







Elasticsearch Suggesters API详解与联想词自动补全应用
引言
在现代搜索引擎的应用场景中,自动补全和拼写检查已成为提升用户搜索体验的重要功能Elasticsearch 作为一款广泛使用的分布式搜索引擎,提供了丰富的 Suggesters API,可以帮助开发者实现精确的自动补全和拼写纠错功能本文将深入探讨 Elasticsearch 中的四种核心 Suggester——Term Suggester、Phrase Suggester、Completion Suggester 和 Context Suggester,并通过实际示例展示如何在不同场景下使用这些工具来优化用户的搜索体验
Elasticsearch Suggesters
参考官网:[Suggesters | Elasticsearch Guide 7.17] | Elastic
1. Term Suggester
Term Suggester 主要用于单个词的拼写纠错它通过编辑距离算法,在用户输入的词不存在于索引中时,提供一系列可能的正确拼写Term Suggester 不仅可以返回建议词,还可以显示每个建议词的得分和词频
实现步骤
- 创建索引并插入数据:确保索引中存在需要搜索的字段
- 发送 Suggest 请求:在 Elasticsearch 的
_search端点发送一个包含suggest字段的请求
示例
POST /zhoutest/_search
{
"suggest": {
"my_suggestion": {
"text": "hots vlna",
"term": {
"field": "content"
}
}
}
}
在这个例子中,用户输入了错误的短语 hots vlna,Term Suggester 会建议正确的拼写,比如 hot 或 volna
2. Phrase Suggester
Phrase Suggester 在 Term Suggester 的基础上更进一步,它可以处理整个短语的拼写纠错Phrase Suggester 考虑了多个词之间的关系,如它们是否同时出现在索引中,以及它们之间的词频和相邻程度
示例
POST /zhoutest/_search
{
"suggest": {
"my_suggestion": {
"text": "lucne and elasticsearch rock",
"phrase": {
"field": "body",
"highlight": {
"pre_tag": "<em>",
"post_tag": "</em>"
}
}
}
}
}
在这个例子中,Phrase Suggester 会识别 lucne 可能是拼写错误,建议改为 lucene,并对其进行高亮显示
3. Completion Suggester
Completion Suggester 专用于快速的前缀搜索和自动补全它通过将分词后的数据编码成 FST(Finite State Transducer)并存储在内存中,以实现极快的查询速度Completion Suggester 非常适用于需要即时反馈的场景,如搜索框的自动补全功能
创建映射和插入数据
首先,需要定义字段类型为 completion 的映射:
PUT localhost:9200/zhoutest/test/_mapping
{
"test": {
"properties": {
"name_suggest": {
"type": "completion",
"analyzer": "simple",
"search_analyzer": "simple",
"payloads": true
}
}
}
}
接着插入数据:
PUT 'localhost:9200/zhoutest/test/1?refresh=true'
{
"name": "xdy",
"name_suggest": {
"input": ["xdy", "hdu"]
}
}
查询示例
POST 'localhost:9200/zhoutest/_suggest?pretty'
{
"index-suggest": {
"text": "b",
"completion": {
"field": "name_suggest"
}
}
}
当用户输入 b 时,Completion Suggester 会返回以 b 开头的建议词,如 banana 或 bicycle
4. Context Suggester
Context Suggester 允许基于上下文(如类别或地理位置)提供更精确的建议它能够提高搜索建议的准确性和相关性,适合需要根据用户输入环境来调整建议结果的场景
示例
假设有一个应用程序需要基于用户的地理位置提供建议,可以这样配置 Context Suggester:
PUT /zhoutest
{
"mappings": {
"properties": {
"suggest": {
"type": "completion",
"contexts": [
{ "name": "location", "type": "geo" }
]
}
}
}
}
然后可以插入数据并执行查询,基于用户的地理位置提供更精确的推荐
Completion Suggester
Completion Suggester 是 Elasticsearch 中的一种专用于实现前缀搜索和自动补全功能的 Suggester它通过将数据编码为 FST(有限状态转换器),并将其存储在内存中,从而提供极快的查询速度,非常适用于需要即时反馈的场景,如搜索框的自动补全功能
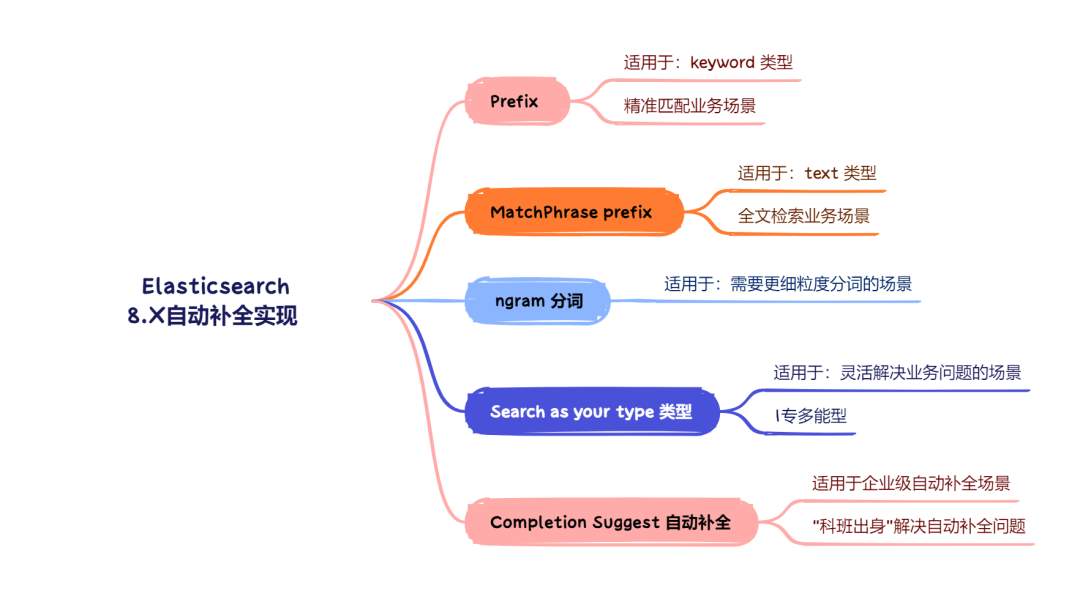
1. 工作原理
Completion Suggester 的核心是 FST,它是一种压缩的有限状态机,能够快速地匹配前缀并生成补全建议FST 具备以下特性:
- 前缀匹配:通过编码词汇表中的所有前缀,FST 能够迅速找到与用户输入匹配的前缀并返回相应的候选项
- 压缩存储:FST 在存储时会自动去除重复前缀,从而显著降低内存占用
- 即时查询:由于 FST 是内存中操作的,查询速度非常快,能够实时提供搜索建议
2. 使用流程
2.1 创建索引与映射
在使用 Completion Suggester 之前,需要为数据创建索引,并在索引的映射中定义字段类型为 completion可以选择设置 analyzer 和 search_analyzer 来控制数据如何被分析
示例:
PUT /zhoutest
