






numpy手写NLP模型(三)———— FastText
1. 模型介绍
首先我附上一个我觉得介绍FastText介绍的很好的博客,非常详细,我也是看了这个博客才懂怎么实现这个模型的最后一部分的。链接在此
然后再说说我对这个模型个人的理解吧。这个模型的功能是给你一段文本,然后给这段文本进行分类,其实和之前的两篇博客NNLM,Skip-gram一样,模型前向传播计算出的结果都是一个分类结果,NNLM的输入是一段固定长度的单词序列,Skip-gram的输入是一个单词,而本文要实现的FastText的输入则是一段文本。将一段文本作为输入,然后模型预测这段文本所属的标签,即文本分类,可应用于垃圾邮件处理等等。
2. 模型
2.1 模型的输入
首先看看这个模型的结构图:
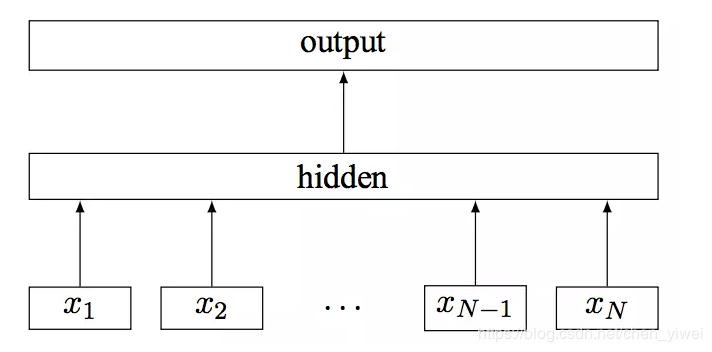
模型的原始输入是一段文本,假如是三个单词。那么首先我们会得到三个单词的embedding向量表示,然后我们把这三个向量相加,再取平均,得到一个最终的向量表示这个句子。比如(1, 2, 3, 4), (9, 6, 11, 8), (5, 10, 7, 12),那么这三个向量取一下平均的结果就是 (5, 6, 7, 8)。
2.2 模型的层次softmax
这个模型对于初学者来说容易搞不清的点在于这个层次softmax——hierarchical softmax,其他博客基本上是简单粗略地说是用一颗哈夫曼树去减少像普通softmax那样的计算,加快模型的训练速度。但是基本很少提这一步具体是怎么实现的,不理解这个哈夫曼树是怎么实现的话,很难把这个模型理解透彻。下面我就来讲讲我是怎么理解这个层次softmax的实现的吧。
首先介绍一下建立哈夫曼树的原料,原材料是标签和对应标签出现的概率(例子中把概率乘以了100),比如:
[(5, 'c1'), (25, 'c2'), (3, 'c3'), (6, 'c4'), (10, 'c5'), (11, 'c6'), (36, 'c7'), (4, 'c8')]
然后我们再看这颗哈夫曼树(建树过程省略,可以自行百度),这颗哈夫曼树有很多节点,每个非叶节点中存着这个节点的权重矩阵(可以把这颗哈夫曼树的非叶节点类比普通神经网络的隐藏层的神经元),只不过和普通神经网络的权重矩阵不太一样罢了。每个叶节点中存储着标签的名称(即例子列表中元组里的string,其实这个信息不放在叶节点里好像也可以),还有标签出现的概率。我们约定向右编码为1,向左编码为0。
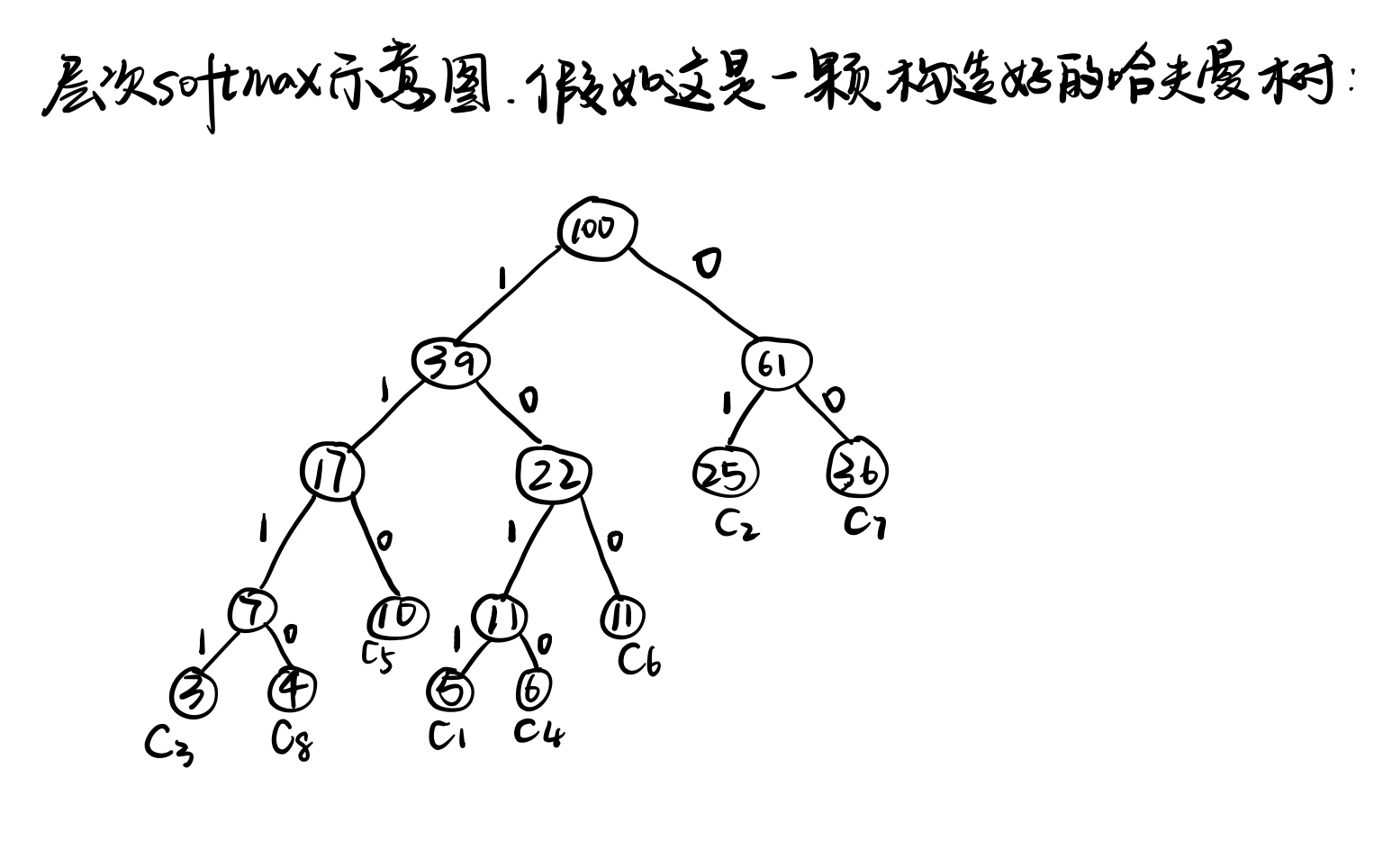
下面我们来了解一下这颗哈夫曼树的计算具体是怎么进行的。首先假如我们已经得到了文本的向量表示X。

继续:

这就是一次完整的基于层次softmax的前向传播计算了。结合大佬的博客理解效果更佳!理解不一定完全准确,如有谬误,还请指出。
2.3 模型的反向传播
模型的反向传播部分的话我就不多加阐述了,我参考的原博客讲得很好很好
3. 模型的代码实现
embed_size:每个单词embedding的维数
voca_size:词汇表单词的个数
lr:网络的学习率
首先我们来看Huffman树的建树部分:
# makeHuffman.py
class Huffman:
def __init__(self, weight, data, embed_size):
self.weight = weight
self.data = data
self.W = np.random.random((embed_size, 1))
self.left_child = None
self.right_child = None
def __lt__(self, other):
return self.weight < other.weight
这个Huffman类用来存储哈夫曼树的节点数据,包含节点的参数,节点权重,标签数据,左右孩子等。在叶节点,节点参数没有用,因为叶节点不参与运算,节点权重就是这个标签出现的频率;在非叶节点,标签数据没用,因为非叶节点不需要标签。
然后看一下造树的函数:
def make_huffman(data, embed_size):
'''
:param data: data是一个列表,里面存着单个元组,即(标签,标签出现的概率)
:return: 返回一个Huffman数的根节点,即一个Huffman类
'''
data_queue = PriorityQueue()
for node in data:
temp = Huffman(node[0], node[1], embed_size)
data_queue.insert(temp)
while len(data_queue.queue) > 1:
min1, min2 = get_min2nodes(data_queue.queue)
# 先找出最小和次小的数据,然后形成新节点,再压入队列
sum_node = Huffman(min1.weight + min2.weight, '', embed_size)
sum_node.left_child = min1
sum_node.right_child = min2
data_queue.insert(sum_node)
return data_queue.queue[0]
逻辑并不复杂,但是写的不是很精简,可能有些地方写的比较冗杂
接着看模型的网络部分的实现,首先是初始化:
# model.py
def __init__(self, label_data, label2code, voca_size, embed_size):
# 得到的是层次softmax的Huffman树的根节点
self.embed_size = embed_size
# 生成-1到1的随机embedding
self.embedding = 2 * np.random.random((voca_size, embed_size)) - 1
# 根据标签数据造树
self.huffmanTree = make_huffman(label_data, embed_size)
# 这个就是参考博客里的Xw,参考博客在前面链接里(刘建平老师的博客)
self.x = np.random.normal((embed_size, 1))
# 根据标签映射哈夫曼编码
self.label2code = label2code
self.loss = 0
# 原始输入,比如[1, 2, 4]这样的
self.raw_input = []
然后就是前向传播部分:
def forward(self, raw_input):
# forward计算的结果是这个输入向量对应的标签,也就是一个string
self.raw_input = raw_input
# 输入是raw_input也就是one-hot编码的单词列表, 其实也就是用十进制数表示的单次[1, 2 ,3]这样
input = [self.embedding[i].T for i in raw_input]
input = np.array(input)
input = input[:, :, np.newaxis]
temp = np.zeros((self.embed_size, 1))
# 求和取平均
for single in input:
temp += single
temp /= len(input)
self.x = temp
now_node = self.huffmanTree
p_total = 1
while now_node.left_child or now_node.right_child:
# print(now_node.W)
p = np.dot(self.x.T, now_node.W)[0][0]
p = sigmoid(p)
if p > 0.5:
p_total *= p
now_node = now_node.right_child
else:
p_total *= (1 - p)
now_node = now_node.left_child
return now_node.data
然后就是计算loss的函数,这个loss不是很严谨,就是我拿来看模型训练效果的,不是最大似然的loss
# model.py
def cal_loss(self, target_label):
loss = 0
target_label_code = self.label2code[target_label]
length = len(target_label_code)
now_node = self.huffmanTree
while now_node.left_child or now_node.right_child:
p = np.dot(self.x.T, now_node.W)[0][0]
p = sigmoid(p)
if target_label_code[0] == '0':
loss += (1 - p)
target_label_code = target_label_code[1:]
