 DeepSeek Token计费分析与成本优化策略
DeepSeek Token计费分析与成本优化策略





deepseek token计费分析
大模型的计费方式都是依据token来计算,但大部分人都没有好好研究过这个token的计算方式,弄清楚token计费方式才能更好使用大模型并控制成本。
下表是deepseek api 的收费方式:
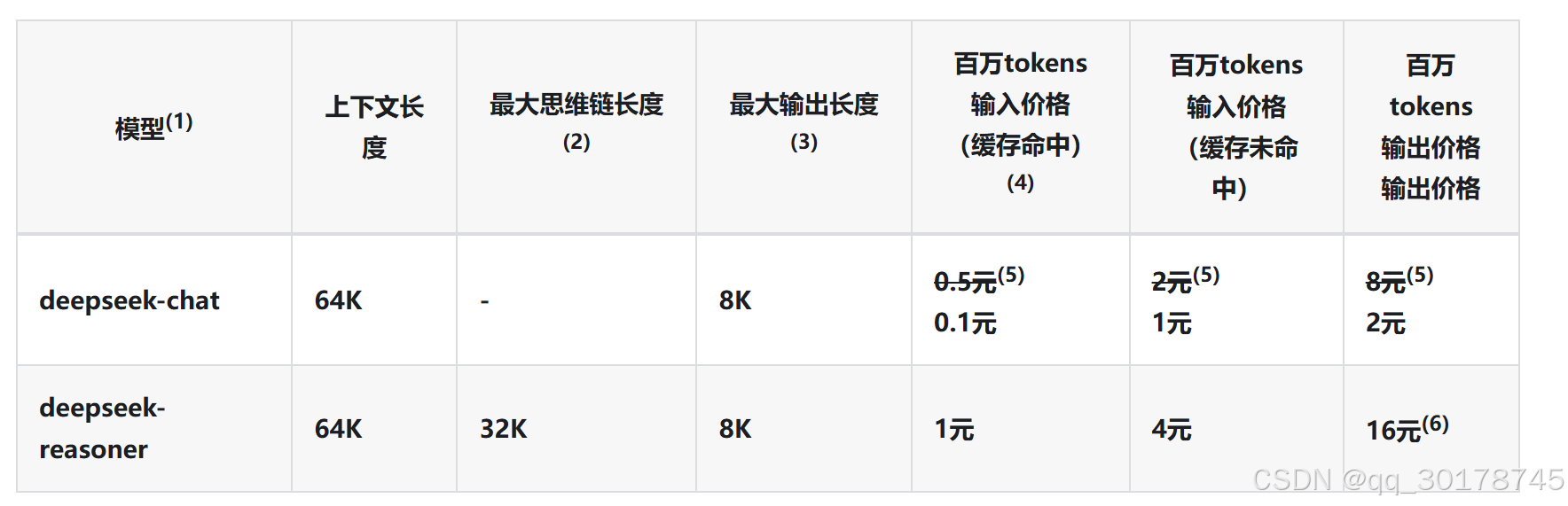
根据官方消息:表格中展示了优惠前与优惠后的价格。即日起至北京时间 2025-02-08 24:00,所有用户均可享受 DeepSeek-V3 API 的价格优惠。 在此之后,模型价格将恢复至原价。DeepSeek-R1不参与优惠。因此有需求的话还是赶在涨价前买,deepseek提价是迟早的事。
token 原理
token实质是将字符转化为大模型认识的数据的一种方式,类似于单词的词元。官方解释如下:token 是模型用来表示自然语言文本的基本单位,也是deepseek的计费单元,可以直观的理解为“字”或“词”;通常 1 个中文词语、1 个英文单词、1 个数字或 1 个符号计为 1 个 token。
一般情况下模型中 token 和字数的换算比例大致如下:
1 个英文字符 ≈ 0.3 个 token。
1 个中文字符 ≈ 0.6 个 token。
但因为不同模型的分词不同,所以换算比例也存在差异,每一次实际处理 token 数量以模型返回为准,您可以从返回结果的 usage 中查看。
对官方token例程进行改造,可以得到具体的值:
python deepseek_tokenizer.py --text "输入文本,dfafgagd,中国"
结果 #1:
------------------------------
文本: 输入文本,dfafgagd,中国
Token 数量: 9
Token ID 列表: [8979, 18804, 14, 5920, 2797, 73, 117308, 14, 2069]
解码验证: 输入文本,dfafgagd,中国
------------------------------
因此这句话的token数为9.
