









二、数据技术篇—— 日志采集
日志本身不是日志采集的目的,服务于基于日志的后续应用,才是正确的着眼点。
日志采集的作用:
- 服务于开发者,协助开发者分析各类设备信息
- 帮助各APP更好了解自己的用户
2.1 浏览器日志采集
2.1.1 页面型的日志采集分类
- 页面展示日志采集:两大基础指标:页面浏览量 (Page View,PV )和 访客数 (Unique Visitors,UV)
- 页面交互日志采集:采集用户的互动行为数据,量化获知用户的兴趣点和体验优化点
- 特定场合:曝光日志、用户在线状态监测
2.1.2 页面访问过程
- 用户点击链接
- 浏览器向服务器发起http请求,请求包括「请求行(请求方法、URL、HTTP协议版本号)、请求报文(Header、Cookie)、请求正文(一般为空)」
- 服务器接受并解析请求,返回「状态行(三位数字组成的状态码),响应报头(命令浏览器记录一些东西如Cookie)、响应正文(一般为非空)」
- 浏览器接收到响应请求,解析文档渲染页面(采集日志的动作在这步进行,解析时出发特定的请求到日志采集服务器,第一第二步请求没到服务器,第三步不能保证浏览器成功解析)
2.1.3 页面浏览日志采集流程@
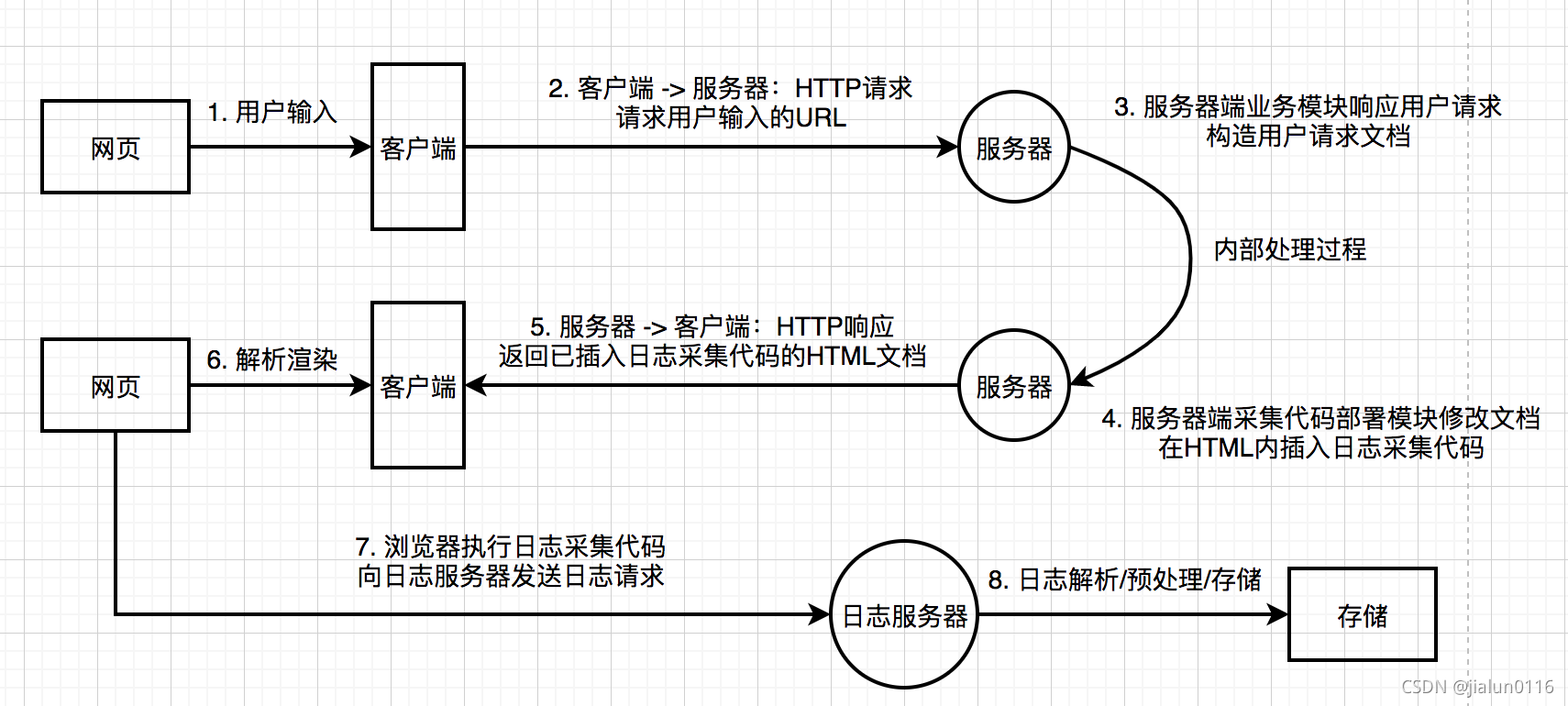
- 客户端日志采集。一般由被植入页面文档内的JS脚本执行,采集页面参数,浏览行为的上下文信息,和运行环境信息。
- 客户端日志发送。采集脚本执行时,把数据发送到日志服务器(大多数时即时的),一般以URL参数形式放在HTTP日志请求的请求行内。
- 服务器端日志收集。日志服务器收到请求后立即发回请求成功响应(避免对页面加载造成影响),同时将内容写入日志缓冲区
- 服务器端日志解析存档。日志会被顺序读出并按照约定的逻辑解析,转存入标准的日志文件
2.1.4 页面交互日志采集
- 需要了解用户在访问某个页面时的具体互动行为特征,但是由于终端类型、页面内容、用户行为等变化不可估计,无法规定统一的采集方案。用一个开放的基于HTTP协议的日志服务,实现高度自定义的夜晚特征。业务方注册需要采集的日志,系统会生成对一个的代码,业务方将交互日志采集代码与要监测的交互行为绑定,对用户上传的数据,原则上不解析只简单的转存。
2.1.5 页面交互日志清洗和预处理
- 识别流量攻击、网络爬虫和流量作弊。对采集的日志进行合法性检验,归纳对应的过滤规则
- 数据缺项补正,一些重要且公用的数据做取值归一、标准化处理或者反向补正(根据新日志对稍早收集的日志中个别数据项做回补或修正)
- 无效数据剔除,删除已经失效或者冗余的数据项
- 日志隔离分发,数据安全和业务特性需要需要做隔离
2.2 无线客户端的日志采集
无线客户端的日志采集采用采集SDK来完成,日志根据不同的用户行为分为不同的事件
- 页面事件(同前面的页面浏览)
- 控件点击事件 (同前面的页面交互)
为什么要对事件分类?
