









基于Springboot的Elasticsearch8.1.3的JavaAPI操作
JavaAPI操作Elasticsearch
最新8.13版本Elasticsearch和Kibana的安装使用
突然发现es最新的client已经更新到了8.1.3,于是本人怒从心头起,恶向胆边生。tmd劳资就是要整最新的!!!!
下载安装
折腾了好一会子,终于把最新的es数据库和kibana安装配置完成了
下载地址:https://www.elastic.co/cn/start
Elasticsearch配置
踩到的坑,由于8.1.3版本新增了几个配置参数,默认没改动,然后启动后死活连不上数据库,报错如下:
[WARN ][o.e.x.s.t.n.SecurityNetty4HttpServerTransport] [es-node0] received plaintext http traffic on an https channel, closing connection Netty4HttpChannel{localAddress=/192.168.0.184:9200, remoteAddress=/192.168.0.146:51975}
解决方案:
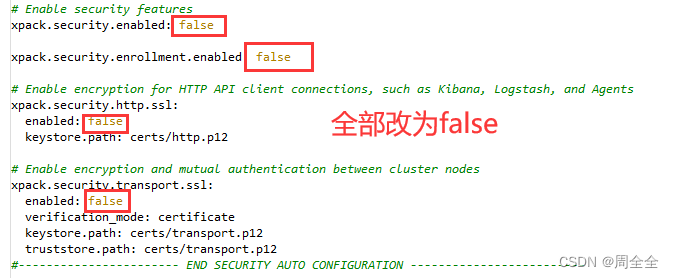
elasticsearch.yml
# Enable security features
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
# Enable encryption for HTTP API client connections, such as Kibana, Logstash, and Agents
xpack.security.http.ssl:
enabled: false
keystore.path: certs/http.p12
# Enable encryption and mutual authentication between cluster nodes
xpack.security.transport.ssl:
enabled: false
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
#----------------------- END SECURITY AUTO CONFIGURATION -------------------------
#默认的集群名称,在集群配置多个节点时需要保持一致,单机可暂不关注
cluster.name: elasticsearch
node.name: es-node0
cluster.initial_master_nodes: ["es-node0"]
# 指定数据存储位置
path.data: /usr/local/software/elasticsearch-8.1.3/data
#日志文件位置
path.logs: /usr/local/software/elasticsearch-8.1.3/logs
#默认只允许本机访问,修改为0.0.0.0后则可以允许任何ip访问
network.host: 0.0.0.0
#设置http访问端口,9200是http协议的RESTful接口,注意端口冲突可修改
http.port: 9200
# 跨域问题配置
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
Kibana配置
kibana.yml
server.host: "192.168.0.184"
elasticsearch.hosts: ["http://192.168.0.184:9200"]
i18n.locale: "zh-CN"
es和kibana的前台启动:
注意:ctrl+c后会退出!
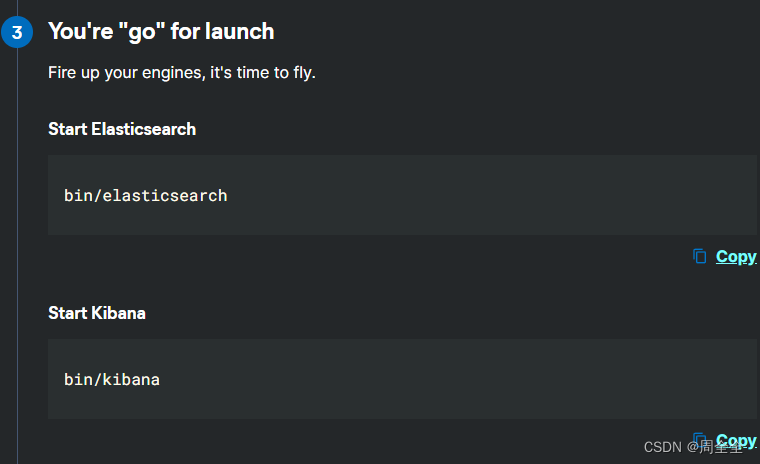
es和kibana的后台启动
以下脚本写完自测可以执行。
注意所属组和可执行权限问题,脚本放置与bin同级目录
es自定义后台启动与关闭脚本:
startes-single.sh
cd /usr/local/software/elasticsearch-7.6.1
./bin/elasticsearch -d -p pid
stopes-single.sh
cd /usr/local/software/elasticsearch-7.6.1
if [ -f "pid" ]; then
pkill -F pid
fi
kibanas自定义后台启动与关闭脚本
【注意:Kibana不建议使用root用户直接运行,如使用root,需加上–allow-root。建议新建普通用户,使用普通用户运行。】
(喵个咪,脚本懂得不多,还专门学了好一会子才写出来)
start-kibana.sh
#首先判断是否已经启动kibana
mypid=$(netstat -tunlp|grep 5601|awk '{print $7}'|cut -d/ -f1);
if [ -n "$mypid" ];then
echo ${mypid}" listening on port 5601,it is being killed !!!"
