









公众号:算法一只狗
今年以来,AI呈爆发式发展。在文本生成的领域,涌现出以ChatGPT为代表的生成式大模型。而在文本图像生成方面,有高度自定义的Stable Diffusion,和简单易用上手的Midjournery。多模态领域更是百花齐放,从GPT4的发布,到国内各大厂商的多模态模型,都证明这个领域具有极大的潜力。而在近期,视频生成领域有了爆发的可能性,众多免费可用的模型开源出来,像比较出名的Pika、Runway Gen 2等,成为各大巨头竞争的新领域。
这篇文章主要总结近一年以来,AI领域上的一些重要节点。

生成式大模型
GPT4
在年初发布的GPT4,确实给沉浸许久的AI圈投入了一个深水炸弹。对比于GPT3来看,GPT4提升幅度较大
- 在处理复杂任务上,GPT-4更可靠、更有创意,并且能够处理更细微的指令。
- 各种奥林匹克竞赛、GRE考试、代码考试、统一律师考试等测试上,GPT-4都基本完虐GPT-3.5

而且GPT4在视觉输入方面也大幅提升,它可以扮演老师的角色,解答图片的数学问题,又或者可以基于图片内容能够理解笑话。

LLAMA2
到目前为止,OpenAI并没有开源GPT4模型,开发者只能够调用其API。而META为了对抗GPT4垄断生成式领域,直接开源其模型LLAMA2,让开发者可以基于LLAMA2模型制作精细化领域大模型。

LLAMA2中,相比于LLAMA1主要引入了RLHF(人类反馈强化学习,也就是在训练ChatGPT提到的一个技术)。
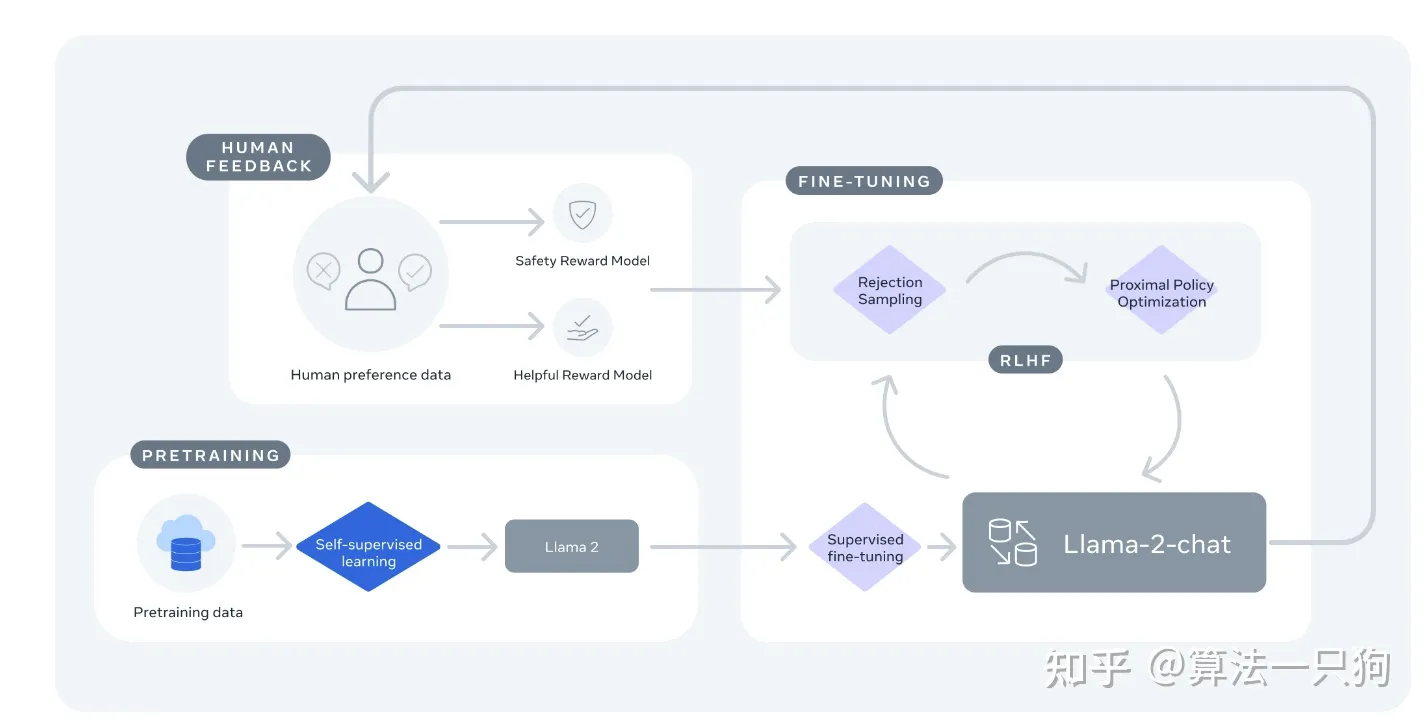
训练 Llama-2-chat:Llama 2 使用公开的在线数据进行预训练。然后通过使用监督微调创建 Llama-2-chat 的初始版本。 它使用人类反馈强化学习 (RLHF) 进行迭代细化,其中包括拒绝采样和近端策略优化 (PPO)。
Claude2
Claude2模型是Anthropic公司发布的第二代模型。说起这家Anthropic公司,其目标是成为一家研究人工智能安全和有益发展的公司,且由Dario Amodei和Daniela Amodei兄妹两于2021年创立。而且Dario Amodei曾在Open AI担任研究副总裁,领导了GPT-2和GPT-3等重要项目的开发。
所以说这家公司和OpenAI还是有一定的渊源的。只是因为后来,由于微软对OpenAI的投资,使其变成了专属于微软的CloseAI,Dario对其心存不满,因此就自立门户,创建了这家公司。
这个模型的优点在于免费可用,且其能够基于给定的多个文档进行回答。具有文档对话能力、和多个文档的联系对话功能。

