










 该博客详细介绍了如何利用BiLSTM、卷积层(CNN)和注意力机制(Attention)构建深度学习模型对时序数据进行预测。首先,数据被划分为三维时序块,接着构建模型,包括卷积层、双向LSTM层和Attention层。模型训练后,通过早停和模型检查点回调进行调优和保存。此外,还提供了数据预处理、模型创建、归一化等步骤的代码实现。
该博客详细介绍了如何利用BiLSTM、卷积层(CNN)和注意力机制(Attention)构建深度学习模型对时序数据进行预测。首先,数据被划分为三维时序块,接着构建模型,包括卷积层、双向LSTM层和Attention层。模型训练后,通过早停和模型检查点回调进行调优和保存。此外,还提供了数据预处理、模型创建、归一化等步骤的代码实现。
1、摘要
本文主要讲解:bilstm-cnn-attention对时序数据进行预测
主要思路:
- 对时序数据进行分块,生成三维时序数据块
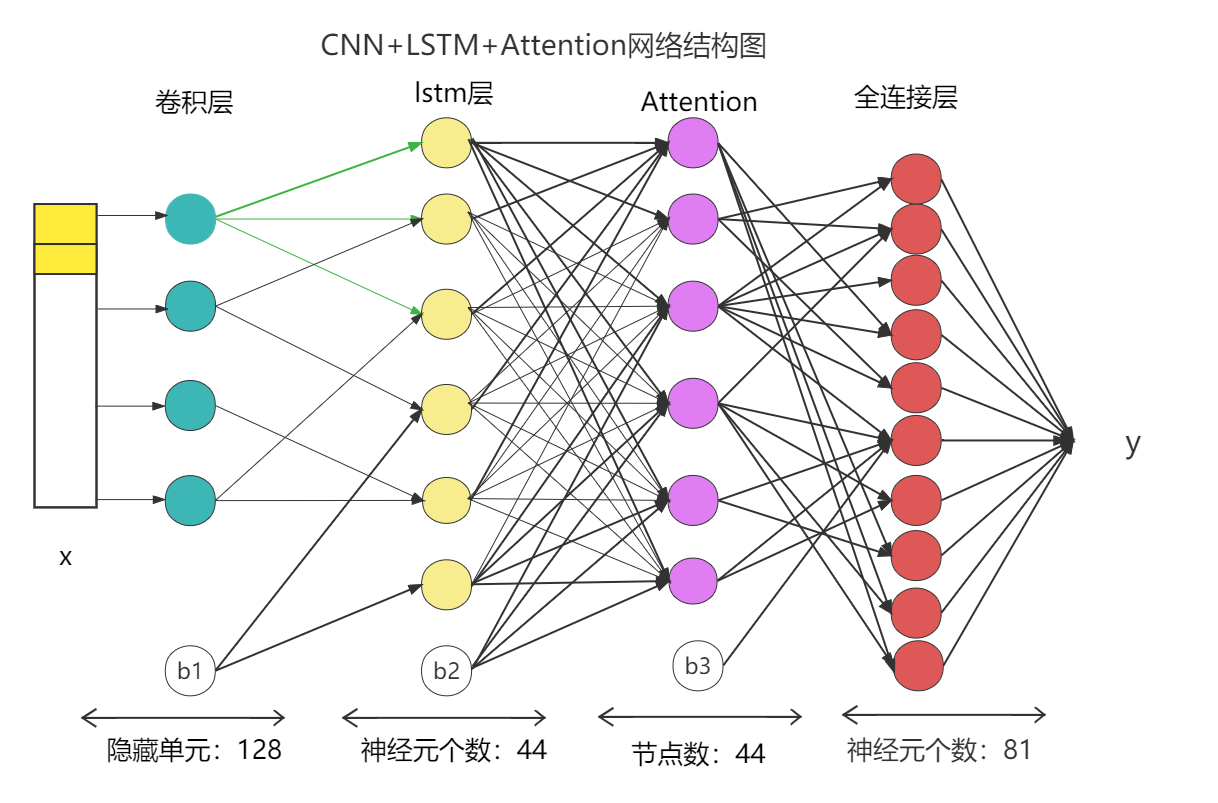
- 建立模型,卷积层-bilstm层-attention按顺序建立,attention层可放中间也可放前面,效果各不相同
- 训练模型,使用训练好的模型进行预测
- 调参优化,保存模型
2、数据介绍
