







4、Local Responce Normalization
CNN卷积神经网络的经典网络综述

CNN的发展详细介绍参见刘昕博士的《CNN的近期进展与实用技巧》,引用刘昕博士的思路,将按下图的CNN发展史进行描述:
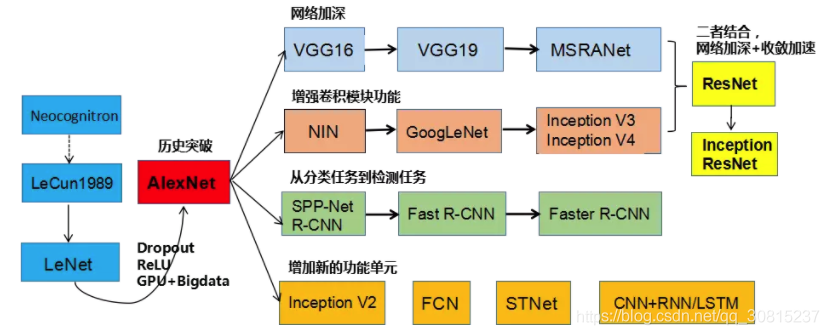
上图所示是刘昕博士总结的CNN结构演化的历史,起点是神经认知机模型,此时已经出现了卷积结构,经典的LeNet诞生于1998年。然而之后CNN的锋芒开始被SVM等手工设计的特征盖过。随着ReLU和dropout的提出,以及GPU和大数据带来的历史机遇,CNN在2012年迎来了历史突破–AlexNet.
本文将对CNN发展的四条路径中最具代表性的CNN模型结构进行讲解。
一切的开始( LeNet)
下图是广为流传LeNet(莱尼特)的网络结构,麻雀虽小,但五脏俱全,卷积层、pooling层、全连接层,这些都是现代CNN网络的基本组件。
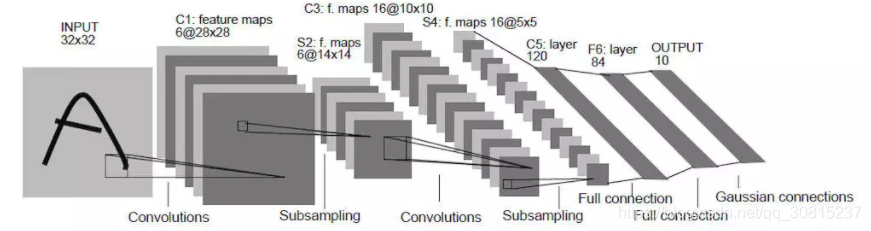
- 输入尺寸:32*32
- 卷积层:3个
- 降采样层:2个
- 全连接层:1个
- 输出:10个类别(数字0-9的概率)
因为LeNet可以说是CNN的开端,所以这里简单介绍一下各个组件的用途与意义。
1、Input (32*32)
输入图像Size为32*32。这要比mnist数据库中最大的字母(28*28)还大。这样做的目的是希望潜在的明显特征,如笔画断续、角点能够出现在最高层特征监测子感受野的中心。
2、C1, C3, C5 (卷积层)
卷积核在二维平面上平移,并且卷积核的每个元素与被卷积图像对应位置相乘,再求和。通过卷积核的不断移动,我们就有了一个新的图像,这个图像完全由卷积核在各个位置时的乘积求和的结果组成。
二维卷积在图像中的效果就是: 对图像的每个像素的邻域(邻域大小就是核的大小)加权求和得到该像素点的输出值。具体做法如下:
卷积运算一个重要的特点就是: 通过卷积运算,可以使原信号特征增强,并且降低噪音。
不同的卷积核能够提取到图像中的不同特征,这里有 在线demo.
以C1层进行说明:C1层是一个卷积层,有6个卷积核(提取6种局部特征),核大小为5*5,能够输出6个特征图Feature Map,大小为28*28。C1有156个可训练参数(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器(卷积核),共(5*5+1)*6 = 156个参数),共156 *(28*28) = 122,304个连接。
3、S2, S4 (pooling层)
S2, S4是下采样层,是为了降低网络训练参数及模型的过拟合程度。池化/采样的方式通常有以下两种:
Max-Pooling:选择Pooling窗口中的最大值作为采样值;
Mean-Pooling:将Pooling窗口中的所有值相加取平均,以平均值作为采样值;
这里采用的是平均池化,S2层是6个14*14的feature map,map中的每一个单元于上一层的 2*2 领域相连接,所以,S2层是C1层的1/4。
卷积网络经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性.最大池化只是计算神经网络某一层的静态属性,没有什么需要学习的,它只是一个静态属性。
需要注意的一点是,池化过程中没有需要学习的参数。执行反向传播时,反向传播没有参数适用于最大池化。只有这些设置过的超参数(核尺寸,步长),可能是手动设置的,也可能是通过交叉验证设置的。
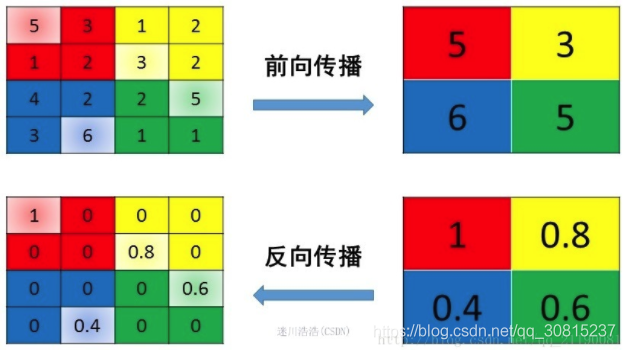
Pooling池化操作的反向梯度传播
因为Pooling操作使得feature map的尺寸变化,假如做2×2的池化,假设那么第l+1层的feature map有16个梯度,那么第l层就会有64个梯度,这使得梯度无法对位的进行传播下去。其实解决这个问题的思想也很简单,就是把1个像素的梯度传递给4个像素,但是需要保证传递的loss(或者梯度)总和不变。根据这条原则,mean pooling和max pooling的反向传播也是不同的。
1、mean pooling
mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变,还是比较理解的,图示如下 :
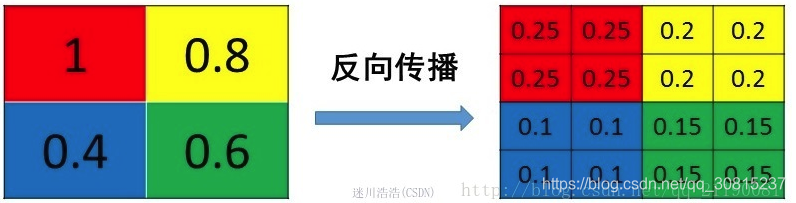
mean pooling比较容易让人理解错的地方就是会简单的认为直接把梯度复制N遍之后直接反向传播回去,但是这样会造成loss之和变为原来的N倍,网络是会产生梯度爆炸的。
2、max pooling
max pooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是max id,这个变量就是记录最大值所在位置的,因为在反向传播中要用到,那么假设前向传播和反向传播的过程就如下图所示 :
4、F6 (全连接层)
F6是全连接层,类似MLP(多层感知器)中的一个layer,共有84个神经元(为什么选这个数字?跟输出层有关),这84个神经元与C5层进行全连接,所以需要训练的参数是:(120+1)*84 = 10164. 如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置bias。然后将其传递给sigmoid函数产生单元 i 的一个状态。
5、Output (输出层)
输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。 换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。
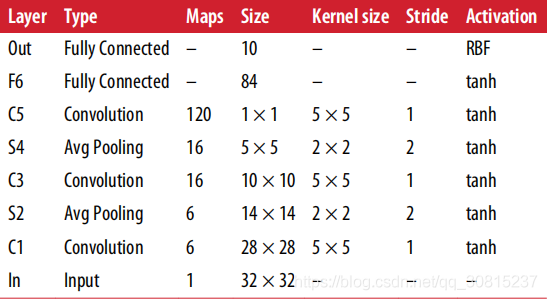
详细参数:
1、INPUT层
首先是数据输入层,输入图像的尺寸统一归一化为32*32。
