









五、数据技术篇—— 实时技术
5.1 简介
流计算,业务希望能在第一时间拿到经过加工的数据,实时监控状态作出运营决策,引导业务往好的方向发展。
特征:
- 实效性高,延时可能到达毫秒级
- 常驻任务,流式任务数据属于常驻进程任务,启动后会一直运行(数据源是无界的)
- 性能要求高,高吞吐量低延时,需要优化性能
- 应用局限性,不能代替离线处理(计算成本大),数据是流式的,有上下文关系的情况下,到达时间的不确定性导致实时和离线处理的结果有一定差异
按照数据的延时情况,时效分为三种
- 离线:在今天(T)处理N天前(T-N,N>=1)的数据。可以在批处理系统中实现
- 准实时:在当前小时(H)处理N小时前(T-N,N>0)的数据。可以在批处理系统中实现
- 实时:当前时刻处理当前的数据。要在流式处理系统中完成,每产生一条数据,会被采集并实时发送到任务处理
5.2 流式技术架构@
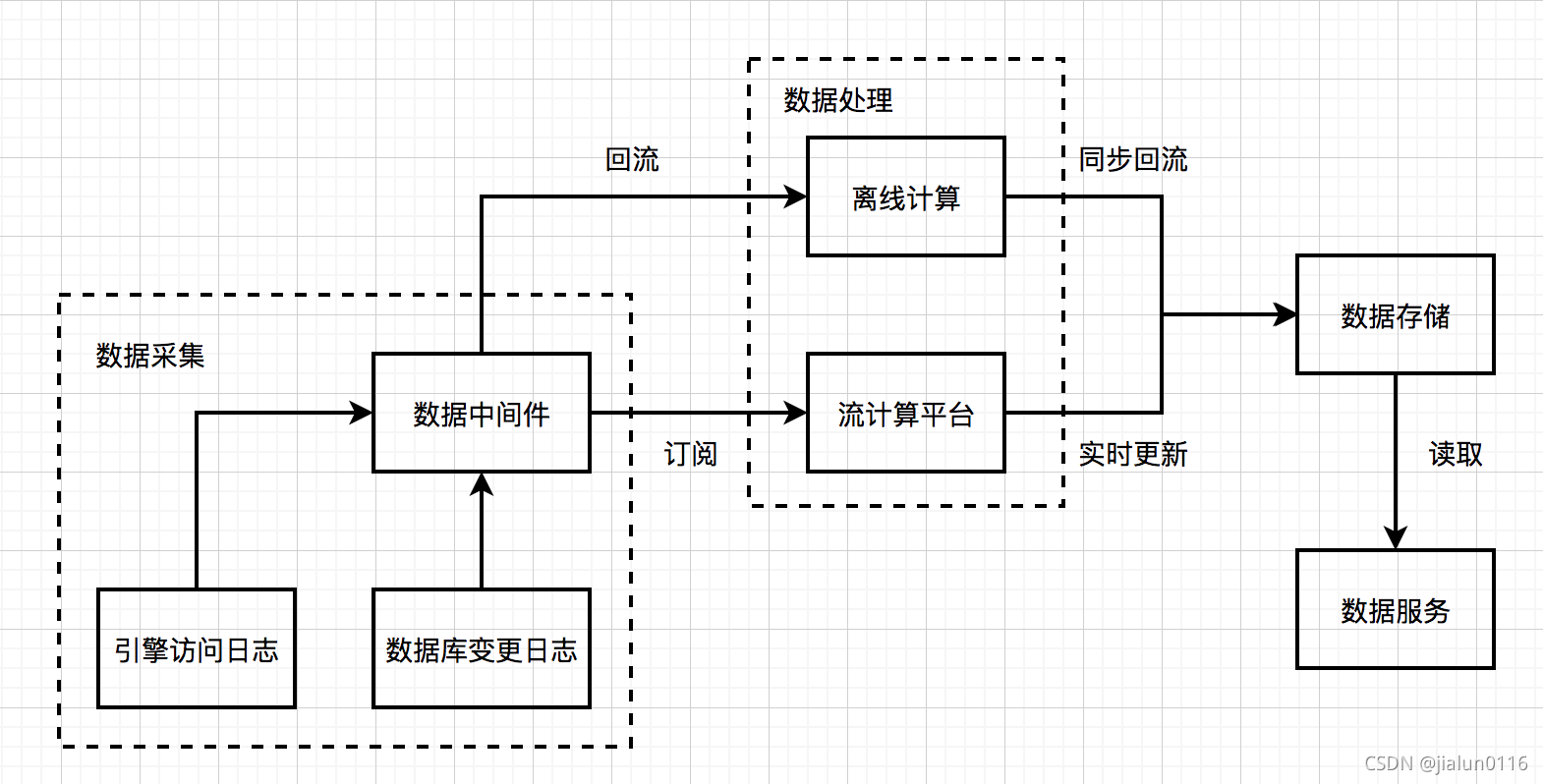
5.2.1 数据采集
日志服务器中数据采集到数据中间件,供下游实时订阅使用
时效性和吞吐量是数据处理的矛盾体
数据采集的种类:
- 数据库变更日志,如MySQL的binlog日志
- 引擎访问日志,用户访问网页产生的Apache引擎日志,接口查询日志
如何对数据进行采集(按批次):
- 数据大小限制,比如新数据达到512k时,为一批写入
- 时间阈值限制,比如30s写一批
消息系统是数据库变更节点的上游,特点:延时低,吞吐量有限。有些业务没有通过消息系统来对数据库更新,所以从消息系统中获取的数据不全,但是从数据库变更日志拿到的肯定是全的,
5.2.2 数据处理
提供流计算引擎,拉取到流式计算系统的任务中进行加工。实时应用的拓扑结构是有向无环图
任务计算往往是多线程的,会根据业务主键进行分桶处理,数据都会在内存中(需要定期处理,可以按照LRU清理)。包装了一层SQL语义,降低门槛。下面介绍一些经典问题:
1. 去重指标:
计算去重的时候,要把去重的明细数据保存下来,会造成内存消耗过多。这里分两种情况:
精确去重,明细数据必须保存,可以通过数据倾斜来处理,一个节点的压力分到多个节点上。
模糊去重,精度要求不高的情况,相关算法去重。
去重算法:
- 布隆过滤器。位数组算法的应用,不保存真实的明细数据,只保存明细数据对应哈希表的标记位。适用于:统计维度值非常多的情况,如统计全网各个商家的UV数据。各个维度之间能够共用。
- 基数估计。也是利用哈希,按照数据的分散程度来估算现有数据集的边界,从而得出大概的去重值总和。适用于:统计维度值非常粗的情况,如统计整个大盘的UV数据。各个维度之间不能够共用。
