







2021/5/20 10:31 第一次编辑;
1. 相关基础
量化基础知识
在量化中,一个比较重要的概念是量化函数 q ( ⋅ ) q(\cdot) q(⋅),即如何从一个浮点数值映射到具有特定宽度的量化值,即: q ( ⋅ ) : R → Q b u,sym q(\cdot): \mathcal{R} \rightarrow \mathcal{Q}_{b}^{\text {u,sym }} q(⋅):R→Qbu,sym . 一般比较常用的量化函数是四舍五入函数,当前很多量化算法使用的是这个函数,比如PACT等。
一般量化问题可以表示为下述的优化目标函数:
min
∥
w
^
−
w
∥
F
2
.
\min \|\hat{\mathbf{w}}-\mathbf{w}\|_{F}^{2} .
min∥w^−w∥F2. s.t.
w
^
∈
Q
b
u
,
sym
\hat{\mathbf{w}} \in \mathcal{Q}_{b}^{\mathrm{u}, \text { sym }}
w^∈Qbu, sym
w ^ \hat{\mathbf{w}} w^ 表示量化后的权重, w \mathbf{w} w表示原始的浮点值的权重。
Q b u , sym \mathcal{Q}_{b}^{\mathrm{u}, \text { sym }} Qbu, sym 表示的是对称均匀量化时的量化值,一般为
Q b u , s y m = s × { − 2 b − 1 , … , 0 , … , 2 b − 1 − 1 } \mathcal{Q}_{b}^{\mathrm{u}, \mathrm{sym}}=s \times\left\{-2^{b-1}, \ldots, 0, \ldots, 2^{b-1}-1\right\} Qbu,sym=s×{−2b−1,…,0,…,2b−1−1}。
s表示step size,b是量化的bit width。
上述的目标函数是对已经训练好的模型的参数直接进行量化,然后最小化量化参数与原始已经优化好的参数之间的量化误差,这种方式一般称为训练后量化。但是,有相关研究表明,最小化参数空间的量化误差并不能直接带来量化后网络的最佳的性能。 此时,有研究表明可以在量化感知训练(QAT)中采用梯度下降的方式学习step size参数 s,其直接采用网络的损失作为目标函数进行训练,如下:
min
E
[
L
(
w
^
)
]
,
s.t.
w
^
∈
Q
b
u
,
s
y
m
.
(
1
)
\min \mathbb{E}[L(\hat{\mathbf{w}})], \text { s.t. } \hat{\mathbf{w}} \in \mathcal{Q}_{b}^{\mathrm{u}, \mathrm{sym}} . (1)
minE[L(w^)], s.t. w^∈Qbu,sym.(1)
虽然这种方式能够得到更好的量化后模型性能,但是存在以下问题:
如果没有端到端的微调训练,如果没有足够的训练数据,如果没有足够的训练资源,
学习到足够优化的量化后权重并不容易。也就是这种量化方法更加依赖训练,更加耗费计算资源和训练时间。
泰勒展开
对权重的量化无非就是将一个给定的浮点值向上或者向下重新赋值为一个新的值,就以最简单的四舍五入为例,假设某个浮点数F,其量化后的值无非就是
⌊
F
⌋
\lfloor F \rfloor
⌊F⌋ 或者
⌊
F
⌋
+
1
\lfloor F \rfloor +1
⌊F⌋+1。有研究认为可以将这种量化看作是加在权重上的一种扰动。为了分析量化带来的模型损失(性能)带来的退化,可以应用泰勒展开对此进行分析,如下:
E
[
L
(
w
+
Δ
w
)
]
−
E
[
L
(
w
)
]
≈
Δ
w
⊤
g
‾
(
w
)
+
1
2
Δ
w
⊤
H
‾
(
w
)
Δ
w
.
