







源码阅读
这部分H神写的太详细了 基本都摘录自H神的博客
1 定义
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence1.可以看到是final类型的
2.实现了ava.io.Serializable(支持序列化与反序列化)、 Comparable<String>(排序)、 CharSequence接口
2 属性
//final类型说明String初始化后是不可修改的 底层是由Char数组实现的.
private final char value[];
//String还默认缓存了字符串的hash值 个人理解是用于快速比较 默认为0
private int hash; // Default to 0
//这两行代码用于序列化
private static final long serialVersionUID = -6849794470754667710L;
private static final ObjectStreamField[] serialPersistentFields =
new ObjectStreamField[0];
1.不可修改 2.由char[]储存 3.默认存储了hash
p.s.因为String实现了Serializable接口,所以支持序列化和反序列化支持。Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常(InvalidCastException)。
3 构造方法
String的构造方法有16种之多,这里就写一个有意思的.
一个特殊的保护类型的构造方法
String除了提供了很多公有的供程序员使用的构造方法以外,还提供了一个保护类型的构造方法(Java 7),我们看一下他是怎么样的:
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}从代码中我们可以看出,该方法和 String(char[] value)有两点区别,第一个,该方法多了一个参数: boolean share,其实这个参数在方法体中根本没被使用,也给了注释,目前不支持使用false,只使用true。那么可以断定,加入这个share的只是为了区分于String(char[] value)方法,不加这个参数就没办法定义这个函数,只有参数不能才能进行重载。那么,第二个区别就是具体的方法实现不同。我们前面提到过,String(char[] value)方法在创建String的时候会用到 会用到Arrays的copyOf方法将value中的内容逐一复制到String当中,而这个String(char[] value, boolean share)方法则是直接将value的引用赋值给String的value。那么也就是说,这个方法构造出来的String和参数传过来的char[] value共享同一个数组。并没有重新占用内存拷贝而是一个视图. 那么,为什么Java会提供这样一个方法呢? 首先,我们分析一下使用该构造函数的好处:
首先,性能好,这个很简单,一个是直接给数组赋值(相当于直接将String的value的指针指向char[]数组),一个是逐一拷贝。当然是直接赋值快了。
其次,共享内部数组节约内存
但是,该方法之所以设置为protected,是因为一旦该方法设置为公有,在外面可以访问的话,那就破坏了字符串的不可变性。例如如下YY情形:
char[] arr = new char[] {'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd'};
String s = new String(0, arr.length, arr); // "hello world"
arr[0] = 'a'; // replace the first character with 'a'
System.out.println(s); // aello world如果构造方法没有对arr进行拷贝,那么其他人就可以在字符串外部修改该数组,由于它们引用的是同一个数组,因此对arr的修改就相当于修改了字符串。
所以,从安全性角度考虑,他也是安全的。对于调用他的方法来说,由于无论是原字符串还是新字符串,其value数组本身都是String对象的私有属性,从外部是无法访问的,因此对两个字符串来说都很安全。

上图是jdk6中的实现方式,源码如下:
//JDK 6
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
public String substring(int beginIndex, int endIndex) {
//check boundary
return new String(offset + beginIndex, endIndex - beginIndex, value);
}在Java 7 之有很多String里面的方法都使用这种“性能好的、节约内存的、安全”的构造函数。比如:substring、replace、concat、valueOf等方法(实际上他们使用的是public String(char[], int, int)方法,原理和本方法相同,已经被本方法取代)。
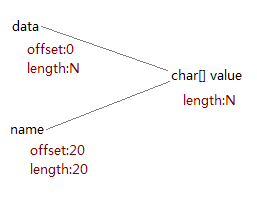
但是在Java 7中,substring已经不再使用这种“优秀”的方法了,为什么呢? 虽然这种方法有很多优点,但是他有一个致命的缺点,对于sun公司的程序员来说是一个零容忍的bug,那就是他很有可能造成内存泄露。 看一个例子,假设一个方法从某个地方(文件、数据库或网络)取得了一个很长的字符串,然后对其进行解析并提取其中的一小段内容,这种情况经常发生在网页抓取或进行日志分析的时候。下面是示例代码。
String aLongString = "...a very long string...";
String aPart = data.substring(20, 40);