kill -9 $mypid
fi
echo ${mypid}" kibana is being start ..."
cd /usr/local/software/kibana-7.8.0-linux-x86_64/bin
nohup ./kibana > myout.log 2>&1 &
stop-kibana.sh
#杀死特定端口进程
mypid=$(netstat -tunlp|grep 5601|awk '{print $7}'|cut -d/ -f1);
if [ -z "$mypid" ];then
echo "No process is listening on port 5601"
fi
if [ -n "$mypid" ];then
echo ${mypid}" is being killed!!!!"
fi
kill -9 $mypid
结束脚本的语句分解:

Spring项目配置启动
Maven configuration (依赖配置)
这里配置es官方文档客户端和es库的依赖,注意版本要与es数据库的保持一致!
<!-- 引入和数据库版本相同的依赖 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>8.1.3</version>
</dependency>
<!-- 8.1版本官方推荐的elasticsearch 的客户端 -->
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.1.3</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>
<!-- Needed only if you use the spring-boot Maven plugin -->
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.0.1</version>
</dependency>
Initialization (初始化项目)
A RestHighLevelClient instance needs a REST low-level client builder to be built as follows:
官网给出的快速使用client的示例:
// Create the low-level client
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200)).build();
// Create the transport with a Jackson mapper
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// And create the API client
ElasticsearchClient client = new ElasticsearchClient(transport);
这里本人将RestHighLevelClient交给spring管理,在使用时直接注入即可
-
项目架构
-
配置类源码
package com.zhou.config;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author zhouquan
* @description ElasticSearchClient配置类
* @date 2022-05-02 17:28
**/
@Configuration
public class ElasticSearchClientConfig {
/**
* @deprecated 7.6版本的
* @return
*/
// @Bean
// public RestHighLevelClient restHighLevelClient() {
// RestHighLevelClient client = new RestHighLevelClient(
// RestClient.builder(
// new HttpHost("192.168.0.184", 9200, "http")));
//
// return client;
// }
/**
* 8.13版本
* @return
*/
@Bean
public ElasticsearchClient elasticsearchClient() {
// Create the low-level client
RestClient restClient = RestClient.builder(
new HttpHost("192.168.0.184", 9200)).build();
// Create the transport with a Jackson mapper
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// And create the API client
ElasticsearchClient client = new ElasticsearchClient(transport);
return client;
}
}
- 测试类源码
package com.zhou;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch.indices.CreateIndexResponse;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
import java.io.IOException;
/**
* @author zhouquan
* @description todo
* @date 2022-05-02 10:06
**/
@SpringBootTest
public class ElasticSearchTest {
@Resource
private ElasticsearchClient client;
/**
* 创建索引
* @throws IOException
*/
@Test
void createIndex() throws IOException {
CreateIndexResponse products = client.indices().create(c -> c.index("products"));
System.out.println(products.acknowledged());
}
}
4.pojo类源码
package com.zhou.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.stereotype.Component;
import java.io.Serializable;
/**
* @author zhouquan
* @description 测试pojo类
* @date
**/
@Component
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Product implements Serializable {
private String name;
private String sku;
private Double price;
}
Java操作ES(参照官方文档)
创建索引
/**
* 创建索引
*
* @throws IOException
*/
@Test
void createIndex() throws IOException {
//这种方式使用了Effective Java 中推广的构建器模式,但是必须实例化构建器类并调用 build ()方法有点冗长
CreateIndexResponse createResponse = client.indices().create(
new CreateIndexRequest.Builder()
.index("my-index")
.aliases("foo", new Alias.Builder().isWriteIndex(true).build())
.build()
);
/*(推荐)
So every property setter in the Java API Client also accepts a lambda expression
that takes a newly created builder as a parameter and returns a populated builder.
