






链接:https://arxiv.org/pdf/2503.04625
1. 论文概述
- 解决现有大规模推理模型(LRMs)在复杂推理任务中容易产生幻觉(hallucination)以及内部推理效率低下的问题。
- 提出一种工具集成的长链条思考(Long Chain-of-Thought, CoT)方法,通过引入外部工具(主要是 Python 解释器)来辅助模型进行复杂计算、自检、自我调试,从而提高推理能力和准确性。
2. 动机与背景
2.1 长链条思考 (Chain-of-Thought, CoT) 的优势与局限
- 优势:
- 利用多步中间推理步骤,将复杂问题分解,模仿人类思考方式,提升复杂任务的解决能力。
- 局限:
- LRMs 纯粹依赖内部推理时,容易出现计算错误或幻觉,尤其在需要精确计算和调试的场景下存在较大局限性。
2.2 工具集成推理 (Tool-Integrated Reasoning, TIR)
- 概念:
- 将外部工具(如代码解释器)引入到模型的推理过程中,让模型在遇到复杂计算或需要自我验证时,通过调用工具来获得反馈并进行修正。
- 背景:
- OpenAI 的 o1 系列模型曾报告具备调用外部工具(尤其是写代码并执行代码)的能力,但具体技术细节并未公开。
- 本文的出发点就是探索如何将长 CoT 与 TIR 有机结合。
3. 方法论
论文提出了一个两阶段的自我学习框架,通过两大关键技术实现模型的工具集成推理能力。
3.1 Hint-infer 方法
核心思想:
- 在模型进行长链条思考(CoT)的过程中,人工设计一系列提示(Hints),并在关键时刻(例如在出现“Wait”、“Alternatively”等连词后或在接近推理结束前)插入提示,直接激活模型调用外部 Python 工具的能力。
实现步骤:
- 提示设计:
- 针对数学问题、代码生成任务分别设计不同的提示。例如,数学问题中可插入“Wait, maybe using Python here is a good idea.”;而代码问题则设计包含代码模板的提示,促使模型在生成最终代码前进行测试和自我调试。
- 顺序推理与工具调用:
- 在推理过程中,当检测到提示插入点时,模型输出的内容会被截断,然后插入提示。随后,模型继续生成推理过程,同时生成的代码会通过 Python 解释器执行,返回的结果用于进一步指导后续推理。
数学相关公式:
- 论文中提到,对于两个互质数
a
a
a 和
b
b
b,最大不可表示数为
a b − a − b ab - a - b ab−a−b
虽然这里主要用于解释经典的硬币问题(Frobenius 问题),但体现了模型在计算问题时对公式化问题的处理思路。
3.2 Hint Rejection Sampling Fine-Tuning (Hint-RFT)
目的:
- 结合 Hint-infer 生成的推理轨迹,通过规则打分、过滤以及内容修改,对数据进行精选,然后对模型进行细调,从而使模型学会如何更好地利用外部工具。
过程描述:
- 数据筛选:
- 利用 Hint-infer 生成的长 CoT 推理轨迹,对所有样本进行打分和过滤,剔除重复或不合理的推理。
- 数据修改:
- 对于包含代码调用的推理,修改提示中 Python 标识符(如将“python”替换为“Debug Code Template”),并去除不必要的输出占位符。
- 模型细调:
- 基于处理后的数据集 D s e e d D_{seed} Dseed 对 QwQ-32B-Preview 进行进一步细调,得到初步模型 START-0。
- 随后再利用 START-0 生成自我蒸馏轨迹,构建数据集 D S T A R T D_{START} DSTART,最后再一次细调得到最终的 START 模型。
3.3 模型训练框架
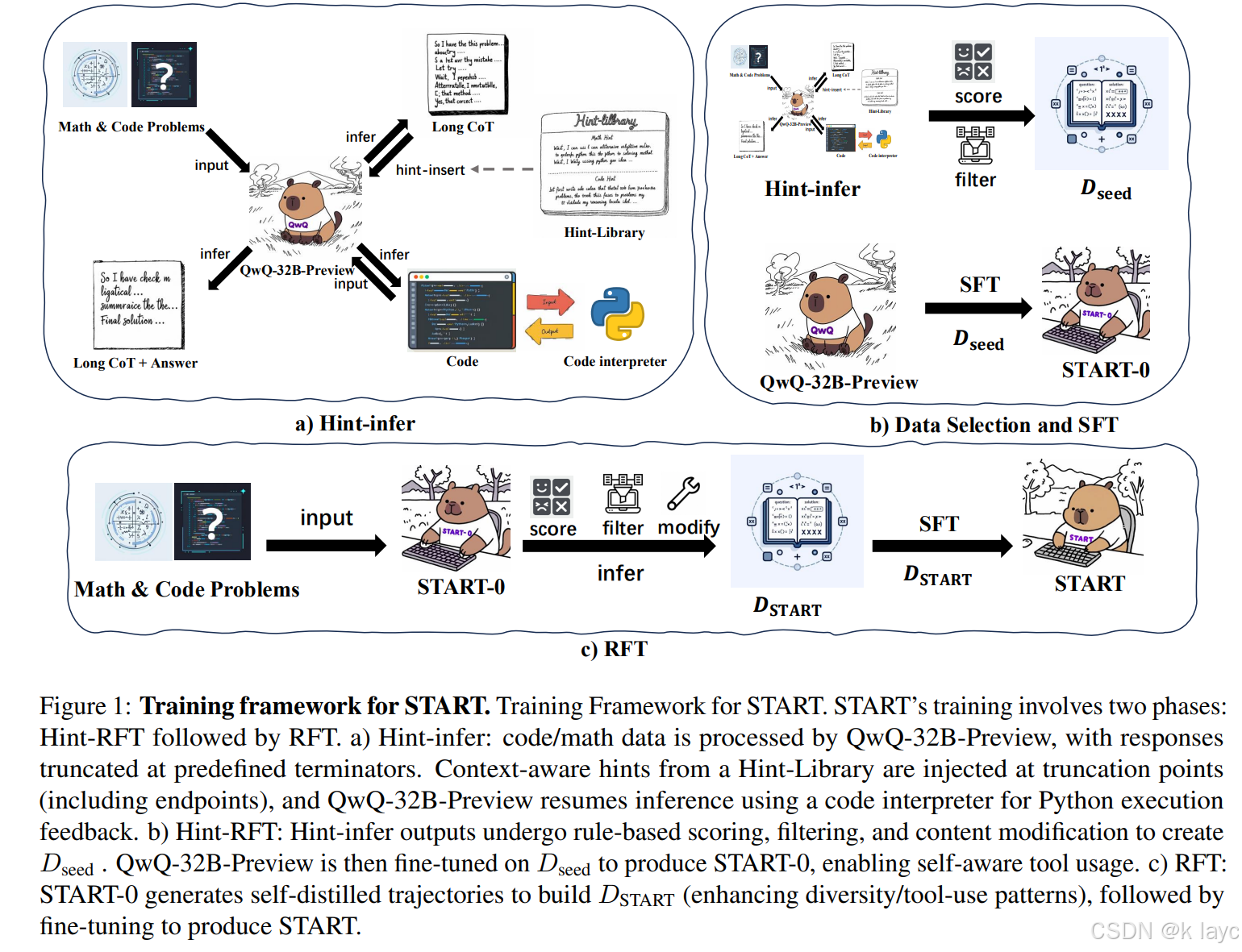
论文中提出的训练流程(如图 1 所示)主要包括三个阶段:
- Hint-infer 阶段:
- 在 QwQ-32B-Preview 的推理过程中插入提示,触发外部工具调用,生成初步的工具调用推理数据。
- Hint-RFT 阶段:
- 对 Hint-infer 输出的数据进行评分、过滤、修改,从而生成高质量的数据 D s e e d D_{seed} Dseed,并用其对模型进行细调,得到 START-0。
- RFT 阶段:
- 利用 START-0 进行自我蒸馏采样,得到更加多样化的推理轨迹数据 D S T A R T D_{START} DSTART,再对模型进行最终细调,生成完整的 START 模型。
训练过程中,模型采用全参数细调,使用 DeepSpeed ZeRO-3 进行优化,并在推理时采用贪婪解码,最大序列长度可达
32768
32768
32768 个 token,同时限制最多使用 6 次工具调用。


4. 实验与评估
论文在多个具有挑战性的推理任务上对 START 进行了验证,涵盖了数学、科学和代码问题。

4.1 数据集与评估基准
数学数据:
- 来源包括 AIME(2024年前的问题)、MATH 数据集(Hendrycks 等, 2021)、以及 Numina-MATH(LI 等, 2024),共约 40K 道数学问题。
代码数据:
- 数据来源包括 Codeforces、代码竞赛以及 LiveCodeBench(2024年7月前数据),共约 10K 道代码问题。
科学问答:
- GPQA 数据集包含 448 道博士级别的多选题,覆盖物理、化学和生物学领域。
4.2 实验结果
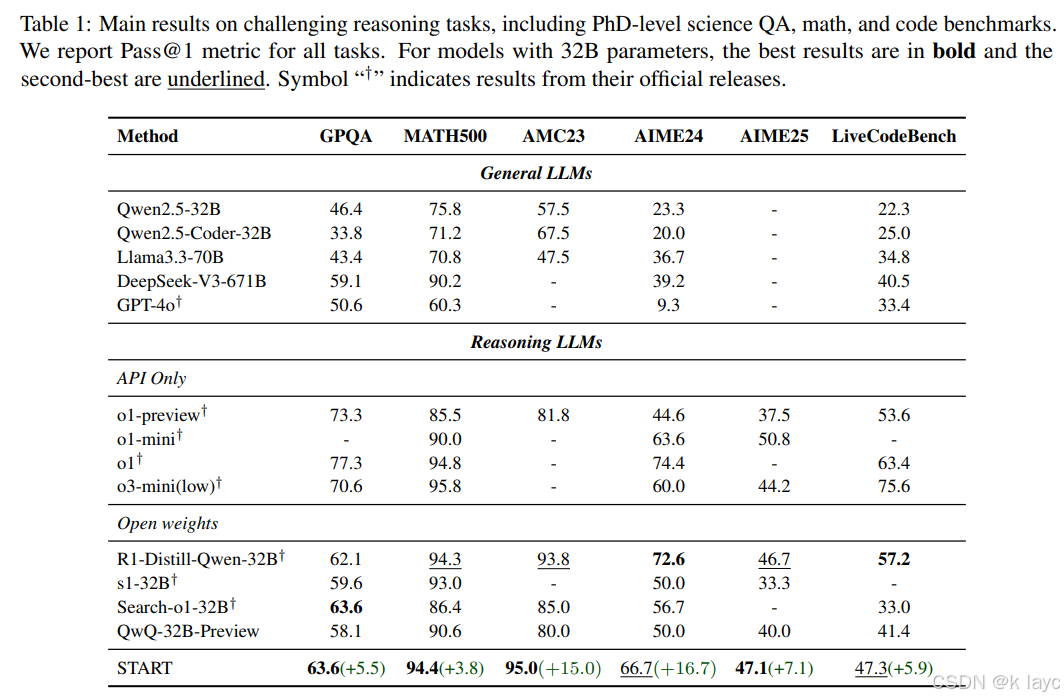
论文中通过表格展示了在多个基准数据集上的 Pass@1 指标对比结果,主要对比对象包括:
- General LLMs:例如 Qwen2.5-32B、Llama3.3-70B、DeepSeek-V3-671B、GPT-4o 等。
- 具备长 CoT 推理能力的模型:如 OpenAI 的 o1 系列、o3-mini,以及部分开源模型(如 QwQ-32B-Preview、Search-o1-32B 等)。
主要结果:
- 在 GPQA、MATH500、AMC23、AIME24、AIME25 以及 LiveCodeBench 上,START 相对于 QwQ-32B-Preview 分别有 5.5%、3.8%、15.0%、16.7%、7.1% 和 5.9% 的绝对提升。