return aPart;在这里aLongString只是临时的,真正有用的是aPart,其长度只有20个字符,但是它的内部数组却是从aLongString那里共享的,因此虽然aLongString本身可以被回收,但它的内部数组却不能(如下图)。这就导致了内存泄漏。如果一个程序中这种情况经常发生有可能会导致严重的后果,如内存溢出,或性能下降。
新的实现虽然损失了性能,而且浪费了一些存储空间,但却保证了字符串的内部数组可以和字符串对象一起被回收,从而防止发生内存泄漏,因此新的substring比原来的更健壮。

上图是JDK7中的实现方式,源码如下:
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}虽然substring方法已经为了其鲁棒性放弃使用这种share数组的方法,但是这种share数组的方法还是有一些其他方法在使用的,这是为什么呢?首先呢,这种方式构造对应有很多好处,其次呢,其他的方法不会将数组长度变短,也就不会有前面说的那种内存泄露的情况(内存泄露是指不用的内存没有办法被释放,比如说concat方法和replace方法,他们不会导致元数组中有大量空间不被使用,因为他们一个是拼接字符串,一个是替换字符串内容,不会将字符数组的长度变得很短!)
4 其他方法
length() 返回字符串长度
isEmpty() 返回字符串是否为空
charAt(int index) 返回字符串中第(index+1)个字符
char[] toCharArray() 转化成字符数组
trim() 去掉两端空格
toUpperCase() 转化为大写
toLowerCase() 转化为小写
String concat(String str) //拼接字符串
String replace(char oldChar, char newChar) //将字符串中的oldChar字符换成newChar字符
//以上两个方法都使用了
String(char[] value, boolean share);boolean matches(String regex) //判断字符串是否匹配给定的regex正则表达式
boolean contains(CharSequence s) //判断字符串是否包含字符序列s
String[] split(String regex, int limit) 按照字符regex将字符串分成limit份。
String[] split(String regex)
getBytes
在创建String的时候,可以使用byte[]数组,将一个字节数组转换成字符串,同样,我们可以将一个字符串转换成字节数组,那么String提供了很多重载的getBytes方法。但是,值得注意的是,在使用这些方法的时候一定要注意编码问题。比如:
String s = "你好,世界!";
byte[] bytes = s.getBytes();这段代码在不同的平台上运行得到结果是不一样的。由于我们没有指定编码方式,所以在该方法对字符串进行编码的时候就会使用系统的默认编码方式,比如在中文操作系统中可能会使用GBK或者GB2312进行编码,在英文操作系统中有可能使用iso-8859-1进行编码。这样写出来的代码就和机器环境有很强的关联性了,所以,为了避免不必要的麻烦,我们要指定编码方式。如使用以下方式:
String s = "你好,世界!";
byte[] bytes = s.getBytes("utf-8");
比较方法
boolean equals(Object anObject);
boolean contentEquals(StringBuffer sb);
boolean contentEquals(CharSequence cs);
boolean equalsIgnoreCase(String anotherString);
int compareTo(String anotherString);
int compareToIgnoreCase(String str);
boolean regionMatches(int toffset, String other, int ooffset,int len) //局部匹配
boolean regionMatches(boolean ignoreCase, int toffset,String other, int ooffset, int len) //局部匹配字符串有一系列方法用于比较两个字符串的关系。 前四个返回boolean的方法很容易理解,前三个比较就是比较String和要比较的目标对象的字符数组的内容,一样就返回true,不一样就返回false,核心代码如下:
int n = value.length;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}v1 v2分别代表String的字符数组和目标对象的字符数组。 第四个和前三个唯一的区别就是他会将两个字符数组的内容都使用toUpperCase方法转换成大写再进行比较,以此来忽略大小写进行比较。相同则返回true,不想同则返回false
在这里,看到这几个比较的方法代码,有很多编程的技巧我们应该学习。我们看equals方法:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String) anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}该方法首先判断this == anObject ?,也就是说判断要比较的对象和当前对象是不是同一个对象,如果是直接返回true,如不是再继续比较,然后在判断anObject是不是String类型的,如果不是,直接返回false,如果是再继续比较,到了能终于比较字符数组的时候,他还是先比较了两个数组的长度,不一样直接返回false,一样再逐一比较值。 虽然代码写的内容比较多,但是可以很大程度上提高比较的效率。值得学习~~!!!