{
"mappings": {
"properties": {
"name_suggest": {
"type": "completion"
}
}
}
}
2.2 插入数据
定义好索引映射后,可以向索引中插入数据需要确保将希望进行补全建议的字段作为 input 提供给 completion 类型字段
示例:
PUT /zhoutest/_doc/1
{
"name": "Elasticsearch",
"name_suggest": {
"input": ["Elasticsearch", "Elastic"]
}
}
PUT /zhoutest/_doc/2
{
"name": "Elastic Stack",
"name_suggest": {
"input": ["Elastic Stack", "ELK Stack"]
}
}
在以上示例中,我们为每个文档提供了多个输入选项,用于在用户输入时提供不同的补全建议
2.3 查询建议
插入数据后,可以使用 Completion Suggester 进行查询查询请求会根据用户输入的文本前缀,返回匹配的建议
示例:
POST /zhoutest/_search
{
"suggest": {
"name_suggestion": {
"prefix": "Elas", // 用户输入的前缀
"completion": {
"field": "name_suggest", // 指定补全字段
"size": 5, // 返回的建议数量
"fuzzy": { // 启用模糊搜索,允许拼写错误
"fuzziness": 2
}
}
}
}
}
在这个示例中,用户输入了前缀 Elas,Completion Suggester 会返回与该前缀匹配的词汇,如 Elasticsearch 或 Elastic Stack
2.4 响应结果
查询结果会返回与输入前缀匹配的建议列表,每个建议包含了补全的文本以及其他元数据(如得分、频率等)
示例:
{
"suggest": {
"name_suggestion": [
{
"text": "Elas",
"offset": 0,
"length": 4,
"options": [
{
"text": "Elasticsearch",
"score": 1.0
},
{
"text": "Elastic Stack",
"score": 1.0
}
]
}
]
}
}
3. 使用建议和优化
- 字段优化:在定义
completion类型字段时,合理选择分析器和映射配置,可以优化查询的性能和结果质量 - 模糊匹配:如果需要容忍拼写错误,可以启用
fuzzy配置,允许模糊匹配提升用户使用 - 内存使用:由于 FST 存储在
内存中,建议在高并发或大规模数据场景下,合理配置内存,以确保系统的稳定性
4. 单节点使用优化
如果在单节点数据量较大并且设置的补全字段较多的时候,可能会导致下列报错:
[ERROR][o.e.b.ElasticsearchUncaughtExceptionHandler] [test_node1] fatal error in thread [elasticsearch[test_node1][management][T#1]], exiting
java.lang.OutOfMemoryError: Java heap space
at org.apache.lucene.util.fst.OnHeapFSTStore.init(OnHeapFSTStore.java:59) ~[lucene-core-8.6.2.jar:8.6.2 016993b65e393b58246d54e8ddda9f56a453eb0e - ivera - 2020-08-26 10:53:36]
at org.apache.lucene.util.fst.FST.<init>(FST.java:461) ~[lucene-core-8.6.2.jar:8.6.2 016993b65e393b58246d54e8ddda9f56a453eb0e - ivera - 2020-08-26 10:53:36]
at org.apache.lucene.util.fst.FST.<init>(FST.java:412) ~[lucene-core-8.6.2.jar:8.6.2 016993b65e393b58246d54e8ddda9f56a453eb0e - ivera - 2020-08-26 10:53:36]
at org.apache.lucene.search.suggest.document.NRTSuggester.load(NRTSuggester.java:332) ~[lucene-suggest-8.6.2.jar:8.6.2 016993b65e393b58246d54e8ddda9f56a453eb0e - ivera - 2020-08-26 10:54:46]
at org.apache.lucene.search.suggest.document.CompletionsTermsReader.suggester(CompletionsTermsReader.java:70) ~[lucene-suggest-8.6.2.jar:8.6.2 016993b65e393b58246d54e8ddda9f56a453eb0e - ivera - 2020-08-26 10:54:46]
at org.apache.lucene.search.suggest.document.CompletionTerms.suggester(CompletionTerms.java:71) ~[lucene-suggest-8.6.2.jar:8.6.2 016993b65e393b58246d54e8ddda9f56a453eb0e - ivera - 2020-08-26 10:54:46]
at org.elasticsearch.index.engine.CompletionStatsCache.lambda$get$0(CompletionStatsCache.java:93) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.index.engine.CompletionStatsCache$$Lambda$5243/0x00000008018102e0.get(Unknown Source) ~[?:?]
