









梳理一下快手的笔试中的选择题吧,主要是机器学习的内容,当然数学题也有一部分。
- 卷积层的存储量和计算量
存储量:
C(上一层卷积数量) * K(卷积核高) * K(卷积核宽) * C(这一层卷积核的数量)
计算量:
C(上一层卷积数量) * K(卷积核高) * K(卷积核宽) * C(这一层卷积核的数量) * W(输出特征图的宽度) * H(输出 特征图的高度)
即为: O ( K ∗ K ∗ C i n ∗ M ∗ M ∗ C o u t ) O(K * K * C_{in} * M * M * C_{out}) O(K∗K∗Cin∗M∗M∗Cout)
这里简单说一下计算量的推导:
首先计算量为: ( ( K ∗ K + 1 ) ∗ C i n + C i n − 1 ) ∗ M ∗ M ∗ C o u t ((K * K+1) * C_{in} + C_{in}-1) * M * M * C_{out} ((K∗K+1)∗Cin+Cin−1)∗M∗M∗Cout
其中, ( K ∗ K + 1 ) (K * K+1) (K∗K+1)表示在一个卷积核计算时在叠加bias
乘以 C i n C_{in} Cin表示在输入的channel方向进行乘积
C i n − 1 C_{in}-1 Cin−1表示一次卷积之后 C i n C_{in} Cin方向的叠加
$((K * K+1) * C_{in} + C_{in}-1) $表示最终汇聚成特征图上的一个点乘以 M ∗ M ∗ C o u t M * M * C_{out} M∗M∗Cout表示在最终的输出特征图上所有点的个数
经过简化之后的计算量为: O ( K ∗ K ∗ C i n ∗ M ∗ M ∗ C o u t ) O(K * K * C_{in} * M * M * C_{out}) O(K∗K∗Cin∗M∗M∗Cout)
其中输出特征图的尺寸计算公式为: M = ( M i n − K + 2 ∗ p a d d i n g ) / s t r i d e + 1 M = (M_{in}-K+2*padding)/stride+1 M=(Min−K+2∗padding)/stride+1
-
红白球各50个,按照一定分配方法放入两个框子中,一个人随即从框子中取出一个球,问如何分配才能使抓到红球的概率最大?
首先对于两个框,选择拿球的框概率是一样的,都是0.5;
假设从第一个框子中拿到红球的概率是p1,从第二个框子中拿到红球的概率是p2,那么最终抓取到红球的概率是p=0.5*(p1+p2)。
此时,如果一个框子中(假设是第一个框子)只用红球,而另一个框子中有红球和白球,那么p1=1,0<p2<1,于是p=0.5 + 0.5*p2。这样的结果绝对大于0.5。
剩下的就好想了。为了使p2尽可能地大,那么第二个框子中的红球要尽可能的多,很容易得出第一个框子放一个红球,第二个框子放49个红球和50个白球这样的结论,此时第一次抓取到红球的概率最大,约为0.75。
稍稍扩展一下,如果小球的数量不是50个呢?那么球的数量越多,最后越接近于0.75,因为这样的p2越接近1。 -
矩阵的广义逆

答案:D
解答如下:
对每一个mxn阶矩阵A,存在一个唯一的nxm阶矩阵M,使得下面三个条件同时成立:
(1) AMA = A
(2)MAM = M
(3)AM与MA均为对称矩阵
这样的矩阵M成为矩阵A的Moore-Penrose广义逆矩阵,记作M=A+
当A非奇异时,也满足以上4个条件,因此M-P逆也是通常逆矩阵的推广. -
二叉树的遍历
前序:根节点 -> 左子树 -> 右子树
中序:左子树 -> 根节点 -> 右子树
后序:左子树 ->右子树 -> 根节点
(注意根节点的位置) -
A袋中有5个白球,3个黑球,从中任取2个,颜色不一样的概率?
这题很简单,主要是过一下概率题的计算过程:
( C 5 2 + C 3 2 ) / C 8 2 = 13 / 28 (C_5^2+C_3^2)/C_8^2 = 13/28 (C52+C32)/C82=13/28, 1 − 13 / 28 = 15 / 28 = 0.357 1-13/28=15/28=0.357 1−13/28=15/28=0.357 -
l1范数、l2范数相关问题