javaapi Client 中的每个属性 setter 也接受一个 lambda 表达式,
该表达式接受一个新创建的构建器作为参数,并返回一个填充的构建器
*/
CreateIndexResponse products = client.indices().create(c -> c
.index("my-index")
.aliases("zhouquan", a -> a.isWriteIndex(true))
);
System.out.println(products.acknowledged());
}
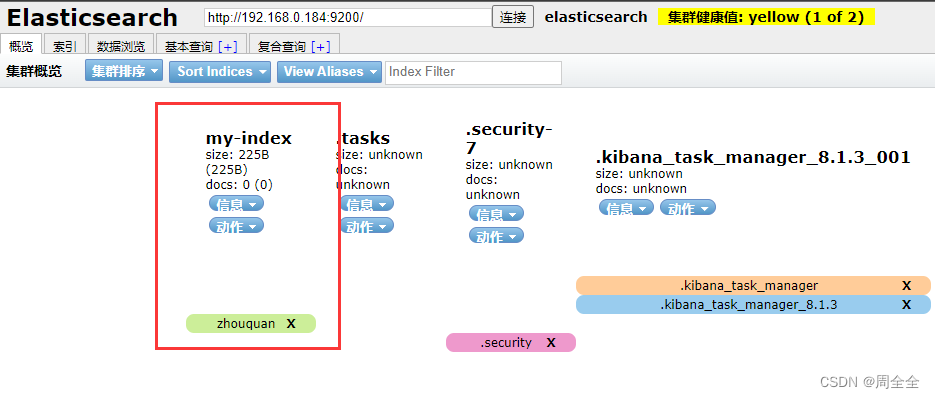
创建多个索引并同时增加文档记录
/**
* Bulk: indexing multiple documents
* 批量创建多个索引文档
*
* @throws IOException
*/
@Test
void createBulkIndex() throws IOException {
/*
A BulkRequest contains a collection of operations, each operation being a type with several variants.
To create this request, it is convenient to use a builder object for the main request,
and the fluent DSL for each operation.
BulkRequest 包含一组操作,每个操作都是一个具有多个变量的类型。
为了创建这个请求,对主请求使用 builder 对象和对每个操作使用 fluent DSL 是很方便的。
*/
List<Product> products = Arrays.asList(
new Product("city bike", "bk-1", 100.5),
new Product("mount bike", "bk-2", 588D),