(
2
)
\mathbb{E}[L(\mathbf{w}+\Delta \mathbf{w})]-\mathbb{E}[L(\mathbf{w})] \approx \Delta \mathbf{w}^{\top} \overline{\mathbf{g}}^{(\mathbf{w})}+\frac{1}{2} \Delta \mathbf{w}^{\top} \overline{\mathbf{H}}^{(\mathbf{w})} \Delta \mathbf{w} . (2)
E[L(w+Δw)]−E[L(w)]≈Δw⊤g(w)+21Δw⊤H(w)Δw.(2)
其中,
g
‾
(
w
)
=
E
[
∇
w
L
]
\overline{\mathbf{g}}^{(\mathbf{w})}=\mathbb{E}\left[\nabla_{\mathbf{w}} L\right]
g(w)=E[∇wL] ,
H
‾
(
w
)
=
E
[
∇
w
2
L
]
\overline{\mathbf{H}}^{(\mathbf{w})}=\mathbb{E}\left[\nabla_{\mathbf{w}}^{2} L\right]
H(w)=E[∇w2L] 分别表示损失函数关于权重的梯度和海森矩阵(由二阶导数构成的矩阵),
Δ
w
\Delta \mathbf{w}
Δw代表权重的扰动。
另外,我们是针对已经优化好的权重进行分析的,对优化好的权重其一阶导数可以认为是0,因为此时其应该是处于局部最优点的。所以上述公式中可以只考虑包含海森矩阵的第二项。
然后论文指出,因为网络中包含的参数量过于庞大,如果直接计算这种大规模参数的海森矩阵是十分占用内存的,为了解决这种问题,论文提出了两个假设,如下(还不是很懂):

2. 该论文的量化方法
2.1 层间依赖性
做一些符号描述: 假设网络共有n层,网络参数表示为
θ
\theta
θ,
θ
\theta
θ表示为一种向量的形式,即将每一层的权重参数展开成一维向量的形式,然后将n层的参数堆叠而形成最终的参数,
θ
=
vec
[
w
(
1
)
,
⊤
,
…
,
w
(
n
)
,
⊤
]
⊤
\theta=\operatorname{vec}\left[\mathbf{w}^{(1), \top}, \ldots, \mathbf{w}^{(n), \top}\right]^{\top}
θ=vec[w(1),⊤,…,w(n),⊤]⊤。假设
θ
\theta
θ的维度是d。网络的输出表示为
z
(
n
)
=
f
(
θ
)
\mathbf{z}^{(n)}=f(\theta)
z(n)=f(θ),假设
z
(
n
)
\mathbf{z}^{(n)}
z(n)的维度是m。 损失函数表示为
L
(
f
(
θ
)
)
L(f(\theta))
L(f(θ))。损失函数关于参数
θ
\theta
θ的海森矩阵可以通过下式进行计算:
∂
2
L
∂
θ
i
∂
θ
j
=
∂
∂
θ
j
(
∑
k
=
1
m
∂
L
∂
z
k
(
n
)
∂
z
k
(
n
)
∂
θ
i
)
=
∑
k
=
1
m
∂
L
∂
z
k
(
n
)
∂
2
z
k
(
n
)
∂
θ
i
∂
θ
j
+
∑
k
,
l
=
1
m
∂
z
k
(
n
)
∂
θ
i
∂
2
L
∂
z
k
(
n
)
∂
z
l
(
n
)
∂
z
l
(
n
)
∂
θ
j
(
3
)
\frac{\partial^{2} L}{\partial \theta_{i} \partial \theta_{j}}=\frac{\partial}{\partial \theta_{j}}\left(\sum_{k=1}^{m} \frac{\partial L}{\partial \mathbf{z}_{k}^{(n)}} \frac{\partial \mathbf{z}_{k}^{(n)}}{\partial \theta_{i}}\right)=\sum_{k=1}^{m} \frac{\partial L}{\partial \mathbf{z}_{k}^{(n)}} \frac{\partial^{2} \mathbf{z}_{k}^{(n)}}{\partial \theta_{i} \partial \theta_{j}}+\sum_{k, l=1}^{m} \frac{\partial \mathbf{z}_{k}^{(n)}}{\partial \theta_{i}} \frac{\partial^{2} L}{\partial \mathbf{z}_{k}^{(n)} \partial \mathbf{z}_{l}^{(n)}} \frac{\partial \mathbf{z}_{l}^{(n)}}{\partial \theta_{j}} (3)