-
算法复杂度

摘自牛客网上的解答,其实也就是等比数列求和:
T ( 2 n ) = 2 T ( n ) + 2 n T(2n) = 2T(n) + 2n T(2n)=2T(n)+2n
T ( 2 n ) / 2 n = T ( n ) / n + 1 T(2n)/2n = T(n)/n + 1 T(2n)/2n=T(n)/n+1
令$c(n) = T(n)/n $
则 c ( 2 n ) = c ( n ) + 1 c(2n) = c(n) + 1 c(2n)=c(n)+1
c ( 2 n ) − c ( n ) = 1 c(2n) - c(n) = 1 c(2n)−c(n)=1
即 c ( 2 k ) − c ( 2 k − 1 ) = 1 c(2^k) - c(2^{k-1}) = 1 c(2k)−c(2k−1)=1
累加求和 得
c ( 2 k ) = c ( 1 ) + k c(2^k) = c(1) + k c(2k)=c(1)+k
即 T ( 2 k ) = c ( 1 ) + k T(2^k) = c(1) + k T(2k)=c(1)+k
即 T ( 2 k ) = ( c ( 1 ) + k ) ∗ ( 2 k ) T(2^k) = (c(1) + k) * (2^k) T(2k)=(c(1)+k)∗(2k)
即 T ( n ) = ( c ( 1 ) + l o g 2 ( n ) ) ∗ n T(n) = (c(1) + log2(n)) * n T(n)=(c(1)+log2(n))∗n
- 数据的存储结构

答案:D
摘自牛客网回答,算是数据结构的基础知识了:
存储结构是数据的逻辑结构用计算机语言的实现,常见的存储结构有: 顺序存储 , 链式存储 , 索引存储 ,以及 散列存储 。其中散列所形成的存储结构叫 散列表(又叫哈希表) ,因此哈希表也是一种存储结构。栈只是一种抽象数据类型,是一种逻辑结构,栈逻辑结构对应的顺序存储结构为顺序栈,对应的链式存储结构为链栈,循环队列是顺序存储结构,链表是线性表的链式存储结构
-
概率题

设棍子的长为1,第一段长x,第二段长y,为了满足"三角形两边之和大于第三边",有以下约束条件:
x + y > 0.5 x+y> 0.5 x+y>0.5
0 < x < 0.5 , 0 < y < 0.5 0<x<0.5, 0<y<0.5 0<x<0.5,0<y<0.5
x + y < 1 x+y<1 x+y<1
如下图所示:

阴影部分为满足约束条件的x、y范围,为1/8,
总的面积为1/2
概率为:1/8 / 1/2 = 1/4 -
数学题
小于1000且既不能被5整除 也不能被3整除的正整数有?个
答案:533
能被5整除的数5n 0<5n<1 000 ∴0<n<200 有199个
能被3整除的数3n 0<3n<1 000 ∴0<n≤333 有333个
能被15整除的数15n 0<15n<1 000 ∴0<n≤66
不能被5也不能被3整除的数共有999-(199+333-66)=533
- 相关性
下列哪一项能反映出 X 和 Y 之间的强相关性?
A. 相关系数为 0.9
B. 对于无效假设 β=0 的 p 值为 0.0001
C. 对于无效假设 β=0 的 t 值为 30
D. 以上说法都不对
答案:A
解析:相关系数的概念我们很熟悉,它反映了不同变量之间线性相关程度,一般用 r 表示。
其中,Cov(X,Y) 为 X 与 Y 的协方差,Var[X] 为 X 的方差,Var[Y] 为 Y 的方差。r 取值范围在 [-1,1] 之间,r 越大表示相关程度越高。A 选项中,r=0.9 表示 X 和 Y 之间有较强的相关性。
而 p 和 t 的数值大小没有统计意义,只是将其与某一个阈值进行比对,以得到二选一的结论。例如,有两个假设:
- 无效假设(null hypothesis)H0:两参量间不存在“线性”相关。
- 备择假设(alternative hypothesis)H1:两参量间存在“线性”相关。
如果阈值是 0.05,计算出的 p 值很小,比如为 0.001,则可以说“有非常显著的证据拒绝 H0 假设,相信 H1 假设。即两参量间存在“线性”相关。p 值只用于二值化判断,因此不能说 p=0.06 一定比 p=0.07 更好。
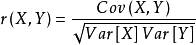
- 函数调用

这题画个递归树就可以很清楚地看到了:

当x<=2的时候就不会再继续调用了,递归树中每个节点调用了一次,一共调用了15次。















 697
697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









