







概述
引入的原因
- 关系型数据库局限
- 不能直接管理非结构化数据
- 受单机服务器限制难以支持数据库高并发读写访问
- 受磁盘容量限制不能满足海量数据的高效存储和处理
- 实现分布式数据库的高扩展性、高可用性比较复杂
- 对数据处理的要求
- 对各类数据的管理
- 大量用户同时访问应用要求数据库支持高并发读写访问
- 大量数据需要数据库高效存储
- 要求数据库有高拓展性和高可用性
大数据管理
定义:指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合
特点
- 大量
- 高速性
- 多样性(区别于传统关系数据库的最重要特性)
- 真实性
- 低价值(单个数据单元)
挑战
- 数据类型多样性与异构性
- 海量数据存储访问高速性
- 数据处理的时效性
- 数据的安全与隐私保护
- 大数据的能耗问题
- 大数据管理易用性问题
存储关键技术包括:
- 分布式数据存储(在分布式数据库的基础上更高的数据访问速度;更强的可拓展性;更高并发访问量)
- 数据一致性和可用性
- 负载均衡
- 容错机制
- 虚拟存储技术
- 云存储技术
在可用性、一致性、高并发、高容量等方面达到平衡
NoSQL数据库
Not only SQL Database,非关系型、开源代码、具有水平扩展能力的分布式数据库
特性
- 支持非结构化数据存储,不用预先定义模式
- 分布式集群架构,无共享结构
- 弹性可扩展,可动态增减数据库结点
- 数据分区存储,各分区结点并发访问.
- 结点之间数据异步复制,实现最终数据一致性
- 数据处理遵循BASE特性原则
BASE特性
- Basically Available(基本可用):允许部分出现故障
- Soft state(软状态):允许数据库系统存在暂时的数据不一致,经过纠错处理,系统数据最终保持一致态
- Eventual Consistency(最终一致性):系统数据在某一时刻达到最终一致性
数据库一致性
- 强一致性:无论更新在哪一个副本,数据复制时同步的,之后所有的数据库节点都能获取最新的数据
- 弱一致性:数据更新在数据库节点执行,但数据复制时异步的,需要经过一定的时间才能到达不同数据库节点数据一致
- 最终一致性:用户最终能读到某操作对系统特定数据的更新
最终一致性的形式
- 因果一致性:B是基于A的数据,A更新,B也更新
- 读一致性:
- 会话一致性:
- 单调读一致性:
- 单调写一致性:
类型及对比
| 分类 | 典型数据库 | 应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值存储数据库 | Redis,Voldemort,Oracle BDB | 主要用于处理大量数据的高性能访问负载,也用于一些日志系统等. | Key-Value键值对,通常用哈希表来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制串 |
| 列存储数据库 | HBase,Cassandra,Rjak | 分布式的联机事务处理系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,容易进行分布式扩展 | 功能相对局限,不适合随机的更新 |
| 文档存储数据库 | MongoDb,CouchDB | Web应用 | Key-Value对应的键值对,Value为版本化文档 | 数据结构要求不严格,表结构可变,不需要预先定义表结构 | 查询新能不高,而且缺乏统一的查询语法 |
| 图存储数据库 | Neo4J,InfoGrid,Infinite Graph | 社交网络,推荐系统 | 图结构 | 利用图结构相关算法进行快速查找 | 需要对整个图做计算才能得出需要的信息,而且这种结构不容易实现分布式的集群方案 |
整体框架