contentEquals有两个重载,StringBuffer需要考虑线程安全问题,再加锁之后调用contentEquals((CharSequence) sb)方法。contentEquals((CharSequence) sb)则分两种情况,一种是cs instanceof AbstractStringBuilder,另外一种是参数是String类型。具体比较方式几乎和equals方法类似,先做“宏观”比较,在做“微观”比较。
下面这个是equalsIgnoreCase代码的实现:
public boolean equalsIgnoreCase(String anotherString) {
return (this == anotherString) ? true
: (anotherString != null)
&& (anotherString.value.length == value.length)
&& regionMatches(true, 0, anotherString, 0, value.length);
}看到这段代码,眼前为之一亮。使用一个三目运算符和&&操作代替了多个if语句。
hashCode
使用公式实现
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]s[i]是string的第i个字符,n是String的长度。那为什么这里用31,而不是其它数呢? 计算机的乘法涉及到移位计算。当一个数乘以2时,就直接拿该数左移一位即可!选择31原因是因为31是一个素数!
在存储数据计算hash地址的时候,我们希望尽量减少有同样的hash地址,所谓“冲突”。如果使用相同hash地址的数据过多,那么这些数据所组成的hash链就更长,从而降低了查询效率!所以在选择系数的时候要选择尽量长的系数并且让乘法尽量不要溢出的系数,因为如果计算出来的hash地址越大,所谓的“冲突”就越少,查找起来效率也会提高。
31可以 由i*31== (i<<5)-1来表示,现在很多虚拟机里面都有做相关优化,使用31的原因可能是为了更好的分配hash地址,并且31只占用5bits!
在java乘法中如果数字相乘过大会导致溢出的问题,从而导致数据的丢失.
而31则是素数(质数)而且不是很长的数字,最终它被选择为相乘的系数的原因不过与此!
在Java中,整型数是32位的,也就是说最多有2^32= 4294967296个整数,将任意一个字符串,经过hashCode计算之后,得到的整数应该在这4294967296数之中。那么,最多有 4294967297个不同的字符串作hashCode之后,肯定有两个结果是一样的, hashCode可以保证相同的字符串的hash值肯定相同,但是,hash值相同并不一定是value值就相同。
String对“+”的重载
我们知道,Java是不支持重载运算符,String的“+”是java中唯一的一个重载运算符,那么java使如何实现这个加号的呢?我们先看一段代码:
public static void main(String[] args) {
String string="hollis";
String string2 = string + "chuang";
}然后我们将这段代码反编译:
public static void main(String args[]){
String string = "hollis";
String string2 = (new StringBuilder(String.valueOf(string))).append("chuang").toString();
}看了反编译之后的代码我们发现,其实String对“+”的支持其实就是使用了StringBuilder以及他的append、toString两个方法。
String.valueOf和Integer.toString的区别
接下来我们看以下这段代码,我们有三种方式将一个int类型的变量变成呢过String类型,那么他们有什么区别?
int i = 5;
String i1 = "" + i;
String i2 = String.valueOf(i);
String i3 = Integer.toString(i);1、第三行和第四行没有任何区别,因为
String.valueOf(i)也是调用Integer.toString(i)来实现的。2、第二行代码其实是
String i1 = (new StringBuilder()).append(i).toString(),首先创建一个StringBuilder对象,然后再调用append方法,再调用toString方法。















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









