






这是篇IEEE的文章,录入与2018.2
摘要
item-CF已经由于其可解释性和有效的实时个性化性多用与工业数据。它通 过用户历史交互构成的用户profile,给用户推荐和用户profile相似的新的item。因此,item-CF的关键就是评估item之间的相似性。早期的方法是使用余弦距离或皮尔逊距离。因为其缺少针对推荐任务的定制优化,准确度有点低。近几年来,一些研究工作,试图去从数据中学习相似性,通过表示相似性作为潜在模型,通过优化推荐感知对象函数评估模型参数。尽管有很多扩展工作在使用浅层线性模型去学习相似性,但是很有少研究非线性模型。我们提出了一个叫NAIS的神经网络模型,去解决item-CF。NAIS的关键是注意力网络。对比于最新的item-CF方法,因式分解相似模型FISM(factored item similarity model)我们的NAIS有超强的表示能力,但是他只有通过使用注意力网络而有的很少的额外参数。在两个数据集上的实验,证明了NSIA的更有效。这是第一次在item-CF中使用神经网络,开启了未来研究神经推荐系统的先河。
1introduce
在现代推荐系统中,CF在候选产生阶段扮演了一个很重要的角色,咋NetFlix Prize中,MF(matrix Factorization)矩阵分解方法,变得越来越受欢迎并得到了广泛的研究。尽管MF就评级预测方法具有超高的准确率,但它很少被用于工业应用。可能的原因之一就是,MF的个性化方案:user-to-item CF,用ID来表征用户并与嵌入向量相关联。导致的结果就是,当一个用户有了一个新的交互,就需要更新推荐、更新用户嵌入向量。然而,再次实时训练大规模的MF模型是很困难的,并且需要复杂的软件堆栈去支持在线学习,所以在工业上很少用。
另一方面,item-CF,有一个特点:用户的推荐item和历史item相似。这已广泛应用于工业。不仅因为,其具有强可解释性,而且它可以使得实时个性化更容易实现。
具体来说,评估相似性的计算离线进行,在线的推荐模型只需要去执行,查找相似项就好了,这很容易达到实时。
早期的item-CF方法,使用静态方法计算距离,比如皮尔逊距离和余弦距离。因为这样的启发式方法(根据经验而来,并非最优解)缺乏定制优化,他们的性能比不上基于机器学习模型的准确性。为了解决这个,**Ning在item-CF上采用机器学习方法,通过优化推荐感知目标函数,从数据中学习item的相似性。**尽管可以达到良好的准确率,但是直接学习总体item-item的相似性矩阵的复杂度是乘方级的wrt。所以没法灵活得预测对那种几百万甚至上亿的数据进行预测。
为了有效的解决基于item-to-itemCF的学习问题,CK提出了因式分解item相似模型,它用嵌入向量表示一个item,通过两个item嵌入向量的内积建模相似性。作为表示学习的起源,FISM提供了良好的准确性且适合于在线推荐应用场景。然而,我们认为,FISM模型的保真度被其假设限制。因为直观来说,用户以前交互过的诸多item中,很些交互可能不是能够真实反应用户兴趣的,比如,一个爱看剧情片的人突然看了个很火的恐怖片。另一个例子是用户兴趣可能随着时间而改变,因此,最近交互的项目应该更反映用户未来的偏好。
在我们的论文中,我们提出通过区分不同重要性的交互item,来增强模型相似性,以对用户爱好起作用。NAIS是在FISM的基础上提出来的,它保留了FISM的优点,高效的预测能力。然而他比FISM更强的地方在于,学习了交互的item的不同的重要程度。这是采用注意力模型实现的。我们注意的一个发现是,标准的注意力机制不能学习用户历史数据,因为这些数据长度有很大变化。为了解决这个问题,我们对用户历史记录进行平滑处理。我们进行综合的实验,实验证明,NAIS就NDGG方面比FISM性能好,。
论文的其余部分如下。在介绍第二节的一些预备知识之后,我们在第三节详细阐述了我们提出的方法。然后我们在第4节中进行实验评估。在结束第六节的整篇论文之前,我们将在第五节讨论相关的工作。
2 preliminaries
21 标准的基于item的CF