相关程序与deepseek_tokenizer分析可见以下链接,同时该文章中还加入了费用估算
deepseek_v3_tokenizer 使用与分析
代码例程
缓存命中与缓存未命中
它输入价格中分为缓存命中与缓存未命中,具体是怎么回事了?
缓存命中是计算机领域的一个核心概念,指当系统接收到数据请求时,所需数据已存在于缓存(Cache)中,无需从原始数据源(如数据库、API接口)重复获取。这一机制能显著提升响应速度并降低资源消耗
在 DeepSeek API 中的缓存命中场景
假设用户多次发送相同或相似的问题给模型:
首次请求:
用户提问 → 调用 DeepSeek API → 生成回答(消耗输入+输出 Token)。
将 问题+回答 存入缓存(例如以问题内容的哈希值为 Key)。
后续相同请求:
用户再次提问 → 检查缓存是否存在该问题 → 缓存命中 → 直接返回缓存的回答(不消耗 Token)。
若缓存过期或问题变化 → 缓存未命中 → 重新调用 API。
因此缓存是否命中关键在于deepseek是否被询问到之前的问题。
token费用计算公式
根据deepseek定价可以得出如下计算公式
总成本 = 输入成本(含缓存) + 输出成本
输入成本(缓存命中) = 输入 Tokens × 缓存命中单价
输入成本(缓存未命中) = 输入 Tokens × 缓存未命中单价
输出成本 = 输出 Tokens × 输出单价
假设请求量为 1,000,000 Tokens,缓存命中率为 80%:
(1) 使用 deepseek-chat 模型
计费项 计算逻辑 费用
输入(缓存命中 80%) 1M × 80% × 0.5 元 0.4 元
输入(缓存未命中 20%) 1M × 20% × 0.1 元 0.02 元
输出(假设生成 50%) 1M × 50% × 2 元 1 元
总成本 0.4 + 0.02 + 1 = 1.42 元
(2) 使用 deepseek-reasoner 模型
计费项 计算逻辑 费用
输入(缓存命中 80%) 1M × 80% × 1 元 0.8 元
输入(缓存未命中 20%) 1M × 20% × 4 元 0.8 元
输出(假设生成 50%) 1M × 50% × 16 元 8 元
总成本 0.8 + 0.8 + 8 = 9.6 元
相关分析
1.模型选择对成本影响巨大。
deepseek-chat 成本仅 1.42 元,而 deepseek-reasoner 高达 9.6 元,相差近 6.8 倍。
建议:优先使用轻量级模型(如 deepseek-chat)处理常规任务,保留高性能模型(如 reasoner)用于复杂推理。
2.缓存命中率对输入成本至关重要。
若 deepseek-chat 缓存命中率从 80% 降至 50%:
输入成本从 0.42 元 升至 0.5 × 0.5 + 0.5 × 0.1 = 0.3 元,总成本 1.3 元 → 1.8 元。
优化方向:通过预加载高频问题、动态调整 TTL 提升命中率。
3.输出成本占比显著:
deepseek-reasoner 输出成本占总成本的 83%(8 元 / 9.6 元),需严格控制生成长度(如设置 max_tokens)。
成本优化策略
1.动态模型路由根据任务复杂度自动选择模型(如简单问答 → chat,复杂分析 → reasoner)。
2.输出长度限制 通过 max_tokens 参数限制生成内容,减少输出 Token 消耗。
3.缓存分层设计 高频数据用内存缓存(如 Redis),低频数据用磁盘缓存,降低存储成本。
4.请求合并去重 对相似请求合并处理(如批量问答),减少重复调用。
注意事项
冷启动成本:新系统初始缓存命中率低,需预留预算缓冲期。
数据一致性:缓存内容需定期更新,避免模型升级导致旧答案不准确。
总结
通过合理选择模型、提升缓存命中率及控制输出长度,可显著降低 DeepSeek API 使用成本。建议结合业务需求实测不同策略效果,持续优化成本结构。

















 2563
2563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