Gemini
在最近,最为爆火的当然要属于谷歌发布的Gemini模型。从发布的Gemini模型来看,其具有三个不同的版本:
- Gemini Ultra:最强的Gemini版本,在多个测试结果上与GPT-4不分上下,但是目前还仅在demo状态。
- Gemini Pro:对标GPT-3.5模型
- Gemini Nano:致力于使得手机也能够运行大模型

而且谷歌宣传Gemini最强模型已经部分超越GPT4模型,但是最强模型目前暂时还不能用,说是要等到2024年才开放使用。
在谷歌放出Gemini的效果视频后,就有人开始打假说这个视频经过了剪辑。随后谷歌确实承认视频是经过前后剪辑。比如从下面视频看,以为是Gemini可以实时识别手部姿势,但是其实是谷歌给出了三个图片,让他说出答案的。

多模态领域
MiniGPT4
在多模态领域,GPT4一开始是不能够使用的。于是有些研究者等不及了,利用大语言模型和视觉编码器,训练了一个MiniGPT-4模型。
在MiniGPT-4模型中,你可以围绕一张图片和它进行对话:
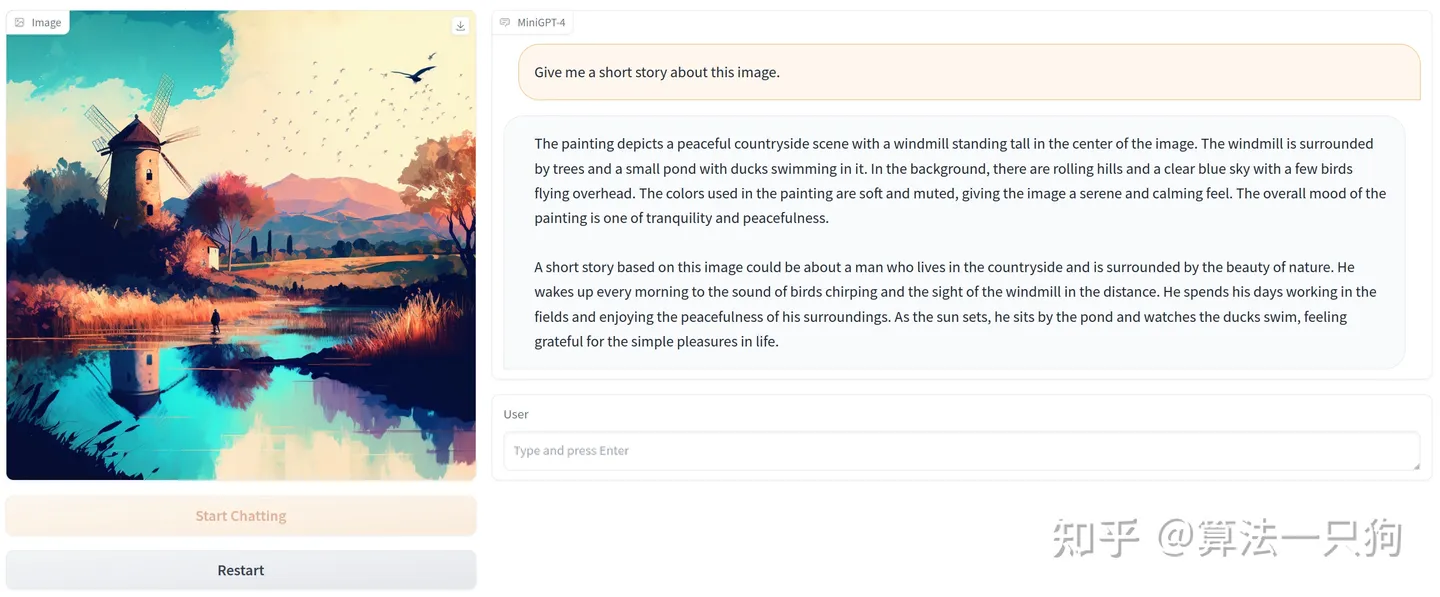
在官网放出的例子中,它可以描述这张图片的内容:
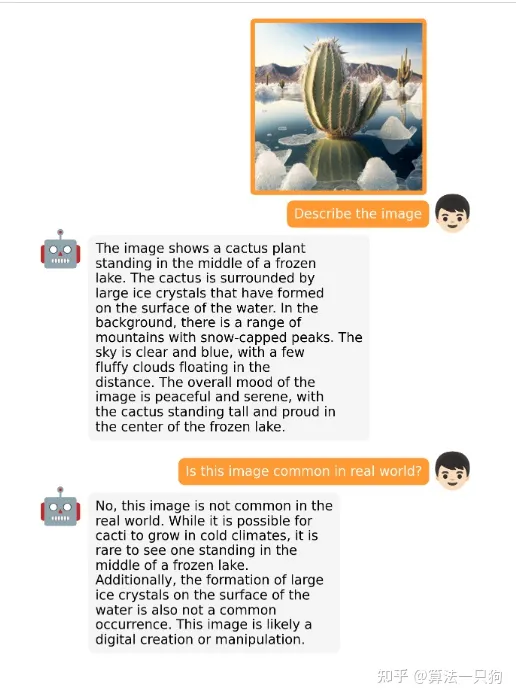
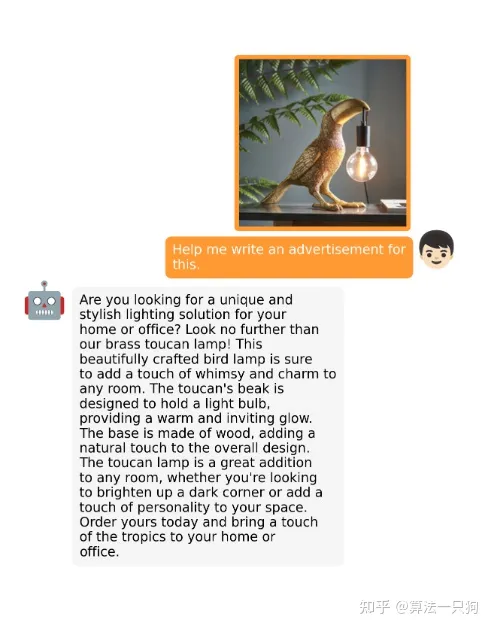
或者可以给这张图定制一个广告语:
文心一言
文心一言是集百度所有技术产生的国产模型。而且百度从很早开始就一直聚焦于AI技术,它也是国内处于第一梯度的大模型。
文心一言不仅仅能够进行文本生成,也能够输入文本进行图像生成。其功能比较强大,目前已经出到了4.0版本。