new Product("wild bike", "bk-3", 9999D));
BulkRequest.Builder builder = new BulkRequest.Builder();
for (Product product : products) {
builder.operations(op -> op
.index(idx -> idx
.index("products")
.id(product.getSku())
.document(product))
);
}
BulkResponse bulkResponse = client.bulk(builder.build());
// Log errors, if any
if (bulkResponse.errors()) {
log.error("Bulk had errors");
for (BulkResponseItem item: bulkResponse.items()) {
if (item.error() != null) {
log.error(item.error().reason());
}
}
}
@Data
class Product {
public String name;
public String sku;
public Double price;
public Product(String name, String sku, Double price) {
this.name = name;
this.sku = sku;
this.price = price;
}
}
索引创建成功
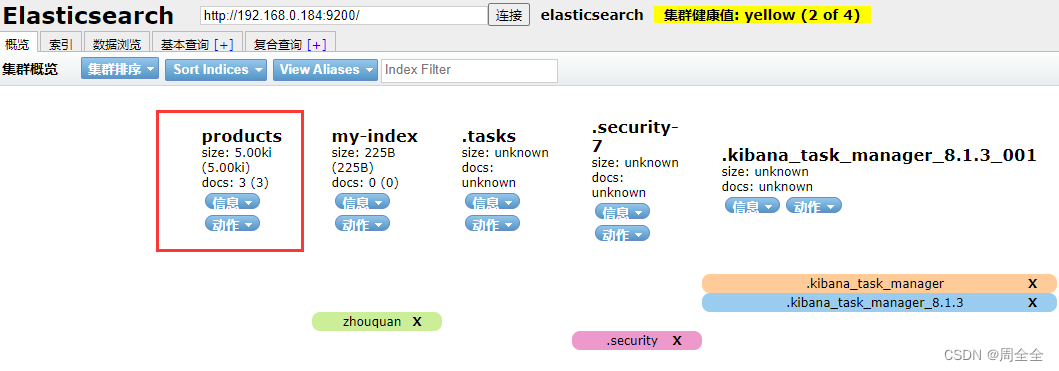
数据查询
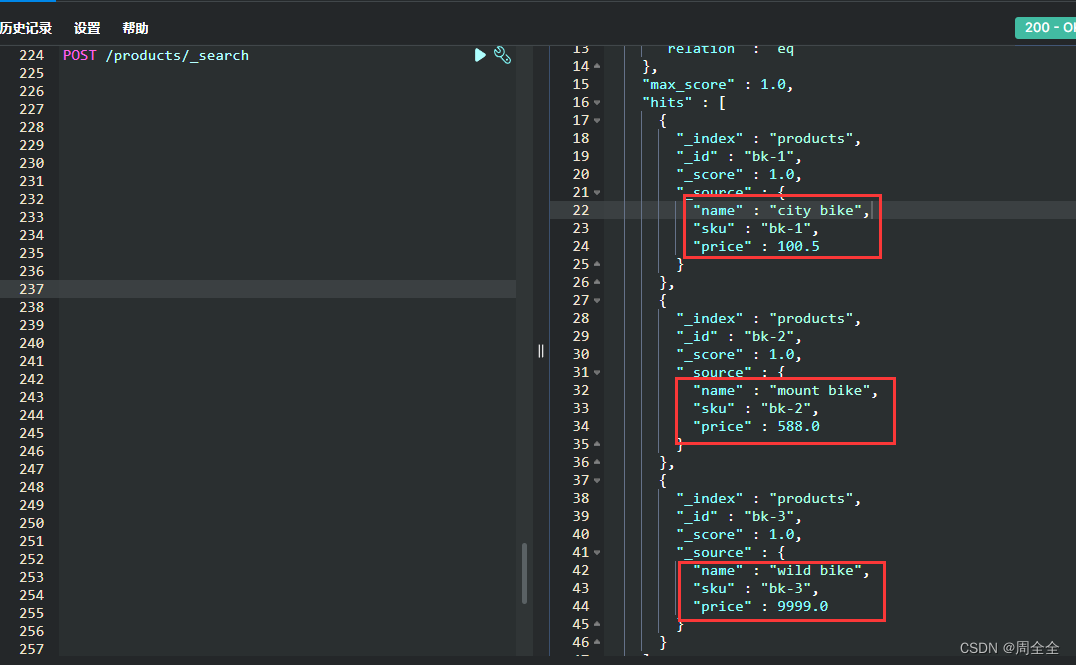
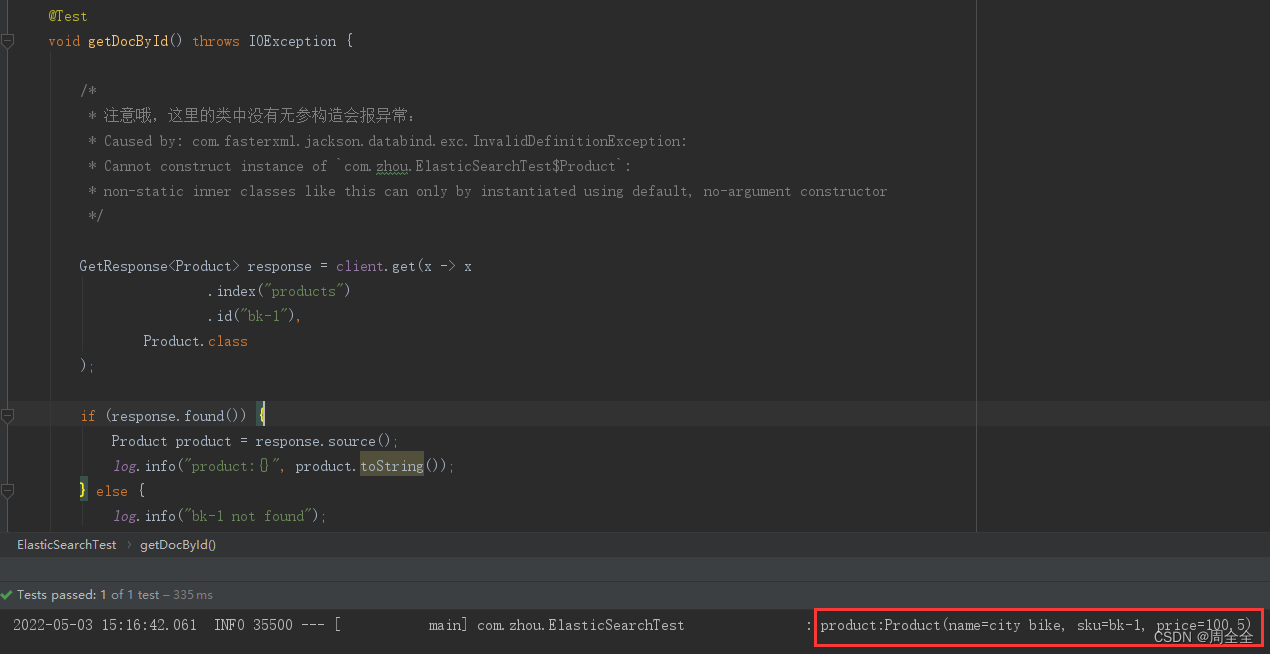
根据id查询文档并装载到对象中
/**
* Reading documents by id
* 直接根据id获取文档
*
* @throws IOException
