







Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。下面我简单说说在centos6.9上搭建Hadoop分布式:
准备工作:三台虚拟机,网卡是net模式
主机IP:bigdatamaster.com 192.168.0.60
bigdatawork01.com 192.168.0.61
bigdatawork02.com 192.168.0.62
1. 修改主机名
vim /etc/sysconfig/network三台虚拟机都要修改

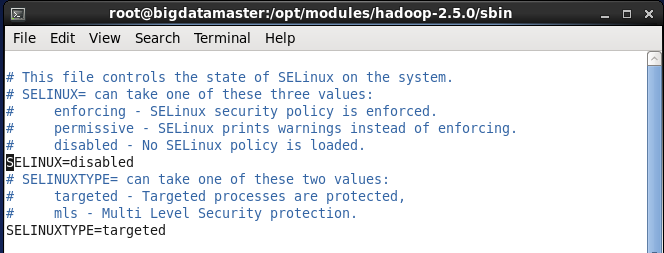
2. 关闭selinux
vim /etc/sysconfig/selinux修改enforcing为disabled
3. 关闭防火墙
service iptables stop4. 永久关闭防火墙
chkconfig iptables off5. 检测防火墙状态
service iptables status

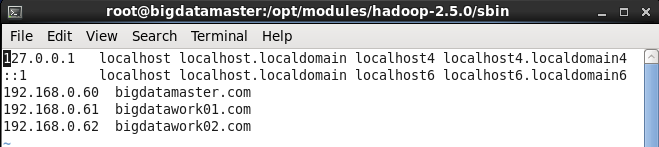
6. 修改本地host文件
vim /etc/hosts
7. 建立文件
mkdir -p /opt/modules/hadoop-2.5.0/tmp/archy-hadoop8. 配置java环境
Java环境配置传送阵
9. 配置ssh
SSH配置传送阵
10. 配置hadoopjava环境
a) hadoop-env.sh(第25行)、yarn-env.sh(第20行)、mapred-env.sh(第16行)这三个文件只配置Java环境;
b) 配置core-site.xml文件
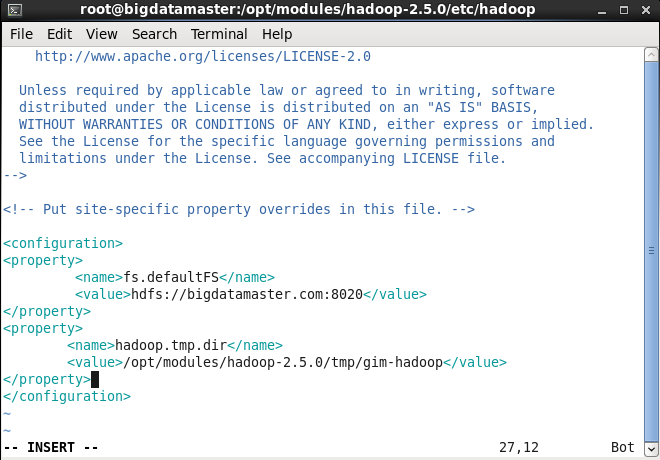
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdatamaster.com:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.5.0/tmp/archy-hadoop</value>
</property>
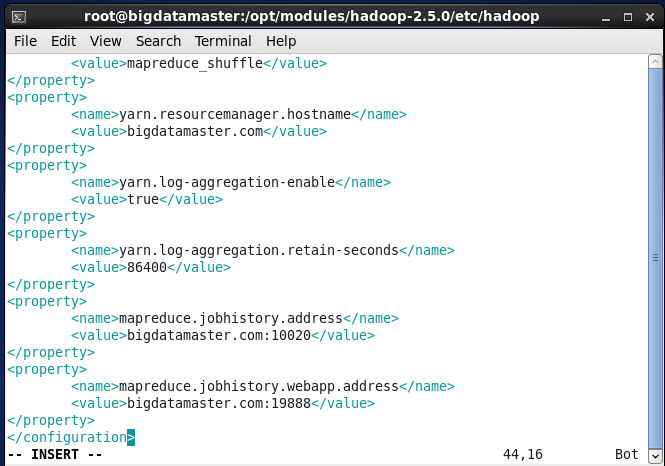
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdatamaster.com</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdatamaster.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdatamaster.com:19888</value>
</property>d) 配置hdfs-site.xml文件
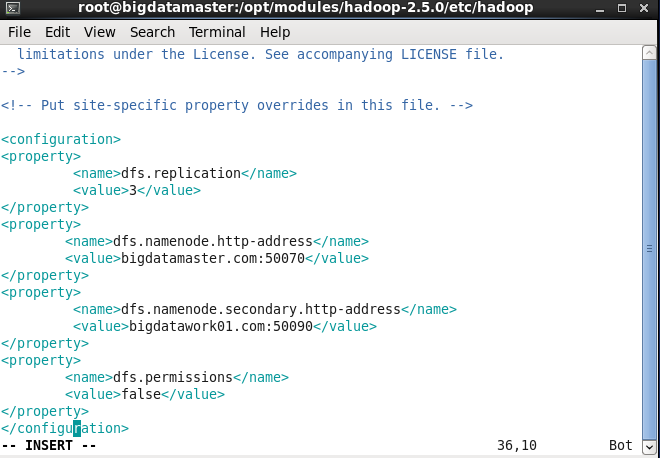
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>bigdatamaster.com:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdatawork01.com:50090</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>11. 配置slaves文件
vim slaves