百度CEO李彦宏称:最新的4.0版本的综合能力与GPT4相比毫不逊色。从使用体验上看,文心一言在中文领域上对比ChatGPT使用效果更好,而且能够适合多种多样的场景,使用起来已经提前帮你设定好prompt,让你快速上手提升工作效率。
通义千问
通义千问是阿里发布的开源模型,其集成了文本生成、图片生成等能力,也可以让开发者基于该模型自定义自己的领域模型

从官网中介绍,通义千问有以下几个优点:
- 训练时使用了大规模的高质量数据:使用了超过2.2万亿token进行预训练
- 更好地支持多语言:基于更大词表的分词器在分词上更高效,同时它对其他语言表现更加友好。用户可以在Qwen-7B的基础上更方便地训练特定语言的7B语言模型。
- 支持8K长度上下文:允许用户输入更长的prompt。
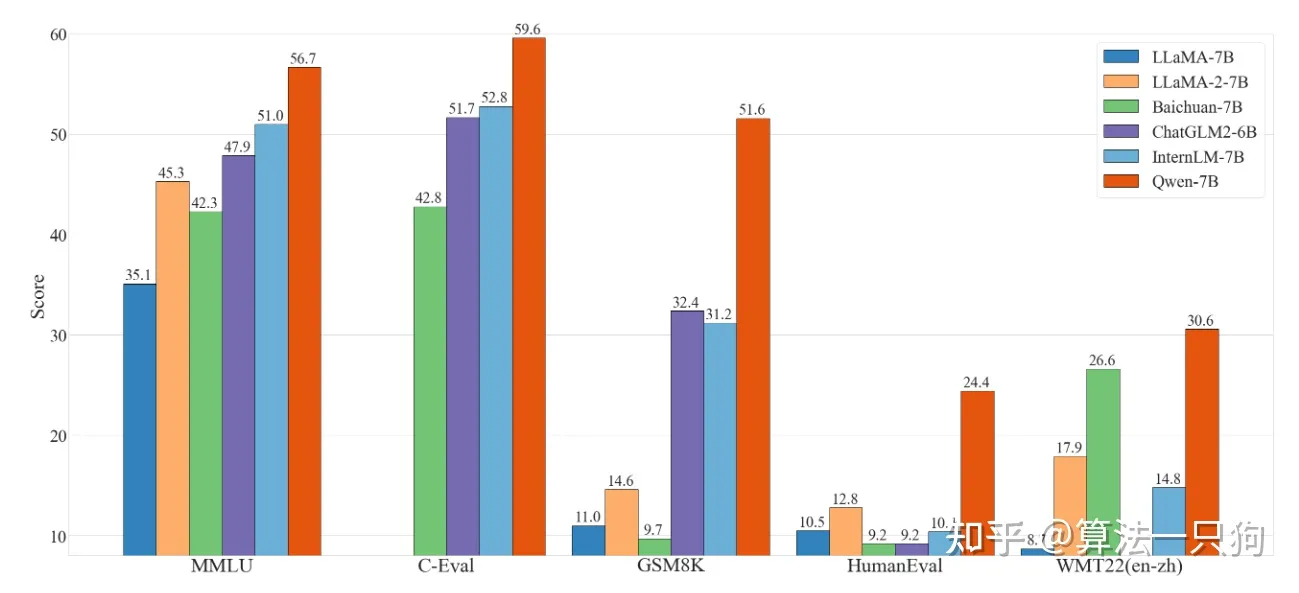
- 评测能力有大幅提升:通义千问在多个评测数据集上具有显著优势,甚至超出12-13B等更大规模的模型。
