







在采用分库分表设计时,通过一个PartitionKey根据散列策略将数据分散到不同的库表中,从而有效降低海量数据下C端访问数据库的压力。这种方式可以缓解单一数据库的压力,提升了吞吐量,但同时也带来了新的问题。对于B端商户而言,如何查看这些数据呢?由于数据被散列到不同的库表中,想要查询它们就需要全库表路由查询,这样分库分表将无法带来优势。例如,生成的短链码散列到不同的数据库抵御了海量消费者的访问压力,但在业务层面上,商家无法查询到自己旗下生成的所有短链码。
方案一:
字段解析配置。定义hash对应的库表策略关系,每次生成库表位时,根据商家的唯一标识进行hash,找到固定的库表位,然后将短链写入该库表中。当商家查询时,同样根据商家的唯一标识进行hash,找到可能在的库表,采用笛卡尔积方式将数据查出,此种方式不触发全库表路由。
| 库 | 表 | 账号hash |
| a,b | c,1 | 1 |
| a | 1 | 2 |
难点:随不触发全库表的路由,但所涉及库表都会进行查询,给所涉及的库表造成访问压力,结果聚合呈现,但存在了无效查询,不够干脆利落。
方案二:
Nosql方案。可利用canl-server监听数据库的变动,kafka缓冲,冗余到es中。
难点:需同时维护两套不同类型数据库,遵从各自数据库存储管理规则,增加了技术栈的复杂性和学习成本,且采用Nosql数据库方式数据并不安全,数据一致性也难以保证。介于当时团队的技术能力,更多采用了第三种方案。
方案三:
冗余双写方案。在数据库中拆分买家库和卖家库:1)买家库,按照用户的id来分库分表;2)卖家库,按照卖家的id来分库分表。下订单的时候需写两份数据,即在买家库和卖家库各写一份。
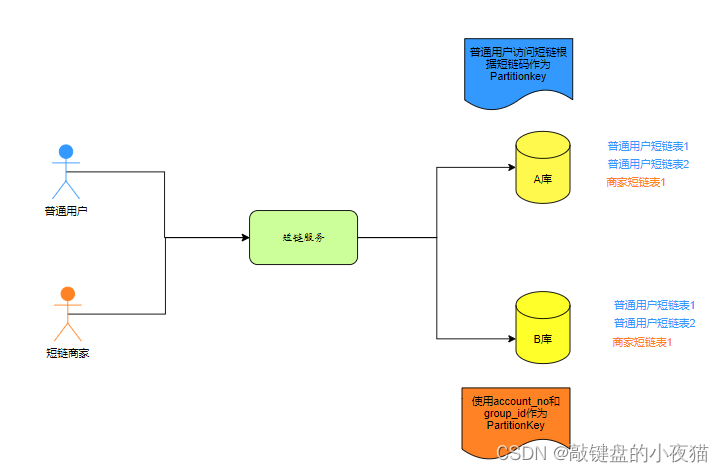
难点: 带来一定的技术栈复杂性(以当时的技术团队而言在接受范围),但同时需面临海量数据环境下数据一致性、错误处理机制问题(且看后面一一解决)















 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