- 不同事件的日志触发时机、日志内容和实现方式有差异
- 为了更好的完成数据分析
- 降低后续处理的复杂性
2.2.1 页面事件
对通用的用户行为抽象出一些普通的接口方式,页面事件日志包括:
- 设备及用户的基本信息
- 被访问页面的信息,如商品详情页的商品ID
- 基本访问路径,还原用户完整的访问行为(归因)
提供了接口
- 页面展示时,记录页面进入时的状态
- 页面退出时,发送日志(为什么不在页面进入时就发送?离开时发送能够记录每个页面停留时长)
- 提供页面扩展信息的接口
- 提供透传参数功能,把当前页面的部分信息传到下个页面(好处是能够进行来源去向的追踪)
2.2.2 控件点击事件
和浏览器的日志采集一致,无法规定统一的采集内容,需要自定义处理。
这里会提供自定义埋点类:
- 事件名称
- 事件时长
- 事件所携带的属性
- 事件对应的页面
2.2.3 特殊场景
- 为了平衡日志大小,减少流量消耗、采集服务器压力、网络传输压力,采集SDK提供聚合功能。总体的思路就是:每个曝光的元素一般都属于一个页面,用页面的生命周期来实现适当的聚合以及确定发送时机。比如搜索结果页的滚屏操作产生很多日志,客户端对这些日志进行聚合(包括一些只需要计数的),上传聚合后的日志到采集服务器即可。
- 访问路径存在明显的回退行为,业务分析时:主会场->男装分会场->男装店铺A->男装分会场->男装店铺B,会发现活动承接页(分会场)来源一大部分来自详情页(店铺),会干扰归因。需要利用页面的生命周期,识别页面的复用。
2.2.4 H5 & Native日志统一 @
APP分为 (纯Native APP)和 (有Native和H5嵌入的APP,Hybrid APP),需要统一处理。Native页面采用采集SDK,H5一般基于浏览器的页面日志采集方式采集。
为什么要把H5日志归到SDK日志呢?
- 采集SDK能采集到更多的设备相关数据,为移动端的数据分析提供便利
- 能在本地缓存,后借机上传,保证数据不丢
具体流程:H5页面浏览时通过运行JS脚本,采集当前页面数据并打包成对象,调用客户端对应的接口放入传入参数,转化为客户端日志格式(根据类别识别浏览事件还是控件点击事件),择机上传。
2.2.5 日志传输
无线客户端产生日志后先存在本地,后借机上传。需要考虑到日志的大小、合理性,还要考虑到上传时网络的消耗,不能简单的靠间隔时间。
客户端数据上传时是想服务器发送POST请求。服务器对请求进行校验,将数据追加到本地文件存储,用Nginx的access_log,切分维度为天。计算压力较大时可以释放其他日志资源
2.3 日志采集的挑战
如何实现日志数据的结构化和规范化,实现更为高效的下游统计计算,提供服务业务特性的数据展现,为算法提供更便捷、灵活的支持。
2.3.1 日志分流和定制处理
短时间的流量热点爆发,不能采用统一的解析方案(需要在资源浪费,尽可能多的进行预处理;和需求覆盖不全,仅对重要内容预处理,进行取舍)。所以要考虑业务分流、日志优先级控制。
分治是基本原则,PV日志的请求位置随着页面所在业务类型的不同变化,通过尽可能靠前的布置路具差异,可以尽早分流,降低日志处理中分支判断消耗,并作为后续的资源配置调配的前提。
客户端日志采集代码更新频次高(月/周为单位),不仅考虑到日志服务端分布计算方案,而且将分类任务前置到客户端,实现系统的效能最大化。
规模小时可以以URL正则规则集来进行日志分类,但是数据变多后,需要有日志规范和与之对应的元数据中心。规范制定 -> 元数据注册 -> 日志采集 -> 自动化计算 -> 可视化
2.3.2 大促保障 @
考虑服务器的收集能力(QPS、峰值等)、数据传输能力(速度)、实时解析的吞吐率、实时业务分析处理能力。
- 实现了服务器端推送配置到客户端,高到达率
- 日志分流,结合重要程度和大小,实现日志服务器端拆分
- 高峰期通过推送配置的方式对非重要日志进行限流,错峰后恢复。(作用范围:应用、平台、事件、场景;具体实施:延迟上报、部分采样)

















 4055
4055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