注意:本层不算LeNet-5的网络结构,传统上,不将输入层视为网络层次结构之一。
2、C1层-卷积层
输入图片尺寸:32x32x1(MNIST数据集是28*28,对齐进行边缘0填充扩展为32*32);
输出featuremap尺寸:28x28x6;(32-5+1=28,filter=5*5, strides(步幅)=1, padding(填充方式选择“不填充”)='VALID')
卷积层参数:5x5x1x6+6=156个参数,其中6个为偏置参数;
卷积层连接:(5x5+1)x28x28x6=122304个连接。
- 输入图片:32*32
- 卷积核大小:5*5
- 卷积核种类:6
- 神经元数量:28*28*6
- 可训练参数:(5*5+1) * 6(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器)
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小为 5*5 的卷积核),得到6个C1特征图(6个大小为28*28的 feature maps, 32-5+1=28)。我们再来看看需要多少个参数,卷积核的大小为5*5,总共就有6*(5*5+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的5*5个像素和1个bias有连接,所以总共有156*28*28=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
3、S2层-池化层(下采样层)
输入图片尺寸:28x28x6;
输出图片尺寸:14x14x6;(filter=2*2, strides=2, padding='SAME')
池化层参数:2x6=12个参数;
池化层连接:(4+1)x14x14x6=5880个连接。
- 采样区域:2*2
- 采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
- 采样种类:6
- 神经元数量:14*14*6
详细说明:第一次卷积之后紧接着就是池化运算,使用 2*2核 进行池化,于是得到了S2,6个14*14的特征图(28/2=14)。S2中每个特征图的大小是C1中特征图大小的1/4。S2这个pooling层是对C1中的2*2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。同时有(4+1)x14x14x6=5880个连接。
4、C3层-卷积层
输入图片尺寸:14x14x6;
输出图片尺寸:10x10x16;(14-5+1=10,filter=5*5, strides=1, padding='VALID')
卷积层参数:(5x5x3+1)x6 + (5x5x4 + 1) x 3 + (5x5x4 +1)x6 + (5x5x6+1)x1 = 1516个参数;(这里的卷积核不再是二维平面卷积核,而是3维卷积核,分别对应3层,4层,4层,6层)
卷积层连接:1516x10x10=151600个连接。
Note: C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合,存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。这样C3层有1516个可训练参数和151600个连接。
- 输入:S2中所有6个或者几个特征map组合
- 卷积核种类:16
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 5*5. 我们知道S2有6个 14*14 的特征图,怎么从6 个特征图得到 16个特征图了? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。具体如下:
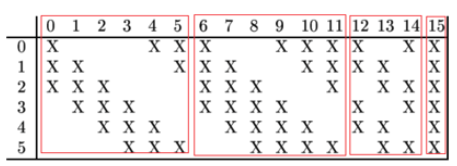
C3的前6个feature map(对应上图第一个红框的6列)与S2层相连的3个feature map相连接(上图第一个红框),后面6个feature map与S2层相连的4个feature map相连接(上图第二个红框),后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为5*5,所以总共有6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516个参数。而图像大小为10*10,所以共有151600个连接。
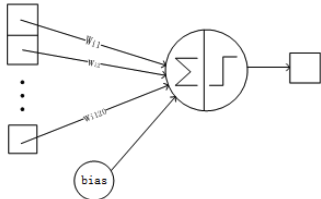
C3与S2中前3个图相连的卷积结构如下图所示:
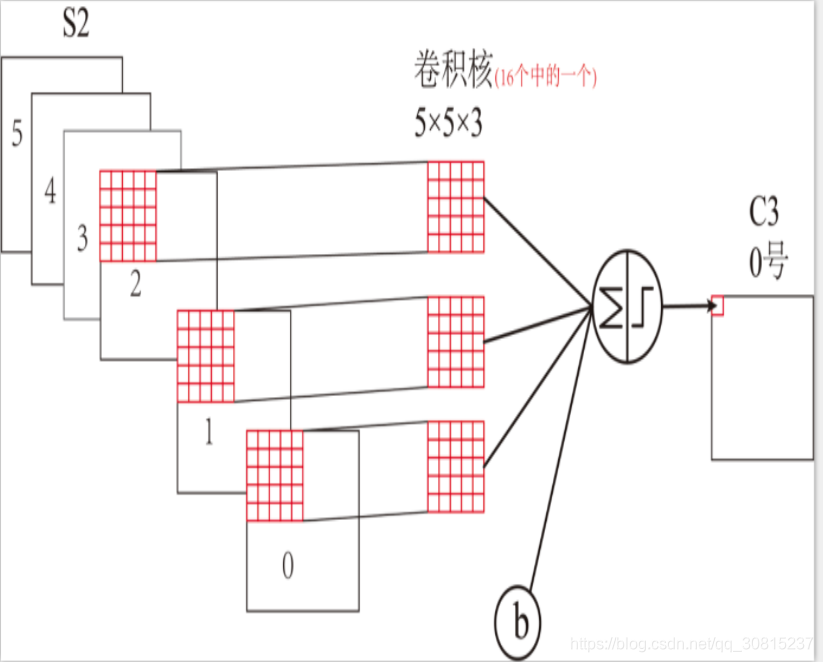
上图对应的参数为 3*5*5+1,一共进行6次卷积得到6个特征图,所以有6*(3*5*5+1)参数。 为什么采用上述这样的组合了?论文中说有两个原因:
- 减少参数
- 这种不对称的组合连接的方式有利于提取多种组合特征。
5、S4层-池化层(下采样层)
输入图片尺寸:10x10x16;
输出featureMap尺寸:5x5x16;(filter=2*2, strides=2, padding='SAME')
池化层参数:2x16=32个参数;
池化层连接:(4+1)x5x5x16=2000个连接。
- 采样区域:2*2
- 采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
- 采样种类:16
- 神经元数量:5*5*16=400
详细说明:S4是pooling层,窗口大小仍然是2*2,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。有5x5x5x16=2000个连接。连接的方式与S2层类似。
6、C5层-卷积层
输入图片尺寸:5x5x16;
输出图片尺寸:1x1x120;(filter=5*5, strides=1,5-5+1)