从实验中看出,通义千问模型在多个数据集评测上都超过现有的开源模型,而且甚至比之前META开源的LLAMA2-7B模型效果要好:
ChatGLM
经过前面两代版本的更新迭代,清华的ChatGLM第三代终于发布了,在实用性能上确实可以称得目前国内最好用的多模态大模型。
其功能涵盖了多方面,不仅仅包括简单的文本问答,图片问答,还有类似于ChatGPT一样的文档问答,代码解析器等。真正做到了多场景下的应用。
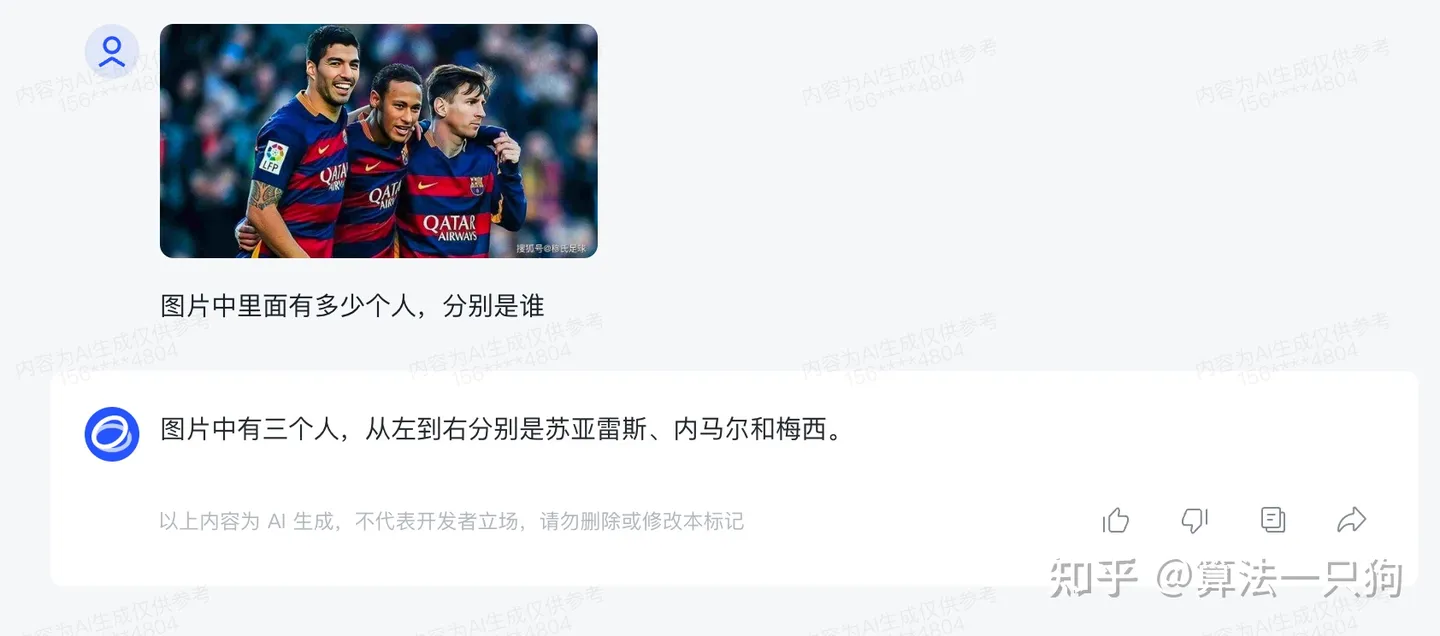
比如你可以问它类似于图片的内容: Q:图片中里面有多少个人,分别是谁
文本图像生成领域
Stable Diffusion
Stable Diffusion模型发布以来,“AI文本图片生成”真正的变成普通人也能使用的技术。
特别是在上半年,一些网友利用网上的真人图片,不断喂给模型进行自主学习。其训练出来的效果已经可以做到以假乱真,你甚至不知道哪些图片是AI生成的还是真人拍出来的。