∂θi∂θj∂2L=∂θj∂(k=1∑m∂zk(n)∂L∂θi∂zk(n))=k=1∑m∂zk(n)∂L∂θi∂θj∂2zk(n)+k,l=1∑m∂θi∂zk(n)∂zk(n)∂zl(n)∂2L∂θj∂zl(n)(3)
这里的公式推导主要就是基本的微积分中的求导公式。
同样的,对于一个已经训练好的收敛的模型来说,损失函数关于参数的一阶导数应该可以认为是0的,所以第一项可以忽略。
所以,只看第二项的话,损失函数
L
L
L关于参数
θ
\theta
θ的海森矩阵可以表示为:
H
(
θ
)
≈
G
(
θ
)
=
J
z
(
n
)
(
θ
)
⊤
H
(
z
(
n
)
)
J
z
(
n
)
(
θ
)
(
4
)
\mathbf{H}^{(\theta)} \approx \mathbf{G}^{(\theta)}=\mathbf{J}_{\mathbf{z}^{(n)}}(\theta)^{\top} \mathbf{H}^{\left(\mathbf{z}^{(n)}\right)} \mathbf{J}_{\mathbf{z}^{(n)}}(\theta) (4)
H(θ)≈G(θ)=Jz(n)(θ)⊤H(z(n))Jz(n)(θ)(4)
下面,针对二次型
Δ
θ
⊤
H
(
θ
)
Δ
θ
\Delta \theta^{\top} \mathbf{H}^{(\theta)} \Delta \theta
Δθ⊤H(θ)Δθ,它可以表达为下面的形式:
Δ
θ
⊤
H
(
θ
)
Δ
θ
=
∑
i
=
1
d
Δ
θ
i
2
(
∂
2
L
∂
θ
i
2
)
+
2
∑
i
<
j
d
Δ
θ
i
Δ
θ
j
∂
2
L
∂
θ
i
θ
j
=
∑
i
=
1
d
∑
j
=
1
d
(
Δ
θ
i
Δ
θ
j
∂
2
L
∂
θ
i
θ
j
)
(
5
)
\Delta \theta^{\top} \mathbf{H}^{(\theta)} \Delta \theta=\sum_{i=1}^{d} \Delta \theta_{i}^{2}\left(\frac{\partial^{2} L}{\partial \theta_{i}^{2}}\right)+2 \sum_{i<j}^{d} \Delta \theta_{i} \Delta \theta_{j} \frac{\partial^2 L}{\partial \theta_{i} \theta_{j}}=\sum_{i=1}^{d} \sum_{j=1}^{d}\left(\Delta \theta_{i} \Delta \theta_{j} \frac{\partial^2 L}{\partial \theta_{i} \theta_{j}}\right) (5)
Δθ⊤H(θ)Δθ=i=1∑dΔθi2(∂θi2∂2L)+2i<j∑dΔθiΔθj∂θiθj∂2L=i=1∑dj=1∑d(ΔθiΔθj∂θiθj∂2L)(5)
这一步其实就是将向量矩阵相乘的形式展开,即可得到上式的形式。
再利用公式(3)的推导,将公式(3)带入公式(5),上述式子可以继续推导为:
Δ
θ
⊤
H
(
θ
)
Δ
θ
=
∑
i
=
1
d
∑
j
=
1
d
Δ
θ
i
Δ
θ
j
(
∑
k
=
1
m
∑
l
=
1
m
∂
z
k
(
n
)
∂
θ
i
∂
2
L
∂
z
k
(
n
)
z
l
(
n
)
∂
z
l
(
n
)
∂
θ
j
)
=
∑
i
=
1
d
∑
j
=
1
d
∑
k
=
1
m
∑
l
=
1
m
(
Δ
θ
i
Δ
θ
j
∂
z