卷积层参数:(5x5x16+1)x120=48120个参数;(120个三维卷积核,卷积核维度是5*5*16,即一个卷积核有16层,每层参数相同)
卷积层连接:(5x5x16+1)x120=48120个连接,与参数大小一致(相当于全连接)。
- 输入:S4层的全部16个单元特征map(与s4全相连)
- 卷积核大小:5*5
- 卷积核种类:120
详细说明:S4层的16个特征图的尺寸为5x5,与C5卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构如下:
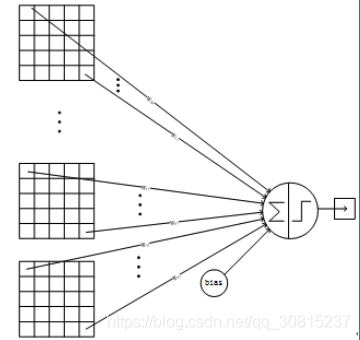
7、F6层-全连接层
输入图片尺寸:1x1x120;(C5 层的120维向量)
输出图片尺寸:1x1x84;
全连接层参数:(120+1)x84=10164个参数;
全连接层连接:(120+1)x84=10164个连接,与参数大小一致。(84个神经元,与120维向量全连接)
计算方式:计算输入向量和权重向量之间的点积(结果为标量),再加上一个偏置,结果通过sigmoid函数输出。
详细说明:全连接层F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。ASCII编码图如下:???????不懂

F6层的连接方式如下:
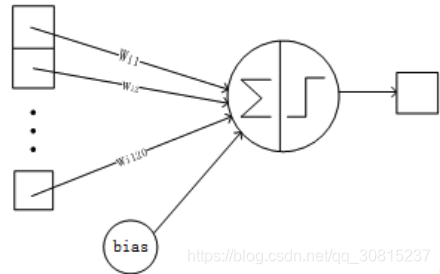
8、Output层-全连接层
输入图片尺寸:1x1x84;
输出图片尺寸:1x1x10;
全连接层参数:(84+1)x10=850个参数;
全连接层连接:(84+1)x10=850个连接,与参数大小一致
Output层也是全连接层,共有10个节点,分别代表数字0到9,如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
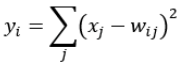
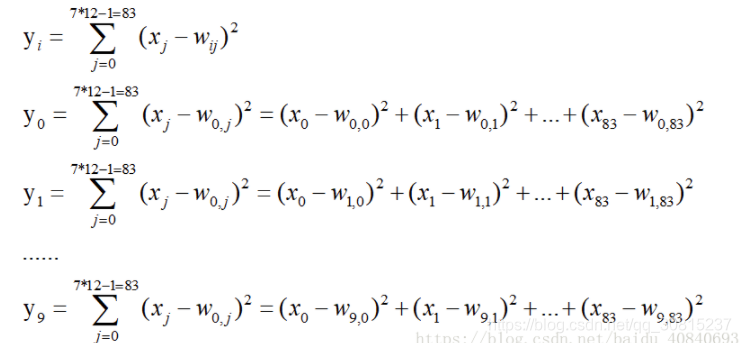
上式的值由i的比特图编码确定,i从0到9,j取值从0到7*12-1。RBF输出的值越接近于0,则越接近于 i,即越接近于 i 的ASCII编码图,表示当前网络输入的识别结果是字符 i。该层有84x10=840个参数和连接。
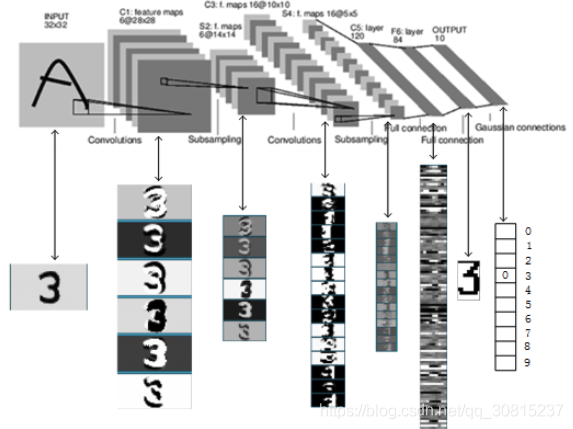
上图是LeNet-5识别数字3的过程。Yann LeCun的个人网站http://yann.lecun.com/exdb/lenet/index.html有演示数字识别的例子。
也可以参考一下Caffe中的配置文件:https://github.com/BVLC/caffe/blob/master/examples/mnist/lenet.prototxt
常用预训练模型池:https://github.com/BVLC/caffe/wiki/Model-Zoo
总结
- LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络。代码见:使用LeNet-5和类LeNet-5网络识别手写字体
- 卷积神经网络能够很好的利用图像的结构信息。
- 卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
from :https://cuijiahua.com/blog/2018/01/dl_3.html
from:https://blog.csdn.net/Fireman1994/article/details/78659270
王者回归(AlexNet)
AlexNet 可以说是具有历史意义的一个网络结构,可以说在AlexNet之前,深度学习已经沉寂了很久。历史的转折在2012年到来,AlexNet 在当年的ImageNet图像分类竞赛中,top-5错误率比上一年的冠军下降了十个百分点,而且远远超过当年的第二名。AlexNet 之所以能够成功,深度学习之所以能够重回历史舞台,原因在于:
- 非线性激活函数:ReLU
- 防止过拟合的方法:Dropout,Data augmentation
- 大数据训练:百万级ImageNet图像数据
- 其他:GPU实现,LRN归一化层的使用
AlexNet的创新有如下几个方面:
1、Data augmentation
有一种观点认为神经网络是靠数据喂出来的,若增加训练数据,则能够提升算法的准确率,因为这样可以避免过拟合,而避免了过拟合你就可以增大你的网络结构了。当训练数据有限的时候,可以通过一些变换来从已有的训练数据集中生成一些新的数据,来扩大训练数据的size。
其中,最简单、通用的图像数据变形的方式:
- 从原始图像(256,256)中,随机的crop出一些图像(224,224)。【平移变换,crop】
- 水平翻转图像。【反射变换,flip】
- 给图像增加一些随机的光照。【光照、彩色变换,color jittering】

AlexNet 训练的时候,在data augmentation上处理的很好:
- 随机crop。训练时候,对于256*256的图片进行随机crop到224*224,然后允许水平翻转,那么相当与将样本倍增到((256-224)^2)*2=2048。
- 测试时候,对左上、右上、左下、右下、中间做了5次crop,然后翻转,共10个crop,之后对结果求平均。作者说,不做随机crop,大网络基本都过拟合(under substantial overfitting)。
- 对RGB空间做PCA,然后对主成分做一个(0, 0.1)的高斯扰动。结果让错误率又下降了1%。
2、ReLU 激活函数
Sigmoid 是常用的非线性的激活函数,它能够把输入的连续实值“压缩”到0和1之间。特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1.