*/
@Test
void getDocById() throws IOException {
/*
* 注意哦,这里的类中没有无参构造会报异常:
* Caused by: com.fasterxml.jackson.databind.exc.InvalidDefinitionException:
* Cannot construct instance of `com.zhou.ElasticSearchTest$Product`:
* non-static inner classes like this can only by instantiated using default, no-argument constructor
*/
GetResponse<Product> response = client.get(x -> x
.index("products")
.id("bk-1"),
Product.class
);
if (response.found()) {
Product product = response.source();
log.info("product:{}", product.toString());
} else {
log.info("bk-1 not found");
}
}
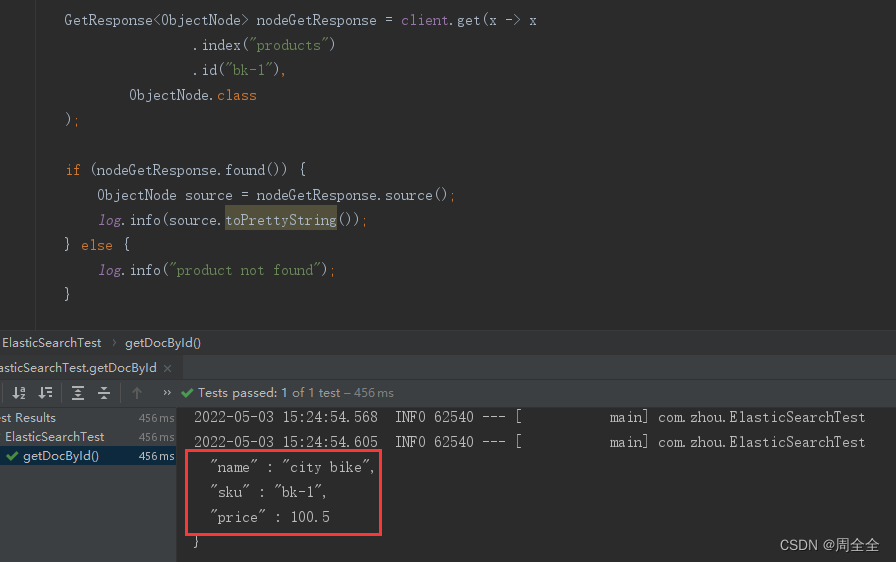
根据id查询文档输出为json
- Raw JSON data is just another class that you can use as the result type for the get request. In the example below we use Jackson’s ObjectNode. We could also have used any JSON representation that can be deserialized by the JSON mapper associated to the ElasticsearchClient.