而且开源的Stable Diffusion模型可以简单的部署到自己的电脑上进行使用,真的是免费的开源文生图工具。
Midjourney
除了上面比较出名的文生图Stable Diffusion外,另一个文生图利器当属Midjourney。它使用起来比Stable Diffusion模型要简单,只需要输入文本等待一段时间,就可以获得自己想要的图片。

同时调节图片的命令较为简单,因此很适合普通人快速上手生成图片。
视频生成领域
视频生成领域则是23年年末火起来的,很多有趣的技术,我都在下面这篇文章总结过,如果感兴趣的,可以看看下面这篇文章。
小白如何入门AI视频生成?这里总结了近一年的算法和工具 https://mp.weixin.qq.com/s/-mrQwQGHcGORpXlgLf5z_A
https://mp.weixin.qq.com/s/-mrQwQGHcGORpXlgLf5z_A
这里面主要介绍几个比较火的软件。
Pika
它是由斯坦福华人博士郭文景研究出的AI视频生成工具。目前在加入其Discord可以免费使用。
在discord网上上,可以上传一张图片进行生成:
可以看到我自己生成的表情包:

不仅仅是可以上传图片,也可以在图片的基础上,写入相应的prompt进行限制:
上传之后可以看到需要等待:
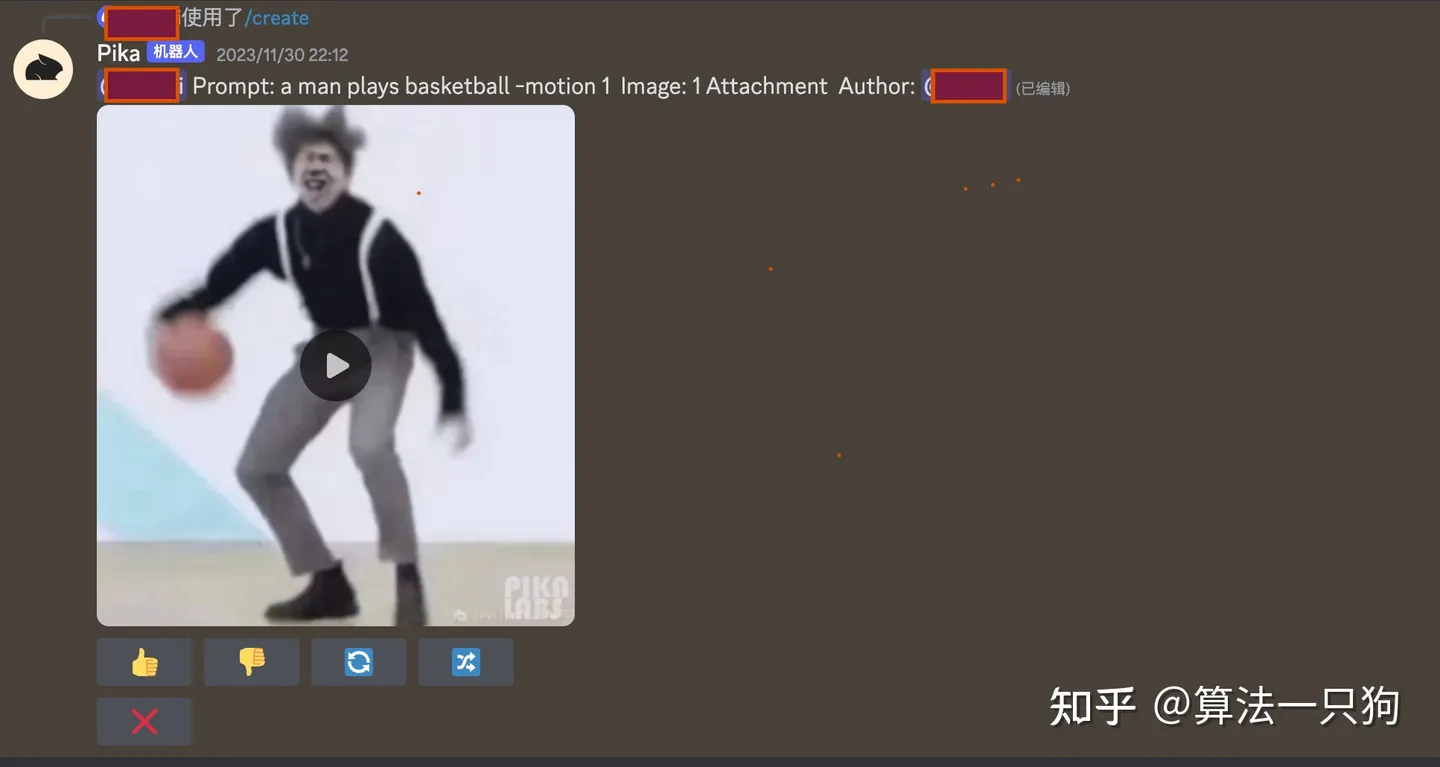
然后生成的gif图像这样:

CoDeF
从官方文档中介绍,CoDef是内容变形场的缩写(content deformation field),它将输入视频分解为2D内容规范场(canonical content field)和3D时间形变场(temporal deformation field):
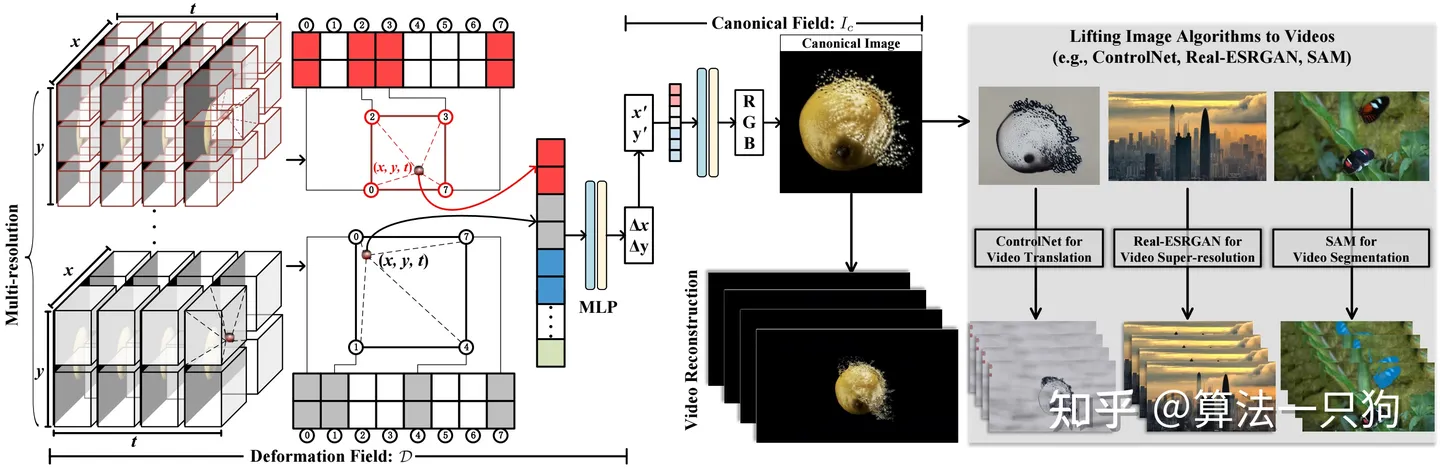
他们首先按在一张图片上进行转换,然后再转换为视频-视频之间的转换。更重要的是,由于仅在一张图像上部署算法的提升策略,与现有的视频到视频转换方法相比,在处理的视频中实现了卓越的跨帧一致性,甚至能够跟踪非刚性物体,例如水和烟雾。
总结
从2023年爆火的各领域AI来看,他们强大的功能正在进一步提升我们日常的工作效率。同时,由于其入手门槛较低,让普通人也能够接触到最为厉害的AI算法和工具,真正的改变我们的生活。
而AI的进步可能远远不止于此,它在今年的发展和进步让我们所有人感到了震惊。在未来,AI到底会进化成什么呢?没有人可以预估到。但是可以确信的是,AI将会走向更加强大,到时候将会惠及到更多的人,帮助人类解决更加复杂困难的东西。
以上就是这篇文章的主要内容了,我是leo,我们下期再见~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











