







任务:PyTorch理解更多神经网络优化方法,了解不同优化器,书写优化器代码Momentum,二维优化,随机梯度下降法进行优化实现Ada自适应梯度调节法,RMSProp,Adam ,PyTorch种优化器选择
作业:参考https://blog.csdn.net/u010089444/article/details/76725843
SGD方法的一个缺点是其更新方向完全依赖于当前batch计算出的梯度,因而十分不稳定。
Momentum算法借用了物理中的动量概念,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力,Momentum算法会观察历史梯度vt−1vt−1 v_{t-1}vt−1,若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度,若当前梯度与历史梯方向不一致,则梯度会衰减。**一种形象的解释是:**我们把一个球推下山,球在下坡时积聚动量,在途中变得越来越快,γ可视为空气阻力,若球的方向发生变化,则动量会衰减。
RMSprop是Geoff Hinton提出的一种自适应学习率方法。Adagrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应的平均值,因此可缓解Adagrad算法学习率下降较快的问题。
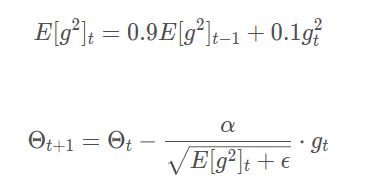
Adam(Adaptive Moment Estimation)是另一种自适应学习率的方法。它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
其中,mtmt m_tmt,vtvt v_tvt分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望E[gt]E[gt] E[g_t]E[gt],E[g2t]E[gt2] E[g_t2]E[gt2]的近似;mtˆmt \hat{m_t}mt,vtˆvt \hat{v_t}vt^是对mtmt m_tmt,vtvt v_tvt的校正,这样可以近似为对期望的无偏估计。 Adam算法的提出者建议β1β1 \beta_1β1 的默认值为0.9,β2β2 \beta_2β2的默认值为.999,$\epsilon $默认为10−810−8 10^{-8}10−8。 另外,在数据比较稀疏的时候,adaptive的方法能得到更好的效果,例如Adagrad,RMSprop, Adam 等。Adam 方法也会比 RMSprop方法收敛的结果要好一些, 所以在实际应用中 ,Adam为最常用的方法,可以比较快地得到一个预估结果。
作者:Joe-Han
来源:CSDN
原文:https://blog.csdn.net/u010089444/article/details/76725843
版权声明:本文为博主原创文章,转载请附上博文链接!















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