2. 数据倾斜:
单个节点数据量比较大时,会遇到性能瓶颈。需要对数据进行分桶处理。
- 去重指标分桶。通过对去重值进行分桶Hash,相同值的会放到同一个桶中去重,再把每个桶里的值加总。利用了CPU和内存资源
- 非去重指标分桶。随机分发到每个桶,每个桶汇总,利用了各个桶的CPU能力
3. 事务处理:
实时计算时分布式处理的,系统是不稳定的,如何做到数据精确处理
- 超时时间: 每个数据处理按照批次来进行的,超时时重发,此外还有限流的功能
- 事务信息: 每批数据都会带一个事务ID的信息
- 备份机制: 内存数据可以通过外部存储数据恢复
- 数据自动ACK
- 失败重发
5.2.3 数据存储
数据被实时加工(聚合、清洗),写到在线存储系统中。写操作是增量操作,且源源不断
存储的三种类型数据:
- 中间计算结果,一些状态的保存,用于发生故障时恢复内存现场
- 最终结果数据,通过ETL处理后的实时结果数据,写的频率高,可以被下游直接使用
- 维表数据,由离线系统导入在线系统,供实时任务关联。
实时任务使用的数据库特点:
-
多线程,支持并发读写
-
延时毫秒级
-
先写内存再落磁盘
-
读请求有缓存机制
-
一般使用HBase、MonggoDB等列式存储系统
-
缺点:HBase为例,一张表必须要有rowkey(按照ASCII码来排序),限制了读取数据的方式(读取rowkey的方式变了)
表名设计:汇总层标识+数据域 + 主维度 + 时间维度 (所有主维度相同的数据都在一张物理表中)
rowkey设计:MD5 + 主维度 + 维度标识 + 子维度1 + 时间维度 + 子维度2 (MD5把数据散列,使服务器负载均衡)
5.2.4 数据服务
架设统一的数据服务层,获取结果
优点:
- 不需要直连数据库,数据源等信息在数据服务层维护,对下游透明
- 调用方只需要使用暴露的接口,不需要关心底层逻辑
- 屏蔽存储系统间的差异
5.3 流式数据模型
5.3.1 数据分层
ODS层
属于操作数据层,直接从业务系统采集归来的最原始数据,粒度最细。实时和离线在源头上统一(好处:同一份数据加工出来的指标,口径基本一致,方便对比)。如:原始的订单变更记录数据,订单力度的变更过程,一笔订单有多个记录。
DWD层
根据业务过程建模出来的实时事实明细,对于没有上下文关系的记录会回流到离线系统,最大程度保障实时离线在ODS和DWD层一致。如:订单的支付明细表,用户访问日志明细表。订单力度的支付记录,一笔订单只有一条记录。
DWS层
计算各个维度的汇总指标,如果维度是各垂直业务线通用,会放在实时通用汇总层。比如电商数据的几大维度的汇总表(卖家力度)。卖家的实时成交金额,一个卖家一条记录。
