







如何获取公众号文章并保存有道笔记
写作目的
做这个程序是出于自己的学习目的。因为我有学习英语的习惯,每天看公众号TeachGwen的推送文章,并把相关文章短语词汇记录到有道笔记,方便以后复习。但又不是每次都可以在电脑面前学习,很多时候是对着手机看,手机上粘贴复制到有道笔记很麻烦,还容易出错。于是萌生了写个python爬虫自动抓取文章并保存有道笔记的想法。从有这个想法到最后写成,时间也不长,网上资料很多,实现也不复杂,主要使用了爬虫常用的request,xml解析等模块。
该程序分三部分:
1. 获取公众号文章链接
这部分参考了爬虫如何爬取微信公众号文章,利用微信订阅号里面的查询公众号文章的功能来爬取公众号文章的url,更新时间等信息。
-
https://mp.weixin.qq.com/ 在这里申请订阅号,注册登录后,在公众号系统里面->内容与互动->草稿箱->新的创作->写新图文->超链接->公众号搜索
如下: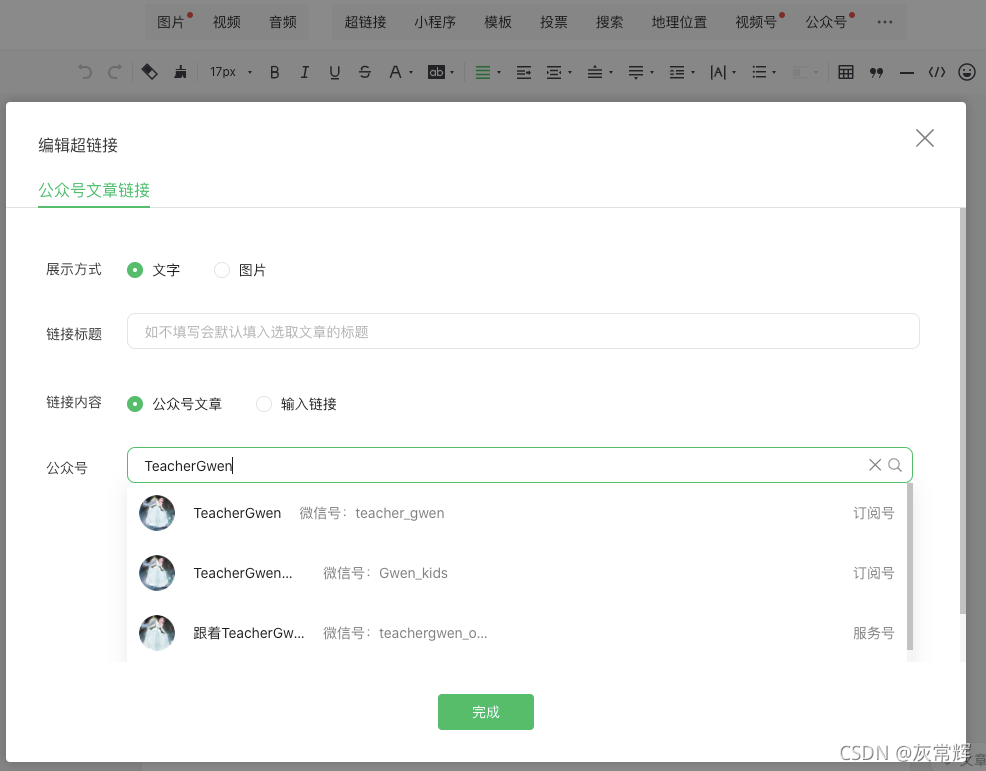
-
点击搜索,便出现了该公众号下所有文章的列表。
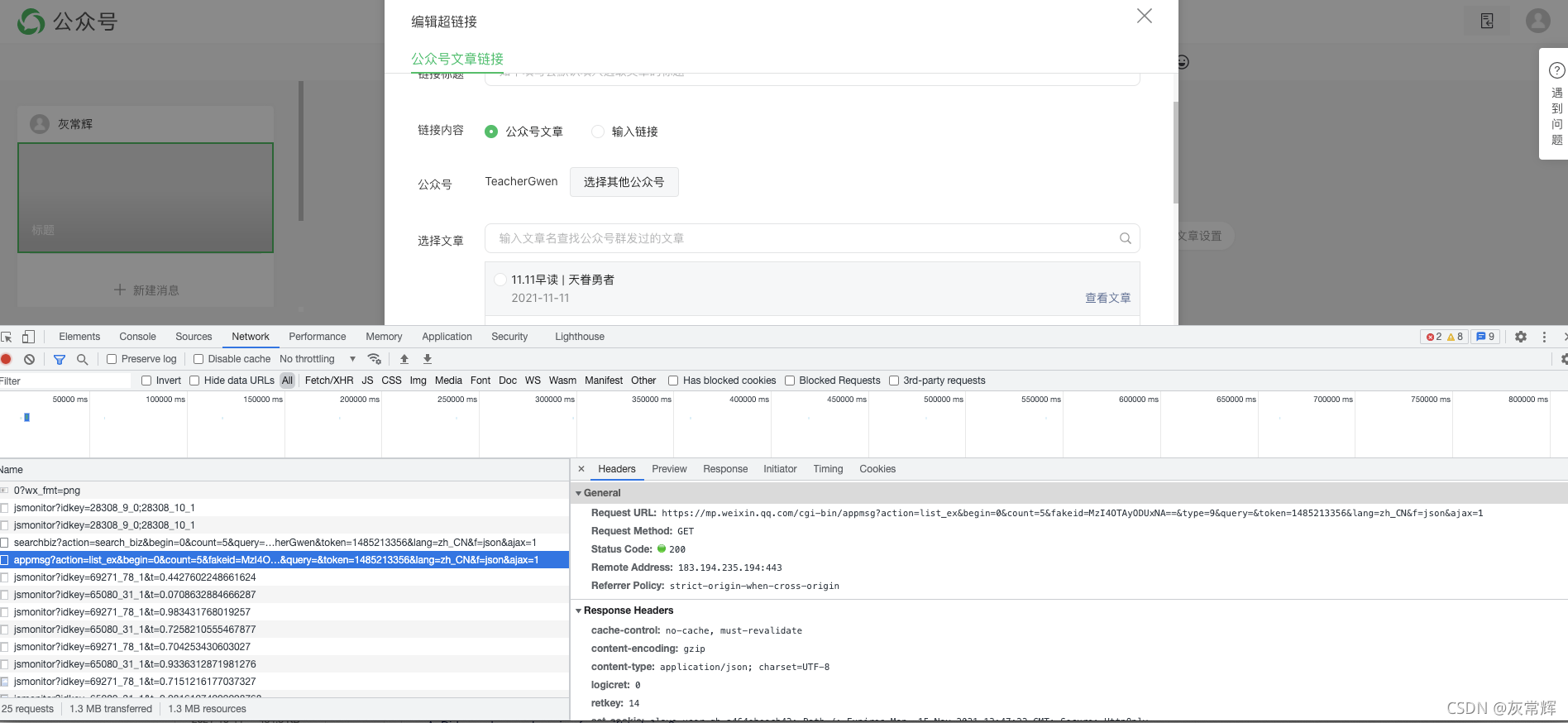
-
利用chrome中的develop tool获取 Request URL, Headers等信息来构造request请求包。
url里面包括了begin和count参数,表示翻页获取任何也一页内所有文章列表。同样可以构造不同的url来获取你想要页数的所有文章。 -
注意事项
- 因为公众号登录的cookie是有时效的,大概一周,不能一直使用一个cookie。
- python爬虫如何实现每天爬取微信公众号的推送文章方法也不再好用,因为微信网页版已经不能通过wxpy登陆,这个方法也无效。
- 而且登录需要扫描微信二维码,旦旦账号密码也不能完成登录。
- 目前只能自己手动登录获取cookie再执行程序,没有其他好的办法。如果有大神指点感激不尽。
self.headers = {
"Cookie": "appmsglist_action_3889698448=card; ***", #此处使用自己的cookie
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36",
}
for i in range(30):
self.BEGIN = str(i * 5)
url = "https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={BEGIN}&count=5&fakeid={FAKEID}&type=9&query=&token={TOKEN}&lang=zh_CN&f=json&ajax=1".format(
BEGIN=self.BEGIN, FAKEID=self.FAKEID, TOKEN=self.TOKEN)
r = requests.request("GET", url, headers=self.headers)
content_json = r.json()
200即成功返回,把其中的app_msg_list中的时间日期,标题,url link提出出来,保存到文件中。
for item in con 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