依靠计算item i与用户以前交互过的item的距离来得到目标item i,进行预测用户u的目标item i。一般的基于item的CF的模型如下:
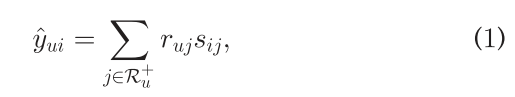
Ru^+表示:用户u交互过的item集,sij表示itemi和j的相似度,ruj表示用户u和itemj的交互即已知的u对j喜欢。这是显示反馈,也可以用隐式反馈,只要u与j发现交互,比如浏览,购买等,就说ruj等于1否则为0。高效在线推荐的优势在于它在计算预测得分时的组合性。首先,当离线获得item相似性时,在线推荐阶段只需要检索候选项目的顶部相似item,并用公式(1)对其进行评分。其次,为了用新交互刷新用户推荐,我们只需要考虑与新交互的item类似的item。这种增加的复杂性使得基于项目的CF非常适合在线学习和实时个性化。
对于item相似性sij,直观的方法是将一个item表示为其交互的用户,并应用相似性度量,如余弦相似性和皮尔逊系数。另一种常见的方法是在用户-item交互图上采用随机游动。然而,这种基于启发式的项目相似度估计方法缺乏针对推荐的优化,因此可能产生次优性能。接下来,我们介绍了基于学习的方法,其目的是通过自适应地从数据中学习item相似度来提高基于项目的CF的准确性。
2.2基于学习的基于item的协同过滤
SLIM(short for sparse Linear Method),通过优化推荐感知目标函数,来学习item的相似性。这是方法是通过最小化原始交互矩阵和从基于item的CF中得到的重构矩阵的损失。最终的目标函数如下:

其中S表示,item-item的相似性矩阵,B控制L2范数以防过拟合。注意SLIM有三个带有目的性的设计,去约束S,以保证有效的学习item的相似性。1)由r去控制L1范数,增强稀疏。2)对S个元素的非负性约束,使其是一个有意义的相似性度量3)diag(s)=0消除item本身对其的影响。
尽管可以更好地推荐精度,SLIM有两个固有的局限性。1)离线训练大规模数据很耗时,因为,I^2元素需要计算。2)只能学习两个item之间的相似度,不能捕捉有关系的item的传递性。为了解决这个问题,提出FISM(short for factored item similarity model),其用低维度嵌入向量表示item,sij是itemi和itemj嵌入向量的内积。

其中,a是控制泛化效果的超参数,pi,qj是item i和j的嵌入向量。{i}对应于diag(s)=0,为了避免目标item的自我相似度建模。
从基于用户的CF的角度来看,括号中的术语可以看作用户u的表示,它是从u的历史item的嵌入中聚合的。注意,FISM中每个item都有两个嵌入向量pq去区分其预测目标和历史相互的角色,这可以增强模型的表示,评级ruj被省略了。FISM只考虑隐式反馈。对于给定的方程(3)的预测模型,可以通过优化推荐的标准损失(即,没有SLIM中使用的项目相似性约束)来学习模型参数,例如逐点分类损失[5]和成对回归损失[18]。
虽然FISM在基于item的CF方法中提供了最新的性能,但我们认为,当获得用户的表示时,它对用户的所有历史项目的平等处理会限制其表示能力。如前所述,这个假设是不符合现实的,可能降低模型的保真度。我们提出的NISM模型通过利用神经注意网络区分历史item的重要性来克服FISM的这种局限性。
3 神经注意力item相似性模型
在这一节中,我们提出我们提出的NAIS方法。在介绍NAIS模型之前,我们首先讨论了几种注意机制的设计,试图解决FISM的局限性。然后,我们详细阐述了模型参数的优化。我们集中讨论用隐式反馈优化NAIS,这是最近推荐研究的焦点,因为隐式反馈比显式评级更普遍,更容易收集。最后,我们讨论了NAIS的几个特性,包括时间复杂度、对在线个性化的支持以及注意功能的选择。
3.1 模型设计
(1)注意力的最初想法是模型的不同部分可以为最终的预测不同地贡献。在基于item的CF场景中,我们可以直观地通过为每个历史item分配个性化的权重来对用户的表示作出不同的贡献。
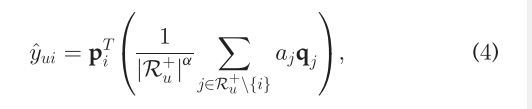