- 特别在需要大量计算推理的物理题目上,START 的效果尤为明显;而在需要知识型推理的生物学题目中,其他依赖外部知识的模型(如 Search-o1-32B)表现略胜一筹。
4.3 分析与讨论
论文还从多个角度对方法进行了分析:
- 长 CoT 与长 TIR 对比:通过对比仅有长 CoT(QwQ-32B-Preview 与其经过 RFT 得到的 QwQ-RFT)的表现,发现单纯增加推理深度对结果提升有限,而工具调用能力是主要的性能提升因素。
- Hint-infer 的作用:在不打断模型原有推理流程的前提下,在停用符号前插入提示(Hint),可以有效延长模型思考时间并激活工具调用,从而逐步提高解题成功率。
- 细调的重要性:仅通过提示(Hint-infer)能够带来一定提升,但经过 Hint-RFT 细调后,模型的工具调用能力和整体推理性能有了显著改善。
5. 结论与局限性
5.1 主要贡献
- 提出 Hint-infer:一种简单而有效的顺序测试时扩展(sequential test-time scaling)方法,通过在推理过程中动态插入提示激活工具调用。
- 提出 Hint-RFT 框架:将 Hint-infer 与拒绝采样细调相结合,使模型能自我学习如何利用代码解释器进行复杂计算和自我调试。
- 构建 START 模型:这是首个将长链条思考与代码工具调用相结合的开源推理模型,在数学、科学和编程任务上均表现出色。
5.2 局限性与未来工作
- 工具种类限制:目前仅集成了 Python 解释器,未来可以扩展到搜索引擎、专用库等更多外部工具。
- 提示设计的人工性:提示的设计和插入位置是手工制定的,可能在不同任务中需要进行调整以避免打断原有思路。
- 数据集范围有限:实验主要在部分数学、编程和科学问答数据集上验证,未来需要在更广泛的数据集上检验模型的泛化能力。
- 潜在风险:模型具有自动生成和执行代码的能力,可能会被恶意利用,因此需要在使用中引入安全防护机制。
6. 关键技术细节与公式
- 提示触发与工具调用:在模型推理过程中,通过检测特定连词(如“Wait”、“Alternatively”)插入提示,使得模型能够生成调用 Python 代码的部分。
- 顺序测试时扩展效果:通过在推理末尾反复插入提示,模型的思考时间和工具调用次数同步增加,从而实现测试时的性能扩展。
- 数学公式示例:对于两个互质数
a
a
a 和
b
b
b,最大不可表达数为
a b − a − b ab - a - b ab−a−b
这一公式虽然仅适用于两数情况,但展示了模型在处理数学问题时对公式化问题的理解和应用能力。
7. 总结
论文《START: Self-taught Reasoner with Tools》通过将外部工具(Python 解释器)与长链条思考相结合,成功地解决了传统大规模推理模型在复杂计算任务中出现的幻觉和错误问题。其核心技术——Hint-infer 和 Hint-RFT——使得模型能够在推理过程中自我生成、调用并验证代码,显著提升了数学、编程及科学问答等领域的表现。虽然仍存在工具种类、提示设计和数据泛化等方面的局限性,但这项工作为未来大语言模型在更高层次认知任务中的应用提供了新的思路和方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