at org.elasticsearch.action.ActionListener.completeWith(ActionListener.java:325) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.index.engine.CompletionStatsCache.get(CompletionStatsCache.java:82) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.index.engine.InternalEngine.completionStats(InternalEngine.java:323) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.index.shard.IndexShard.completionStats(IndexShard.java:1073) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.action.admin.indices.stats.CommonStats.<init>(CommonStats.java:207) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.action.admin.indices.stats.TransportIndicesStatsAction.shardOperation(TransportIndicesStatsAction.java:105) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.action.admin.indices.stats.TransportIndicesStatsAction.shardOperation(TransportIndicesStatsAction.java:48) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.action.support.broadcast.node.TransportBroadcastByNodeAction$BroadcastByNodeTransportRequestHandler.onShardOperation(TransportBroadcastByNodeAction.java:423) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.action.support.broadcast.node.TransportBroadcastByNodeAction$BroadcastByNodeTransportRequestHandler.messageReceived(TransportBroadcastByNodeAction.java:401) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.action.support.broadcast.node.TransportBroadcastByNodeAction$BroadcastByNodeTransportRequestHandler.messageReceived(TransportBroadcastByNodeAction.java:388) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.xpack.security.transport.SecurityServerTransportInterceptor$ProfileSecuredRequestHandler$1.doRun(SecurityServerTransportInterceptor.java:257) ~[?:?]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.xpack.security.transport.SecurityServerTransportInterceptor$ProfileSecuredRequestHandler.messageReceived(SecurityServerTransportInterceptor.java:315) ~[?:?]
at org.elasticsearch.transport.RequestHandlerRegistry.processMessageReceived(RequestHandlerRegistry.java:72) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.transport.TransportService$8.doRun(TransportService.java:800) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:737) ~[elasticsearch-7.9.2.jar:7.9.2]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) ~[elasticsearch-7.9.2.jar:7.9.2]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630) ~[?:?]
at java.lang.Thread.run(Thread.java:832) [?:?]
fatal error in thread [elasticsearch[test_node1][management][T#1]], exiting
java.lang.OutOfMemoryError: Java heap space
at org.apache.lucene.util.fst.OnHeapFSTStore.init(OnHeapFSTStore.java:59)
at org.apache.lucene.util.fst.FST.<init>(FST.java:461)
解决方案:
-
增加 JVM 堆内存:
-
可以尝试增加 Elasticsearch JVM 的堆内存大小默认情况下,JVM 堆内存的最大值可能较小,可以通过调整
jvm.options文件中的-Xmx和-Xms参数来增加堆内存具体的堆内存大小需要根据硬件配置和数据规模来设置,最大修改为:-Xms31g -Xmx31g
-
-
使用es集群配置
改为使用集群,增加集群数据节点,同时合理划分分片数量,确保数据分片有足够的节点进行分布,可以减轻每个节点的内存负担
分片配置:
- 分片数量:减少每个索引的主分片数量,同时增加副本分片,以便分布在多个节点上这样可以降低每个节点的内存负担对于大索引,分片的大小通常建议在10GB到50GB之间
- 分片分配:确保分片均匀分布在集群的所有节点上,以避免单个节点过载
内存设置:
- JVM堆内存:对于每个节点,JVM堆内存的大小应设置为服务器物理内存的50%左右,但不超过32GB(推荐设置在
-Xms和-Xmx之间相同的值) - 操作系统级别的内存管理:可以配置
vm.max_map_count参数,以增加可映射文件数增大file descriptors限制以支持更多的文件句柄
FST内存占用:
- 减少自动补全字段:由于FST(有限状态转换器)数据结构用于实现自动补全功能,它的内存占用可能很大建议减少自动补全字段的数量或分割这些字段
- FST外置存储:考虑将FST存储在磁盘上,而不是堆内存中这可以通过适当的索引设置来实现,例如通过调整
index.codec为best_compression



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