aj是item j的注意力权重,aj=1就是FISM.虽然这个模型似乎能够区分他的历史项目的重要性,但它忽略了目标项目对历史项目的影响。特别地,我们认为,为历史项目分配所有预测的全局权重是不合理的,而不管预测哪个项目。例如,在预测用户对浪漫电影的偏好时,不希望将恐怖电影与另一部浪漫电影同等重要。从用户表示学习的角度出发,假设用户具有表示其兴趣的静态向量,这可能限制了模型的表示能力。
(2)为了解决(1),使用aij表示每对(i,j)的权重。
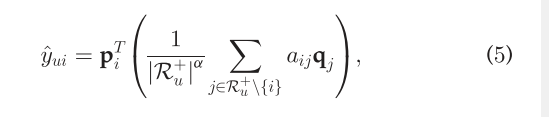
其中aij,当预测用户u对i的偏好时,以i为目标,j的注意力权重。但是缺点是如果(i,j)在训练数据中要是没有重复出现的话,注意力权重就不能算出来。
(3)为了解决(2)中的泛化问题,我们建议用嵌入向量pi和qj算出aij。基本原理是,嵌入向量可以编码item的信息,因此他们可以用于决定(i,j)的权重。具体的公式如下:

优点是即使(i,j)没有出现,只要pi和qj是真实数据,仍然可以去计算aij。为了实现这一目标,我们需要确保这个函数有的表现能力。受到最近的神经网络去建模注意力机制的启发,我们使用多层感知器去参数化注意力函数f,特别的,我们采用两个方法去定义注意力网络。
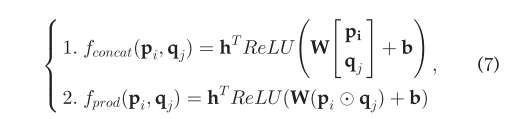
其中w和b分别表示从输入层到隐藏层权重矩阵和偏置向量,h^T是从隐藏层到输出注意力权重的向量。我们将隐藏层的大小作为注意力因子,值越大注意力网络的表示能力越强。我们使用ReLU作为隐藏层的激活函数,它在神经注意力网络上表现了好的性能。3.3讨论两个函数的优缺点。
标准的神经注意力的公式如下:

前面几个式子里的1/(|Ru+|a)被去掉了,不让其影响表示能力。用softmax将注意力权值转化成概率分布。注意到,这是最直接的方法,将注意力网络运用到交互历史中。
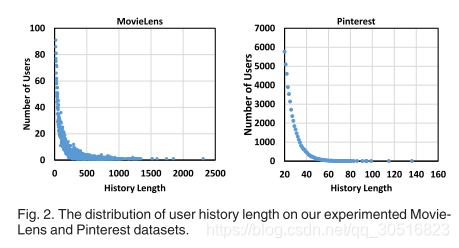
但是,非常不幸的是,标准的解决方案性能不太行。他比FISM的性能还差,即使他是在FISM的基础上开发的。研究完注意力权值,我们发现这个问题来自softmax,原因是,传统的,注意力使用场景中,如CV、NLP注意成分不大,如句子中的单词和图像中的区域。因此softmax可以适当的标准化注意力权值,从而提供一个很好的概率解释。但是对于用户历史数据,因为用户的历史长度可以有很大变化,从定性来说,softmax对注意力权值进行L1归一化,可能会对历史较长的活跃用户的权值造成过大惩罚。
为了证明这一点,在图2中,我们展示了在实验中的MovieLens和Pinnterest数据集上的用户历史长度的分布。我们可以看到,对于两个真实数据集,用户的历史长度变化很大,具体而言,用户历史长度的均值和方差分别为(166,37145)(27,572)。所有用户的平均长度为166,最大长度为2313。也就是说,最活跃用户的平均注意力权重是1/2313,比平均用户(即,1/166)少大约14倍。如此大的注意权重差异将导致优化模型的item嵌入是个问题。
NaIS模型。现在,我们提出了我们的最终设计的NAIS模型。如上所述,Design 3的弱性能来自于softmax,它对注意力权重进行L1归一化,导致不同用户的注意力权重存在较大差异。为了解决这个问题,我们提出了平滑softmax的分母,以减少对活动用户注意权重的惩罚,同时减少注意权重的方差。形式上,NAIS的预测模型如下:
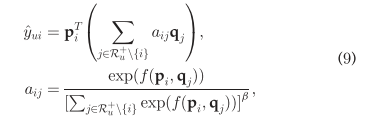
B是平滑指数,范围[0,1],B=1就是softmax。B<1,值就被压缩,活跃用户的注意力权值会收到惩罚。B<1的话,就不是概率分布了,但是它的性能比softmax好。我们使用NAIS-concat和NAIS-prod表示刚才的那两个注意力函数。
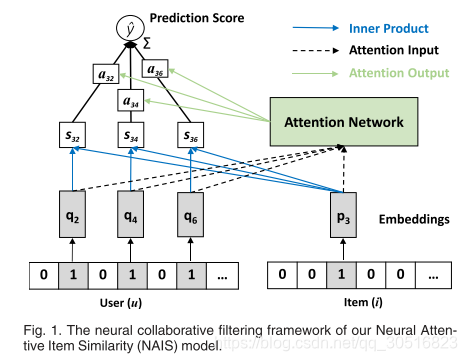
