量,程序如下:
clc
load data.txt;
high=data(:,1:2:9);high=high(:);
weight=data(:,2:2:10);weight=weight(:);
shuju=[high weight];
jun_zhi=mean(shuju)
zhong_wei_shu=median(shuju)
biao_zhun_cha=std(shuju)
ji_cha=range(shuju)
pian_du=skewness(shuju)
feng_du=kurtosis(shuju)
统计量中重要、常用的是均值和标准差,由于样本是随机变量,它们作为样本的函数自然也是随机变量,当用它们去推断总体时,有多大的可靠性就与统计量的概率 分布有关,因此我们需要知道几个重要分布的简单性质。
1.4 统计中几个重要的概率分布
1.4.1 分布函数、密度函数和分位数

我们前面画过的直方图是频数分布图,频数除以样本容量n,称为频率,n充分大 时频率是概率的近似,因此直方图可以看作密度函数图形的(离散化)近似。
1.4.2 统计中几个重要的概率分布
(i)正态分布

正态分布可以说是常见的(连续型)概率分布,成批生产时零件的尺寸,射击中 弹着点的位置,仪器反复量测的结果,自然界中一种生物的数量特征等,多数情况下都 服从正态分布,这不仅是观察和经验的总结,而且有着深刻的理论依据,即在大量相互独立的、作用差不多大的随机因素影响下形成的随机变量,其极限分布为正态分布。
鉴于正态分布的随机变量在实际生活中如此地常见,记住下面 3 个数字是有用的:

(ii)  分布(Chi square)
分布(Chi square)
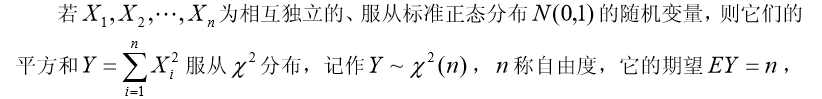
![]()
(iii)t分布

(iv)F 分布

1.4.3 Matlab 统计工具箱(Toolbox\Stats)中的概率分布
Matlab 统计工具箱中有 27 种概率分布,这里只对上面所述 4 种分布列出命令的字 符:
norm 正态分布; chi2 分布(Chi square) ; t t分布 f F 分布
工具箱对每一种分布都提供 5 类函数,其命令的字符是:
pdf 概率密度; cdf 分布函数; inv 分布函数的反函数; stat 均值与方差; rnd 随机数生成
当需要一种分布的某一类函数时,将以上所列的分布命令字符与函数命令字符接起 来,并输入自变量(可以是标量、数组或矩阵)和参数就行了,如:
p=normpdf(x,mu,sigma) //均值 mu、标准差 sigma 的正态分布在 x 的密度函数 (mu=0,sigma=1 时可缺省)。
p=tcdf(x,n) // t分布(自由度 n)在 x 的分布函数。
x=chi2inv(p,n) // 分布(自由度 n)使分布函数 F(x)=p 的 x(即 p 分位数)。
[m,v]=fstat(n1,n2) // F 分布(自由度 n1,n2)的均值 m 和方差 v。
几个分布的密度函数图形就可以用这些命令作出,如:
x=-6:0.01:6; y=normpdf(x); z=normpdf(x,0,2);
plot(x,y,x,z),gtext('N(0,1)'),gtext('N(0,2^2)')
分布函数的反函数的意义从下例看出:

1.5 正态总体统计量的分布
用样本来推断总体,需要知道样本统计量的分布,而样本又是一组与总体同分布的随机变量,所以样本统计量的分布依赖于总体的分布。当总体服从一般的分布时,求某个样本统计量的分布是很困难的,只有在总体服从正态分布时,一些重要的样本统计量 (均值、标准差)的分布才有便于使用的结果。另一方面,现实生活中需要进行统计推 断的总体,多数可以认为服从(或近似服从)正态分布,所以统计中人们在正态总体的假定下研究统计量的分布,是必要的与合理的。

2 参数估计

2.1 点估计

2.2 区间估计


2.3 参数估计的 Matlab 实现
Matlab 统计工具箱中,有专门计算总体均值、标准差的点估计和区间估计的函数。 对于正态总体,命令是
[mu,sigma,muci,sigmaci]=normfit(x,alpha)
其中 x 为样本(数组或矩阵),alpha 为显著性水平 α (alpha 缺省时设定为 0.05),返 回总体均值 μ 和标准差 σ 的点估计 mu 和 sigma,及总体均值 μ 和标准差 σ 的区间估计 muci 和 sigmaci。当 x 为矩阵时,x 的每一列作为一个样本。
Matlab 统计工具箱中还提供了一些具有特定分布总体的区间估计的命令,如 expfit,poissfit,gamfit,你可以从这些字头猜出它们用于哪个分布,具体用法参见 帮助系统。
3 假设检验
统计推断的另一类重要问题是假设检验问题。在总体的分布函数完全未知或只知其 形式但不知其参数的情况,为了推断总体的某些性质,提出某些关于总体的假设。例如, 提出总体服从泊松分布的假设,又如对于正态总体提出数学期望等于 0 μ 的假设等。假设检验就是根据样本对所提出的假设做出判断:是接受还是拒绝。这就是所谓的假设检 验问题
3.1 单个总体  均值μ 的检验
均值μ 的检验
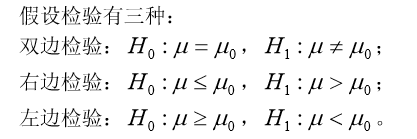
3.1.1 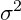 已知,关于μ 的检验(Z 检验)
已知,关于μ 的检验(Z 检验)