k
(
n
)
∂
θ
i
∂
2
L
∂
z
k
(
n
)
z
l
(
n
)
∂
z
l
(
n
)
∂
θ
j
)
=
∑
k
=
1
m
∑
l
=
1
m
(
∂
2
L
∂
z
k
(
n
)
z
l
(
n
)
)
(
∑
i
=
1
d
Δ
θ
i
∂
z
k
(
n
)
∂
θ
i
)
(
∑
j
=
1
d
Δ
θ
j
∂
z
l
(
n
)
∂
θ
j
)
=
(
J
[
z
(
n
)
θ
]
Δ
θ
)
⊤
H
(
z
(
n
)
)
(
J
[
z
(
n
)
θ
]
Δ
θ
)
(
6
)
\begin{aligned} \Delta \theta^{\top} \mathbf{H}^{(\theta)} \Delta \theta &=\sum_{i=1}^{d} \sum_{j=1}^{d} \Delta \theta_{i} \Delta \theta_{j}\left(\sum_{k=1}^{m} \sum_{l=1}^{m} \frac{\partial \mathbf{z}_{k}^{(n)}}{\partial \theta_{i}} \frac{\partial^{2} L}{\partial \mathbf{z}_{k}^{(n)} \mathbf{z}_{l}^{(n)}} \frac{\partial \mathbf{z}_{l}^{(n)}}{\partial \theta_{j}}\right) \\ &=\sum_{i=1}^{d} \sum_{j=1}^{d} \sum_{k=1}^{m} \sum_{l=1}^{m}\left(\Delta \theta_{i} \Delta \theta_{j} \frac{\partial \mathbf{z}_{k}^{(n)}}{\partial \theta_{i}} \frac{\partial^{2} L}{\partial \mathbf{z}_{k}^{(n)} \mathbf{z}_{l}^{(n)}} \frac{\partial \mathbf{z}_{l}^{(n)}}{\partial \theta_{j}}\right) \\ &=\sum_{k=1}^{m} \sum_{l=1}^{m}\left(\frac{\partial^{2} L}{\partial \mathbf{z}_{k}^{(n)} \mathbf{z}_{l}^{(n)}}\right)\left(\sum_{i=1}^{d} \Delta \theta_{i} \frac{\partial \mathbf{z}_{k}^{(n)}}{\partial \theta_{i}}\right)\left(\sum_{j=1}^{d} \Delta \theta_{j} \frac{\partial \mathbf{z}_{l}^{(n)}}{\partial \theta_{j}}\right) \\ &=\left(\mathbf{J}\left[\frac{\mathbf{z}^{(n)}}{\theta}\right] \Delta \theta \right )^{\top} \mathbf{H}^{\left(\mathbf{z}^{(n)}\right)}\left(\mathbf{J}\left[\frac{\mathbf{z}^{(n)}}{\theta}\right] \Delta \theta \right) \end{aligned} (6)
Δθ⊤H(θ)Δθ=i=1∑dj=1∑dΔθiΔθj(k=1∑ml=1∑m∂θi∂zk(n)∂zk(n)zl(n)∂2L∂θj∂zl(n))=i=1∑dj=1∑dk=1∑ml=1∑m(ΔθiΔθj∂θi∂zk(n)∂zk(n)zl(n)∂2L∂θj∂zl(n))=k=1∑ml=1∑m(∂zk(n)zl(n)∂2L)(i=1∑dΔθi∂θi∂zk(n))(j=1∑dΔθj∂θj∂zl(n))=(J[θz(n)]Δθ)⊤H(z(n))(J[θz(n)]Δθ)(6)
其中,
J
[
x
y
]
\mathbf{J}\left[\frac{x}{y}\right]
J[yx] 表示x关于y的雅各比矩阵。