此外,我们的NAIS模型可以在最近提出的神经协同过滤(NCF)框架[5]下观察,如图1所示。不同于使用单热点用户ID作为输入特征的基于用户的NCF模型,我们的NAIS模型使用多热点交互项作为用户的输入特征。与作为隐藏层的精心设计的注意力网络一起,我们的NAIS模型可以更直观地理解为执行基于item的CF
3.2优化
为了学习推荐模型,我们需要指定一个目标函数来进行优化。当我们处理每个item是二进制值1或0的隐式反馈时,我们可以将推荐模型的学习视为二进制分类任务。类似于之前关于Neural CF[5]的工作,我们将观察到的用户与项目交互视为正实例,从剩余的未观察到的交互中取样负实例。设R+和R-分别表示正实例和负实例的集合,我们最小化如下定义的正则化日志丢失:

其中N是全体训练实例,a是sigmoid函数,其作用是将
转化成概率值以表示用户u将要交互的item i的可能性。超参数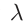 控制L2的正则化以防过拟合。我们认为,其他的损失函数,比如逐点回归和成对排序可以很好的运用于NAIS的隐式反馈。由于工作的重点是展示NAIS的有效性,特别是改进FISM以证明注意力的使用,因此我们将对其他目标函数的探索留作将来的工作。
控制L2的正则化以防过拟合。我们认为,其他的损失函数,比如逐点回归和成对排序可以很好的运用于NAIS的隐式反馈。由于工作的重点是展示NAIS的有效性,特别是改进FISM以证明注意力的使用,因此我们将对其他目标函数的探索留作将来的工作。
为了优化目标函数,我们使用自适应梯度下降,对每个参数应用自适应学习率。它从所有训练实例中抽取一个随机样本,向着梯度的负方向更新相关参数。我们使用Adagrad的小批量来加速训练过程,并且在实验设置的第4.1节中详细介绍了小批量的生成。在每个训练阶段,我们首先生成所有负实例,然后将它们与正实例一起馈送到参数更新的训练算法中。这比在GPU平台上进行训练时对负实例进行动态采样(如贝叶斯个性化排序[11]中所做的那样)要快得多,因为它避免GPU(用于参数更新)和CPU(用于负采样)之间的不必要的切换。具体来说,对于每个正实例(u,i),我们随机采样X个用户u从未交互过的item,在我们的实验中,X=4,这是个经验值。
预训练:由于神经网络模型的非线性和目标函数(w.r.t.所有参数)的非凸性,使用SGD的优化很容易陷入性能差的局部极小。因此,模型参数的初始化对模型的最终性能起着至关重要的作用。从经验上讲,当我们尝试从随机初始化训练NAIS时,我们发现它收敛缓慢,最终性能略好于FISM。我们假设这是因为同时优化注意网络和项目嵌入的困难。由于注意力网络的输出对item嵌入进行重复标度,联合训练可能产生协同适应效应,从而减慢了收敛速度。我们假设这是由于注意网络和item嵌入难以同时优化。由于注意力网络的输出对item嵌入进行重新缩放,**因此联合训练它们可能导致共适应效应,减缓收敛速度。**例如,训练一次,可能降低注意力权值aij,但是会增加嵌入内积pi^Tqj,这就导致更新预测分数,只能取得很小的进展。
为了解决NAIS训练中的实际问题,我们使用FISM对NAIS进行预训练,使用FISM学习的item嵌入来初始化NAIS。由于FISM没有共同适配问题,因此它可以在编码item相似性时很好地学习item嵌入。因此,使用FISM嵌入来初始化NAIS可以极大地促进注意网络的学习,导致更快的收敛和更好的性能。通过这样有意义的item嵌入的初始化,我们可以简单地用随机高斯分布初始化注意网络。
3.3discussions
在本部分中,我们讨论了NAIS的三个特性,即它的时间复杂性、易于支持在线个性化以及注意函数的两个选择。时间复杂度分析。我们分析了NAIS预测模型的时间复杂度,即方程(9)。这直接反映了NAIS在测试(或推荐)中的时间成本,并且训练的时间成本应该与测试的时间成本成比例。时间复杂度用的是FISM预测yui。0(k|R+u|),K是嵌入尺寸。Ru+历史交互的数量。对比于FISM,NAIS额外的时间来自于注意力网络。a表示注意力因子,f(pi,qj)的时间复杂度为o(ak)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









