









目录
什么是 GLM-4-9B
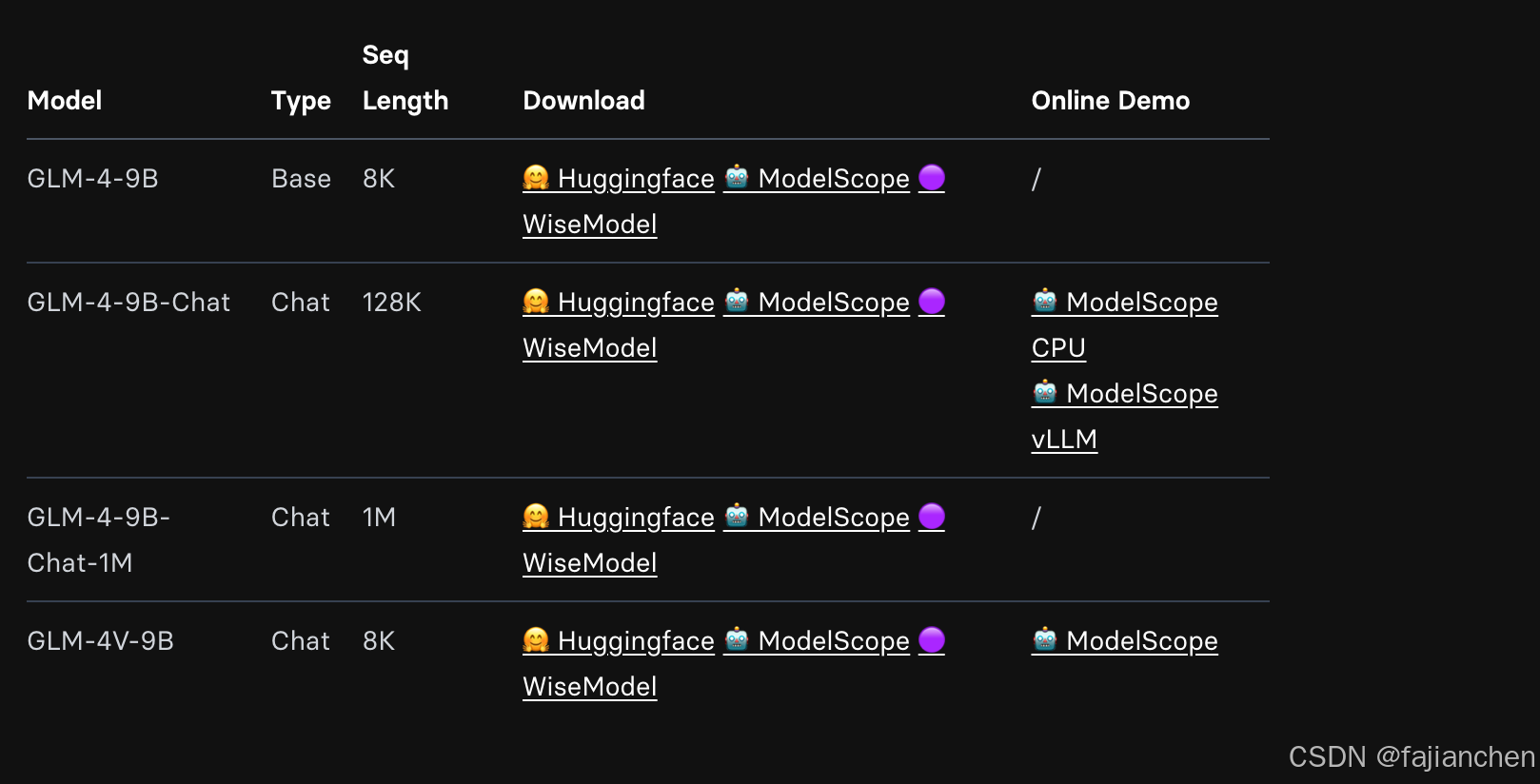
GLM-4-9B是由Zhipu AI推出的GLM-4系列中最新训练模型的开源版。在对语义,数学,推理,代码和知识的数据集的评估中,GLM-4-9B及其人类偏好一致的版本GLM-4-9B-CHAT在Llama-3-8B上表现出了出色的性能。除多轮对话外,GLM-4-9B-CHAT还具有高级功能,例如Web浏览,代码执行,自定义工具调用(功能调用)和长文本推理(最多支持128K上下文)。这一代模型增加了多语言支持,支持了包括日语,韩语和德语在内的26种语言。我们还启动了基于GLM-4-9B的1M上下文长度(约200万个汉字)和多模型GLM-4V-9B的GLM-4-9B-CHAT-1M模型。
GLM-4V-9B具有中文和英语的对话能力,高分辨率为1120*1120。在各种多模式评估中,包括中文和英语的全面能力,感知和推理,文本识别和图表理解,GLM-4V-9B与GPT-4-Turbo-2024-04-09,Gemini 1.0 Pro相比,表现出卓越的性能QWEN-VL-MAX和Claude 3 Opus
快速入门
使用以下方法快速调用GLM-4-9B-Chat语言模型
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat", trust_remote_code=True)
query = "你好"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))使用VLLM后端进行推理:
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat
# If you encounter OOM, you can try to reduce max_model_len or increase tp_size
max_model_len, tp_size = 131072, 1
model_name = "THUDM/glm-4-9b-chat"
prompt = [{"role": "user", "content": "你好"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# if you encounter OOM in GLM-4-9B-Chat-1M, you can try to enable the following parameters
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)使用以下方法快速调用GLM-4V-9B多模态模型
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4v-9b", trust_remote_code=True)
query = 'display this image'
image = Image.open("your image").convert('RGB')
inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": query}],
add_generation_prompt=True, tokenize=True, return_tensors="pt",
return_dict=True) # chat mode
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4v-9b",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0]))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