上述公式的最后一步就是将展开式以矩阵的形式表示。
还没完,还可以继续推导:
对网络输出
z
(
n
)
\mathbf{z}^{(n)}
z(n)也进行一次泰勒展开的话,那么可以得到下式:
Δ
z
(
n
)
=
z
^
(
n
)
−
z
(
n
)
≈
J
z
(
n
)
(
θ
)
Δ
θ
(
7
)
\Delta \mathbf{z}^{(n)}=\hat{\mathbf{z}}^{(n)}-\mathbf{z}^{(n)} \approx \mathbf{J}_{\mathbf{z}^{(n)}}(\theta) \Delta \theta (7)
Δz(n)=z^(n)−z(n)≈Jz(n)(θ)Δθ(7)
这里其实就是只保留了一阶项。
所以,最终就可以得到:
Δ
θ
⊤
H
(
θ
)
Δ
θ
=
Δ
z
(
n
)
,
⊤
H
(
z
(
n
)
)
Δ
z
(
n
)
(
8
)
\begin{aligned} \Delta \theta^{\top} \mathbf{H}^{(\theta)} \Delta \theta &=\Delta \mathbf{z}^{(n), \top} \mathbf{H}^{\left(\mathbf{z}^{(n)}\right)} \Delta \mathbf{z}^{(n)} \end{aligned} (8)
Δθ⊤H(θ)Δθ=Δz(n),⊤H(z(n))Δz(n)(8)
以上是该篇论文的核心推导,也是该论文所述的原理3.1. 即将原始的关于参数
θ
\theta
θ的优化问题转化为关于网络输出
z
(
n
)
\mathbf{z}^{(n)}
z(n)的优化问题,如下:
arg
min
θ
^
Δ
θ
⊤
H
‾
(
θ
)
Δ
θ
≈
arg
min
θ
^
E
[
Δ
z
(
n
)
,
⊤
H
(
z
(
n
)
)
Δ
z
(
n
)
]
(
9
)
\underset{\hat{\theta}}{\arg \min } \Delta \theta^{\top} \overline{\mathbf{H}}^{(\theta)} \Delta \theta \approx \underset{\hat{\theta}}{\arg \min } \mathbb{E}\left[\Delta \mathbf{z}^{(n), \top} \mathbf{H}^{\left(\mathbf{z}^{(n)}\right)} \Delta \mathbf{z}^{(n)}\right] (9)
θ^argminΔθ⊤H(θ)Δθ≈θ^argminE[Δz(n),⊤H(z(n))Δz(n)](9)
下面再来梳理一下:
对于量化问题的优化目标目前存在两种,一种是直接在参数空间进行优化,即最小化量化后参数与原始训练好的浮点参数之间误差。但是有研究表明,最小化参数空间的误差并不能带来最终量化模型的最佳的性能。所以最好使用另一个优化目标,即直接优化量化后模型的损失函数,如公式(1)所示。但是这种优化方法目前主要应用在量化感知训练的情况下,而这种情况下,必须需要足够的训练数据,足够的计算资源和足够的训练时间才能得到较好的量化结果。所以呢,这篇论文就基于泰勒展开,将公式(1)中的目标函数进行展开之后得到公式(2),又因为训练之后网络已经收敛,所以第一项可以省略,只保留第二项。但是呢,因为网络中的参数量非常多,所以参数向量的维度很大,如果直接计算参数向量的海森矩阵是一件非常耗费内存,也是一件几乎不可能的事情。所以,本文核心的推导就来了,也就是公式(6)(7)(8),将损失函数对参数向量
θ
\theta
θ的海森矩阵转换为损失函数对网络输出
z
(
n
)
\mathbf{z}^{(n)}
z(n) 的海森矩阵,从而就可以大大降低计算海森矩阵的复杂度。
2.2 块重建
根据上一小节所述,如果直接利用整个网络的最终输出
z
(
n
)
\mathbf{z}^{(n)}
z(n) 来近似二阶误差实现量化重建的话,其效果是差于逐层重建的方法,主要因为重建使用的校准数据太少,只有1024,很容易导致过拟合。而为了量化重建的高效性,不能增加太多的训练数据 。如何在使用较少校准数据的前提下,提高重建的网络性能呢?