原始 JSON 数据只是另一个类,您可以使用它作为 get 请求的结果类型。在下面的示例中,我们使用 Jackson 的 ObjectNode。我们还可以使用任何可以由与 ElasticsearchClient 关联的 JSON 映射器反序列化的 JSON 表示。
GetResponse<ObjectNode> nodeGetResponse = client.get(x -> x
.index("products")
.id("bk-1"),
ObjectNode.class
);
if (nodeGetResponse.found()) {
ObjectNode source = nodeGetResponse.source();
log.info(source.toPrettyString());
} else {
log.info("product not found");
}
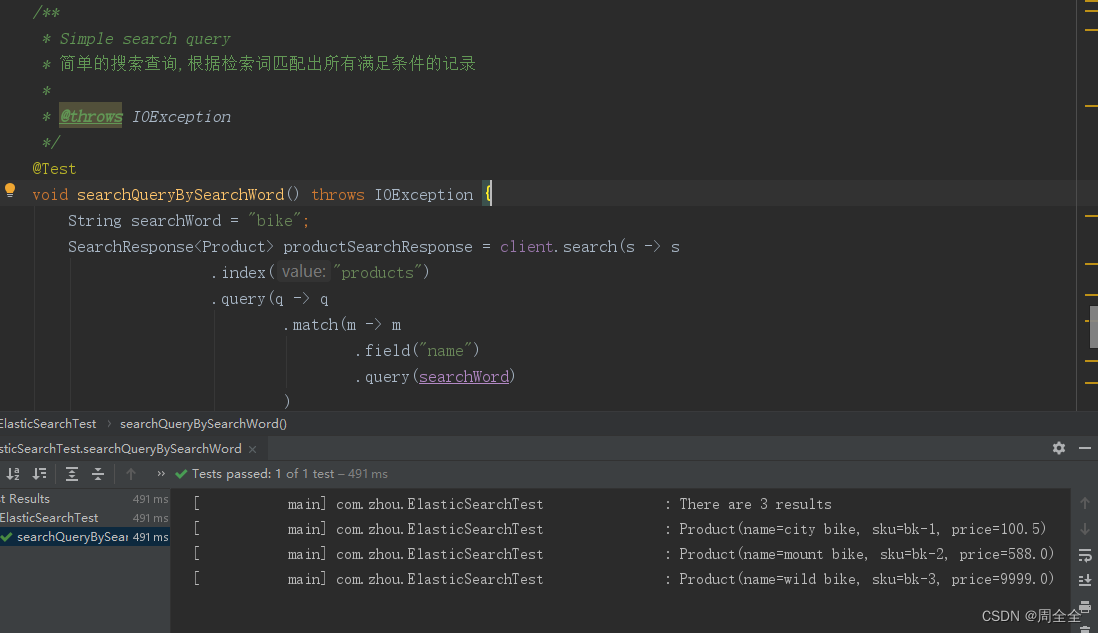
Simple search query 简单的搜索查询
There are many types of search queries that can be combined. We will start with the simple text match query, searching for bikes in the products index.
有许多类型的搜索查询可以组合在一起。我们将从简单的文本匹配查询开始,在产品索引中搜索自行车。
/**
* Simple search query
* 简单的搜索查询,根据检索词匹配出所有满足条件的记录
*
* @throws IOException
*/
@Test
void searchQueryBySearchWord() throws IOException {
String searchWord = "bike";
SearchResponse<Product> productSearchResponse = client.search(s -> s
.index("products")
.query(q -> q
.match(m -> m
.field("name")
.query(searchWord)
)
),
Product.class
);
TotalHits total = productSearchResponse.hits().total();
boolean isExactResult = total.relation() == TotalHitsRelation.Eq;
if (isExactResult) {
log.info("There are " + total.value() + " results");
} else {
log.info("There are more than " + total.value() + " results");
}
//遍历查询出来的数据
productSearchResponse.hits().hits().stream().forEach(x -> log.info(x.source().toString()));
}
Nested search queries 嵌套搜索查询
Elasticsearch allows individual queries to be combined to build more complex search requests. In the example below we will search for bikes with a maximum price of 1000.