需要完整代码和数据介绍请移步我的下载:
cnn+lstm+attention对时序数据进行预测
3、相关技术
BiLSTM:前向和方向的两条LSTM网络,被称为双向LSTM,也叫BiLSTM。其思想是将同一个输入序列分别接入向前和先后的两个LSTM中,然后将两个网络的隐含层连在一起,共同接入到输出层进行预测。
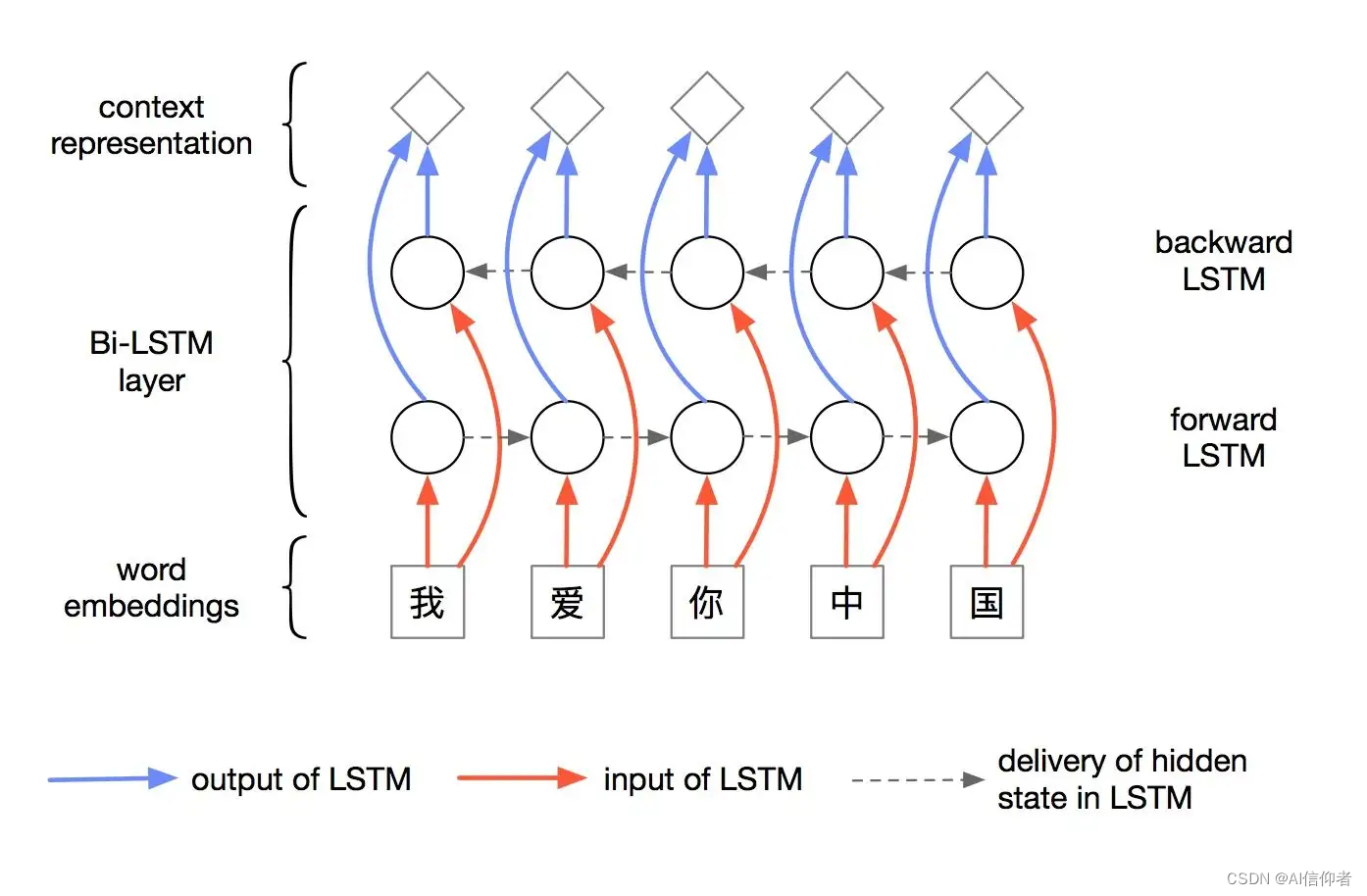
attention注意力机制
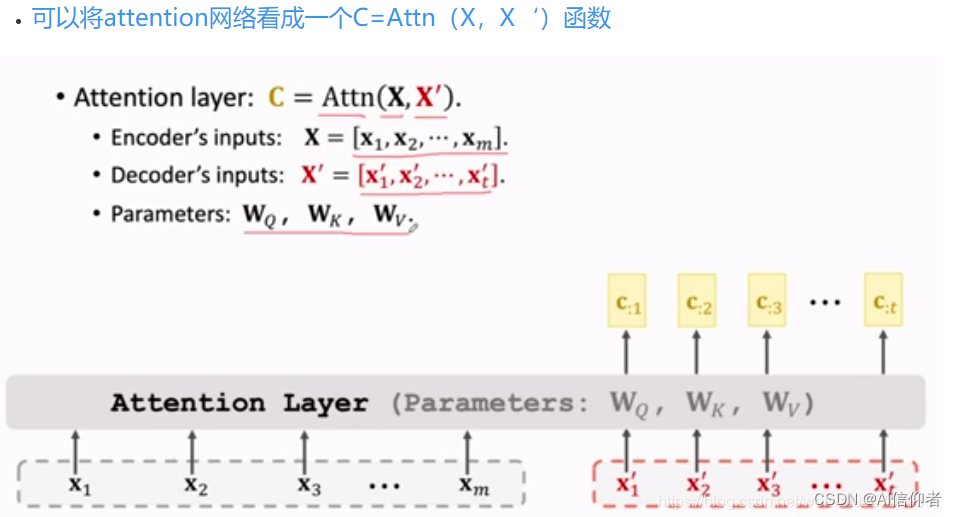
一维卷积
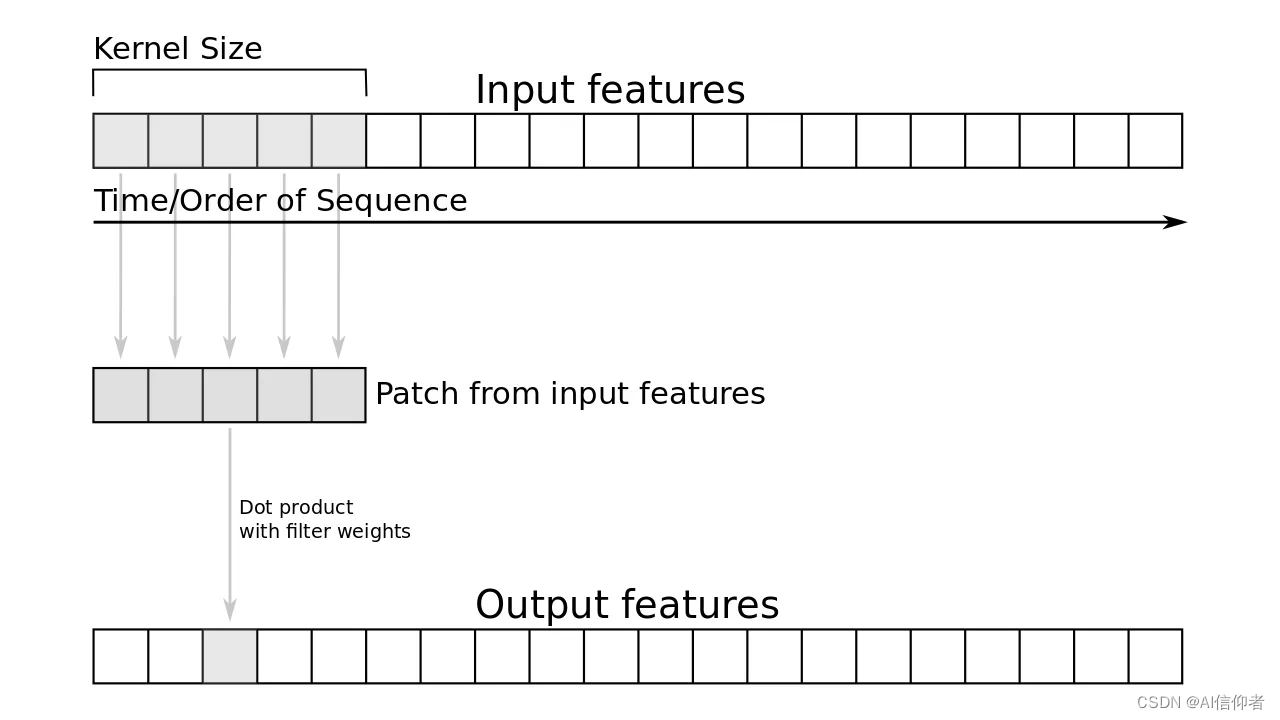
cnn+lstm+attention 网络结构图
4、完整代码和步骤
此程序运行代码版本为:
tensorflow==2.5.0
numpy==1.19.5
keras==2.6.0
matplotlib==3.5.2
主运行程序入口
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras.layers import Conv1D, Bidirectional, Multiply, LSTM
from keras.layers.core import *
from keras.models import *
from sklearn.metrics import mean_absolute_error
from keras import backend as K
from tensorflow.python.keras.layers import CuDNNLSTM
from my_utils.read_write import pdReadCsv
import numpy as np
SINGLE_ATTENTION_VECTOR = False
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
os.environ["TF_KERAS"] = '1'
# 注意力机制
def attention_3d_block(inputs):
input_dim = int(inputs.shape[2])
a = inputs
a = Dense(input_dim, activation='softmax')(a)
# 根据给定的模式(dim)置换输入的维度 例如(2,1)即置换输入的第1和第2个维度
a_probs = Permute((1, 2), name='attention_vec')(a)