在逐层重建(基于网络每一层的输出进行重建)和基于整个网络的最终输出重建之间还存在若干重建粒度。这也就是本节提出的块重建,即将若干层组成一个块,基于块的输出进行重建。其原理跟上一节提到的基于网络最终输出
z
(
n
)
\mathbf{z}^{(n)}
z(n)重建的原理是一样的,即如果层k到等l组成一个块,该块的权重向量表示为
θ
~
=
vec
[
w
(
k
)
,
⊤
,
…
,
w
(
ℓ
)
,
⊤
]
⊤
\tilde{\theta}=\operatorname{vec}\left[\mathbf{w}^{(k), \top}, \ldots, \mathbf{w}^{(\ell), \top}\right]^{\top}
θ~=vec[w(k),⊤,…,w(ℓ),⊤]⊤,对应的海森矩阵可以表示为
Δ
θ
~
⊤
H
‾
(
θ
~
)
Δ
θ
~
=
E
[
Δ
z
(
ℓ
)
,
⊤
H
(
z
(
ℓ
)
)
Δ
z
(
ℓ
)
]
\Delta \tilde{\theta}^{\top} \overline{\mathbf{H}}^{(\tilde{\theta})} \Delta \tilde{\theta}=\mathbb{E}\left[\Delta \mathbf{z}^{(\ell), \top} \mathbf{H}^{\left(\mathbf{z}^{(\ell)}\right)} \Delta \mathbf{z}^{(\ell)}\right]
Δθ~⊤H(θ~)Δθ~=E[Δz(ℓ),⊤H(z(ℓ))Δz(ℓ)]。
2.3 海森矩阵的近似
前面已经提到使用基于块的方式,这样既能考虑到块内层之间的依赖性,同时将每个块的二阶误差转化为对应的该块的输出 E [ Δ z ( ℓ ) , ⊤ H ( z ( ℓ ) ) Δ z ( ℓ ) ] \mathbb{E}\left[\Delta \mathbf{z}^{(\ell), \top} \mathbf{H}^{\left(\mathbf{z}^{(\ell)}\right)} \Delta \mathbf{z}^{(\ell)}\right] E[Δz(ℓ),⊤H(z(ℓ))Δz(ℓ)] 。但是,要想求解,该海森矩阵 H ( z ( ℓ ) ) \mathbf{H}^{\left(\mathbf{z}^{(\ell)}\right)} H(z(ℓ))必须要先求出来。目前常用的一种方式是直接假设 H ( z ( ℓ ) ) = c × I \mathbf{H}^{\left(\mathbf{z}^{(\ell)}\right)}=c \times \mathbf{I} H(z(ℓ))=c×I,这样的话,这个二次损失函数就变成 ∥ Δ z ( ℓ ) ∥ 2 \left\|\Delta \mathbf{z}^{(\ell)}\right\|^{2} ∥∥Δz(ℓ)∥∥2,但是论文指出这种方式会损失很多有用信息。
在该论文中,使用 diagonal Fisher Information Matrix (FIM) 来近似该海森矩阵。 对于一个概率模型
p
(
x
∣
θ
)
p(x \mid \theta)
p(x∣θ), FIM 定义为:
F
‾
(
θ
)
=
E
[
∇
θ
log
p
θ
(
y
∣
x
)
∇
θ
log
p
θ
(
y
∣
x
)
T
]
=
−
E
[
∇
θ
2
log
p
θ
(
y
∣
x
)
]
=
−
H
‾
log
p
(
x
∣
θ
)
(
θ
)
\overline{\mathbf{F}}^{(\theta)}=\mathbb{E}\left[\nabla_{\theta} \log p_{\theta}(y \mid x) \nabla_{\theta} \log p_{\theta}(y \mid x)^{\mathrm{T}}\right]=-\mathbb{E}\left[\nabla_{\theta}^{2} \log p_{\theta}(y \mid x)\right]=-\overline{\mathbf{H}}_{\log p(x \mid \theta)}^{(\theta)}
F(θ)=E[∇θlogpθ(y∣x)∇θlogpθ(y∣x)T]=−E[∇θ2logpθ(y∣x)]=−Hlogp(x∣θ)(θ)
FIM 就是对数似然函数的期望海森矩阵的负值。
论文中说:当模型分布和真实数据分布匹配时,损失函数的海森矩阵就等于FIM。(不理解!!!)