Elasticsearch 允许将单个查询组合起来,以构建更复杂的搜索请求。在下面的例子中,我们将搜索自行车的最高价格大于1000。
/**
* Nested search queries 嵌套搜索查询
* 匹配出满足name为bike且价格高于1000的数据
*
* @throws IOException
*/
@Test
void nestedQuery() throws IOException {
String searchWord = "bike";
double price = 1000D;
//全文匹配“name”字段包含检索词“bike”
Query matchQuery = MatchQuery.of(m -> m
.field("name")
.query(searchWord)
)._toQuery();
//范围匹配“price”字段大于1000
Query rangeQuery = RangeQuery.of(r -> r
.field("price")
// Elasticsearch range query accepts a large range of value types.
// We create here a JSON representation of the maximum price.
.gt(JsonData.of(price))
)._toQuery();
SearchResponse<Product> productSearchResponse = client.search(s -> s
.index("products") //Name of the index we want to search.
.query(q -> q
//The search query is a boolean query that combines the text search and max price queries.
.bool(b -> b
//Both queries are added as must as we want results to match all criteria.
.must(matchQuery, rangeQuery)
)
),
Product.class
);
TotalHits total = productSearchResponse.hits().total();
boolean isExactResult = total.relation() == TotalHitsRelation.Eq;
if (isExactResult) {
log.info("There are " + total.value() + " results");
} else {
log.info("There are more than " + total.value() + " results");
}
//遍历查询出来的数据
productSearchResponse.hits().hits().stream().forEach(x -> log.info(x.source().toString()));
}

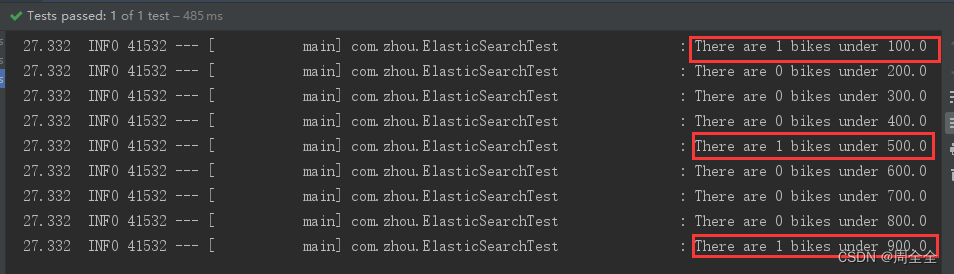
simple aggregation query 简单的聚合查询
此处的需求为:根据名称字段与用户提供的文本匹配的产品创建一个产品索引的价格直方图
/**
* A simple aggregation 一个简单的聚合
* 匹配出满足name为bike且价格高于1000的数据
*
* @throws IOException
*/
@Test
void aggregationQuery() throws IOException {
String searchText = "bike";
Query query = MatchQuery.of(m -> m
.field("name")
.query(searchText)
)._toQuery();
SearchResponse<Void> response = client.search(b -> b
.index("products")
.size(0)/* Set the number of matching documents to zero as we only use the price histogram.
将原始数据返回设置为零,因为我们只是用价格直方图 */
.query(query)
/* Create an aggregation named "price-histogram". You can add as many named aggregations as needed.
创建一个名为“价格直方图”的聚合,可以根据需要添加任意多的命名聚合。*/
.aggregations("price-histogram", a -> a
.histogram(h -> h
.field("price")
.interval(100.0)
)
),
Void.class //We do not care about matches (size is set to zero), using Void will ignore any document in the response.
);
List<HistogramBucket> buckets = response.aggregations()
.get("price-histogram")
.histogram() //Cast it down to the histogram variant results. This has to be consistent with the aggregation definition.
.buckets().array(); //Bucket 可以表示为数组或映射,这将强制转换为数组变量(默认值)。
//遍历输出
buckets.stream().forEach(bucket -> log.info("There are " + bucket.docCount() + " bikes under " + bucket.key()));
}
















 2485
2485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