例 3 某车间用一台包装机包装糖果。包得的袋装糖重是一个随机变量,它服从正 态分布。当机器正常时,其均值为 0.5 公斤,标准差为 0.015 公斤。某日开工后为检验 包装机是否正常,随机地抽取它所包装的糖 9 袋,称得净重为(公斤): 0.497 0.506 0.518 0.524 0.498 0.511 0.520 0.515 0.512 问机器是否正常?
Matlab 实现如下:
x=[0.497 0.506 0.518 0.524 0.498...
0.511 0.520 0.515 0.512];
[h,p,ci]=ztest(x,0.5,0.015) 求得 h=1,p=0.0248,说明在 0.05 的水平下,可拒绝原假设,即认为这天包装机 工作不正常。
3.1.2 σ未知,关于μ 的检验(t检验)


x=[159 280 101 212 224 379 179 264 ...
222 362 168 250 149 260 485 170];
[h,p,ci]=ttest(x,225,0.05,1) 求得 h=0,p=0.2570,说明在显著水平为 0.05 的情况下,不能拒绝原假设,认为 元件的平均寿命不大于 225 小时。
3.2 两个正态总体均值差的检验(t检验)
还可以用t检验法检验具有相同方差的 2 个正态总体均值差的假设。在 Matlab 中 由函数 ttest2 实现,命令为:
[h,p,ci]=ttest2(x,y,alpha,tail)
与上面的 ttest 相比,不同处只在于输入的是两个样本 x,y(长度不一定相同), 而不是一个样本和它的总体均值;tail 的用法与 ttest 相似,可参看帮助系统。

x=[78.1 72.4 76.2 74.3 77.4 78.4 76.0 75.6 76.7 77.3];
y=[79.1 81.0 77.3 79.1 80.0 79.1 79.1 77.3 80.2 82.1];
[h,p,ci]=ttest2(x,y,0.05,-1) 
3.3 分布拟合检验
在实际问题中,有时不能预知总体服从什么类型的分布,这时就需要根据样本来检 验关于分布的假设。下面介绍 检验法和专用于检验分布是否为正态的“偏峰、峰度 检验法”。
3.3.1 检验法

例 6 下面列出了 84 个伊特拉斯坎(Etruscan)人男子的头颅的大宽度(mm), 试检验这些数据是否来自正态总体(取 )
141 148 132 138 154 142 150 146 155 158 150 140 147 148 144 150 149 145 149 158 143 141 144 144 126 140 144 142 141 140 145 135 147 146 141 136 140 146 142 137 148 154 137 139 143 140 131 143 141 149 148 135 148 152 143 144 141 143 147 146 150 132 142 142 143 153 149 146 149 138 142 149 142 137 134 144 146 147 140 142 140 137 152 145
解 编写 Matlab 程序如下:
clc
x=[141 148 132 138 154 142 150 146 155 158 ...
150 140 147 148 144 150 149 145 149 158 ...
143 141 144 144 126 140 144 142 141 140 ...
145 135 147 146 141 136 140 146 142 137 ...
148 154 137 139 143 140 131 143 141 149 ...
148 135 148 152 143 144 141 143 147 146 ...
150 132 142 142 143 153 149 146 149 138 ...
142 149 142 137 134 144 146 147 140 142 ...
140 137 152 145];
mm=minmax(x) %求数据中的小数和大数
hist(x,8) %画直方图
fi=[length(find(x<135)),...
length(find(x>=135&x<138)),...
length(find(x>=138&x<142)),...
length(find(x>=142&x<146)),...
length(find(x>=146&x<150)),...
length(find(x>=150&x<154)),...
length(find(x>=154))] %各区间上出现的频数
mu=mean(x),sigma=std(x) %均值和标准差
fendian=[135,138,142,146,150,154] %区间的分点
p0=normcdf(fendian,mu,sigma) %分点处分布函数的值
p1=diff(p0) %中间各区间的概率
p=[p0(1),p1,1-p0(6)] %所有区间的概率
chi=(fi-84*p).^2./(84*p)
chisum=sum(chi) %皮尔逊统计量的值
x_a=chi2inv(0.9,4) %chi2分布的0.9分位数 
3.3.2 偏度、峰度检验(留作习题1)
3.4 其它非参数检验
Matlab还提供了一些非参数方法。
3.4.1 Wilcoxon秩和检验

例7 某商店为了确定向公司 A或公司B 购买某种产品,将 A, B公司以往各次进 货的次品率进行比较,数据如下所示,设两样本独立。问两公司的商品的质量有无显著 差异。设两公司的商品的次品的密度多只差一个平移,取

求得p=0.8041,h=0,表明两样本总体均值相等的概率为0.8041,并不很接近于零, 且h=0说明可以接受原假设,即认为两个公司的商品的质量无明显差异。
3.5 中位数检验
在假设检验中还有一种检验方法为中位数检验,在一般的教学中不一定介绍,但在 实际中也是被广泛应用到的。在Matlab中提供了这种检验的函数。函数的使用方法简单, 下面只给出函数介绍。
3.5.1 signrank函数

3.5.2 signtest函数

习题:
















 3351
3351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