scp -r /opt/modules/hadoop-2.5.0/ archy@bigdatawork01.com:/opt/modules/
13. 格式化:
cd /opt/modules/hadoop-2.5.0/bin
./hdfs namenode –format14. 启动hadoop
./start-all.sh15.成功:
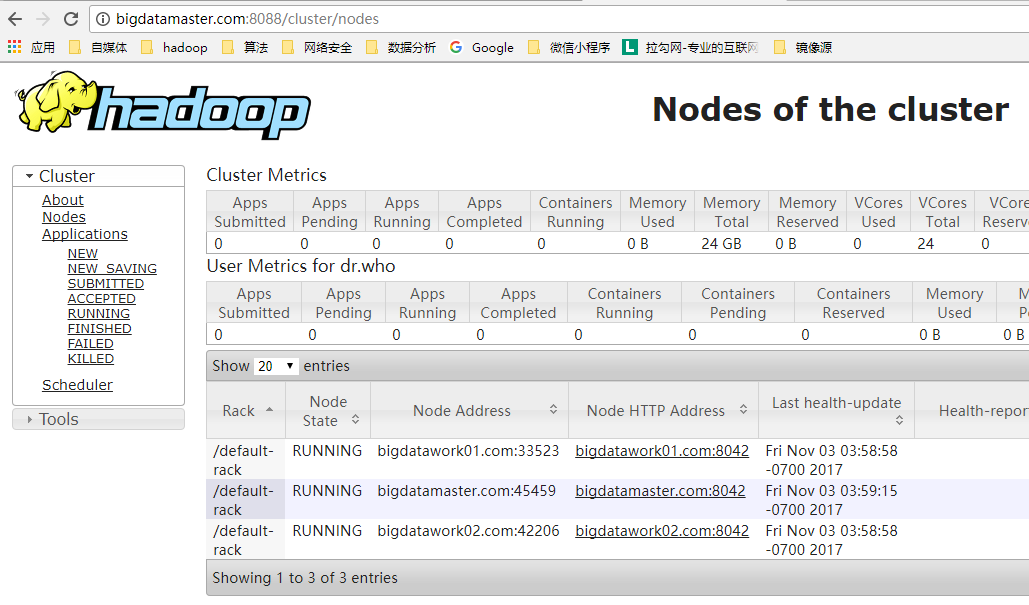
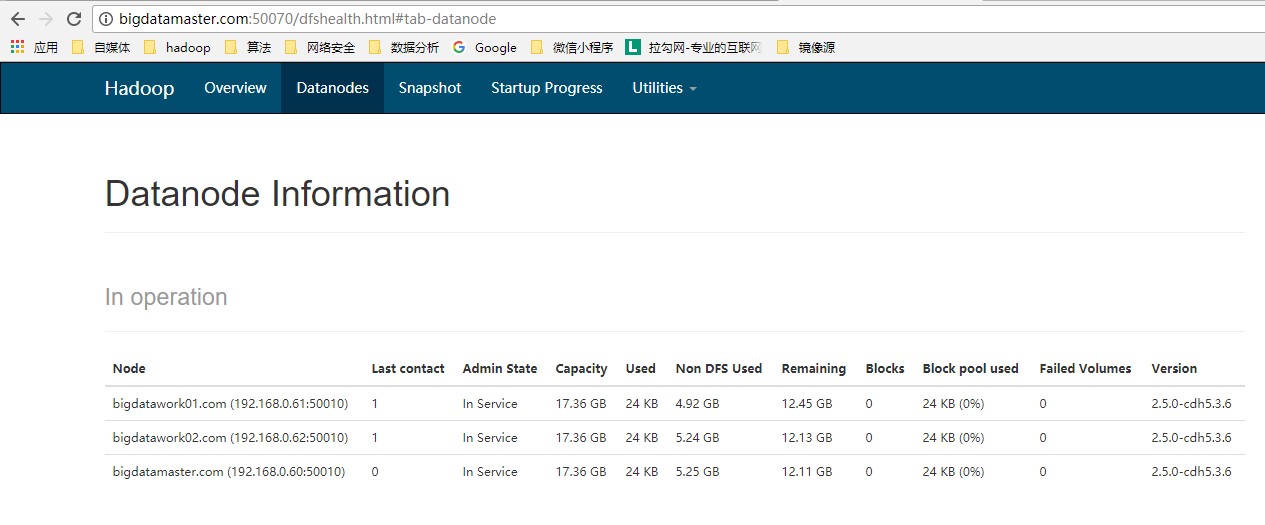















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









