







目录
摘要
由于机器学习课程的老师要求我们在后面的课程中分小组到讲台上去分享论文,所以本周的学习任务就是进行文献阅读。我选择了一篇来自今年2月份 AAAI 会议上的论文,这篇论文在上个月(9月)才被正式收录。这篇论文算是我第一篇进行逐字阅读的论文,下面的内容我会用我自己浅薄的数学理解进行推导和证明,如有错误,请不吝指正。
Abstract
Due to the requirement from our machine learning course instructor that we present papers in groups in subsequent classes, this week’s learning task is to read literature. I have chosen a paper from this year’s February AAAI conference, which was officially accepted last month (September). This is the first paper I am reading word by word. Below, I will derive and prove the content using my limited mathematical understanding. If there are any errors, please do not hesitate to correct me.
QLABGrad:一种无超参数且保证收敛的深度学习方案
Title: QLABGrad: a Hyperparameter-Free and Convergence-Guaranteed Scheme for Deep Learning
Author: Fu, MH (Fu, Minghan) ; Wu, FX (Wu, Fang-Xiang)
Source: THIRTY-EIGHTH AAAI CONFERENCE ON ARTIFICIAL INTELLIGENCE, VOL 38 NO 11
WOS:https://www.webofscience.com/wos/alldb/full-record/WOS:001241514400024
1.研究背景
学习率是深度学习任务的一个关键超参数,它决定了学习过程中模型参数的更新快慢。然而,学习率的选择通常取决于经验判断,如果没有密集的试错实验,可能不会产生令人满意的结果。
深度神经网络寻找最优参数最常见的方案是梯度下降法,基本的下降方法包括随机梯度下降法(SGD)、小批量梯度下降法、批量梯度下降法和它们的变体 ,其中学习率是用户指定的一个固定值。如果选择的学习率太小,那么学习过程可能会非常耗时。而如果选择的有限学习率太大,则学习过程可能会无法收敛到最小值。因此,在任何一种情况下,保持恒定的学习率都不是理想的学习策略。
下列有几种策略可以解决恒定学习率的问题:
- 学习率随迭代次数减小
- 损失函数值和/梯度和适应学习率
- 适应下降方向的恒定学习率
下面简单的讲一下三种策略代表算法的公式,至于具体的含义和思想不再赘述。
1.1.学习率随迭代次数减小
这种策略一般采用 Decay 算法,也就是说寻找一个以迭代次数 t t t 为自变量的单调减函数 f ( t ) f(t) f(t),将学习率 η η η 改为超参数 α α α 和 f ( t ) f(t) f(t) 的乘积。常用的 Decay 算法有指数衰减(E-decay)、倒数衰减(R-decay)、步长衰减(SS-decay)和余弦退火衰减(CA-decay)等。
1.2.损失函数值和/梯度和适应学习率
1.2.1.Adagrad
AdaGrad(Adaptive Gradient Algorithm,自适应梯度算法)是一种用于机器学习和深度学习领域的梯度下降优化算法。它的主要特点是可以自适应地调整每个参数的学习率,这意味着AdaGrad能够根据参数的历史梯度信息动态地改变学习率。这种特性使得AdaGrad特别适合处理稀疏数据和非平稳目标函数,因为在这种情况下,不同的参数可能需要不同的学习率来达到最优解。
Adagrad 的算法如下所示:
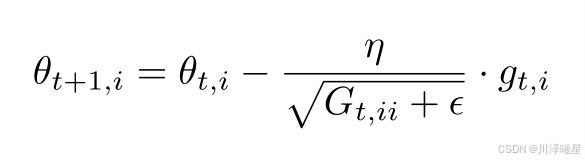
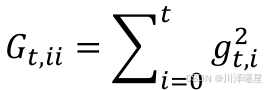
其中, ϵ \epsilon ϵ 是一个防止分母为0的小值(一般取 e − 8 e^{-8} e−8 ), G t , i i G_{t,ii} Gt,ii 是某个参数的历史梯度平方和。
不过这种方法也有缺陷,那就是随着训练的进行,累积梯度平方不断增大,导致学习率逐渐减小,可能会过早地停止学习。
1.2.2.RMSprop
RMSprop(Root Mean Square Propagation)是一种自适应学习率的优化算法,由 Geoffrey Hinton 在他的课程中提出。RMSprop 是为了改进 AdaGrad 的一些缺点而设计的,特别是 AdaGrad 在训练过程中学习率过快衰减的问题。RMSprop 通过引入一个衰减因子来平滑过去的梯度平方的累积,从而使得学习率在训练过程中不会过快下降。
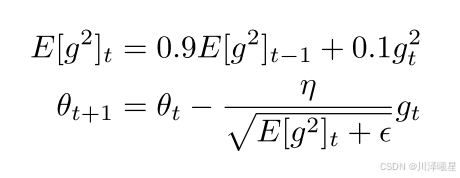
1.3.适应下降方向的恒定学习率
1.3.1.Momentum
在机器学习中,动量法(Momentum)是一种优化算法,用于加速梯度下降过程,特别是在处理具有高曲率、狭窄山谷或鞍点的损失函数时。动量法通过在梯度下降过程中引入一个累积的历史梯度项(动量项),来帮助模型更快地收敛并减少振荡。
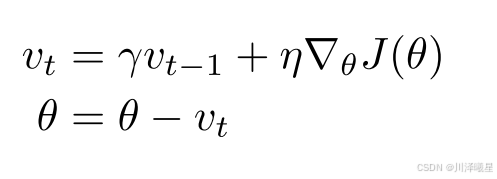
1.3.2.Adam
Adam(Adaptive Moment Estimation)是一种在机器学习中广泛应用的优化算法,特别是用于训练深度神经网络。Adam 结合了动量法(Momentum)和 RMSProp 的优点,旨在提供更快的收敛速度和更好的性能。
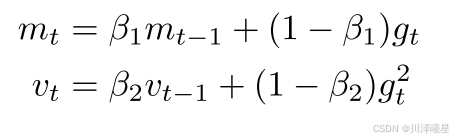
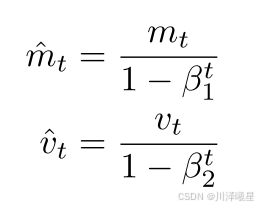
2.研究动机

由上图可以看到,三种策略中的任何一个调整学习率的算法,都至少会含有一个需要人工手动调节的超参数,这就要求用户要根据自己的经验来适当设置一个或多个参数,这是一个非常有挑战性的过程。
因此在本论文中,作者提出了一种基于二次损失近似(quadratic loss approximation, QLAB)的方法,当下降方向为梯度方向时,不需要任何用户指定的超参数的情况下就可以自动确定最优学习率。
3.QLAB算法推导过程

综上可知,只需要用数学的方法求得 a 1 a_1 a1 和 a 2 a_2 a2 就可以求出 a ∗ a^* a∗ 了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