但是它有一些致命的 缺点:
- 当输入非常大或者非常小的时候,会有饱和现象,这些神经元的梯度是接近于0的。如果你的初始值很大的话,梯度在反向传播的时候因为需要乘上一个sigmoid 的导数,所以会使得梯度越来越小,这会导致网络变的很难学习。
- Sigmoid 的 output 不是0均值. 这是不可取的,因为这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。 产生的一个结果就是:如果数据进入神经元的时候是正的(e.g. x>0 elementwise in f=wTx+b),那么 w计算出的梯度也会始终都是正的。 当然了,如果你是按batch去训练,那么那个batch可能得到不同的信号,所以这个问题还是可以缓解一下的。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的 kill gradients 问题相比还是要好很多的。
Alex用ReLU代替了Sigmoid,发现使用 ReLU 得到的SGD的收敛速度会比 sigmoid/tanh 快很多。
主要是因为它是linear,而且 non-saturating(因为ReLU的导数始终是1),相比于 sigmoid/tanh,ReLU 只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的运算。
3、Dropout
AlexNet 提出了一个非常有效的模型组合版本,它在训练中只需要花费两倍于单模型的时间。这种技术叫做Dropout,它做的就是以0.5的概率,将每个隐层神经元的输出设置为零。以这种方式“dropped out”的神经元既不参与前向传播,也不参与反向传播。
每次输入一个样本,就相当于该神经网络就尝试了一个新的结构,但是所有这些结构之间共享权重。因为神经元不能依赖于其他特定神经元而存在,所以这种技术降低了神经元复杂的互适应关系。正因如此,网络需要被迫学习更为鲁棒的特征,这些特征在结合其他神经元的一些不同随机子集时有用。在测试时,我们将所有神经元的输出都仅仅只乘以0.5,对于获取指数级dropout网络产生的预测分布的几何平均值,这是一个合理的近似方法。
4、Local Responce Normalization
LRN是一种提高深度学习准确度的技术方法。LRN一般是在激活、池化函数后的一种方法。 在ALexNet中,提出了LRN层,对局部神经元的活动创建竞争机制,使其中响应比较大对值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。LRN的详细介绍如下: (链接地址:tensorflow下的局部响应归一化函数tf.nn.lrn)
总结的来说,是对输入值除以一个数达到归一化的目的。具体计算公式如下:
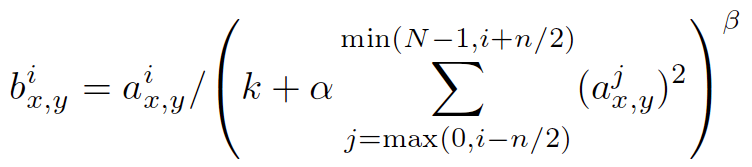
是归一化后的值,i是通道的位置,代表更新第几个通道的值,x与y代表待更新像素的位置。
是输入值,表示卷积层(包括卷积操作和池化操作)后的输出结果,是一个四维数组[batch,height,width,channel]。batch就是批次数(每一批为一张图片),height就是图片高度,width就是图片宽度,channel就是通道数可以理解成一批图片中的某一个图片经过卷积操作后输出的神经元个数(或是理解成处理后的图片深度)。
- k、alpha、beta、n/2 都是自定义系数,一般设置k=2,n=5,aloha=1*e-4,beta=0.75。
- N是总的通道数,即kernal的总数。注意一下∑叠加的方向是沿着通道方向的,即每个点值的平方和是沿着a中的channel方向的,也就是一个点同方向的前面n/2个通道(最小为第0个通道)和后n/2个通道(最大为第d-1个通道)的点的平方和(共n+1个点)。而函数的英文注解中也说明了把input当成是d个3维的矩阵,说白了就是把input的通道数当作3维矩阵的个数,叠加的方向也是在通道方向。
- a表示第i个神经元在位置(x, y)使用激活函数ReLU后的输出,n是同一位置上临近的kernal map的数目.
一句话概括:本质上,这个层也是为了防止激活函数的饱和的。
通过正则化让激活函数的输入靠近“碗”的中间(避免饱和),从而获得比较大的导数值。所以从功能上说,跟ReLU是重复的。从试验结果看,LRN操作可以提高网络的泛化能力,将错误率降低了大约1个百分点。
AlexNet 优势在于:网络增大(5个卷积层+3个全连接层+1个softmax层),同时解决过拟合(dropout,data augmentation,LRN),并且利用多GPU加速计算。
AlexNet网络结构:
AlexNet网络共有:卷积层 5个,池化层 3个,全连接层:3个(其中包含输出层)。
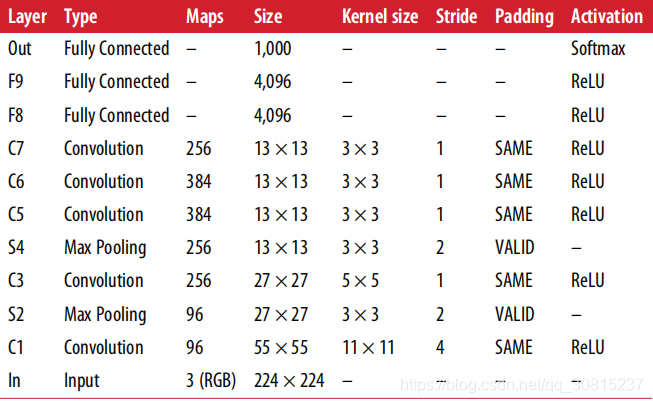
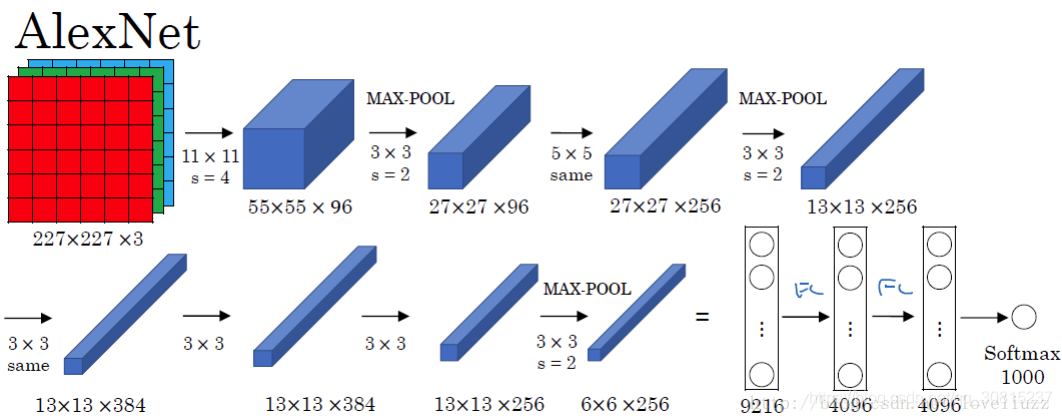
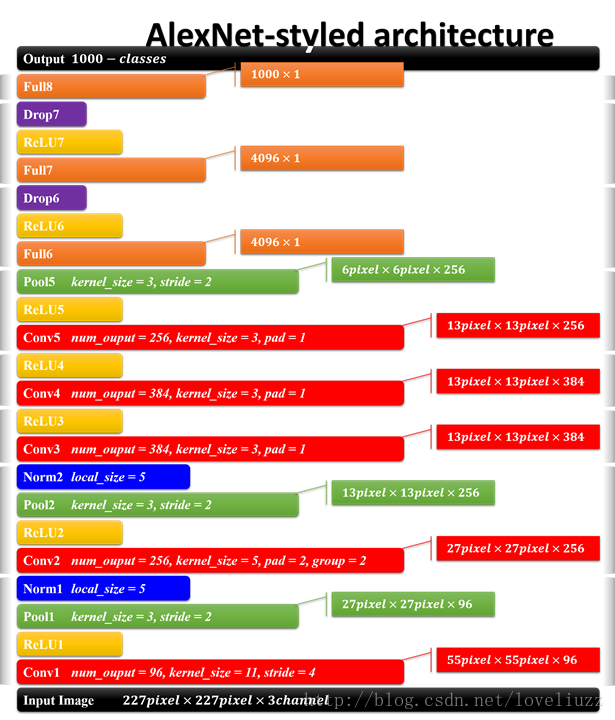
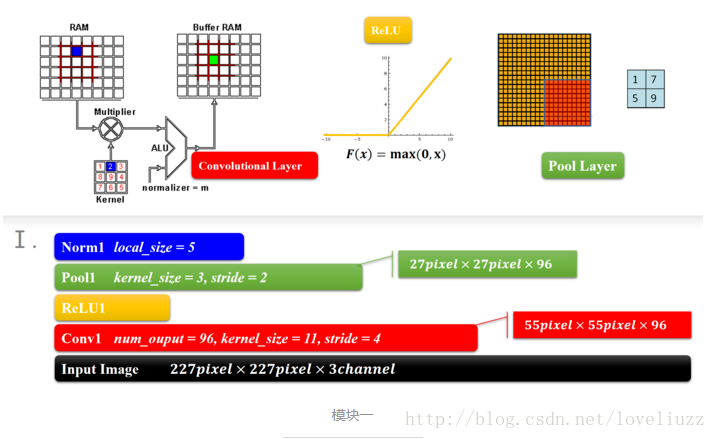
AlexNet的结构图,它是由八个模块组成的。
1、AlexNet——模块一和模块二
结构类型为:卷积——激活函数(ReLU)——降采样(池化)——标准化
这两个模块是CNN的前面部分,构成了一个计算模块,这个可以说是一个卷积过程的标配,从宏观的角度来看,就是一层卷积,一层降采样这样循环的,中间适当地插入一些函数来控制数值的范围,以便后续的循环计算。
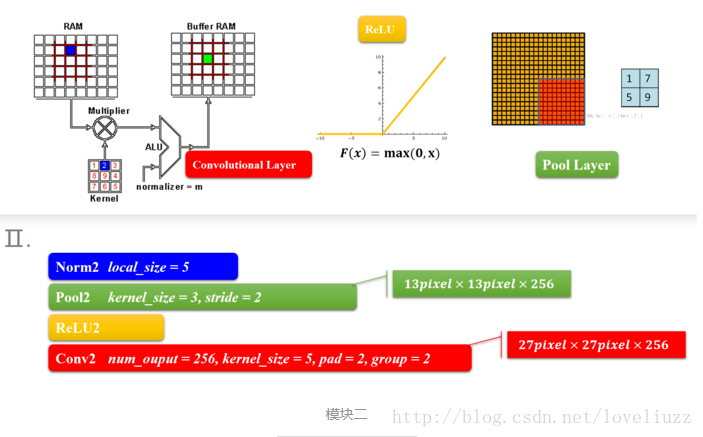
2、AlexNet——模块三和模块四
模块三和模块四也是两个same卷积过程,差别是少了降采样(池化层),原因就跟输入的尺寸有关,特征的数据量已经比较小了,所以没有降采样。

3、AlexNet——模块五
模块五也是一个卷积和池化过程,和模块一、二一样的。模块五输出的其实已经是6*6的小块儿了(一般设计可以到1*1的小块,由于ImageNet的图像大,所以6*6也正常的)。原来输入的227*227像素的图像会变成6*6这么小,主要原因是归功于池化层降采样,当然卷积层也会让图像变小,一层层的下去,图像越来越小。

4、模块六、七
模块六和七就是所谓的全连接层了,全连接层就和人工神经网络的结构一样的,结点数超级多,连接线也超多,所以这儿引出了一个dropout层,来去除一部分没有足够激活的层。