激活值的FIM的对角值就等于每个元素的梯度的平方。(不理解!!!)
基于上述结论,优化目标函数可以转换为:
min
w
^
E
[
Δ
z
(
ℓ
)
,
⊤
H
(
z
(
ℓ
)
)
Δ
z
(
ℓ
)
]
=
min
w
^
E
[
Δ
z
(
ℓ
)
,
⊤
diag
(
(
∂
L
∂
z
1
(
ℓ
)
)
2
,
…
,
(
∂
L
∂
z
a
(
ℓ
)
)
2
)
Δ
z
(
ℓ
)
]
(
10
)
\min _{\hat{\mathbf{w}}} \mathbb{E}\left[\Delta \mathbf{z}^{(\ell), \top} \mathbf{H}^{\left(\mathbf{z}^{(\ell)}\right)} \Delta \mathbf{z}^{(\ell)}\right]=\min _{\hat{\mathbf{w}}} \mathbb{E}\left[\Delta \mathbf{z}^{(\ell), \top} \operatorname{diag}\left(\left(\frac{\partial L}{\partial \mathbf{z}_{1}^{(\ell)}}\right)^{2}, \ldots,\left(\frac{\partial L}{\partial \mathbf{z}_{a}^{(\ell)}}\right)^{2}\right) \Delta \mathbf{z}^{(\ell)}\right] (10)
w^minE[Δz(ℓ),⊤H(z(ℓ))Δz(ℓ)]=w^minE⎣⎡Δz(ℓ),⊤diag⎝⎛(∂z1(ℓ)∂L)2,…,(∂za(ℓ)∂L)2⎠⎞Δz(ℓ)⎦⎤(10)
与MSE最小化相比,上述最小化包含了平方梯度信息。如果输出具有较高的绝对梯度,那么在重建时它将得到更多的关注。
在该论文中,分别对权重和激活值都进行量化,但是对权重的量化直接采用自适应的四舍五入,而对激活值的量化的step size(delta)进行学习。
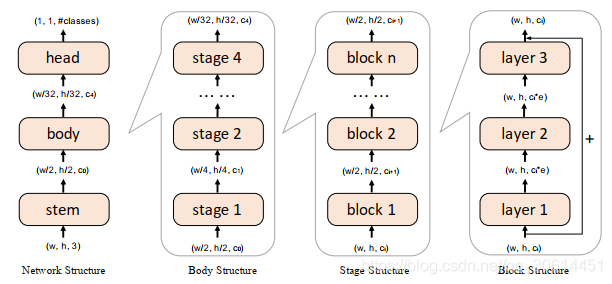
上图是该论文中提到的模型的不同的结构层次,network->body->stage->block
w
^
=
s
×
clip
(
⌊
w
s
⌋
+
σ
(
v
)
,
n
,
p
)
\hat{\mathbf{w}}=s \times \operatorname{clip}\left(\left\lfloor\frac{\mathbf{w}}{s}\right\rfloor+\sigma(\mathbf{v}), n, p\right)
w^=s×clip(⌊sw⌋+σ(v),n,p)
上式是量化函数,不同于传统的量化函数,其额外引入了一个
σ
(
v
)
\sigma(v)
σ(v)函数,其中
v
v
v是一个可学习的参数,
σ
(
⋅
)
\sigma(\cdot)
σ(⋅)是一个sigmoid-like的函数,使得
v
v
v移动在0-1之间,同时再损失函数中引入一个正则化项,使得
σ
(
v
)
\sigma(v)
σ(v)能够收敛到0或1.