优点
- 高可扩展性
- 分布式计算
- 低成本
- 架构灵活
- 没有复杂的关系
缺点
- 缺乏通用性
- 不支持SQL查询功能
- 不支持事务特性
- 系统安全特性欠缺
应用场景
- 解决传统关系型数据库无法解决的数据存储及访问问题
- 解决大数据多样性、异构性、高速性等数据存储与处理问题
- 解决互联网海量非结构化数据管理与应用问题
与关系数据库比较
- NoSQL数据库采用非结构化数据存储模型,关系数据库采用结构化数据存储模型
- NoSQL数据库采用分布式部署,关系数据库采用集中式部署
- NoSQL数据库编程遵循BASE原则,关系数据库编程遵循ACID事务原则
- NoSQL数据库没有统一的数据操作标准,关系数据库遵循SQL数据操作标准
- NoSQL数据库支持海量数据存储,关系数据库数据存储受限于TB级
分布式数据库
优点
(1)具有灵活的体系结构
(2)适应分布式的管理和控制机构
(3)系统的可靠性高、可用性好
(4)局部应用的响应速度快
(5) 可扩展性好,易于集成现有系统
缺点
(1)系统通信开销大
(2)系统存取结构复杂
(3)数据安全性和保密性较难处理
数据不一致产生的情况
1)数据库结点故障
2)通信网络出现故障
3)两阶段提交过程中出现问题
CAP理论
- 一致性(Consistency):不同节点数据库保持一致
- 可用性(Availability):数据访问请求随时可满足
- 分区容忍性(PartitionTolerance):当出现故障结点,系统任能响应数据访问请求
CAP证明:出现故障结点下,三种属性最多只能满足两种
证明:
- 满足C和A时,P
- 满足C需要所有服务器节点的数据要一样,这样要求数据库在不同服务器节点进行复制同步. 结点越多,时间越多
- 满足A,同步的时间必须足够短才行,因此系统的服务节点数不能太多
- 节点数少了,就不能保证结点故障时仍能满足P
- 满足C,P
- 满足P,需要足够多的节点
- 满足C,复制同步的时间因为P所以会比较长
- 所以难以满足A
- 满足A,P
- 满足P,需要足够多的节点
- 满足A,复制同步的时间要短(受限)
- 因为节点多,时间不够,所以C难以满足
当网络发生故障,服务器间数据不一致.
有如下两种解决方案
- 牺牲数据一致性,将老数据传给请求的应用
- 牺牲可用性,阻塞等待,直到网络连接恢复
CAP模型方案选择
- CA——放弃分区容错性:即传统的单机数据库处理方式
- AP——放弃强一致性:大多数分布式系统的设计方式。如一些电商系统(用户规定时间内提交请求满足)
- CP——放弃可用性:很多NoSQL系统采用的方案
列存储数据库
- 纵向切分数据
- 对于稀疏表,存储效率加快高
- 一般会按行键值排序,加开了分布式检索速度
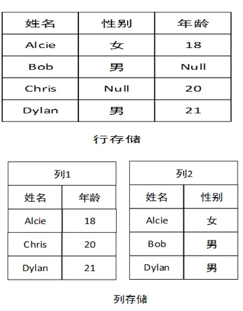
与关系型数据库对比
如果要查询年龄情况,关系型数据库需要读取多个(所有)数据磁盘块,但是列存储数据库只需要读取某一块即可,时间短
HBASE数据库
全称:Hadoop Database,构建在Hadoop大数据平台上
- 开源非关系型分布式数据库,用于存储海量非结构化与班结构化数据
- 建立在HDFS,具有自动故障转移、自动分区、水平扩展等特性
与关系数据库比较

HBASE数据模型
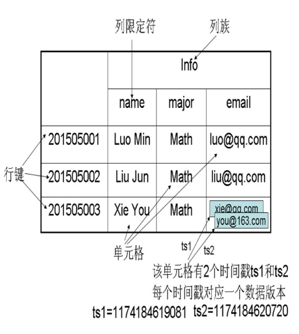
- 表:用表来组织数据,表由行列组成,列划分为若干个列族
- 行:每个行由行键来标识
- 列族:一个表被分组成许多“列族”,基本的访问控制单元
- 列限定符:通过列限定符来定位列族内数据
- 单元格:
- 时间戳:每个单元格存放的多个数据通过时间戳来索引
根据行键、列族、列限定符和时间戳来确定一个单元格
物理存储
- Table所有行都按照row key的字典序排列
- Table在行的方向上分割为多个区域(Region)
- Region按大小分割,Region里的数据增加到阈值时等分为两个新的Region(表最开始只有一个Region)
- Region是Hbase中分布式存储和负载均衡的最小单元,不同的Region分不到不同的RegionServer上
- Region由一个或多个存储单元Store组成,每个store保存一个列簇。每个Store由一个内存单元和0至多个StoreFile组成。StoreFile以File格式保存在HDFS上
















 3065
3065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