# Layer that multiplies (element-wise) a list of inputs.
output_attention_mul = Multiply()([inputs, a_probs])
return output_attention_mul
# 创建时序数据块
def create_dataset(dataset, look_back):
dataX, dataY = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i:(i + look_back), :]
dataX.append(a)
dataY.append(dataset[i + look_back, :])
TrainX = np.array(dataX)
Train_Y = np.array(dataY)
return TrainX, Train_Y
# 建立cnn-BiLSTM-并添加注意力机制
def attention_model():
inputs = Input(shape=(TIME_STEPS, INPUT_DIMS))
# 卷积层和dropout层
x = Conv1D(filters=64, kernel_size=1, activation='relu')(inputs) # , padding = 'same'
x = Dropout(0.3)(x)
# For GPU you can use CuDNNLSTM cpu LSTM
lstm_out = Bidirectional(CuDNNLSTM(lstm_units, return_sequences=True))(x)
lstm_out = Dropout(0.3)(lstm_out)
attention_mul = attention_3d_block(lstm_out)
# 用于将输入层的数据压成一维的数据,一般用再卷积层和全连接层之间
attention_mul = Flatten()(attention_mul)
# output = Dense(1, activation='sigmoid')(attention_mul) 分类
output = Dense(1, activation='linear')(attention_mul)
model = Model(inputs=[inputs], outputs=output)
return model
# 归一化
def fit_size(x, y):
from sklearn import preprocessing
x_MinMax = preprocessing.MinMaxScaler()
y_MinMax = preprocessing.MinMaxScaler()
x = x_MinMax.fit_transform(x)
y = y_MinMax.fit_transform(y)
return x, y, y_MinMax
def flatten(X):
flattened_X = np.empty((X.shape[0], X.shape[2]))
for i in range(X.shape[0]):
flattened_X[i] = X[i, (X.shape[1] - 1), :]
return (flattened_X)
src = r'E:\dat'
path = r'E:\dat'
trials_path = r'E:\dat'
train_path = src + r'merpre.csv'
df = pdReadCsv(train_path, ',')
df = df.replace("--", '0')
df.fillna(0, inplace=True)
INPUT_DIMS = 43
TIME_STEPS = 12
lstm_units = 64
def load_data(df_train):
X_train = df_train.drop(['Per'], axis=1)
y_train = df_train['wap'].values.reshape(-1, 1)
return X_train, y_train, X_train, y_train
groups = df.groupby(['Per'])
for name, group in groups:
X_train, y_train, X_test, y_test = load_data(group)
# 归一化
train_x, train_y, train_y_MinMax = fit_size(X_train, y_train)
test_x, test_y, test_y_MinMax = fit_size(X_test, y_test)
train_X, _ = create_dataset(train_x, TIME_STEPS)
_, train_Y = create_dataset(train_y, TIME_STEPS)
print(train_X.shape, train_Y.shape)
m = attention_model()
m.summary()
m.compile(loss='mae', optimizer='Adam', metrics=['mae'])
model_path = r'me_pre\\'
callbacks = [
EarlyStopping(monitor='val_loss', patience=2, verbose=0), # 当两次迭代损失未改善,Keras停止训练
ModelCheckpoint(model_path, monitor='val_loss', save_best_only=True, verbose=0),
]
m.fit(train_X, train_Y, batch_size=32, epochs=111, shuffle=True, verbose=1,
validation_split=0.1, callbacks=callbacks)
# m.fit(train_X, train_Y, epochs=111, batch_size=32)
test_X, _ = create_dataset(test_x, TIME_STEPS)
_, test_Y = create_dataset(test_y, TIME_STEPS)
pred_y = m.predict(test_X)
inv_pred_y = test_y_MinMax.inverse_transform(pred_y)
inv_test_Y = test_y_MinMax.inverse_transform(test_Y)
mae = int(mean_absolute_error(inv_test_Y, inv_pred_y))
print('test_mae : ', mae)
mae = str(mae)
print(name)
m.save(
model_path + name[0] + '_' + name[1] + '_' + name[2] + '_' + mae + '.h5')
需要数据和代码代写请私聊,pytorch版本的也有,cnn+lstm+attention对时序数据进行预测
参考论文:
基于CNN和LSTM的多通道注意力机制文本分类模型



















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