5、模块八
是一个输出的结果,结合softmax做出分类。有几类,输出几个结点,每个结点保存的是属于该类别的概率值。
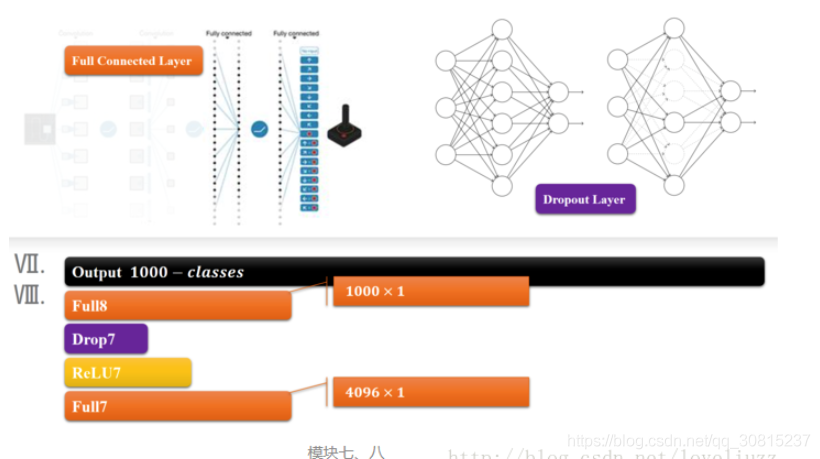
AlexNet总结
- 输入尺寸:227*227*3
- 卷积层:5个
- 降采样层(池化层):3个
- 全连接层:2个
- 输出层:1个。1000个类别
转载来自:https://blog.csdn.net/loveliuzz/article/details/79131131
DL开源caffe的Alexnet的配置
在imagenet上的图像分类赛上Alex提出的Alexnet网络结构模型赢得了2012届的冠军。要研究CNN类型DL网络模型在图像分类上的应用,就逃不开研究Alexnet,这是CNN在图像分类上的经典模型(DL火起来之后)。在DL开源实现caffe的model样例中,它也给出了Alexnet的复现,具体网络配置文件如下:
https://github.com/BVLC/caffe/blob/master/models/bvlc_reference_caffenet/train_val.prototxt
AlexNet 代码及模型(Caffe) https://github.com/BVLC/caffe/tree/master/models/bvlc_alexnet
微调AlexNet以适应任意数据集(Tensorflow) https://github.com/kratzert/finetune_alexnet_with_tensorflow
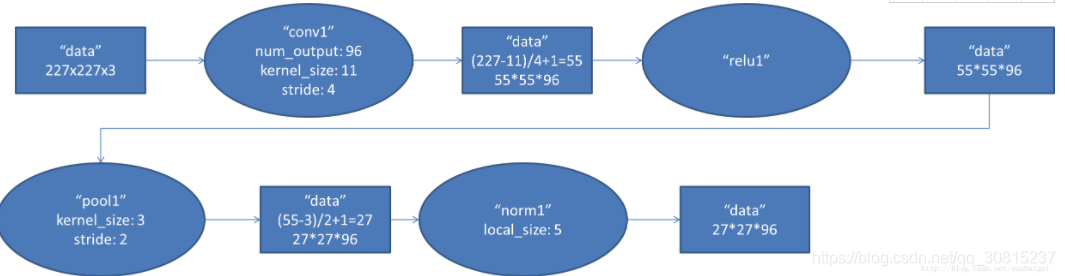
1. conv1阶段DFD(data flow diagram)C1/S2:
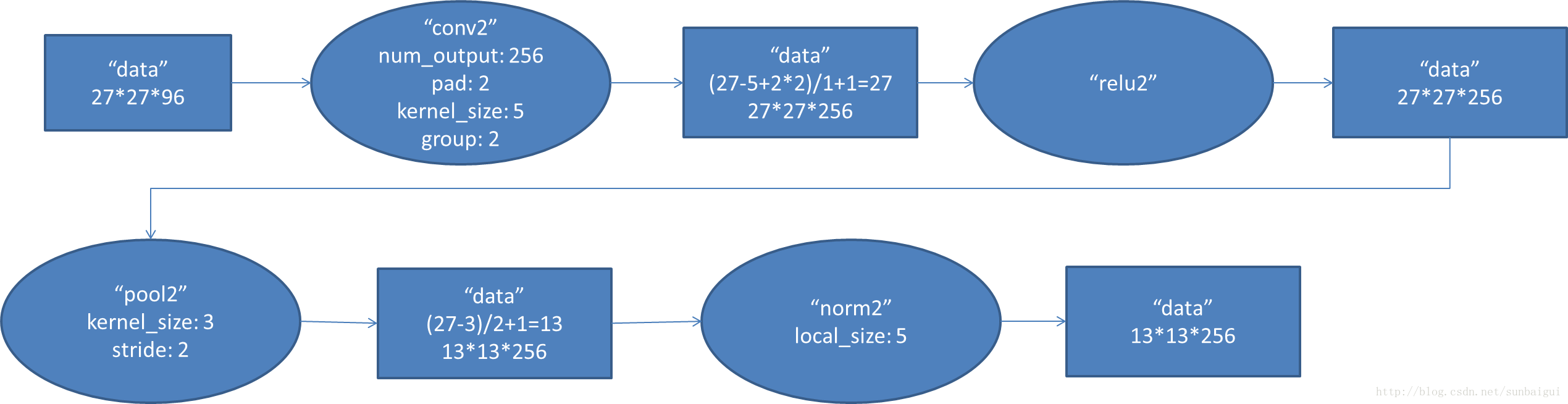
2. conv2阶段DFD(data flow diagram)C3/S4:
3. conv3阶段DFD(data flow diagram)C5:

4. conv4阶段DFD(data flow diagram)C6:

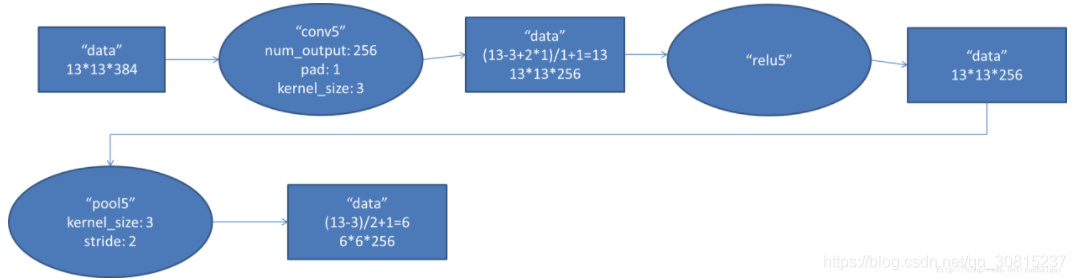
5. conv5阶段DFD(data flow diagram)C7:
6. fc6阶段DFD(data flow diagram)F8:
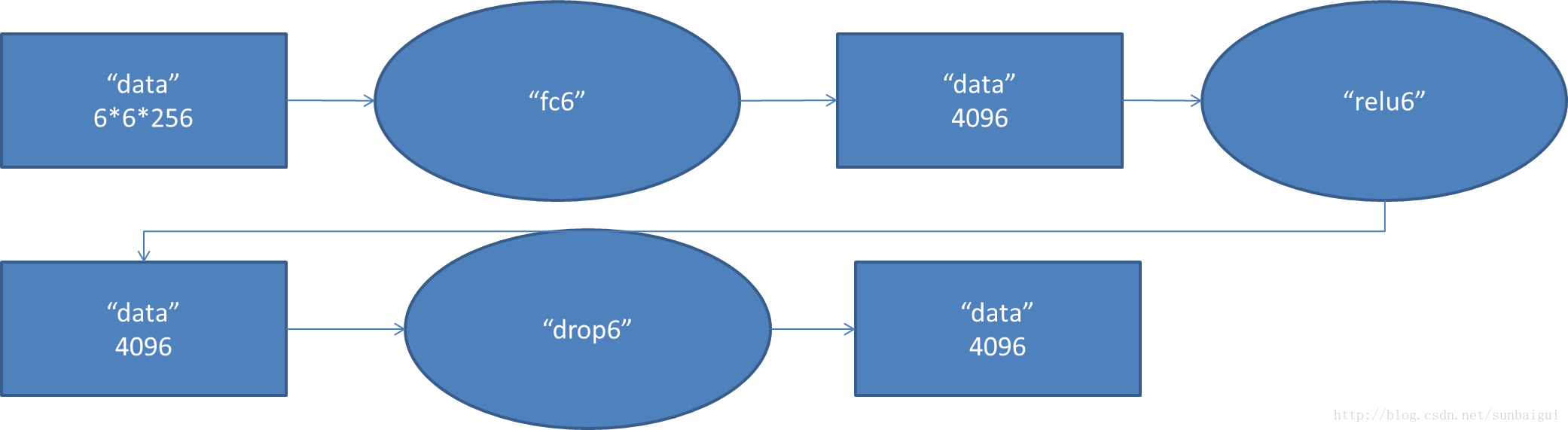
7. fc7阶段DFD(data flow diagram)F9:
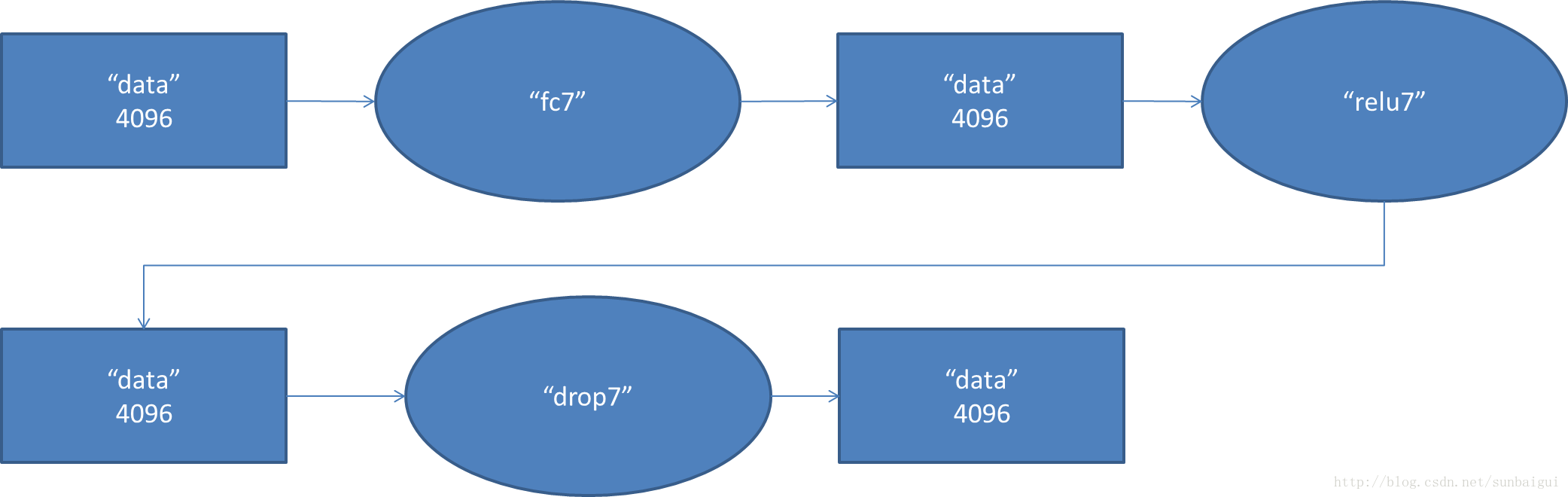
8. fc8阶段DFD(data flow diagram)OUT:

各种layer的operation更多解释可以参考http://caffe.berkeleyvision.org/tutorial/layers.html
from :https://blog.csdn.net/sunbaigui/article/details/39938097
AlexNet将LeNet的思想发扬光大,AlexNet主要使用到的新技术点如下:
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)数据增强,随机从256*256的原始图像截取224*224大小区域(以及水平翻转镜像),相当于增加数据量,仅靠原始数据量,CNN众多的参数,会过拟合,通过数据增强大大减小过拟合。测试时,对图片取4个角加中间5个位置,并进行左右翻转,共10幅图,对齐进行预测求均值。
AlexNet的tensorflow实现:
AlexNet.py文件实现前向传播过程以及网络的参数的代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#用AlexNet实现电脑破译手语——SIGNG datasets
#训练集:1080张图片,每张图片大小为:64*64*3,表示数字0至5,每个数字的图片为180张
#测试集:120张图片,每张图片大小为:64*64*3,表示数字0至5,每个数字的图片为20张
#AlexNet网络框架实现前向传播过程及网络的参数
import tensorflow as tf
#显示网络每一层结构的函数,展示每一个卷积层或池化层输出Tensor的尺寸
def print_acrivations(t):
"""
显示每一层的名称(t.op.name)和tensor的尺寸(t.get_shape.as_list())
param :
t -- Tensor类型的输入
"""
print(t.op.name," ",t.get_shape.as_list())
#配置AlexNet网络的参数
NUM_CHANNELS = 3 #图片的通道数
#第一层卷积层的尺寸和深度(卷积核个数)
CONV1_SIZE = 11
CONV1_DEEP = 96
#第二层卷积层的尺寸和深度(卷积核个数)
CONV2_SIZE = 5
CONV2_DEEP = 256
#第三层卷积层的尺寸和深度(卷积核个数)
CONV3_SIZE = 3
CONV3_DEEP = 384
#第四层卷积层的尺寸和深度(卷积核个数)
CONV4_SIZE = 3
CONV4_DEEP = 256
#第五层卷积层的尺寸和深度(卷积核个数)
CONV5_SIZE = 3
CONV5_DEEP = 256
#第六、七层全连接层的尺寸
FC6_SIZE = 4096
FC7_SIZE = 4096
#输出层的尺寸(分类数目)
OUTPUT_NODE = 10
def AlexNet(input_tensor,train,regularizer):
"""
AlexNet网络框架实现前向传播过程
param :
input_tensor -- 输入的张量,一般为图片
train -- 用于区分训练和测试过程
regularizer -- 正则化
return:
out -- 输出最后一层
"""
# 第一个卷积层
with tf.variable_scope("conv1"):
# 第一个卷积层,用截断的正态分布函数tf.truncated_normal_initializer 初始化卷积核conv1_weights
# 卷积核大小为 11*11*3,个数为96个
conv1_weights = tf.get_variable(name="weight",shape=[CONV1_SIZE,CONV1_SIZE,NUM_CHANNELS,CONV1_DEEP],
dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1))
# 初始化偏向biases全部为0
conv1_biases = tf.get_variable(name="bias",shape=[CONV1_DEEP],
dtype=tf.float32,initializer=tf.constant_initializer(0.0))
# 卷积操作,步长s = 4,padding = "SAME"
conv1 = tf.nn.conv2d(input=input_tensor,filter=conv1_weights,strides=[1,4,4,1],padding="SAME")
# 将conv和baises加起来并进行relu激活
conv1 = tf.nn.relu(tf.nn.bias_add(conv1,conv1_biases))
# 打印conv1的结构
print_acrivations(conv1)
# 卷积层后添加LRN层(除AlexNet其他经典网络基本无LRN层,效果不明显且速度有所降低)
lrn1 = tf.nn.lrn(conv1, depth_radius=4, bias=1.0, alpha=0.001 / 9, beta=0.75, name="lrn1")
# 最大池化层(尺寸为 3*3,步长s=2*2)
pool1 = tf.nn.max_pool(lrn1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="VALID", name="pool1")
# 打印pool1的结构
print_acrivations(pool1)
#第二个卷积层,卷积核大小为(5,5,96,256)
with tf.variable_scope("conv2"):
conv2_weights = tf.get_variable(name="weight",shape=[CONV2_SIZE,CONV2_SIZE,CONV1_DEEP,CONV2_DEEP],
dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable(name="bias",shape=[CONV2_DEEP],
dtype=tf.float32,initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(input=pool1,filter=conv2_weights,strides=[[1,1,1,1]],padding="SAME")
conv2 = tf.nn.relu(tf.nn.bias_add(conv2,conv2_biases))
print_acrivations(conv2)
lrn2 = tf.nn.lrn(conv2, depth_radius=4, bias=1.0, alpha=0.001 / 9, beta=0.75, name="lrn2")
pool2 = tf.nn.max_pool(lrn2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="VALID", name="pool2")
print_acrivations(pool2)
# 第三个卷积层,卷积核大小为(3,3,256,384),无LRN与最大池化
with tf.variable_scope("conv3"):
conv3_weights = tf.get_variable(name="weight",shape=[CONV3_SIZE,CONV3_SIZE,CONV2_DEEP,CONV3_DEEP],
dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1))
conv3_biases = tf.get_variable(name="bias",shape=[CONV3_DEEP],
dtype=tf.float32,initializer=tf.constant_initializer(0.0))
conv3 = tf.nn.conv2d(input=pool2,filter=conv3_weights,strides=[1,1,1,1],padding="SAME")
conv3 = tf.nn.relu(tf.nn.bias_add(conv3,conv3_biases))
print_acrivations(conv3)
# 第四个卷积层,卷积核大小为(3,3,384,256),无LRN与最大池化
with tf.variable_scope("conv4"):
conv4_weights = tf.get_variable(name="weight",shape=[CONV4_SIZE,CONV4_SIZE,CONV3_DEEP,CONV4_DEEP],
dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1))
conv4_biases = tf.get_variable(name="bias",shape=[CONV4_DEEP],
dtype=tf.float32,initializer=tf.constant_initializer(0.0))
conv4 = tf.nn.conv2d(input=conv3,filter=conv4_weights,strides=[1,1,1,1],padding="SAME")
conv4 = tf.nn.relu(tf.nn.bias_add(conv4,conv4_biases))
print_acrivations(conv4)
# 第五个卷积层,卷积核大小为(3,3,256,256)
with tf.variable_scope("conv5"):
conv5_weights = tf.get_variable(name="weight",shape=[CONV5_SIZE,CONV5_SIZE,CONV4_DEEP,CONV5_DEEP],
dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1))