ADS层
对于不同用的统计维度值数据,自身业务员关注。外卖地区的实时成交金额
DIM层
基本上从离线维表层导出(ODS离线加工而成),抽取到实时应用。如商品维表、卖家维表等。订单商品类目和行业的对应关系表。
5.3.2 多流关联
流式计算中要把两个实时流进行主键关联得到对应的表。
关键点:需要相互等待,双方都到了才能关联成功
难点:数据到达是一个增量的过程,数据到达的时间是不确定和无序的,需要涉及中间状态的保存和恢复。
A表和B表用ID实时关联时,由于无法知道表的到达顺序。因此在两个数据流的每条新数据到来,都要到另一张表进行查找,如果拼的上,拼接成记录输出到下游;拼不上需要放在内存或外部存储,直到B表记录也到达。每次都是到对方表截止当前的全量数据中去查找。可以按照关联主键分桶处理
5.3.3 维表使用@
实时计算中,关联维表会使用当前的实时数据(T)关联 T-2的维表数据
为什么要这么做呢?
- 数据无法及时准备好。零点时,实时数据必须关联维表,T-1的维表数据不能在零点马上准备就绪
- 无法准确获取全量的最新数据。全量最新数据 = T-1的数据 + 当天变更 。当天实时数据无序且时间不确定
- 数据的无序性。比如10点的业务数据成功关联维表,得到维表字段信息(只能说拿到了截止10点的最新状态数据,不知道是否会发生变化)
维表使用分为两种
- 全量加载。数据量小,每天几万条记录,类目维表
- 增量加载。不能全部加载,增量查找和LRU过期形式,热门数据存在内存
5.4 大促挑战
5.4.1 大促特征
- 毫秒级延迟
- 洪峰明显(高吞吐量)
- 高保障(需要做多链路冗余,快速切换,对业务方透明)
- 公关特性(主键过滤、去重精准、口径统一)
5.4.2 大促保障@
实时任务的优化
- 独占资源和共享资源的策略(一台机器长时间都需要去共享资源池抢资源,考虑分配更多独占资源)
- 合理选择缓存机制,降低读写库次数
- 计算单元合并,降级拓扑层级。(数据在每个节点的传输都要经过序列化和反序列化,层级深性能差)
- 内存对象共享,避免字符串拷贝
- 高吞吐量和低延时取平均
数据链路保障
多链路搭建,多机房容灾,异地容灾,链路切换推送
压测
数据压测:把实时作业的订阅数据点位调整到几个小时或前几天,模拟蓄洪压测。
产品压测:本身压测优化服务器性能(手机所有读操作的URL,QPS:500次/秒压测);前端页面稳定性测试(8-24小时,提升前端页面稳定性)















 6652
6652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