now_node = now_node.right_child
else:
loss += p
target_label_code = target_label_code[1:]
now_node = now_node.left_child
return loss / length
接下来是反向传播的部分,这里其实就是对前面数学公式的实现罢了,看懂了刘建平老师的博客的公式的话这里应该还是很好懂的。
# model.py
def backward(self, target_label, lr):
e = np.zeros((self.embed_size, 1))
code = self.label2code[target_label]
now_node = self.huffmanTree
while now_node.left_child or now_node.right_child:
g = (1 - int(code[0]) - sigmoid(np.dot(self.x.T, now_node.weight)[0][0])) * lr
e += g * now_node.W
dLoss_W = g * self.x
now_node.W += lr * dLoss_W
if code[0] == '0':
now_node = now_node.right_child
code = code[1:]
else:
now_node = now_node.left_child
code = code[1:]
# print(e.squeeze().shape)
# update word embedding
for i in self.raw_input:
self.embedding[i] += e.T.squeeze()
模型部分的代码已经写好了,剩下要做的就是用一个例子去验证一下。这里只使用了前面提到的比较小的样本去测试:
# train.py
train_data = [
('i love you', 'positive'),
('he loves me', 'positive'),
('she likes basketball', 'positive'),
('i hate you', 'negtive'),
('sorry for that', 'negtive'),
('that is awful', 'negtive')
]
接下来就是网络的训练:
# train.py
model = FastText(label_data, label2code, len(word_list), embed_size)
for epoch in range(EPOCH):
loss = 0
data_size = len(input_batch)
for i in range(data_size):
model.forward(input_batch[i])
loss += model.cal_loss(target_batch[i])
model.backward(target_batch[i], lr)
if epoch % 500 == 0:
print('Epoch: ', '%04d' % (epoch), ', Loss: ', loss)
训练的速度很快,明显能感觉出比之前两篇博客中的模型训练要快几倍,然后再来看看效果,这是test数据
test_data = [
('he is awful', 'negative'),
('that is awful', 'negative'),
('i love that', 'positive'),
('she likes you', 'negative')
]
这是结果计算:
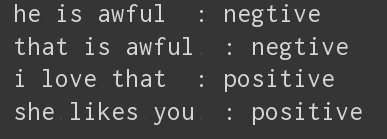
在小样本下的效果还是可以的~
最后附上本博客的github代码,论文链接,Facebook的FastText项目
4. 总结
①愚蠢的我居然一直在问为啥要更新xi,因为xi是单词的embedding表示啊,肯定要更新,训练word2vector模型不就是为了这个吗,愚蠢愚蠢。这个愚蠢的问题直接导致我最开始写的模型里没有更新词向量,导致最后结果loss总是收敛在一个奇奇怪怪的值,预测结果也不对,然后后来发现问题,把词向量也更新了之后就好了。















 551
551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