conv5_biases = tf.get_variable(name="bias",shape=[CONV5_DEEP],
dtype=tf.float32,initializer=tf.constant_initializer(0.0))
conv5 = tf.nn.conv2d(input=conv4,filter=conv5_weights,strides=[1,1,1,1],padding="SAME")
conv5 = tf.nn.relu(tf.nn.bias_add(conv5,conv5_biases))
print_acrivations(conv5)
pool5 = tf.nn.max_pool(conv5,ksize=[1,3,3,1],strides=[1,2,2,1],padding="VALID",name="pool5")
print_acrivations(pool5)
# 第六层 —— 全连接层及dropout
#将第五层输出转化为第六层全连接层输入为向量的格式,即:将矩阵拉成一个向量
#每层输入输出都为一个batch矩阵,得到的维度包含pool5_shape[0] = batch中数据的个数
pool5_shape = pool5.get_shape().as_list()
nodes = pool5_shape[1]*pool5_shape[2]*pool5_shape[3]
dense = tf.reshape(pool5,shape=[pool5_shape[0],nodes]) #向量化
with tf.variable_scope("fc6"):
fc6_weights = tf.get_variable(name="weight",shape=[nodes,FC6_SIZE],dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.1))
#当给出了正则化生成函数,将当前变量的正则化损失加入名字为losses的集合
#add_to_collection函数将一个张量加入一个集合,自定义的集合losses,不在tensorflow自动管理的集合列表中中
if regularizer != None:
tf.add_to_collection("losses",regularizer(fc6_weights))
fc6_biases = tf.get_variable(name="bias",shape=[FC6_SIZE],dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
fc6 = tf.nn.relu(tf.add(tf.matmul(dense,fc6_weights),fc6_biases))
#dropout只在训练时使用
if train:
fc6 = tf.nn.dropout(fc6,keep_prob=0.7)
# 第七层 —— 全连接层及dropout
with tf.variable_scope("fc7"):
fc7_weights = tf.get_variable(name="weight",shape=[FC6_SIZE,FC7_SIZE],dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection("losses",regularizer(fc7_weights))
fc7_biases = tf.get_variable(name="bias",shape=[FC7_SIZE],dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
fc7 = tf.nn.relu(tf.add(tf.matmul(fc6,fc7_weights),fc7_biases))
if train:
fc7 = tf.nn.dropout(fc7,keep_prob=0.7)
# 第八层 —— 全连接层/输出层
with tf.variable_scope("fc8"):
fc8_weights = tf.get_variable(name="weight",shape=[FC7_SIZE,OUTPUT_NODE],dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection("losses",regularizer(fc8_weights))
fc8_biases = tf.get_variable(name="bias",shape=[OUTPUT_NODE],dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
fc8 = tf.add(tf.matmul(fc7,fc8_weights),fc8_biases)
return fc8
train.py文件实现训练的过程代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#AlexNet网络的训练过程
import os
from tensorflow.python.framework import ops
import tensorflow as tf
from SIGNG_AlexNet import *
#配置神经网络参数
BATCH_SIZE = 32 #一个batch数据的数目
TRAINING_EPOCH = 30000 #训练迭代次数
LEARNING_RATE_BASE = 0.8 #基础学习率
LEARNING_RATE_DECAY = 0.99 #学习率衰减
REGULARAZTION_RATE = 0.0001 #描述模型复杂度的正则化在损失函数中的系数
MOVING_AVERAGE_DECAY = 0.99
#模型保存的路径和文件名
MODEL_SAVE_PATH = "/path/to/model"
MODEL_NAME = "model.ckpt"
#训练模型
def AlexNet_train(X_train,Y_train,X_test,Y_test,learning_rate=LEARNING_RATE_BASE,
num_epochs=TRAINING_EPOCH, minibatch_size=BATCH_SIZE, print_cost=True):