那么,最终的优化目标函数可以表示为:
arg
min
v
E
[
Δ
z
(
ℓ
)
,
⊤
diag
(
(
∂
L
∂
z
1
(
ℓ
)
)
2
,
…
,
(
∂
L
∂
z
a
(
ℓ
)
)
2
)
Δ
z
(
ℓ
)
]
+
λ
∑
i
(
1
−
∣
2
σ
(
v
i
)
−
1
∣
β
)
\underset{\mathbf{v}}{\arg \min } \mathbb{E}\left[\Delta \mathbf{z}^{(\ell), \top} \operatorname{diag}\left(\left(\frac{\partial L}{\partial \mathbf{z}_{1}^{(\ell)}}\right)^{2}, \ldots,\left(\frac{\partial L}{\partial \mathbf{z}_{a}^{(\ell)}}\right)^{2}\right) \Delta \mathbf{z}^{(\ell)}\right]+\lambda \sum_{i}\left(1-\left|2 \sigma\left(\mathbf{v}_{i}\right)-1\right|^{\beta}\right)
vargminE⎣⎡Δz(ℓ),⊤diag⎝⎛(∂z1(ℓ)∂L)2,…,(∂za(ℓ)∂L)2⎠⎞Δz(ℓ)⎦⎤+λi∑(1−∣2σ(vi)−1∣β)
在校准训练过程中逐渐减小
β
\beta
β的值,从而使得
σ
(
v
)
\sigma(v)
σ(v)逐渐收敛到0或1.
激活值不能使用自适应四舍五入进行量化的原因,是因为它们随不同的输入数据而变化。

2.4 混合精度
2021/5/24 10:31 添加更新;
该论文同样研究了混合混合精度量化。
所谓混合精度是指针对不同的层使用不同的量化精度(不同的比特宽度)。
该优化问题可以表述为下述优化公式:
min c L ( w ^ , c ) , s.t. H ( c ) ≤ δ , c ∈ { 2 , 4 , 8 } n . ( 11 ) \min _{\boldsymbol{c}} L(\hat{\mathbf{w}}, \mathbf{c}), \text { s.t. } H(\mathbf{c}) \leq \delta, \mathbf{c} \in\{2,4,8\}^{n} . (11) cminL(w^,c), s.t. H(c)≤δ,c∈{2,4,8}n.(11)
c 是长度为层数的向量,其中每个元素代表每层的比特宽度。 H ( ⋅ ) H(\cdot) H(⋅) 是衡量对应比特宽度下的硬件性能,该约束条件的含义是其对应的硬件性能必须满足我们设置的一个阈值条件。 δ \delta δ 就是设置的阈值。
该论文指出一个问题,之前的那些工作在考虑量化损失函数的时候,都是逐层计算每一层的量化损失,然后将所有层的量化损失直接相加作为总的量化损失,也就是说认为每一层在量化的时候是相互独立的,从而将混合精度的求解问题作为一个整数编程问题来求解。
但是!!!
这篇论文指出在量化时,每一层之间不能是相互独立的,它们之间应该是相互影响的。所以呢,在衡量每一层的量化损失时,应该包括两部分的损失,分别称为:对角损失和非对角损失。对角损失就是独立的衡量每一层对应的敏感度(在这篇论文里,用敏感度这个指标来指代相应的量化损失,很明显,如果一层对应的敏感度越高,那么在量化为相同的比特宽度时所产生的量化损失越大。)这个敏感度跟之前的工作做的是相同的。而非对角损失指的是不同层之间的敏感度。
很明显,这种混合精度的问题可以看作是一个搜索问题,而且搜索空间很大。为了降低搜索空间,该论文指出对于比特宽度为4和8时,量化后的精度降低很低,因此只考虑2bit的排列组合情况,从而降低搜索空间。搜索算法使用的是遗传算法。
相应的算法伪代码如下:

总结: 目前还有一些地方没弄明白,后续还需要再研究一下补充,另外,再跑一下该论文的代码,看一下实验,后续再补充!
参考文献,感谢作者。
@article{li2021brecq, title={Brecq: Pushing the limit of
post-training quantization by block reconstruction}, author={Li,
Yuhang and Gong, Ruihao and Tan, Xu and Yang, Yang and Hu, Peng and
Zhang, Qi and Yu, Fengwei and Wang, Wei and Gu, Shi}, journal={arXiv
preprint arXiv:2102.05426}, year={2021} }















 32
32











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









