






什么树形结构 节点等等的概念在这里就要不做阐述了 直接进入主题
1:创建被读取的XML文件
<?xml version="1.0" encoding="UTF-8"?>
<!--
以书类为例
书店-书-属性
-->
<bookStore>
<book id="第一本书">
<name>Spring 入门到精通</name>
<author>Spring 作者</author>
<year>1998</year>
</book>
<book id="第二本书">
<name>Java 设计模式</name>
<author>Java 作者</author>
<year>2001</year>
</book>
</bookStore>2:创建Java类 下边的代码注释挺多的
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Iterator;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import org.jdom2.Attribute;
import org.jdom2.JDOMException;
import org.jdom2.input.SAXBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class Test {
//dom 解析
public void test0() {
//创建解析环境
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();
Document document = documentBuilder.parse("config/ReadXML1.xml");
//NodeList为接口 所有bean节点属性集合 匹配的 Elements 的新 NodeList
NodeList bookRoot = document.getElementsByTagName("book");
for (int i = 0; i < bookRoot.getLength(); i++) {
//获取到book节点
Node book = bookRoot.item(i);
//book节点所有属性的值
NamedNodeMap bookAttr = book.getAttributes();
for (int j = 0; j < bookAttr.getLength(); j++) {
//划分
Node bookNode = bookAttr.item(j);
String name = bookNode.getNodeName();
String value = bookNode.getNodeValue();
System.out.println("属性 "+name+" : "+value);
}
/**
//已知节点属性个数和属性名可以这样读取
Element bookElement = (Element) bookList.item(i);
String value = bookElement.getAttribute("id");
System.out.println("属性 "+value);
*/
//Element和文本类型节点总数 所有子节点
NodeList bookNextList = book.getChildNodes();
for (int j = 0; j < bookNextList.getLength(); j++) {
Node bookNextNode = bookNextList.item(j);
//System.out.println("=="+bookNextNode.getTextContent());
//节点类型判断 基础对象的类型的节点
//System.out.println("节点类型"+bookNextNode.getNodeType());
if (bookNextNode.getNodeType() == Node.ELEMENT_NODE) {
String name = bookNextNode.getNodeName();
//从节点获取 - 如果还有子节点会返回null
//String value = bookNextNode.getFirstChild().getNodeValue();
//节点中所有内容 - 如果有子节点会将直接点的内容一块输出
String value = bookNextNode.getTextContent();
System.out.println("book子节点内容 "+name+" : "+value);
}
}
System.out.println("======遍历此book节点结束======");
System.out.println();
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//DOM4J解析
public void test1() {
//创建解析实例
SAXReader saxReader = new SAXReader();
try {
//加载xml 获取document对象
org.dom4j.Document document = saxReader.read(new File("config/ReadXML1.xml"));
//获取根节点
Element bookRoot = document.getRootElement();
//获取迭代根节点下信息
Iterator<Element> bookIterator = bookRoot.elementIterator();
while (bookIterator.hasNext()) {
Element book = (Element) bookIterator.next();
//获取Book的所有属性名与值
List<org.dom4j.Attribute> bookArrtList = book.attributes();
for (org.dom4j.Attribute bookArrt : bookArrtList) {
//节点属性名
String name = bookArrt.getName();
//节点属性值
String value = bookArrt.getValue();
System.out.println("属性 "+name+" : "+value);
}
//迭代book子节点信息
Iterator<Element> bookNextItertor = book.elementIterator();
while (bookNextItertor.hasNext()) {
Element bookNext = bookNextItertor.next();
//节点名
String name = bookNext.getName();
//节点值
String value = bookNext.getStringValue();
System.out.println("book子节点内容 "+name+" : "+value);
}
System.out.println("======遍历此book节点结束======");
System.out.println();
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
//JDOM解析
public void test2() {
SAXBuilder builder = new SAXBuilder();
try {
InputStream inputStream = new FileInputStream("config/ReadXML1.xml");
//转换编码
InputStreamReader inr = new InputStreamReader(inputStream, "UTF-8");
org.jdom2.Document document = builder.build(inr);
//获取根节点
org.jdom2.Element rootElement = document.getRootElement();
//根节点下的子节点集合
List<org.jdom2.Element> bookElementList = rootElement.getChildren();
for (org.jdom2.Element bookElement : bookElementList) {
//book所有属性的集合
List<Attribute> bookAttrList = bookElement.getAttributes();
for (Attribute bookAttr : bookAttrList) {
String name = bookAttr.getName();
String value = bookAttr.getValue();
System.out.println("book属性 "+name+" : "+value);
}
//直接获得book属性值
Attribute bookAttr = bookElement.getAttribute("id");
String name = bookAttr.getName();
String value = bookAttr.getValue();
System.out.println(bookAttr.getName()+"---"+bookAttr.getValue());
//book自己的节点进行遍历
List<org.jdom2.Element> bookNextNodeList = bookElement.getChildren();
for (org.jdom2.Element bookNextNode : bookNextNodeList) {
String name = bookNextNode.getName();
String value = bookNextNode.getValue();
System.out.println("book子节点内容 "+name+" : "+value);
}
System.out.println("======遍历此book节点结束======");
System.out.println();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (JDOMException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}自我感觉Java常用的读取XML的方法就是DOM和DOM4J两种,但是别的读取方法也要稍微说一下
1:DOM解析:
它是直接将XML文件读取到内存,首先不能否认的是读取过之后它的效率之高;但是同时体现了DOM读取XML的劣势内存资源的占用消耗,树形结构来存储读取的数据;
2:SAX解析:
SAX因为他是从上到下一行一行的解析 所以在读取XML的速度和效率上是毋宁质疑的;但是因为它读取到下一行的时候本行的数据就会释放,因此也限定的它的便捷性;(PS:这也是我没有介绍它的原因、听说SAX解析在安卓中会大量使用)
3:DOM4J解析
这个目前来说是用的最多的一种解析方式;它是基于DOM的一种解析方式;速度和便捷性一定情况下也不比SAX解析差多少;
4:JDOM解析
这个就不说了,我个人对它的理解是一个过渡的解析方式;
最后附带一张XML节点类型的图 (图片来自网络)
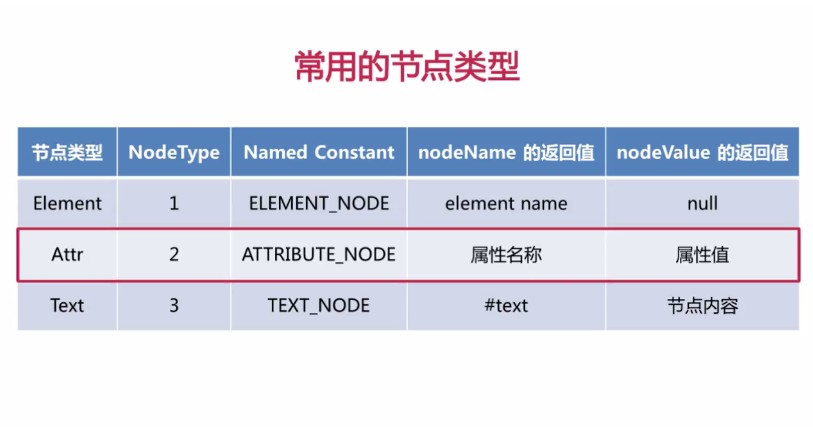















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