ops.reset_default_graph() # 在没有tf变量重写的情况下重新运行模型
(m, n_H0, n_W0, n_C0) = X_train.shape
n_y = Y_train.shape[1]
costs = [] # 列表存放目标函数值
#创建占位符
X = tf.placeholder(dtype=tf.float32,shape=(None,n_H0, n_W0, n_C0),name="X")
Y = tf.placeholder(dtype=tf.float32,shape=(None,n_y),name="Y")
#正则化
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
#前向传播
out = SIGNG_AlexNet.AlexNet(X,regularizer)
#变量模拟神经网络中的迭代次数,可用于动态控制衰减率
global_step = tf.Variable(0,trainable=False)
#定义损失函数、学习率、滑动平均操作机训练过程
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=out,labels=tf.argmax(Y,1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
cost = cross_entropy_mean + tf.add_n(tf.get_collection("losses"))
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,
m/BATCH_SIZE,LEARNING_RATE_DECAY)
optm = tf.train.AdamOptimizer(learning_rate).minimize(cost,global_step=global_step)
with tf.control_dependencies([optm,variable_averages_op]):
train_op = tf.no_op(name="train")
#初始化tensorflow持久化
saver = tf.train.Saver()
with tf.Session() as sees:
init = tf.initialize_all_variables()
sees.run(init)
#循环进行模型训练
for epoch in range(TRAINING_EPOCH):
minibatch_cost = 0
num_minibatch = int(m / minibatch)
minibatchs = random_mini_batches(X_train, Y_train, minibatch)
for minibatch in minibatchs:
#选择一个minibatch
(minibatch_X,minibatch_Y) = minibatch
_,temp_cost,step = sees.run([train_op,cost,global_step],
feed_dict={X:minibatch_X,Y:minibatch_Y})
minibatch_cost += temp_cost / num_minibatch
# 每 1000 次epoch打印目标函数值cost
if print_cost == True and epoch % 1 == 0:
costs.append(minibatch_cost)
if print_cost == True and epoch % 1000 == 0:
print("Cost after epoch %i:%f" % (step, minibatch_cost))
saver.save(
sees,os.path.join(MODEL_SAVE_PATH,MODEL_NAME),global_step==global_step
)
# 计算准确的预测
correct_predict = tf.equal(tf.argmax(out, 1), tf.argmax(Y, 1))
# 在测试集上计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_predict, tf.float32))
print(accuracy)
train_accuracy = accuracy.eval({X: X_train, Y: Y_train})
test_accuracy = accuracy.eval({X: X_test, Y: Y_test})
print("Train Acurracy :" + str(train_accuracy))
print("Test Acurracy :" + str(test_accuracy))
return train_accuracy, test_accuracy
#加载数据集
X_train_orig,Y_train_orig,X_test_orig,Y_test_orig,classes = load_dataset()
#标准化特征值,使得数值在0至1之间
X_train = X_train_orig/255
X_test = X_test_orig/255
Y_train = convert_to_one_hot(Y_train_orig,6).T
Y_test = convert_to_one_hot(Y_test_orig,6).T
#调用构建的模型
AlexNet_train(X_train,Y_train,X_test,Y_test)
常用数据集:
ImageNet http://www.image-net.org/
Microsoft的COCO http://mscoco.org/
CIFAR-10和CIFAR-100 https://www.cs.toronto.edu/~kriz/cifar.html
PASCAL VOC http://host.robots.ox.ac.uk/pascal/VOC/
from:https://blog.csdn.net/loveliuzz/article/details/79131131














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









